1.redis集群模式比较
(1)哨兵模式
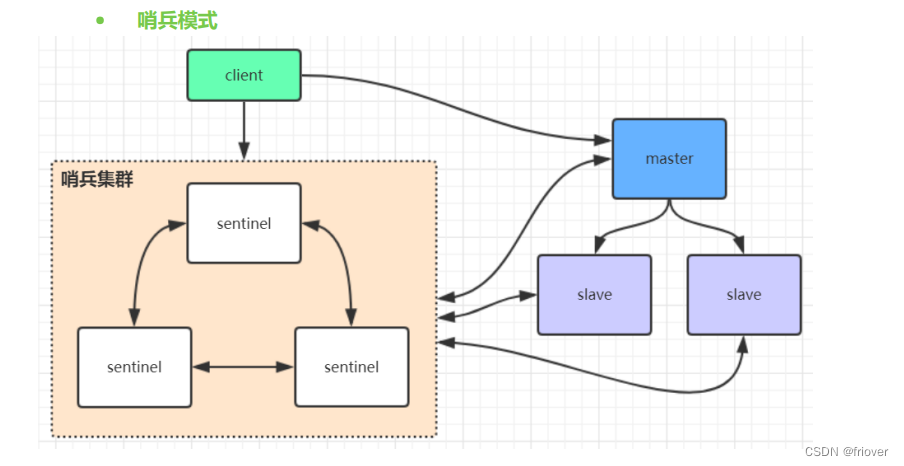
哨兵模式是利用哨兵来做主从切换的,当主节点发生故障的时候,通过哨兵去选取出一个从节点作为主节点,但本身哨兵的配置还是有些麻烦,并且实际上哨兵的性能和高可用性一般!
特别是当主节点发生故障以后,在选举的这个过程中,出现访问瞬断的情况,即此时集群不支持访问,并且哨兵模式只有一个节点提供访问,不能支持很高的并发。
在上一课我们知道redis在持久化文件的时候,不论是rdb持久化还是aof持久化,都是每次备份内存中所有数据到磁盘的,这些的话也会导致持久化时间过长,影响数据恢复和主从同步的效率。
(2)高可用集群模式
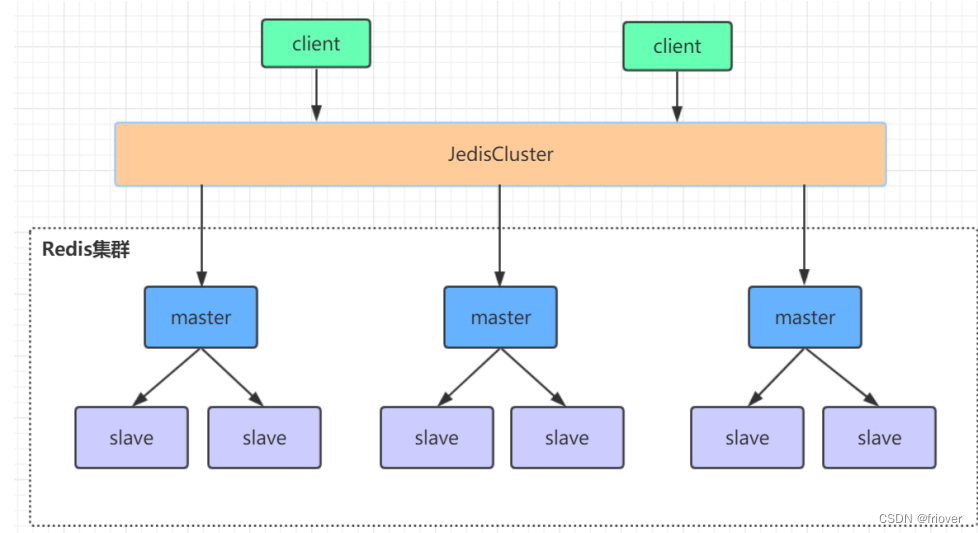
redis集群是由多个主从节点组成的一个大的分布式服务器集群,它具有复制、高可用、高并发、分片的特性。redis不需要哨兵也能完成节点的移除和重新选举。
这种配置不需要一个中心的节点,可以水平拓展(官方说是水平拓展到1000个节点),并且配置比哨兵模式还要简单
2.Redis高可用集群搭建
(1)第一步:准备三台虚拟机,实际一台虚拟机也没问题,反正是自己玩,我这里还是准备了三台,之前学jenkins正好搭建了三台
(2)第二步:把上节课的redis里的配置文件redis.conf复制出来,对每台服务器都复制,这样三台服务器对应6个redis,每台服务器都是一主一从
(3)修改配置文件
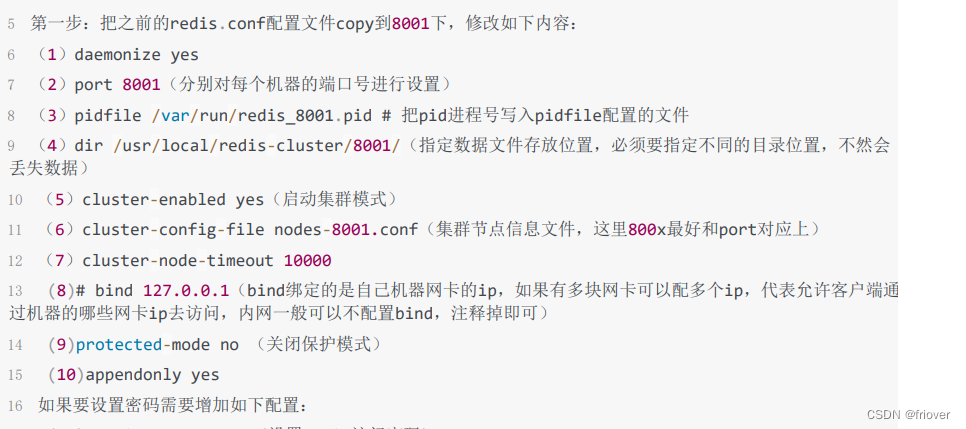
设置redis的密码,这个密码是客户端访问的
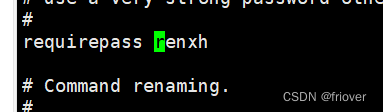
设置集群节点间的密码,这个密码是集群间通信访问的
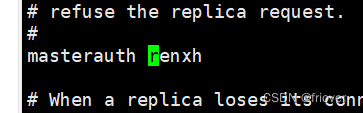
同理其他文件也是如此
(4)分别启动每台服务器的redis,看能否启动成功




