Selector选择器的详细介绍
在上一篇文章中为各位小伙伴简单的介绍了Selector,直接导入的方法就可以使用。这篇文章主要是Scrapy Shell和Xpath选择器为大家带来更加详细的使用方法。
scrapy shell
我们可以借助scrapy shell来模拟请求过程,然后把一些可以操作的变量传递回来,比如:resquest、response等。
PS C:\Users\admin\Desktop> scrapy shell https://www.baidu.com --nolog
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x00000142EEF861F0>
[s] item {}
[s] request <GET https://www.baidu.com>
[s] response <200 https://www.baidu.com>
[s] settings <scrapy.settings.Settings object at 0x00000142EEF864C0>
[s] spider <DefaultSpider 'default' at 0x142ef446400>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]:
从上面的代码我们会发现,返回了很多可以供我们操作的变量。
我们来看看,返回的URL值是什么:
In [1]: response.url
Out[1]: 'https://www.baidu.com'
取出百度标题的文本信息:
In [2]: response.xpath('/html/head/title/text()').get()
Out[2]: '百度一下,你就知道'
取出当前页面所有的链接文本:
In [3]: response.xpath('//a/text()').getall()
Out[3]:
['新闻','hao123','地图','视频','贴吧','登录','更多产品','关于百度','About Baidu','使用百度前必读','意见反馈']
取出当前页面所有的超链接:
In [4]: response.xpath('//a/@href').getall()
Out[4]:
['http://news.baidu.com','https://www.hao123.com','http://map.baidu.com','http://v.baidu.com','http://tieba.baidu.com','http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1','//www.baidu.com/more/','http://home.baidu.com','http://ir.baidu.com','http://www.baidu.com/duty/','http://jianyi.baidu.com/']
get()函数是返回所有结果的第一个结果;而getall()函数是返回全部结果。
当然,我们也可以使用extract_first()返回所有结果的第一个结果;而使用extract()方法则返回全部结果。
使用Xpath选择器
response.selector属性返回的内容相当于response的body构造了一个Selector对象。
