目录
一. 基本数据类型
1.1 64bit数据类型
1.2 128bit数据类型
1.3 结构化数据类型
二. 基本指令集
2.1 初始化寄存器
vcreate
vdup
vmov
2.2 加载数据进寄存器
vld
vld_lane
2.3 存储寄存器到内存
vst
vst_lane
2.4 读取/修改寄存器数据
vget_lane
vget_low
vget_high
vset_lane
2.5 数据重排
vext
vtbl
vrev
vtrn
vzip
vuzp
vcombine
vbsl
2.6 类型转换
vreinterpret
vcvt
2.7 加法减法指令
vadd
vaddl
vaddw
vhadd
vrhadd
vqadd
vaddhn
2.8 乘法指令
vmul
vmla
vmls
2.9 基本数学计算指令
vabs
vneg
vmax
vmin
vrnd
vrecp
vrsqrt
2.10 比较指令
vceq
vcge
vcgt
vcle
vclt
2.11 归约指令
vpadd
vpmax
vpmin
2.12 位操作指令
vmvn
vand
vorr
veor
vcls
vshl
vrshl
参考资料
ARMv7架构的包含如下寄存器:
- 16个通用寄存器(32bit),R0~R15;
- 16个NEON寄存器(128bit),Q0~Q15,同时也可以被视为32个64bit的寄存器,D0~D31;
- 16个VFP寄存器(32bit),S0~S15.
NEON与VFP都能加速浮点计算,区别在于VFP不具备数据并行能力,在双精度浮点数的计算性能上更好,而NEON则更优于多数据的并行计算。
一. 基本数据类型
(type)x(lanes)_t例如,int16x4_t就是一个包含4条向量线的向量数据,每条向量线是一个有符号16位整型数。
1.1 64bit数据类型
typedef __Int8x8_t int8x8_t;
typedef __Int16x4_t int16x4_t;
typedef __Int32x2_t int32x2_t;
typedef __Int64x1_t int64x1_t;
typedef __Float16x4_t float16x4_t;
typedef __Float32x2_t float32x2_t;
typedef __Poly8x8_t poly8x8_t;
typedef __Poly16x4_t poly16x4_t;
typedef __Uint8x8_t uint8x8_t;
typedef __Uint16x4_t uint16x4_t;
typedef __Uint32x2_t uint32x2_t;
typedef __Float64x1_t float64x1_t;
typedef __Uint64x1_t uint64x1_t;1.2 128bit数据类型
typedef __Int8x16_t int8x16_t;
typedef __Int16x8_t int16x8_t;
typedef __Int32x4_t int32x4_t;
typedef __Int64x2_t int64x2_t;
typedef __Float16x8_t float16x8_t;
typedef __Float32x4_t float32x4_t;
typedef __Float64x2_t float64x2_t;
typedef __Poly8x16_t poly8x16_t;
typedef __Poly16x8_t poly16x8_t;
typedef __Poly64x2_t poly64x2_t;
typedef __Uint8x16_t uint8x16_t;
typedef __Uint16x8_t uint16x8_t;
typedef __Uint32x4_t uint32x4_t;
typedef __Uint64x2_t uint64x2_t;1.3 结构化数据类型
将上述基本的数据组合成一个结构体构成结构化数据,通常被映射到一组向量寄存器中,例如:
typedef struct int8x8x2_t
{int8x8_t val[2];
} int8x8x2_t;typedef struct int8x16x2_t
{int8x16_t val[2];
} int8x16x2_t;
...二. 基本指令集
NEON指令按照操作数类型可以分为正常指令、宽指令、窄指令、饱和指令、长指令。
- 正常指令:生成大小相同且类型通常与操作数向量相同到结果向量。
- 长指令:对双字向量操作数执行运算,生产四字向量到结果。所生成的元素一般是操作数元素宽度到两倍,并属于同一类型。L标记,如VMOVL。
- 宽指令:一个双字向量操作数和一个四字向量操作数执行运算,生成四字向量结果。W标记,如VADDW。
- 窄指令:四字向量操作数执行运算,并生成双字向量结果,所生成的元素一般是操作数元素宽度的一半。N标记,如VMOVN。
- 饱和指令:当超过数据类型指定到范围则自动限制在该范围内。Q标记,如VQSHRUN。
NEON指令按照作用可以分为:加载数据、存储数据、加减乘除运算、逻辑AND/OR/XOR运算、比较大小运算等。
2.1 初始化寄存器
vcreate
将一个64bit的数据装入vector,并返回type类型的vector。
Result_t vcreate_type(uint64_t N)int8x8_t s8_8 = vcreate_s8(5);
int16x4_t s16_4 = vcreate_s16(0x0102030405060708);
// s8_8: 5 0 0 0 0 0 0 0
// s16_4:8 7 6 5 4 3 2 1vdup
用类型为type的数值,初始化元素类型为type的vector,所有的元素赋值为相同的数值。
Result_t vdup_n_type(type n)用元素类型为type的vector的某个元素,初始化一个元素类型为type的新vector的所有元素。
Result_t vdup_lane_type(Vector_t M, int8_t n)int8x8_t s8_8_d = vdup_n_s8(8);
// s8_8_d : 8 8 8 8 8 8 8
int8x8_t vdata={0,1,2,3,4,5,6,7};
int8x8_t s8_8_lane = vdup_lane_s8(vdata, 3);
// s8_8_lane: 3 3 3 3 3 3 3 3vmov
功能与vdup相同,用元素为type的数值,初始化元素类型为type的vector,所有的元素赋值相同的数值.
