转载公众号 | DataFunTalk

分享嘉宾:代文博士 小米 高级算法工程师
编辑整理:何雨婷 湖北工业大学
出品平台:DataFunTalk
导读:今天的介绍会围绕以下三点展开:
小爱同学应用场景
信息抽取
图谱问答
01
小爱同学应用场景介绍
首先和大家介绍一下小爱同学的应用场景。通过小爱同学,可以方便快捷的访问小米的各种智能硬件设备,包括扫地机器人、电视、空调等。小爱同学主要包括内容、信息查询、互动、控制、生活服务、基础工具这六大方面的服务。今天要分享的智能问答,主要解决的是有客观事实性答案的这一类query,主要是为了满足用户信息查询类的需求。
下图是智能问答的框架,主要由数据层、知识层、语义层、逻辑层、业务层、设备层组成。在知识层,本文将分享信息抽取的相关工作。逻辑层主要包括图谱问答、检索问答和文档问答,今天主要分享图谱问答。在业务层,基于问答模块,可以在词典、古诗、人物、星座、菜谱等不同的功能垂域来进行业务层的开发。最后,针对不同的智能硬件,我们在设备层上进行相应的适配,来满足用户在不同终端的需求。
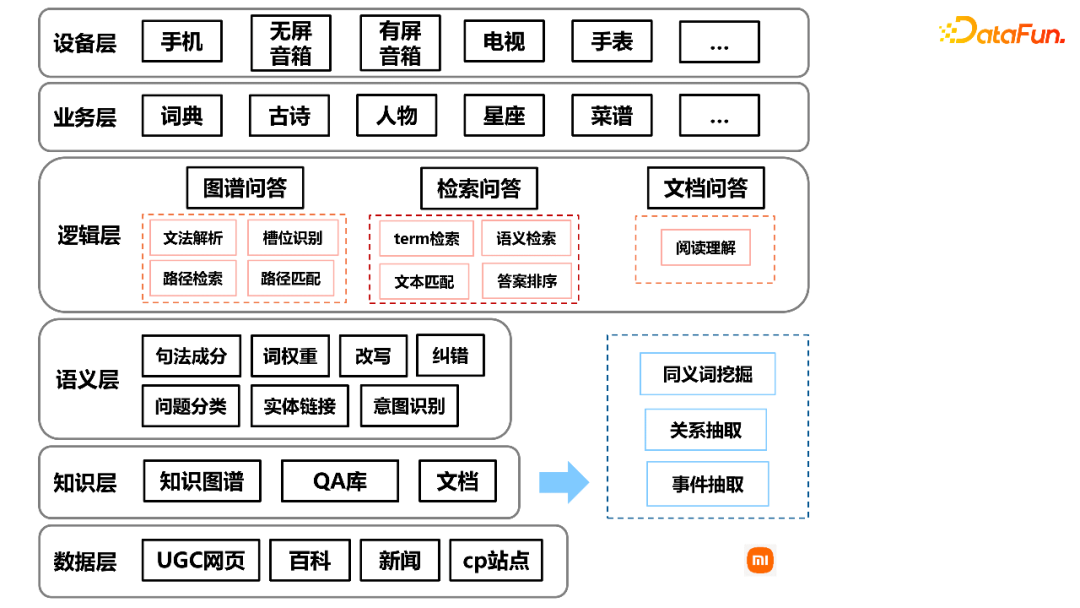
目前,小米的知识图谱实体量是数十亿,三元组spo量超百亿,这些知识囊括了书籍、本地生活、字词、古诗、房产等不同领域的信息。
02
信息抽取

信息抽取是指从非结构化的自然语言文本中提取结构化的知识,如实体、关系、事件等。关系抽取会预先定义好一个schema,然后抽取所有满足schema约束的SPO三元组。事件抽取也是先预先定义好事件类型和论元角色,再从输入的自然语言文本当中识别事件类型,以及这个事件类型对应的一些事件要素。这里举一个关系抽取的例子,“王雪纯是87版《红楼梦》中晴雯的配音者,她是《正大综艺》的主持人”,我们需要去识别出来subject是王雪纯,predicate是配音,object是人物,配音的人物是晴雯。这里的object是一个复合类型,需要同时识别出来配音的角色是谁,属于哪部影视作品。
这里介绍的方案,是我们参加“2021语言与智能技术竞赛:多形态信息抽取任务”的亚军方案。我们主要从关系抽取和事件抽取两个方面介绍信息抽取。