(5)关闭防火墙,或者打开redis的服务端口以及节点gossip通信端口16379(默认是在redis端口号上加1W)
# systemctl stop firewalld # 临时关闭防火墙# systemctl disable firewalld # 禁止开机启动
启动集群:
/usr/local/redis-5.0.14/src/redis-cli -a renxh --cluster create --cluster-replicas 1 192.168.85.200:8001 192.168.85.201:8002 192.168.85.202:8003 192.168.85.200:8004 192.168.85.201:8005 192.168.85.202:8006
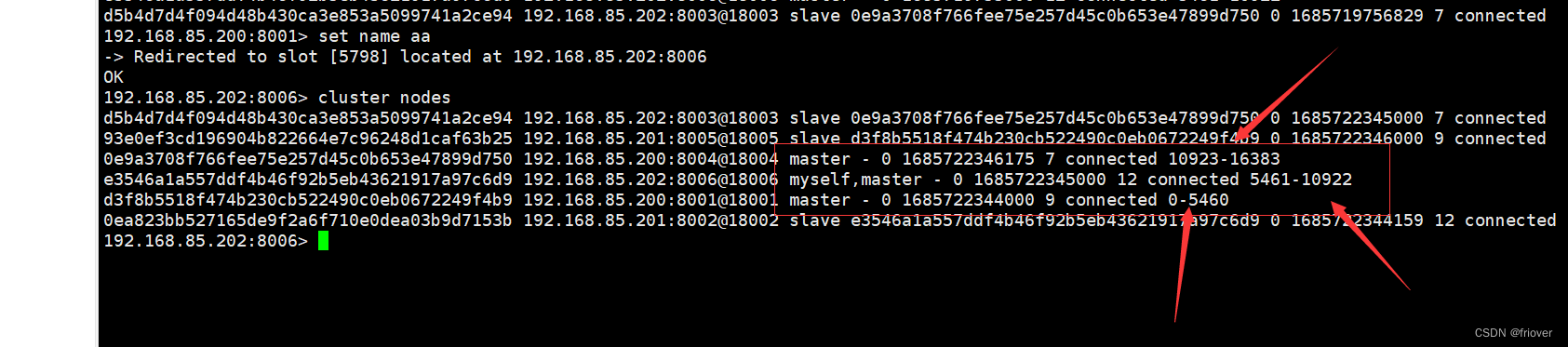
(6)验证集群
连接任意一个客户端,执行cluster nodes
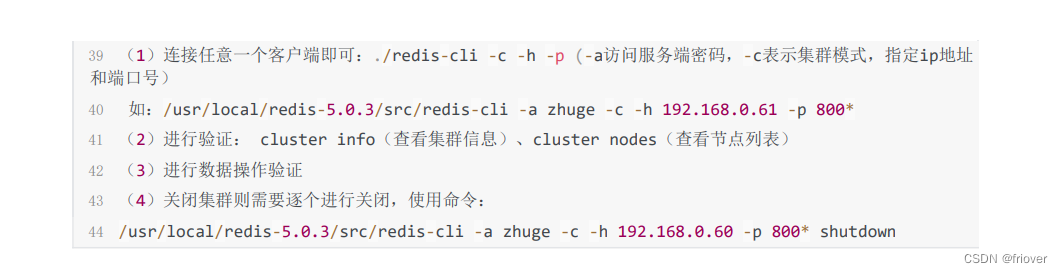