Result_t vmov_n_type(type n)将vector中的元素bit位扩大到原来的两倍,元素值不变。
Result_t vmovl_type(Vector_t M)创建一个新vector,新vector的元素bit位是源vector的一半,新vector只保留原vector低半部分bit数据。
Result vmovn_type(Vector_t M)2.2 加载数据进寄存器
vld
Result_t vld[x]_type(Scalar_t *N) Result_t vld[x]q_type(Scalar_t *N)int8_t data[32] = {0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31};
{printf("vld[x]_type(Scalar_t *N) x=1\n");int8x8_t s8_1 = vld1_s8(data);print_neon_valude<int8x8_t>(s8_1);int8x16_t s8_2 = vld1q_s8(data);print_neon_valude<int8x16_t>(s8_2);
}{printf("vld[x]_type(Scalar_t *N) x=2\n");int8x8x2_t s8_1 = vld2_s8(data);print_neon_valude<int8x8x2_t>(s8_1);int8x16x2_t s8_2 = vld2q_s8(data);print_neon_valude<int8x16x2_t>(s8_2);
}vld_lane
间隔为x,加载数据进NEON寄存器的相关lane(通道),其他lane(通道)的数据不改变
Result_t vld[x]_lane_type(Scalar_t* N,Vector_t M,int n)
Result_t vld[x]q_lane_type(Scalar_t* N,Vector_t M,int n)从N中加载x条数据,分别duplicate(复制)数据到寄存器0-(x-1)的所有通道
Result_t vld[x]_dup_type(Scalar_t* N)
Result_t vld[x]q_dup_type(Scalar_t* N)- lane(通道):比如一个float32x4_t的NEON寄存器,它具有4个lane(通道),每个lane(通道)有一个float32的值,因此c++ float32x4_t dst = vld1q_lane_f32( float32_t* ptr, float32x4_t src, int n=2)的意思就是先将src寄存器的值复制到dst寄存器中,然后从ptr这个内存地址中加载第3个(lane的index从0开始)float到dst寄存器的第3个lane(通道中)。最后dst的值为:{src[0], src[1], ptr[2], src[3]}。
- 间隔:交叉存取,是ARM NEON特有的指令,比如c++ float32x4x3_t = vld3q_f32( float32_t* ptr),此处间隔为3,即交叉读取12个float32进3个NEON寄存器中。3个寄存器的值分别为:{ptr[0],ptr[3],ptr[6],ptr[9]},{ptr[1],ptr[4],ptr[7],ptr[10]},{ptr[2],ptr[5],ptr[8],ptr[11]}。
2.3 存储寄存器到内存
vst
void vst[x]_type(Scalar_t* N, Vector M)
void vst[x]q_type(Scalar_t* N)int8_t data[16] = {0};
{printf("vst[x]_type(Scalar_t *N) x=1\n");int8x8_t s8_1 = vdup_n_s8(5);vst1_s8(data, s8_1);print_neon_valude<int8x8_t>(s8_1);print_array<int8_t>(data, sizeof(data));
}vst[x]_type(Scalar_t *N) x=1
5 5 5 5 5 5 5 5
5 5 5 5 5 5 5 5 0 0 0 0 0 0 0 0vst_lane
void vst[x]_lane_s8(Scalar_t *N, Vector_t M, int lane)
void vst[x]q_lane_s8(Scalar_t *N, Vector_t M, int lane)printf("vst[x]_lane_type(Scalar_t *N, Scalar_t *M, int lane) x=1\n");
int8x8_t s8_2 = vdup_n_s8(6);
vst1_lane_s8(data, s8_2, 1);
print_neon_valude<int8x8_t>(s8_2);
print_array<int8_t>(data, sizeof(data));6 6 6 6 6 6 6 6
6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 02.4 读取/修改寄存器数据
vget_lane
Result vget_lane_type(Vector_t M, int n)读取寄存器的高/低位到新的新的寄存器中,类似于后面的mov指令,数据宽度变化。
vget_low
vget_high
Result vget_low_type(Vector_t M)
Result vget_high_type(Vector_t M)int8_t data8[16] = {0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15};
int8x16_t s8_1 = vld1q_s8(data8);
int8_t int8_lane3 = vgetq_lane_s8(s8_1, 3);
int8x8_t s8_low = vget_low_s8(s8_1);
int8x8_t s8_high = vget_high_s8(s8_1);===========Neon Get & Set Instructions===========
vget_lane_s8(Vector M):
int8x16_t: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
int8x16_t 3 lanel:3
s8_low: 0 1 2 3 4 5 6 7
s8_high: 8 9 10 11 12 13 14 15vset_lane
与vget_lane_type相反的vset_lane_type.