1. 关系抽取
①难点

在关系抽取中,除了复杂o值之外,还有spo重叠这种比较常见的难点,如s和o两个实体分别相同。例如,吴京是战狼的主演,同时吴京也是战狼的导演。此时吴京和战狼这两个实体,在这两种关系中都是相同的。spo重叠还有另外一种形式是,s和o当中,其中一个实体是相同的。
②解决框架

解决框架主要由多模型粗召回和推理模型细打分两部分组成。
多模型粗召回——SPO模型
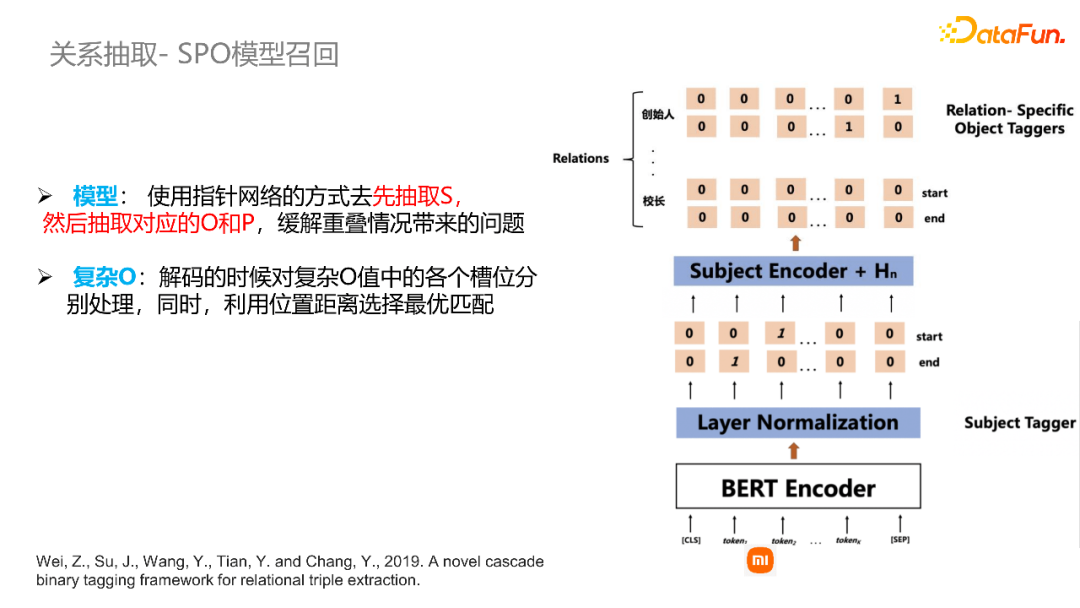
SPO模型:首先通过指针网络的方式抽取s,然后根据s在schema当中对应的p,再通过指针网络的方式找到每一个p在文本当中对应的o的文本片段。上图所示为SPO模型的大体框架图,输入文本后,首先通过编码层对语义信息进行表示,再通过解码网络找到其中的subject,然后将这个subject和输入文本连接起来,再在schema中获取其涉及到的所有谓词,通过指针网络来找到每个谓词下是否存在对应的片段,从而找到这个p和o的结果。对于复杂o值,我们对当中各个槽位都分开来分别处理,并且结合位置距离来选择最优的匹配,最终将复杂o值各个槽位得到的文本结果组合起来作为这个复杂o值的结果。
多模型粗召回——PSO模型
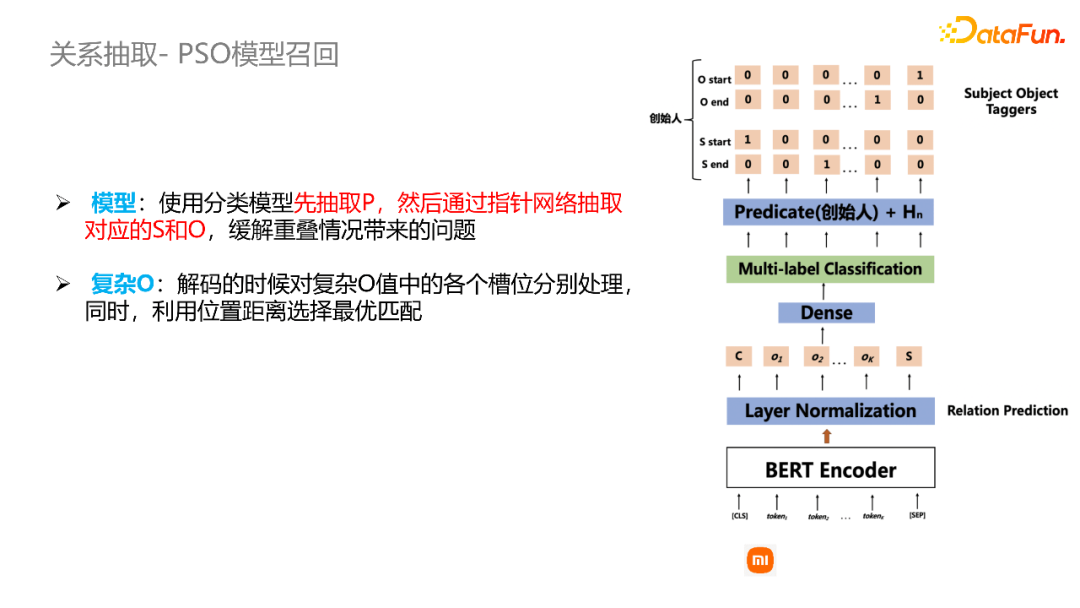
PSO模型:与SPO模型比较类似。我们首先通过分类模型来识别句子中描述的关系类型,再通过指针网络来抽取这个关系类型对应的subject和object。类似我们也可以对复杂o值的各个槽位分别处理,同时利用位置距离来选择最优的匹配。
推理模型细打分
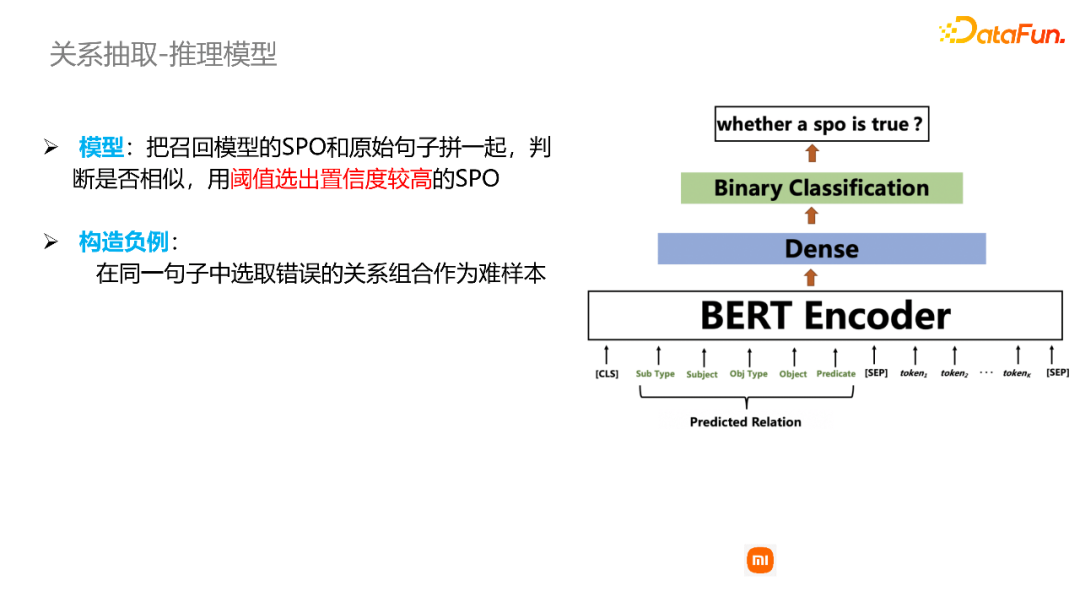
通过SPO模型和PSO模型,得到一些三元组关系的候选队列,还有一个精排的细打分模型。将召回的spo三元组和原始的句子拼接在一起,建模成一个语义相似度的任务,来衡量识别出来的spo三元组和输入文本之间的语义相似度,从而进行细打分。我们可以设定一些阈值,选出置信度较高的一些spo三元组作为最终的抽取结果。