实际当执行启动集群的命令的时候,redis会默认把前三台8001、8002、8003设置为主节点,剩余的三台服务器设置为从节点,但他们各自对应的主节点不在自己的服务器上,而是别的服务器,这样保证了redis的高可用性
小注:上面图片不太对,是因为我后面测试了的,主节点改变了
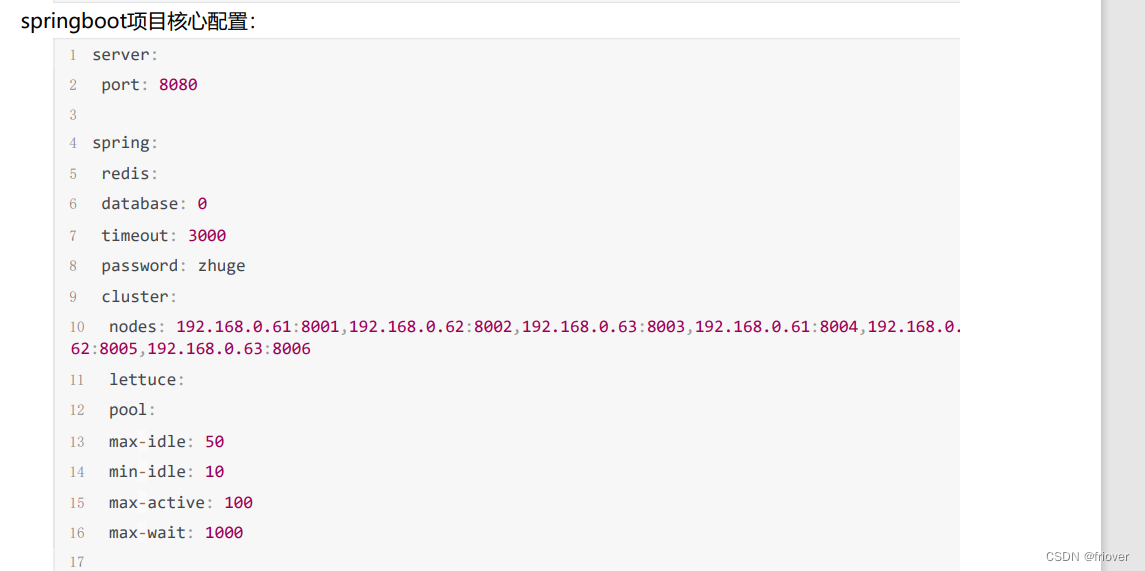
3.springboot的使用配置
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring‐boot‐starter‐data‐redis</artifactId>
</dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons‐pool2</artifactId>
</dependency>
4.集群原理分析
(1)redis Cluster集群实际将所有数据划分为16384个槽,每个节点负责一部分的数据存储,当redis Cluster的客户端来连接的时候,也会把集群的槽位配置信息存储在客户端上,这样客户端查找某一个key的时候,就能直接定位到对应的节点
同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。