Result_t vset_lane_type(Scalar N,Vector_t M,int n)int8x8_t s8_set = vset_lane_s8((int8_t)21, s8_high, 3);
s8_high: 8 9 10 11 12 13 14 15
s8_set: 8 9 10 21 12 13 14 152.5 数据重排
vext
从寄存器M中取出低位的n个通道的数据置于低位,再从寄存器N中取出x-n个通道的数据置于高位,组成新的一个寄存器数据:
Result_t vext[q]_type(Vector_t N,Vector_t M,int n)int8_t data8[16] = TEST_DATA;
int8x8_t s8_1 = vld1_s8(data8);
int8x8_t s8_2 = vld1_s8(&data8[8]);
int8x8_t s8_reorder = vext_s8(s8_1, s8_2, 3);vdata1: 0 1 2 3 4 5 6 7
vdata2: 8 9 10 11 12 13 14 15
vdata3: 3 4 5 6 7 8 9 10vtbl
根据索引值取一个或一组寄存器中的数据组成一个新的寄存器。如果索引值超过输入的寄存器(组)则赋值为0.其中,M可一时寄存器组,如int8x8x2_t,对应的x也必须是2.
Result_t vtblx_type(Vectorx_t M, int8x8_t N)int8x8_t vdata = {0,1,2,3,4,5,6,7};
int8x8_t index = {1,1,2,3,3,7,-1,9};
int8x8_t tbl_1 = vtbl1_s8(vdata, index);
// 则tbl_1: 1 1 2 3 3 7 0 0int8x8x2_t vdata = {0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15};
int8x8_t index = {1,1,2,3,3,7,-1,9};
int8x8_t tbl_2= vtbl2_s8(vdata , index);
// 则tbl_2: 2 2 4 6 6 14 0 3vrev
int8x8_t vrev16_s8(int8x8_t M)
int8x8_t vrev32_s8(int8x8_t M)
int8x8_t vrev64_s8(int8x8_t M)int8x8_t vdata = {0,1,2,3,4,5,6,7};
int8x8_t rev_1 = vrev16_s8(vdata);
int8x8_t rev_2 = vrev32_s8(vdata);
int8x8_t rev_3 = vrev64_s8(vdata);
// rev_1: 1 0 3 2 5 4 7 6
// rev_2: 3 2 1 0 7 6 5 4
// rev_3: 7 6 5 4 3 2 1 0vtrn
将输入的两个向量的元素通过转置生成一个新由两个向量组成的矩阵
int8x8x2_t vtrn_s8(int8x8_t M, int8x8_t N)
int16x4x2_t vtrn_s16(int16x4_t M, int16x4_t N)
int32x2x2_t vtrn_s32(int32x2_t M, int32x2_t N)int8x8_t vdata1 = {0,1,2,3,4,5,6,7};
int8x8_t vdata2 = {8,9,10,11,12,13,14,15};
int8x8x2_t trn_1 = vtrn_s8(vdata1, vdata2);
// vdata1: 0 1 2 3 4 5 6 7
// vdata2: 8 9 10 11 12 13 14 15
// trn_1: 0 8 2 10 4 12 6 14 1 9 3 11 5 13 7 15vzip
将两个输入vector的元素通过交叉生成一个有两个vector的矩阵。
Result_t vzip_type(Vector_t M, Vector_t N)int8x8_t vdata1 = {0,1,2,3,4,5,6,7};
int8x8_t vdata2 = {8,9,10,11,12,13,14,15};