2. 事件抽取
①事件抽取——主要方法
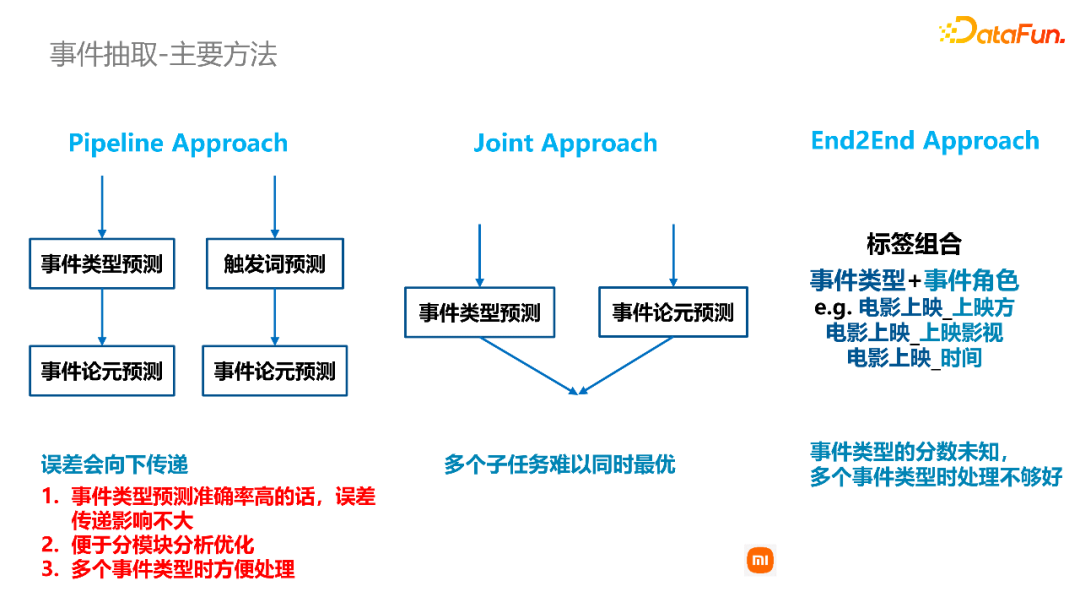
事件抽取的方法流派主要有三种:
第一种是流水线的方式,将事件类型和事件要素的抽取作为流水线串连起来,首先去预测事件类型,得到结果之后,再基于事件类型去预测事件的角色和事件的论元等相关要素的结果。另外基于触发词这种方式,流水线的模式是先抽取触发词,第二步再基于触发词去抽取对应的事件要素。
第二种是联合的模型,将前述的事件类型预测和事件要素抽取联合起来进行多任务学习。为了让多个子任务同时达到最优,收敛过程相对较难一些。
第三种是端到端的方法,我们对标签组合进行了一些调整,将事件类型和事件角色名组合起来,构成一个新的标签组合。通过BIO标注后可以一步到位地识别文本中包含的事件类型,和这个事件类型下每个角色的取值。因为是直接通过序列标注的方式抽取得到两个结果,所以事件类型的分数我们无法得知,因此存在多种事件类型时处理不够好。
如果事件类型的准确率较高,可以优先选择流水线方式,因为事件类型本身误差小,所以误差传递的影响也不大。另外基于流水线方式比较便于后续进行分模块的分析优化。在文本当中存在多个事件类型的情况下,基于流水线方式,可以把第一步事件类型预测得到的多个结果,逐一输送给第二步要素抽取的模型,分别识别每个事件类型对应的事件要素。它对多种事件类型的处理会更好。所以我们的选型也是采用的流水线的方式。
在模型的选择上,常见的有指针网络和序列标注这两种。指针网络的监督信号比较稀疏,模型不好收敛。序列标注的缺点是处理不了overlap的问题。
由于任务中overlap占比少,序列标注模型的准确率受overlap的影响并不大。另外也可以通过一些规则来部分地解决overlap的问题。同时序列标注的训练更容易、效果也更好。所以在事件抽取任务中我们选择了序列标注模型。
②事件抽取——事件类型和触发词识别联合模型