Selector对象可以调用Xpath()实现信息的解析与提取。
现在我们来获取淘宝网–>商品分类–>特色市场的信息:
PS C:\Users\admin\Desktop> scrapy shell https://huodong.taobao.com/wow/tbhome/act/special-markets --nolog
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x00000186B0D061F0>
[s] item {}
[s] request <GET https://huodong.taobao.com/wow/tbhome/act/special-markets>
[s] response <200 https://huodong.taobao.com/wow/tbhome/act/special-markets>
[s] settings <scrapy.settings.Settings object at 0x00000186B0D06280>
[s] spider <DefaultSpider 'default' at 0x186b11b4670>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
打开页面之后,如下图所示:

现在我想要获取到每一个板块的标题信息。
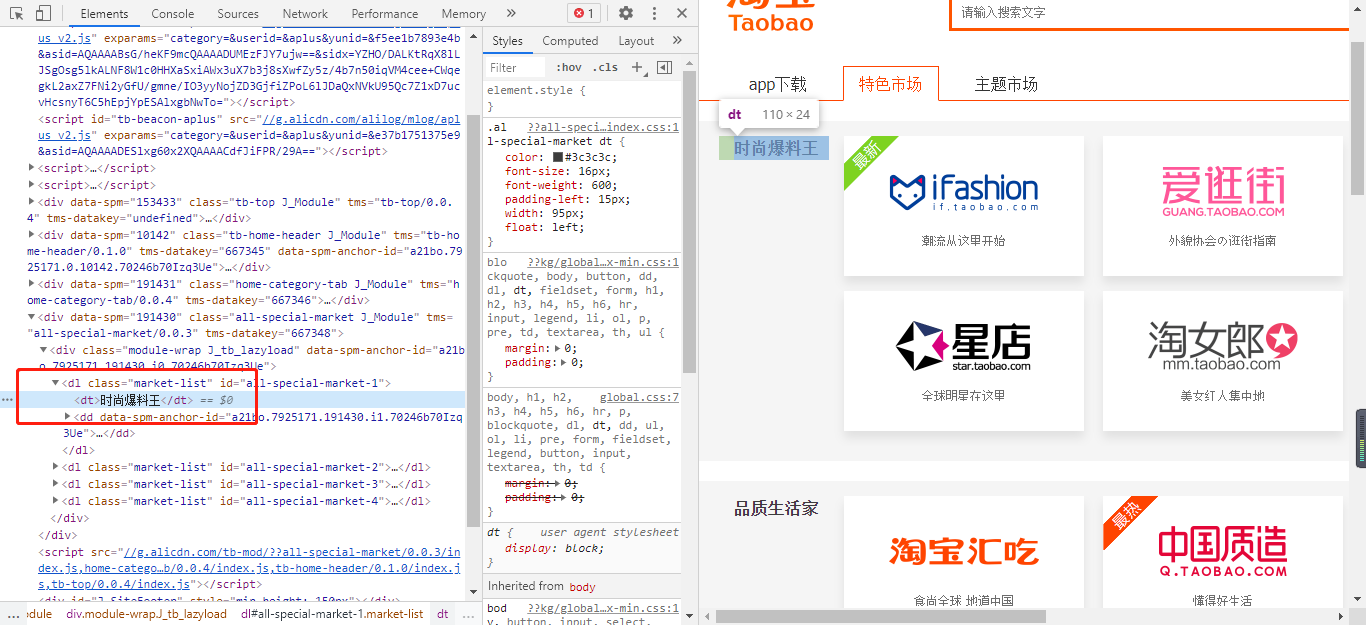
在上图,你会发现这些信息存在于dt这个标签内。具体代码如下所示:
In [1]: response.selector.xpath('//dt/text()')
Out[1]:
[<Selector xpath='//dt/text()' data='时尚爆料王'>,<Selector xpath='//dt/text()' data='品质生活家'>,<Selector xpath='//dt/text()' data='特色玩味控'>,<Selector xpath='//dt/text()' data='实惠专业户'>]In [2]: response.selector.xpath('//dt/text()').extract()
Out[2]: ['时尚爆料王', '品质生活家', '特色玩味控', '实惠专业户']
如果我们除了将每个板块的标题与板块内的标题提取出来,那这段代码应该怎么样写呢?

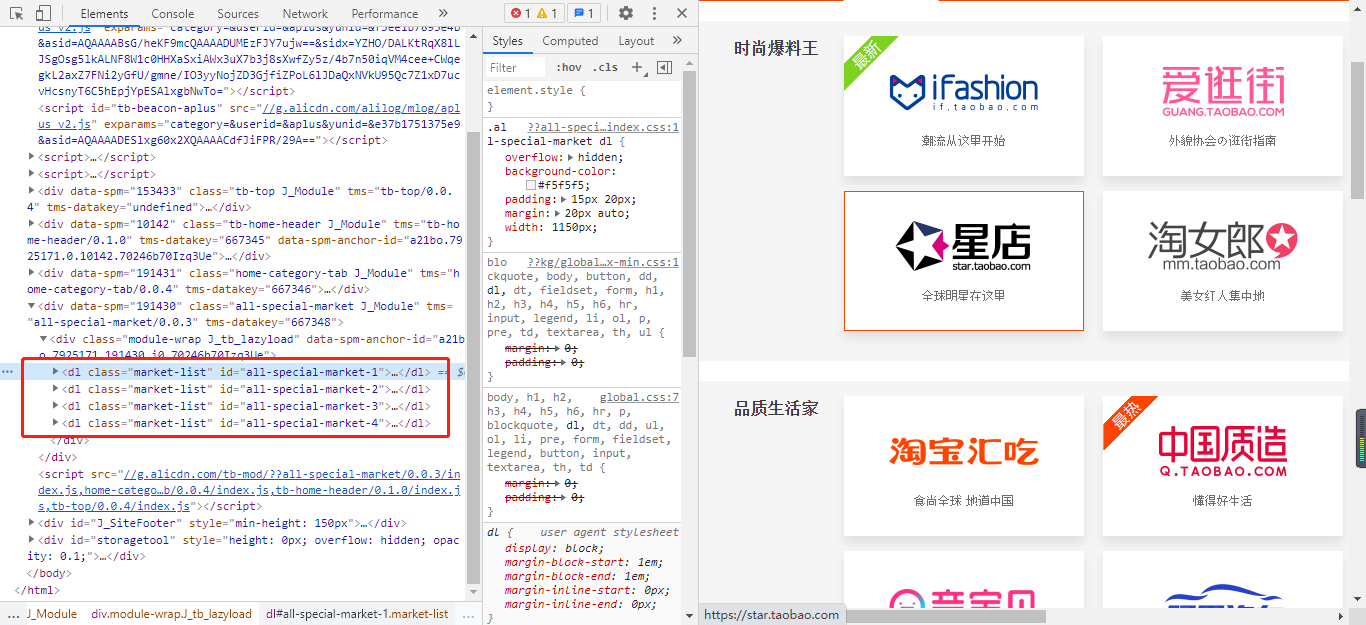
从上图中可以看到,每一个大的板块都在dl标签内部。
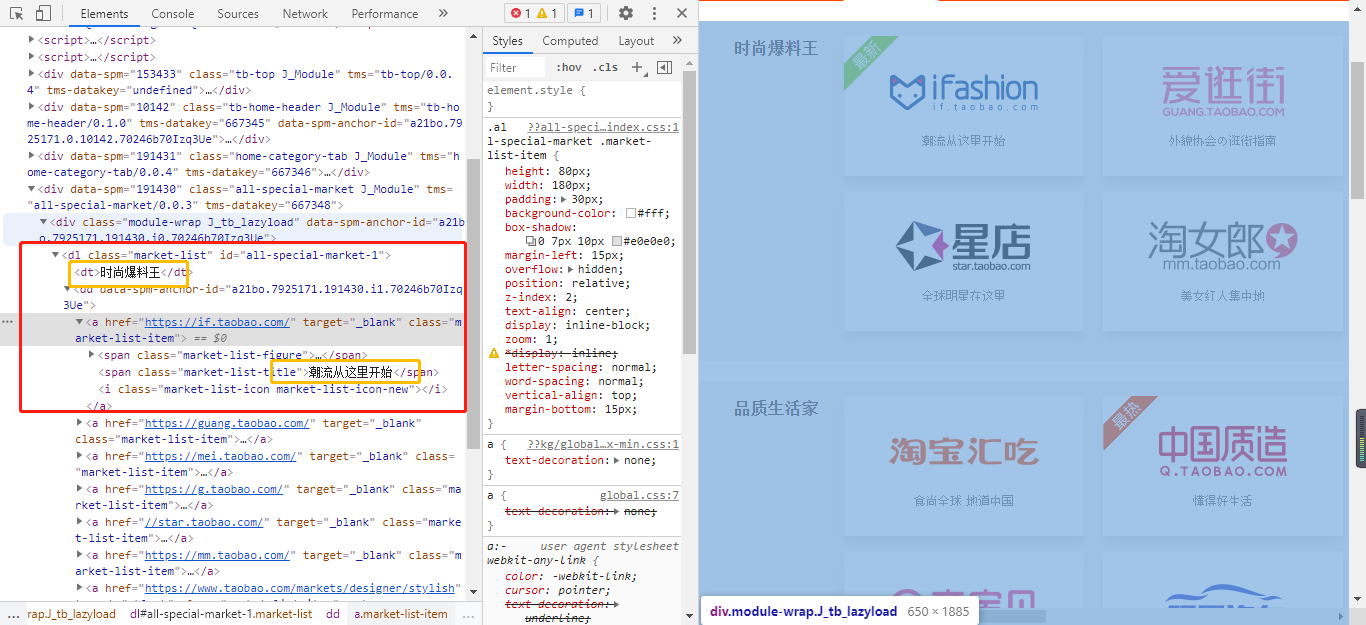
具体代码如下所示:
In [7]: for dl in dllist:...: print(dl.xpath('./dt/text()').extract_first())...: print("="*50)...: alist = dl.xpath('.//a')...: for a in alist:...: print(a.xpath('./@href').extract_first(),':', end='')...: print(a.xpath('.//span[@class="market-list-title"]/text()').extract_first())...:
时尚爆料王