(2)跳转定位法
当客户端向一个错误的节点发送了指令,该节点会发现指令的key并不归属于自己管理,这时他会把客户端发送的这个指定携带到拥有这个槽位的节点地址,同时更新客户端的集群配置信息

可以看到当我set name这个key的时候,他告诉我不能插入,同时我的客户端变成了8006端口号
(3)Redis集群节点间的通信机制
其实大多集群之间的通信基本上就是两种,一种是传播(传播就是一个传一个的通知),还有一种集中式(集中式就是所有的节点都在同一个地方管理,类似eureka,nacos,zk)
redis Cluster集群采用的就是传播机制,实际gossip协议
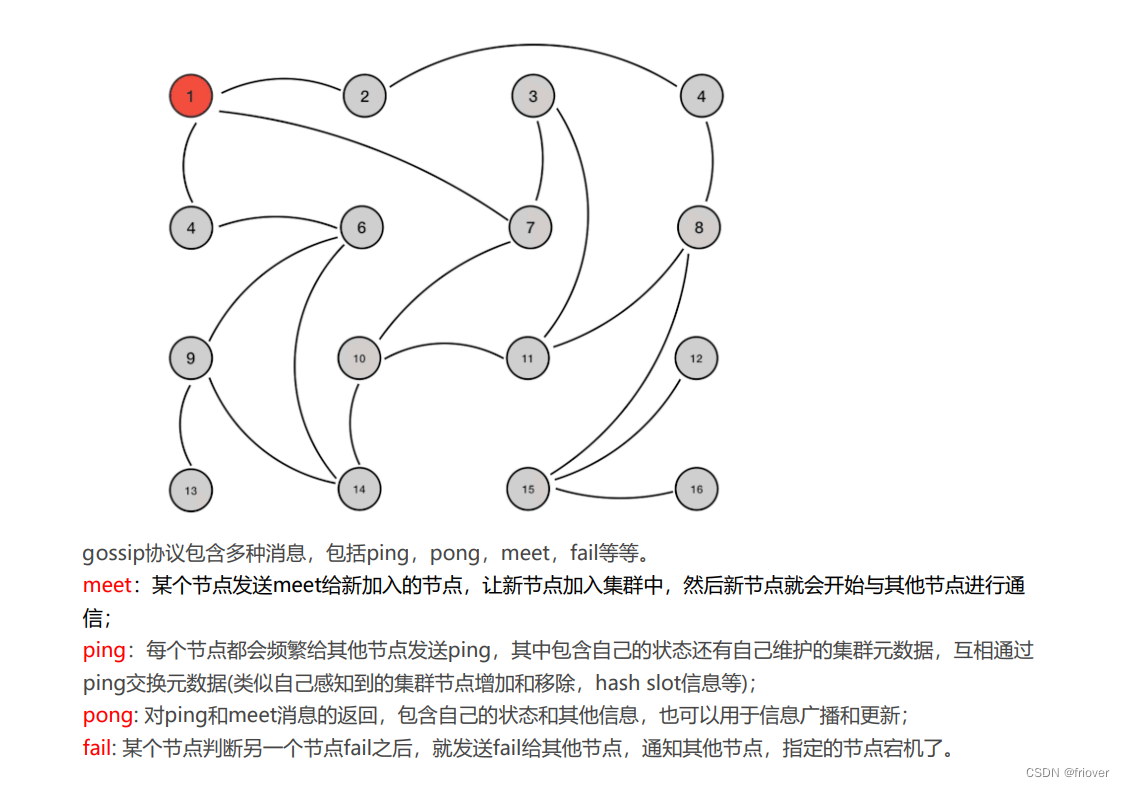
gossip协议有个好处在于元数据的更新比较分散,就是彼此相隔太远,没有集中在一个地方,这样都一定的延时、降低了压力,同理这也是它的缺点,导致元素在更新的时候有延时导致集群的一些操作滞后