在事件抽取任务中,有的研究者基于事件类型做要素的抽取,有的研究者基于事件触发词做要素的抽取。在这里我们提出事件类型和触发词的联合识别模型。我们发现事件类型和触发词实际上是相互影响的,比如“订婚”这个事件类型,触发词不可能是“婚外情”。相反地,如果给的触发词是“婚期已定”,它对应的事件类型不可能是“出轨”。所以我们是通过联合模型来同时对事件类型和事件触发词进行学习,以进一步提升预测的准确率。
如下图所示,首先通过一个共享的编码层来对语义信息进行表示,输出层中,事件类型预测采用的是线性输出层,事件触发词识别采用的是一个CRF的输出层。
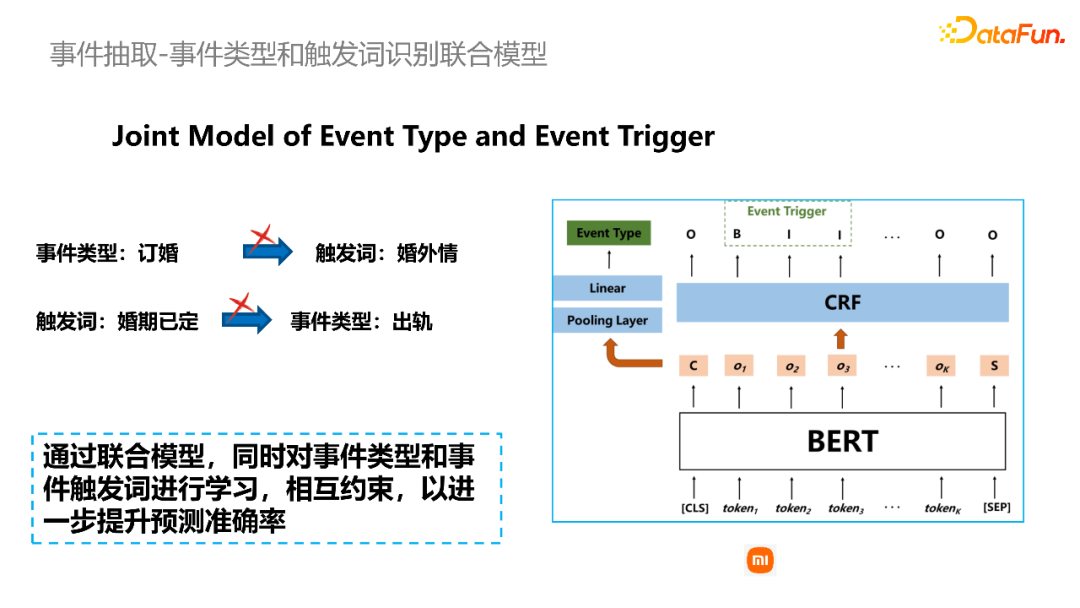
在识别得到事件类型和事件触发词之后,我们设计了并行模型进行要素抽取。第一个模型基于事件类型,第二个模型基于事件触发词。在基于事件类型的抽取模型当中,我们将第一步识别得到的事件类型,连接到输入的文本之前,再通过序列标注的方式来抽取对应的事件要素。
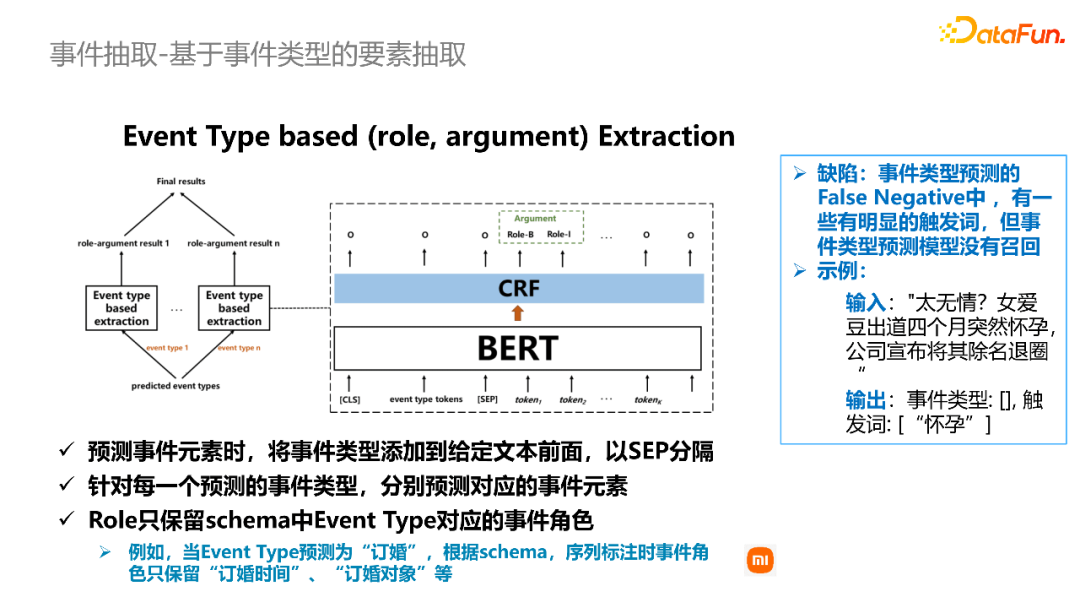
基于这种方式,我们发现结果会有一些欠召回的情形。比如上图右框中的例子,实际上这个句子中存在一个明显的触发词“怀孕”。但是事件类型预测模型就发生了欠召,没能识别出它的事件类型。这时候如果是基于事件触发词来对这个事件要素进行抽取,则可以和基于事件类型的模型进行互补。
第二种方式,基于事件触发词的要素抽取。首先利用抽取得到触发词,然后计算每个token到触发词的距离,将距离映射为向量表示,级联到语义的向量上,再接CRF层预测事件要素。
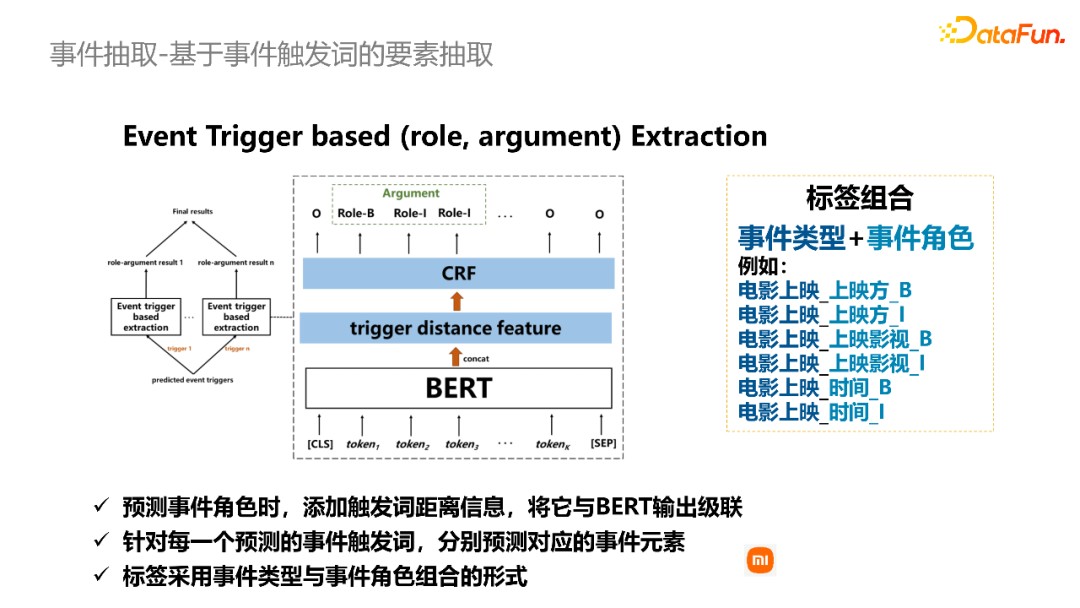
将这两种方式抽取的事件要素进行投票组合,得到最终的抽取结果。基于信息抽取模型得到的结构化知识,可以补充到知识图谱中,作为下游图谱问答的数据基础。
03
图谱问答
1. 基于文法解析的方法
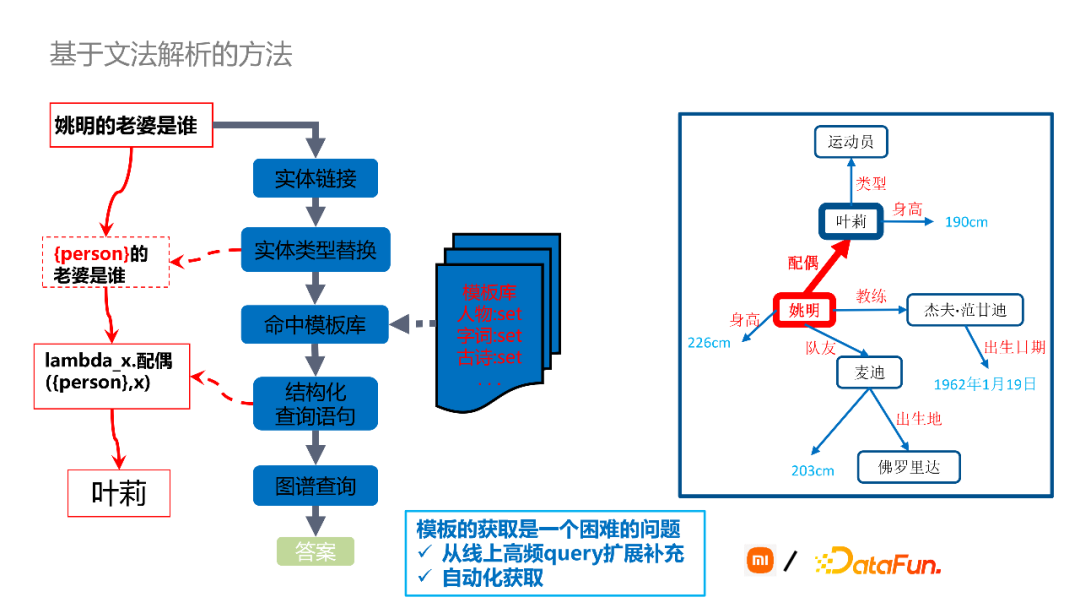
如下图,对用户query进行解析,从模板库中找到与用户query匹配的模板,再通过这个模板把用户非结构的query解析成为结构化的查询语句,进而从图谱中去查找得到答案。这个过程是比较简单的,但主要的问题在于如何高效快速的获取大批量的模板。一方面可以从线上高频query进行扩展补充,这是从业务出发的一种方式,能够尽快满足用户需求。第二种,可以通过挖掘的方式来自动化地获取。