==================================================
https://if.taobao.com/ :潮流从这里开始
https://guang.taobao.com/ :外貌协会の逛街指南
https://mei.taobao.com/ :妆 出你的腔调
https://g.taobao.com/ :探索全球美好生活
//star.taobao.com/ :全球明星在这里
https://mm.taobao.com/ :美女红人集中地
https://www.taobao.com/markets/designer/stylish :全球创意设计师平台
品质生活家
==================================================
https://chi.taobao.com/chi/ :食尚全球 地道中国
//q.taobao.com :懂得好生活
https://www.jiyoujia.com/ :过我想要的生活
https://www.taobao.com/markets/sph/sph/sy :尖货奢品品味选择
https://www.taobao.com/markets/qbb/index :享受育儿生活新方式
//car.taobao.com/ :买车省钱,用车省心
//sport.taobao.com/ :爱上运动每一天
//zj.taobao.com :匠心所在 物有所值
//wt.taobao.com/ :畅享优质通信生活
https://www.alitrip.com/ :比梦想走更远
特色玩味控
==================================================
https://china.taobao.com :地道才够味!
https://www.taobao.com/markets/3c/tbdc :为你开启潮流新生活
https://acg.taobao.com/ :ACGN 好玩好看
https://izhongchou.taobao.com/index.htm :认真对待每一个梦想。
//enjoy.taobao.com/ :园艺宠物爱好者集中营
https://sf.taobao.com/ :法院处置资产,0佣金捡漏
https://zc-paimai.taobao.com/ :超值资产,投资首选
https://paimai.taobao.com/ :想淘宝上拍卖
//xue.taobao.com/ :给你未来的学习体验
//2.taobao.com :让你的闲置游起来
https://ny.taobao.com/ :价格实惠品类齐全
实惠专业户
==================================================
//tejia.taobao.com/ :优质好货 特价专区
https://qing.taobao.com/ :品牌尾货365天最低价
https://ju.taobao.com/jusp/other/mingpin/tp.htm :奢侈品团购第一站
https://ju.taobao.com/jusp/other/juliangfan/tp.htm?spm=608.5847457.102202.5.jO4uZI :重新定义家庭生活方式
https://qiang.taobao.com/ :抢到就是赚到!