int8x8x2_t zip_1 = vzip_s8(vdata1, vdata2);
// zip_1:0 8 1 9 2 10 3 11 4 12 5 13 6 14 7 15vuzp
将两个输入vector的元素通过反交叉生成有两个vectr的矩阵
Result_t vuzp_type(Vector_t M, Vector_t N)int8x8_t vdata1 = {0,1,2,3,4,5,6,7};
int8x8_t vdata2 = {8,9,10,11,12,13,14,15};
int8x8x2_t zip_1 = vuzp_s8(vdata1, vdata2);
// zip_1: 0 2 4 6 8 10 12 14 1 3 5 7 9 11 13 15vcombine
将两个元素类型相同的vector拼接成一个同类型但大小是输入vector两倍的新vector,第一个输入参数存放在新vector低部分元素。
Result_t vcombine_type(Vector_t M, Vector_t N)vbsl
按为选择,mask的元素为1则选择src1中对应的位置的元素,为0则选择src2中的元素。
Result_t vbsl_type(Vector_t Mask, Vector_M, Vector_t N)int8x8_t vdata1 = {0,1,2,3,4,5,6,7};
int8x8_t vdata2 = {8,9,10,11,12,13,14,15};
uint8x8_t vmask = {0, 3, 255, 8, 7, 127, 255, 10};
int8x8_t zbsl_1 = vbsl_s8(vmask, vdata1, vdata2);
// zbsl_1: 8 9 2 3 12 5 6 72.6 类型转换
vreinterpret
类似于C/C++的指针类型强制转换,寄存器数据和长度不发生变化,值类型改变,例如uint8x8_t p1 = vreinterpret_u8_s8(int8x8_t p0);将p0寄存器重新解释为uint8x8_t类型。
DstType vreinterpret_DstType_SrcType(Vector_t N)vcvt
f32, u32, s32之间的转换,f32转到u32时,向下取整,如果是负数则转换成0。
DstType vcvt_DstType_SrcType(SrcType M)float32x2_t vcvt_f32_u32(uint32x2_t __p0)
float32x2_t vcvt_f32_s32(int32x2_t __p0)
int32x2_t vcvt_s32_f32(float32x2_t __p0)
uint32x2_t vcvt_u32_f32(float32x2_t __p0)2.7 加法减法指令
减法与减法都有类似的指令,下列加法指令中add替换为sub即为减法指令,例如vadd_s8与vsub_s8为同类型的加法与减法指令。
vadd
Result_t vadd_type(Vector_t M, Vector_t N) Result_t vaddq_type(Vector_t M, Vector_t N)计算向量对应位置的数据的和,返回结果类型与输入类型一致,可能产生溢出。
vaddl
Result_t vaddl_type(Vector_t M, Vector_t N)vaddw
宽指令,两个寄存器宽度不相等的加法,第一个参数宽度大于第二个,例如,int16x8_t vaddw_s8(int16x8_t p0, int8x8_t p1)
Result_t vaddw_type(Vector_t M, Vector_t N)vhadd
Result vhadd_type(Vector_t M, Vector_t N)vrhadd
计算和的均值,先计算和,再右移一位,如果溢出,则加1,及去四舍五入的均值。
Result vrhadd_type(Vector_t M, Vector_t N)vqadd
饱和指令,饱和加法运算,如:int8x8_t vqadd(int8x8_t p0, int8x8_t p1),如果某个通道的数据加法的和超过127则设置为127.