2.跨垂域粗粒度的槽位抽取方法
该方法的泛化性能会相对更好。它的基模型是意图识别和槽位抽取的联合模型。通过这个联合模型,对用户query的意图和槽位同时进行识别,从而回答用户的问题。这种方式不依赖模板,所以泛化性更好。
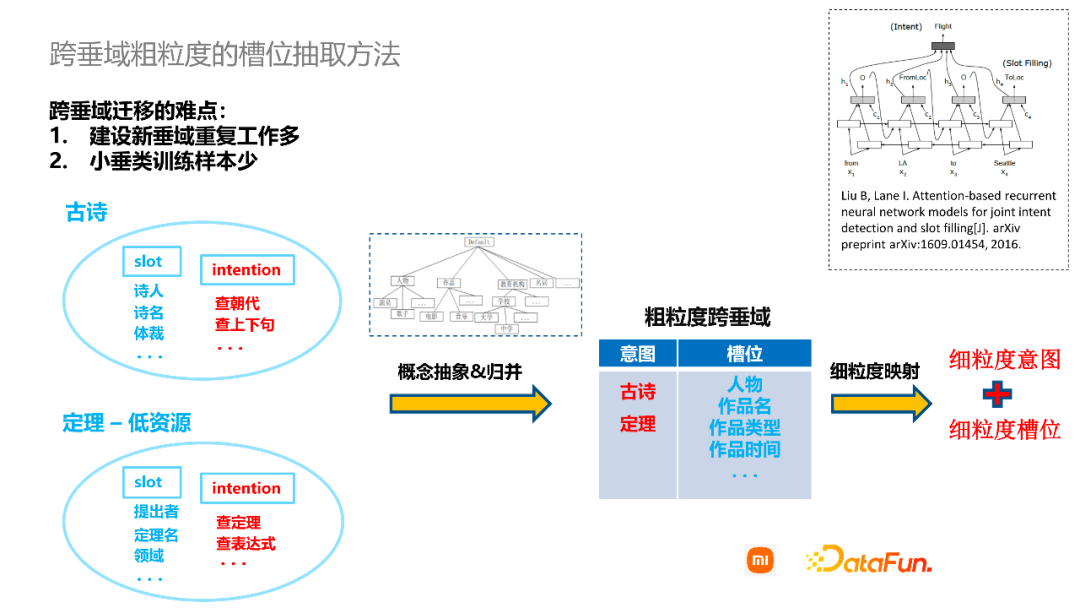
通过这种方式进行垂域建设有一些缺陷。比如建设好一个古诗垂域,它包含查朝代、查上下句等功能点,包含诗人、诗名、体裁等槽位,在这个意图和槽位体系之下,挖掘一些样本进行模型训练、线上部署,以回答用户在线上的问题。如果又需要建设一个新的垂域,比如数学定理垂域,这个垂域不仅是一个新的垂域,而且也是一个低资源垂域,那么我们不得不把古诗垂域建设的过程再重复一遍,而且小垂域的训练样本获取也比较困难。
所以我们提出了一个跨垂域粗粒度的意图识别和槽位抽取方法。具体来说,是将不同垂域涉及到的槽位根据概念图谱来进行抽象,比如诗人和提出者都属于人物,那么我就可以将诗人和提出者定义为人物这样一个槽位。诗名和定理名,可以认为都是作品名。除了合并的槽位之外,各个垂域还有一些特有的槽位,我们将它们直接保留下来。与此同时,也把细粒度的意图直接上升到粗粒度的意图。这样就可以联合不同垂域的样本,训练一个跨垂域粗粒度的模型。在这种跨垂域的模型中,定理垂域就可以利用古诗垂域的训练样本,实现领域知识的迁移。
在模型训练好之后,就可以在线上预测用户query的意图和槽位,最后通过映射关系,将粗粒度的槽位和意图映射到细粒度的意图和槽位之上,用于进行下一步的解析。
3. 基于路径检索的方法
基于路径检索的方式,不需要对用户query进行解析,而是先检索候选的路径,然后从中进行筛选找到正确的解析路径。这里主要介绍我们参加“CCKS2021生活服务领域知识图谱问答评测”的冠军方案。

这次评测任务的难点在带约束复杂query的问答,比如“北京故宫博物院附近2公里有哪些好玩?”或者“故宫附近5km内便宜的酒店是多少钱?”。