https://ju.taobao.com/jusp/nv/fcdppc/tp.htm :大牌正品 底价特惠
https://ju.taobao.com/jusp/shh/life/tp.htm? :惠聚身边精选好货
https://ju.taobao.com/jusp/sp/global/tp.htm?spm=0.0.0.0.biIDGB :10点上新 全球底价
https://try.taobao.com/index.htm :总有新奇等你发现
使用CSS选择器
接下来,我们使用scrapy shell爬取淘宝网–>商品分类–>主题市场的信息
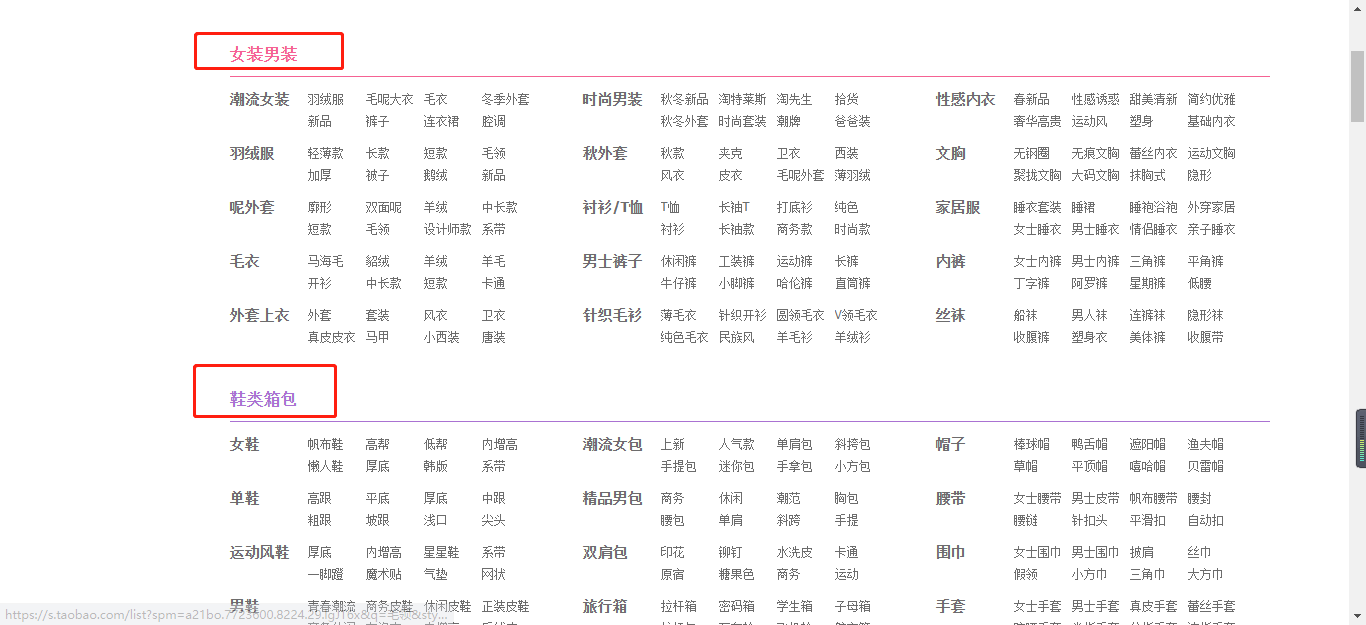
同样的,我们需要拿到每个板块的标题信息,具体代码如下所示:
for dd in dlist:...: print(dd.css('a.category-name-level1::text').get())...:
女装男装
鞋类箱包
母婴用品
护肤彩妆
汇吃美食
珠宝配饰
家装建材
家居家纺
百货市场
汽车·用品
手机数码
家电办公
更多服务
生活服务
运动户外
花鸟文娱
农资采购
和上面的代码相同的,相信聪明的你也可以把每个板块下的标题文本也抓取下来的对吧。
相信这个的文章,你有更加的了解到scrapy提取数据的方式了吧!!
最后
没有什么事情是可以一蹴而就的,生活如此,学习亦是如此!
因此,哪里会有什么三天速成,七天速成的说法呢?
唯有坚持,方能成功!
啃书君说:
文章的每一个字都是我用心敲出来的,只希望对得起每一位关注我的人。在文章末尾点【赞】,让我知道,你们也在为自己的学习拼搏和努力。
路漫漫其修远兮,吾将上下而求索。
我是啃书君,一个专注于学习的人,你懂的越多,你不懂的越多。更多精彩内容,我们下期再见!