Result vqadd_type(Vector_t M, Vector_t N)vaddhn
窄指令,计算结果比参数M/N的长度小一半,相当于计算结果右移8 bit,例如int8x8_t vaddhn_s16(int16x8_t p0, int16x8_t p1)
Result vaddhn_type(Vector_t M, Vector_t N)int8x8_t vdata1 = {0, 10, 100, 127, -10, -100, -128, -128};
int8x8_t vdata2 = {4, 9, 27, 3, -9, -100, -128, -1};
int16x8_t vdata3 = {0, 10, 100, 127, -10, -100, -128, -128};
int16x8_t vdata4 = {4, 9, 27, 3, -9, -100, -128, -1};int8x8_t vdata_0 = vadd_s8(vdata1, vdata2);
int16x8_t vadd_1 = vaddl_s8(vdata1, vdata2);
int16x8_t vadd_3 = vaddw_s8(vdata4, vdata1);
int8x8_t vadd_4 = vhadd_s8(vdata1, vdata2);
int8x8_t vadd_5 = vrhadd_s8(vdata1, vdata2);
int8x8_t vadd_6 = vqadd_s8(vdata1, vdata2);
int8x8_t vadd_7 = vaddhn_s16(vdata3, vdata4);vdata1: 0 10 100 127 -10 -100 -128 -128
vdata2: 4 9 27 3 -9 -100 -128 -1
vadd : 4 19 127 -126 -19 56 0 127
vaddl : 4 19 127 130 -19 -200 -256 -129
vaddw : 4 19 127 130 -19 -200 -256 -129
vhadd : 2 9 63 65 -10 -100 -128 -65
vrhadd: 2 10 64 65 -9 -100 -128 -64
vqadd : 4 19 127 127 -19 -128 -128 -128
vaddhn: 0 0 0 0 -1 -1 -1 -12.8 乘法指令
vmul
Result_t vmul_type(Vector_t M,Vector_t N)Result_t vmull_type(Vector_t M,Vector_t N)vmla
Result_t vmla_type(Vector_t M,Vector_t N,Vector_t P)vmls
Result_t vmls_type(Vector_t M,Vector_t N,Vector_t P)int8x8_t vdata1 = {0, 10, 100, 127, -10, -100, -128, -128};
int8x8_t vdata2 = {4, 9, 27, 3, -9, -100, -128, -1};
int8x8_t vdata3 = {0, 1, 2, 3, 4, 5, 6, 7};int8x8_t vdata_0 = vmul_s8(vdata1, vdata2);
int16x8_t vmul_1 = vmull_s8(vdata1, vdata2);
int8x8_t vmla_0 = vmla_s8(vdata3, vdata1, vdata2);
int16x8_t vmla_1 = vmlal_s8(vmovl_s8(vdata3), vdata1, vdata2);
int8x8_t vmls_0 = vmls_s8(vdata3, vdata1, vdata2);
int16x8_t vmls_1 = vmlsl_s8(vmovl_s8(vdata3), vdata1, vdata2);vdata1: 0 10 100 127 -10 -100 -128 -128
vdata2: 4 9 27 3 -9 -100 -128 -1
vdata3: 0 1 2 3 4 5 6 7
vmul : 0 90 -116 125 90 16 0 -128
vmull : 0 90 2700 381 90 10000 16384 128
vmla : 0 91 -114 -128 94 21 6 -121
vmlal: 0 91 2702 384 94 10005 16390 135
vmls : 0 -89 118 -122 -86 -11 6 -121
vmlsl: 0 -89 -2698 -378 -86 -9995 -16378 -1212.9 基本数学计算指令
vabs
Result_t vabs_type(Vector_t M)vneg
计算相反数:res=-M.先计算数值的相反数,再按值取类型,例如vneg_s8(),当出现-128时,取反得128,对应的8bit数据为10000000b,解析为int8_t为-128,所以-128取反还是-128.
Result_t vneg_type(Vector_t M)vmax
Result_t vmax_type(Vector_t M)vmin
Result_t vmin_type(Vector_t M)vrnd
取整,取整有不同的算法类型, ftype可以是f16, f32, f64
vrndn_ftype: to nearest, tiles to even
vrnda_ftype: to nearest, ties away from zero
vrndp_ftype: towards +Inf
vrndm_ftype: towards -Inf
vrnd_ftype: towards 0vrecp
Vector_t vrecpe_type(Vector_t M)Vector_t vrecps_type(Vector_t M)vrsqrt
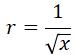
与vrecp同样,type只能是f32,f64和u32,输入不能是负数,否则计算出来是nan。
Vector_t vrsqrte_type(Vector_t M) Vector_t vrsqrts_type(Vector_t M)2.10 比较指令
第一个向量与第二个向量进行比较,如果满足条件则返回bit位全位1的值,否则返回0。例如uint32x2_t vres = vceq_s32({1,2}, {1,3}), vres={0xffffffff,0x00000000}.