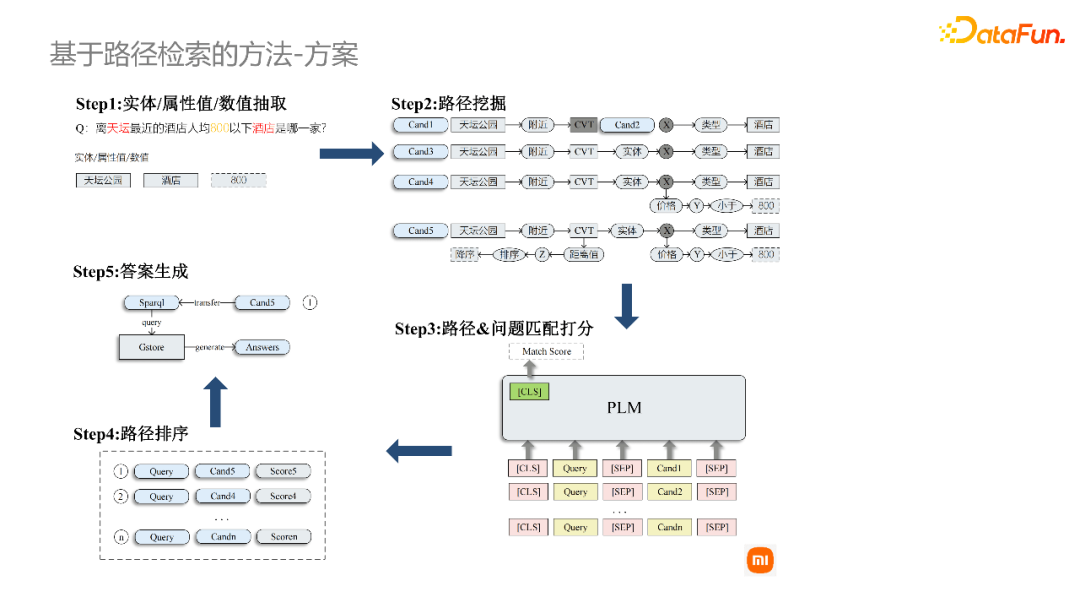
主要涉及两类约束,第一类约束是过滤约束,第二类约束是排序约束。对于这种带约束的复杂query,我们需要做特殊的处理。
整体来讲,我们采用的技术方案的流程为:第一步识别实体和属性值,第二步进行路径的挖掘,第三步进行匹配打分,第四步进行路径排序,最终根据最优路径从图谱中查询答案。
第一步我们需要从query当中找到这个问题涉及到的一些实体、属性值、数值,主要采用三类方式:
①基于AC算法的字面匹配,识别query中涉及到的字面值。
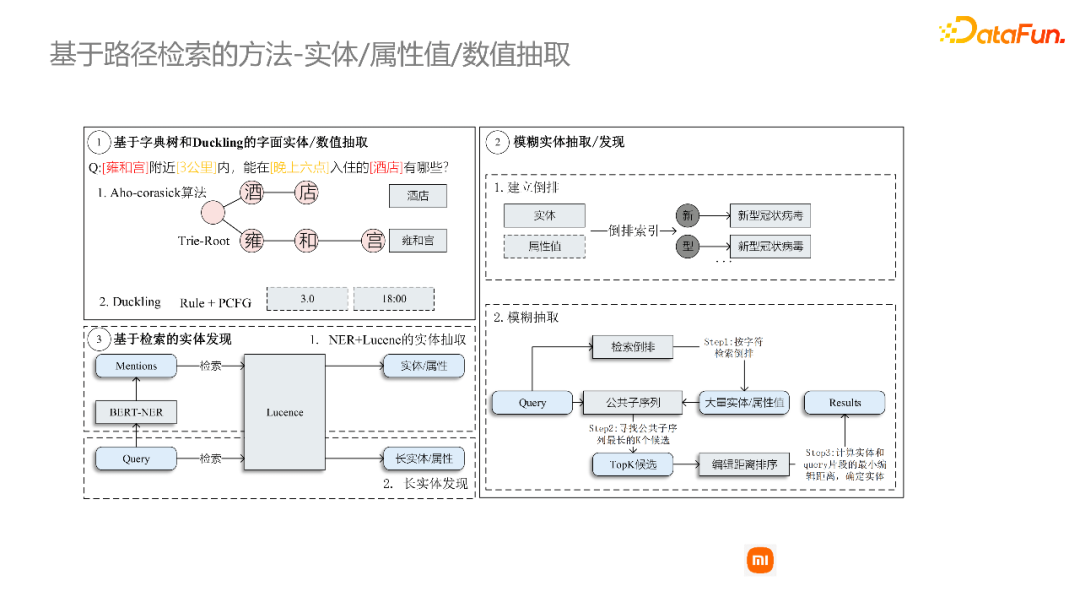
②模糊匹配。实际上用户query中有一些实体提及mention和图谱中实体名称并不完全一样。这时我们需要进行模糊匹配。通过建立倒排索引来找到和mention比较相关的候选实体,计算每个候选实体的编辑距离,来对候选实体进行排序。
③基于NER模型,来找到query当中可能涉及到的实体片段。
实体、属性值抽取是基础的一步,也是比较关键的一步,需要抽取到query中关键的语义信息。如果没有抽取到,后面路径无论如何扩展,都不能找到正确路径。
第二步,基于抽取得到的实体和属性值,进行路径的挖掘。路径挖掘主要包括两个步骤,首先是基础的路径扩展,接着是对复杂query进行约束挂载。
路径扩展,是以query中的抽取得到的实体为出发点,通过新增三元组来扩展路径。中间节点可以继续作为起始节点来新增三元组。同时我们可以将找到的不同路径,在中间节点相同的情况下进行组合,形成语义信息更丰富的一条路径。通过这种路径扩展和组合,尽可能多地挖掘候选路径,最大可能的将query对应的正确解析路径包含在候选队列当中。
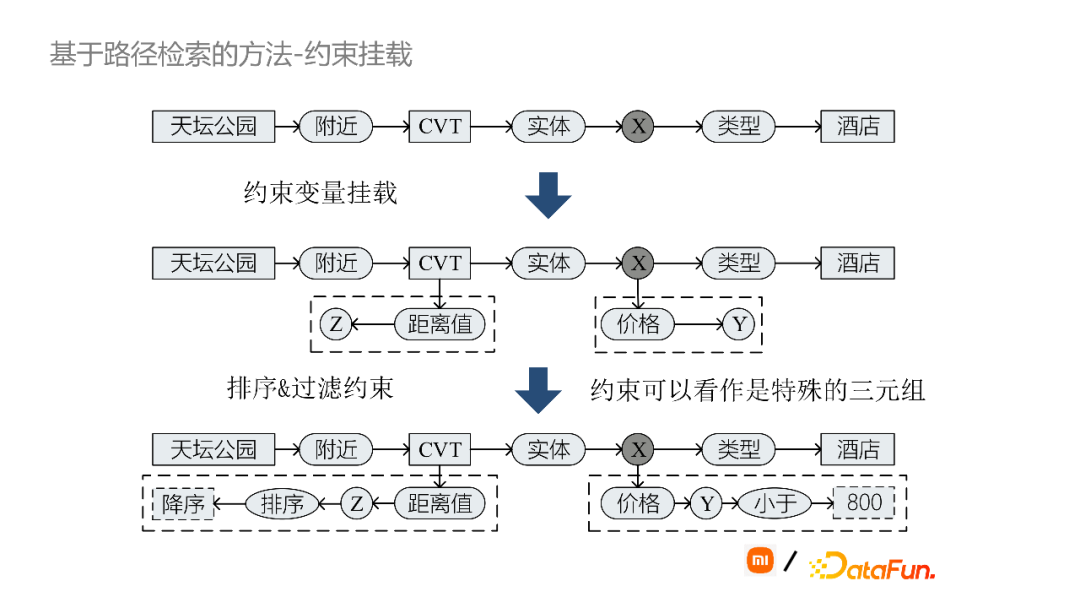