(4)网络抖动
真实世界的机房网络往往并不是风平浪静的,它们经常会发生各种各样的小问题。比如网络抖动就是非常常见的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。
为解决这种问题,Redis Cluster 提供了一种选项cluster-node-timeout,表示当某个节点持续 timeout的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频
繁切换 (数据的重新复制)。
(5)Redis集群选举原理分析
当某个节点的从节点发现主节点故障之后,就会尝试选取,希望自己能够成为主节点(毕竟不想当领导的从节点不是好从节点),但是很可能会有多个从节点相互竞争的情况
1.当主节点挂了之后,从节点会向其他节点发送信息,实际也只有其他节点的主节点能够响应
2.尝试成为主节点的从节点在收到其他主节点返回的信息后,发现如果有半数以上的主节点同意,那么就可以成为主节点了,这里也说明为什么搭建集群需要三个节点,也就是三个主节点了
(当只有两个节点的时候,一个节点挂了,即使申请主节点的从节点拿到的票数也只有一票,是不满足半数以上的)
3.成为主节点以后,广播告知集群的其他节点
图为专业话术,实际学习还是夹杂自己理解吧


补充问:实际情况可能出现两个从节点都拿到了一票?
实际是从节点并不是在主节点故障之后立刻发起选举的,(领导噶了,也不能表现的立刻顶人家的位置吧?总要看清一下形势吧,万一领导没噶了呢),是有一定延迟的,当故障信息在集群里传播之后,才能进行选举,否则当从节点申请选举的时候,其他主节点没有收到故障信息,可能会拒绝投票

(6)集群脑裂丢失问题
简单概括就是每个节点实际也是个小集群,当出现网络波动或者其他原因,主节点和从节点无法通信了,也就是说主节点从集群里剥离出来了,但实际主节点也没有故障,只是因为某种原因!
但是这样的话,剩余的从节点会认为主节点已经故障了,会发起选举,成为了主节点,但是此时网络恢复过来了,发现一个节点里有两个主节点,这就是脑裂问题!
这样的话,原本的主节点就会变成从节点,就会丢失大量数据
解决方法: 
(7)集群是否完整才能对外提供服务?
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
(8)Redis集群对批量操作命令的支持 
5.水平拓展集群
(1)先启动搭建好的集群,如上面介绍,查看集群的插槽
从上图可以看出,整个集群运行正常,三个master节点和三个slave节点,8001对应0-5460,8004对应10923-16383,8006对应5461-10922
这三个master节点存储的所有hash槽组成redis集群的存储槽位,slave点是每个主节点的备份从节点,不显示存储槽位
(2)在/usr/local/redis-cluster下创建8007和8008文件夹,并拷贝8001文件夹下的redis.conf文件到8007和8008这两个文件夹下


(3)配置8007为集群主节点
使用add-node命令新增一个主节点8007(master),前面的ip:port为新增节点,后面的ip:port为已知存在节点,看到日志最后有"[OK]New node added correctly"提示代表新节点加入成功
/usr/local/redis‐5.0.14/src/redis‐cli ‐a renxh --cluster add‐node 192.168.85.200:8007 192.168.85.200:8001
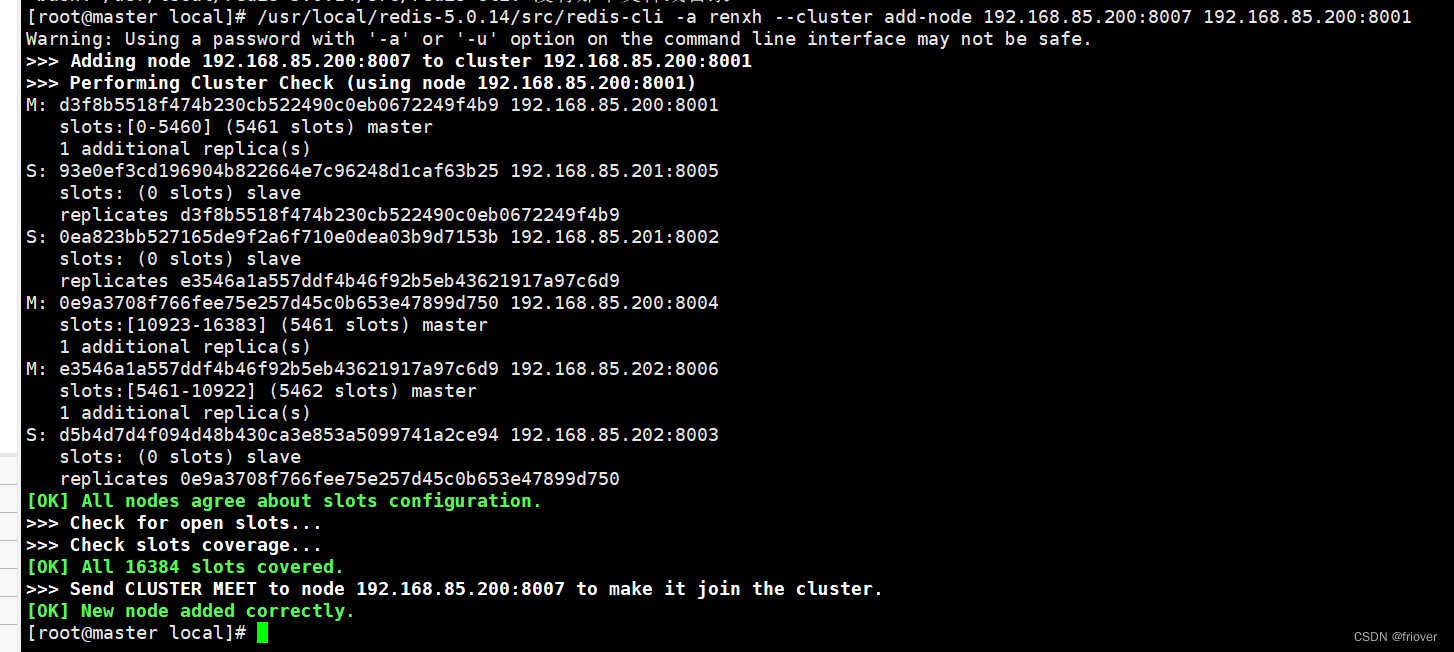
(4)查看集群是否有8007,但此时还不够,因为插槽,新加的节点还没有插槽,数据是分配不了给8007这个redis的