vceq
Result_t vceq_type(Vector_t M, Vector_t N)vcge
Result_t vceg_type(Vector_t M, Vector_t N)vcgt
Result_t vcgt_type(Vector_t M, Vector_t N)vcle
Result_t vcle_type(Vector_t M, Vector_t N)vclt
Result_t vclt_type(Vector_t M, Vector_t N)int8x8_t vdata1 = {0, 10, 20, 127, -10, -100, -128, -128};
int8x8_t vdata2 = {4, 9, 20, 3, -9, -100, -128, -1};uint8x8_t vdata_0 = vceq_s8(vdata1, vdata2);
uint8x8_t vdata_1 = vcge_s8(vdata1, vdata2);
uint8x8_t vdata_2 = vcgt_s8(vdata1, vdata2);
uint8x8_t vdata_3 = vcle_s8(vdata1, vdata2);
uint8x8_t vdata_4 = vclt_s8(vdata1, vdata2);vdata1: 0 10 20 127 -10 -100 -128 -128
vdata2: 4 9 20 3 -9 -100 -128 -1
vceq : 0 0 255 0 0 255 255 0
vcge : 0 255 255 255 0 255 255 0
vcgt : 0 255 0 255 0 0 0 0
vcle :255 0 255 0 255 255 255 255
vclt :255 0 0 0 255 0 0 255因为向量的基本数据类型为int8_t,比较输出mask类型为uint8_t,当满足比较条件时输出0xff,也就是255。
2.11 归约指令
vpadd
[普通指令]归约加法,M,N内部相邻元素对应相加,最后计算和,溢出则截断
Result_t vpadd_type(Vector_t M,Vector_t N)Result_t vpaddl_type(Vector_t M,Vector_t N)vpmax
[普通指令]归约求最大值,M,N各自内部相邻元素求最大值,最后组成一个新的向量
Result_t vpmax_type(Vector_t M,Vector_t N)vpmin
[普通指令]归约求最小值,M,N各自内部相邻元素求最小值,最后组成一个新的向量
Result_t vpmin_type(Vector_t M,Vector_t N)2.12 位操作指令
向量中的数据按比特位进行计算。该类指令会将符号位也做位操作。
vmvn
Result_t vmvn_type(Vector_t M)vand
Result_t vand_type(Vector_t M,Vector_t N)vorr
Result_t vorr_type(Vector_t M, Vector_t N)veor
Result_t veor_type(Vector_t M, Vector_t N)vcls
计算连续相同的位数,0或1连续个数最多的,例如11000011b,4个连续的0,2个连续的1,返回4.
Result_t vcls_type(Vector_t M)vshl
左移位, 无论M是有符号还是无符号数,R为有符号数组成的向量类型,为正数时像左移位,为负数时像右移位。左移符号位固定不变,右边补零;右移符号位固定不变,左边移出的bit位补符号位的bit。例如,-3右移1位,11111101b->11111110b,变为-2.
Result_t vshl_type(Vector_t M, Vector_t R)vrshl
Result_t vshl_type(Vector_t M, Vector_t R)int8x8_t vdata1 = {0, 1, 3, 7, 127, -1, -3, -128};
int8x8_t vdata2 = {0, 2, 3, 8, -128, -2, -3, 127};int8x8_t vdata_0 = vmvn_s8(vdata1);
int8x8_t vdata_1 = vand_s8(vdata1, vdata2);
int8x8_t vdata_2 = vorr_s8(vdata1, vdata2);
int8x8_t vdata_3 = veor_s8(vdata1, vdata2);
int8x8_t vdata_4 = vcls_s8(vdata1);int8x8_t shift_value_l = {1,1,1,1,1,1,1,1};
int8x8_t shift_value_r = {-1,-1,-1,-1,-1,-1,-1,-1};
int8x8_t vdata_5 = vshl_s8(vdata1, shift_value_l);
int8x8_t vdata_6 = vshl_s8(vdata1, shift_value_r);
int8x8_t vdata_7 = vrshl_s8(vdata1, shift_value_r);vdata1: 0 1 3 7 127 -1 -3 -128
vdata2: 0 2 3 8 -128 -2 -3 127
vmvn :-1 -2 -4 -8 -128 0 2 127
vand : 0 0 3 0 0 -2 -3 0
vorr : 0 3 3 15 -1 -1 -3 -1
veor : 0 3 0 15 -1 1 0 -1
vcls : 7 6 5 4 0 7 5 0
vshl : 0 2 6 14 -2 -2 -6 0
vshr : 0 0 1 3 63 -1 -2 -64
vrshl: 0 1 2 4 64 0 -1 -64参考资料
[1] http://Coding for Neon - Part 1: Load and Stores
欢迎关注亦梦云烟的微信公众号: 亦梦智能计算