约束挂载如上图所示。“离天坛最近的酒店人均800以下酒店是哪一家”,首先通过路径扩展得到上图最上方所示的路径,然后进一步约束CVT节点对应的距离值,同时对酒店实体X的价格约束为小于800。通过上图方式,我们将约束可以看作一种特殊的三元组。比如要求价格小于800块钱,那么“小于”作为谓词,“800”就是作为object值。对于排序约束,将“排序”作为谓词,然后“降序”作为object。将约束信息统一处理成三元组是为了下一步路径匹配的需要。
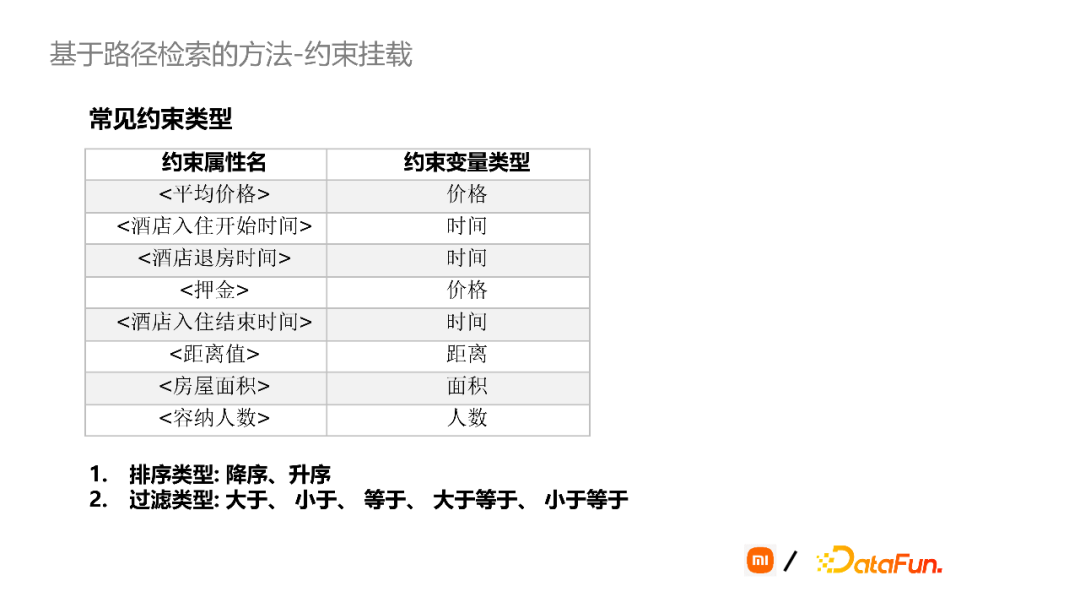
我们总结了可以加约束信息的常见属性,比如平均价格、酒店入住时间、押金、距离值、房屋面积等。在路径扩展过程中,如果发现某一个属性的取值是数值时,就可以对它进行约束挂载,从而表达出query中的复杂语义信息。
下一步是路径匹配。需要在候选路径中找到最有可能的路径。具体方法为:将路径表达成文本的形式,把它建模成一个语义匹配的任务。路径的文本表示,这里介绍三种方式:第一种方式是设计一个模板将路径表示为一句话;第二种方式是把这个路径中的subject、predicate以及答案节点拼接起来;第三种方式和第二种方式相似,但是把中间节点通过[UNK]字符保留下来。通过实验对比,这三种方式的匹配效果差异不大。选择任意一种方式皆可。

经过路径匹配排序之后,可以得到语义上和用户query最接近的候选路径,进一步还可以结合一些业务特征对候选路径进行重排序,最后从图谱中查找正确答案。
在评测结束之后,我们将这个方案在业务中进行了落地,落地时为了追求性能和效果的平衡,落地方案和前面稍有差别。在实体和属性值抽取时,通过实体链接来找到query当中的核心的实体。在路径挖掘时,自研了一套路径检索和路径挖掘的方式,能够提高路径挖掘的性能。得到候选路径后,我们会对候选路径的规模进行约束,比如取前20条候选路径进行语义匹配。最终输出排名第一的候选路径,从图谱中查找正确答案返回用户。
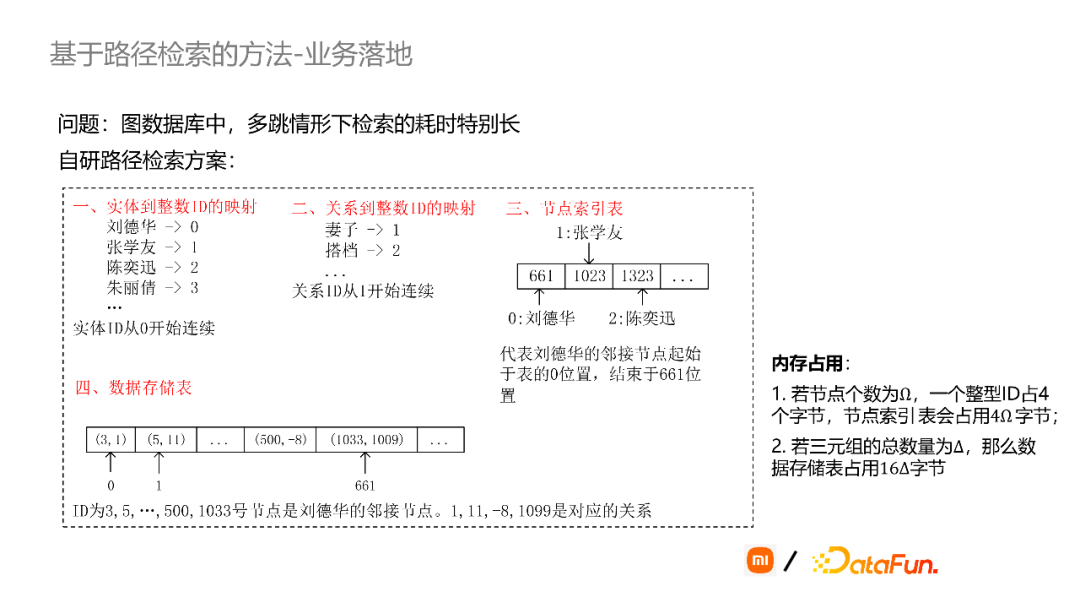
这里简单介绍一下我们自研的路径检索工具。我们将图谱里的实体和关系,进行整型id的映射,然后通过一个节点索引表来记录每个实体对应的SPO三元组,比如刘德华所对应的三元组的终止节点在661,也就是说找刘德华的三元组时,可以快速地在数据存储表中的第0位到第661位进行查找,这里的查找可以通过二分法进一步加速。通过这种方式使检索耗时大大减少,内存的占用也会非常的小。