(5)使用redis-cli命令为8007分配hash槽,找到集群中的任意一个主节点,对其进行重新分片工作。

/usr/local/redis-5.0.14/src/redis-cli -a renxh --cluster reshard 192.168.85.200:8001
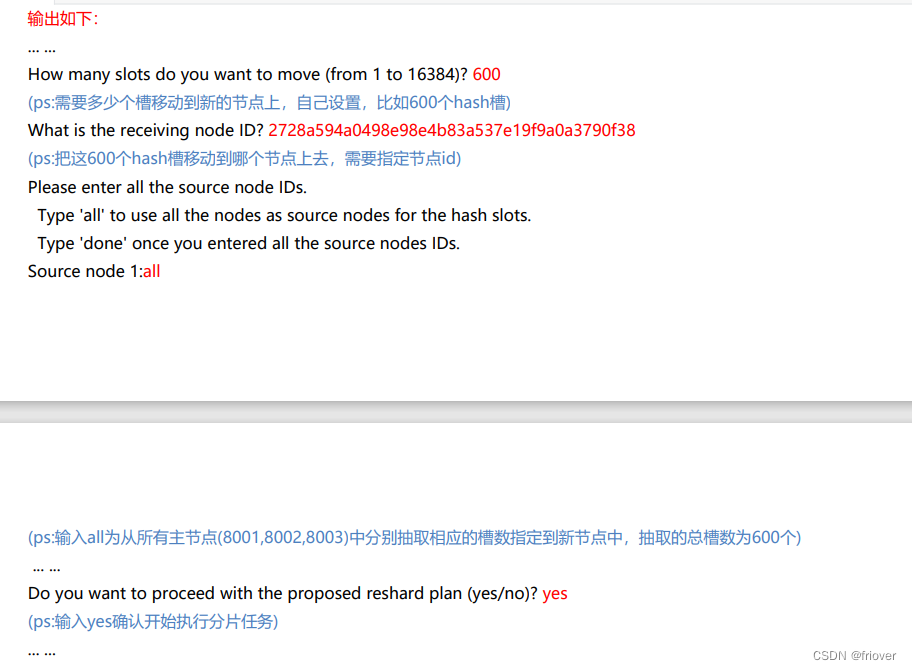
(6)查看最新集群信息

(7)把8008加入到8007,作为8007的从节点
#先把8008加入到集群里
/usr/local/redis-5.0.14/src/redis-cli -a renxh --cluster add-node 192.168.85.200:8008 192.168.85.200:8001
#启动8008客户端
/usr/local/redis-5.0.14/src/redis-cli -a renxh -c -h 192.168.85.200 -p 8008
#后面一长串是8007的名字,作为8007的从节点
cluster replicate 65f0c83b02f700658220a3705f1b1f6250b52bca
(8)检查

(9)又进一步,加油!