最后我们列举了几个图谱问答的示意效果图。图谱问答的结果更适应结构化展示的需求,能满足精品化的产品需求,为用户提供更好的使用体验。
04
问答环节
Q:路径的设定是否能通过神经网络模型去训练获得,还是都需要人工去制定路径规则模板,有没有一些高效的方法去获取路径和规则的方法?
A:神经网络方法可以用于获取路径,有一些研究论文这么去做了。但是在产品中我们目前采用的还是人工定义的方式,一是因为这些人工定义的模板实际上可以覆盖线上绝大部分的真实需求,二是因为通过人工模板挖掘路径,耗时很小,更能适应线上性能的要求。
Q:关系抽取spo模型,对复杂o解析只需要考虑位置距离匹配吗?还需要考虑标签本身的概率吗?
A:在关系抽取里面,我们采用的是指针网络模型,它的优点是可以解决overlap问题,但缺点是解码时可能有多个index候选,因此需要通过一些策略来选择index,比如我们使用的位置距离特征。也可以采用其他的特征进行选择。
Q:事件要素抽取模型,对每个事件类型预测角色的时候,是把schema定义全部角色都用CRF预测出来?还是最后根据事件类型保留相关的角色?
A:在抽取事件要素时,并没有限定于第一步预测的事件类型,而是把所有可能的事件角色都抽取出来,然后再用第一步预测的事件类型进行筛选。
01/分享嘉宾

代文 博士
小米 高级算法工程师
代文,小米AI实验室知识图谱组智能问答业务负责人,2015年博士毕业于中科院自动化所。目前负责小爱同学产品的智能问答系统研发,研究方向包括图谱问答、检索问答、文档摘要、多轮问答等。具有丰富的NLP工作经验,曾获得信息抽取、图谱问答等多项竞赛的冠军。
02/关于 DataFun
DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,14万+精准粉丝。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。






