说明:三层架构开发时目前开发的主流,我这里通过一个案例,来分析非三层架构开发的不利之处,以及三层架构开发的好处。
案例说明:打开员工信息页,页面要显示所有员工的信息;前端页面已提供,后端通过读取本地emp.xml文件,显示员工信息或者提供本地资源(图片资源存放在项目中的resources文件夹中)的路径返回给前端,以此来模拟实际的开发流程(实际开发信息是放在数据库中的)。
分析:后端需要做的,就是读取员工信息,封装成一个对象,返回给前端。
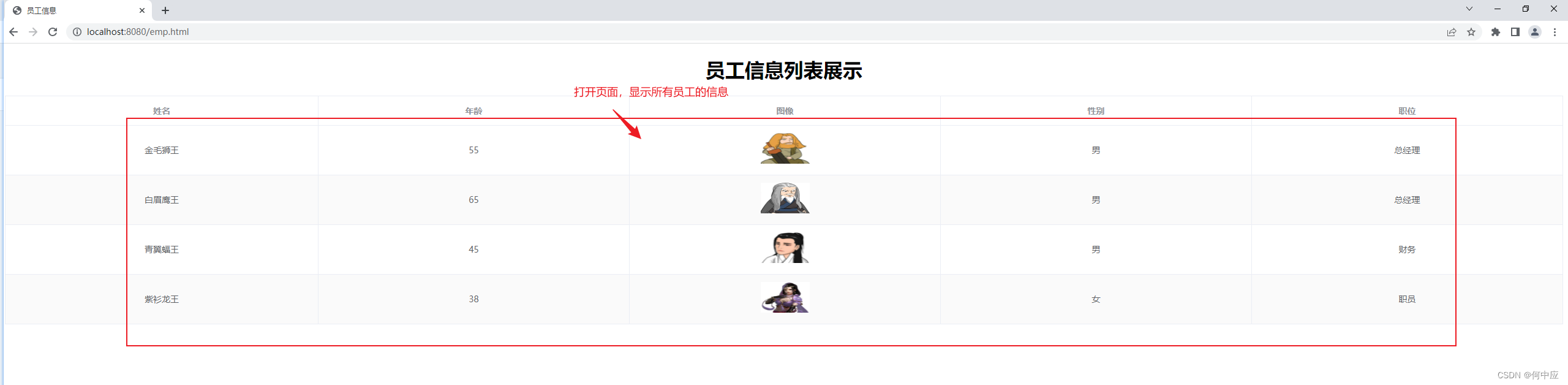
前端页面如下,需要注意axios.get()中的地址,表示后台查询员工所有信息的方法所需要的映射地址要与这个一致。
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>员工信息</title>
</head><link rel="stylesheet" href="element-ui/index.css">
<script src="./js/vue.js"></script>
<script src="./element-ui/index.js"></script>
<script src="./js/axios-0.18.0.js"></script><body><h1 align="center">员工信息列表展示</h1><div id="app"><el-table :data="tableData" style="width: 100%" stripe border ><el-table-column prop="name" label="姓名" align="center" min-width="20%"></el-table-column><el-table-column prop="age" label="年龄" align="center" min-width="20%"></el-table-column><el-table-column label="图像" align="center" min-width="20%"><template slot-scope="scope"><el-image :src="scope.row.image" style="width: 80px; height: 50px;"></el-image></template></el-table-column><el-table-column prop="gender" label="性别" align="center" min-width="20%"></el-table-column><el-table-column prop="job" label="职位" align="center" min-width="20%"></el-table-column></el-table></div>
</body><style>.el-table .warning-row {background: oldlace;}.el-table .success-row {background: #f0f9eb;}
</style><script>new Vue({el: "#app",data() {return {tableData: []}},mounted(){axios.get('/listEmp2').then(res=>{if(res.data.code){this.tableData = res.data.data;}});},methods: {}});
</script>
</html>
资源放在resources文件夹下
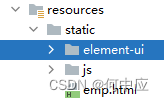
存放员工信息的emp.xml文件放在桌面文件夹里
统一响应结果
开始之前,先介绍一下统一响应结果。因为后端返回给前端的数据,数据类型是不可确定的,不可能每次都前后端开发人员沟通协商,这样就增加了沟通的成本。所以,可以做一个约定,后端把反馈的结果封装成一个对象,对象的属性里有:请求处理状态、请求的信息、数据三个属性。以后所有的请求,反馈结果的都是这样一个对象。前端开发人员就可以通过对象的值判断请求是否处理成功、提示什么信息、以及附带的数据,以供使用。
package com.essay.utils;/*** 统一响应结果*/
public class Result {/*** 请求状态:1表示成功、0表示失败*/private Integer code;/*** 请求信息*/private String msg;/*** 数据*/private Object data;/* set()、get()、toString()方法 *//*** 请求失败的处理方案* @param msg 失败信息* @return*/public static Result error(String msg) {Result result = new Result();result.setCode(0);result.setMsg(msg);return result;}/*** 请求成功的处理方案* @param msg 成功信息* @param obj 数据* @return*/public static Result success(String msg, Object obj) {Result result = new Result();result.setCode(1);result.setMsg(msg);result.setData(obj);return result;}
}将这个类,放在项目的utils包中,同时还需要一个解析xml文件的工具类(这里面的代码不是本文的重点,只需知道是用来解析xml文件的就行)

pom.xml文件中需要添加依赖(SpringBoot依赖、解析xml文件工具类所需的依赖)
<!--springboot项目--><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.12</version><relativePath/></parent><dependencies><!--页面项目所需依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--解析xml文件所需依赖--><dependency><groupId>org.dom4j</groupId><artifactId>dom4j</artifactId><version>2.1.3</version></dependency></dependencies>
非三层架构开发
接下来,用非三层架构的方式,来实现这个查询所有员工信息的功能;
第一步:创建Emp类
package com.essay.domain;public class Emp {private String name;private Integer age;private String image;private String gender;private String job;public Emp() {}public Emp(String name, Integer age, String image, String gender, String job) {this.name = name;this.age = age;this.image = image;this.gender = gender;this.job = job;}/* set()、get()、toString()方法 */
}
第二步:创建EmpComtroller类和启动类
EmpComtroller类,即实现查询员工所有信息功能的类
package com.essay.web;import com.essay.domain.Emp;
import com.essay.utils.Result;
import com.essay.utils.XmlParserUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController
public class EmpContorller {@RequestMapping("/listEmp")public Result listEmp() {// 读取emp.xml文件中的信息String path = "C:\\Users\\1\\Desktop\\Emp\\emp.xml";List<Emp> list = XmlParserUtils.parse(path, Emp.class);// 将返回的员工信息集合封装成Result对象,返回给前端return Result.success("成功", list);}
}
启动类
package com.essay;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class Start {public static void main(String[] args) {SpringApplication.run(Start.class, args);}
}
第三步:启动
功能做完,启动项目
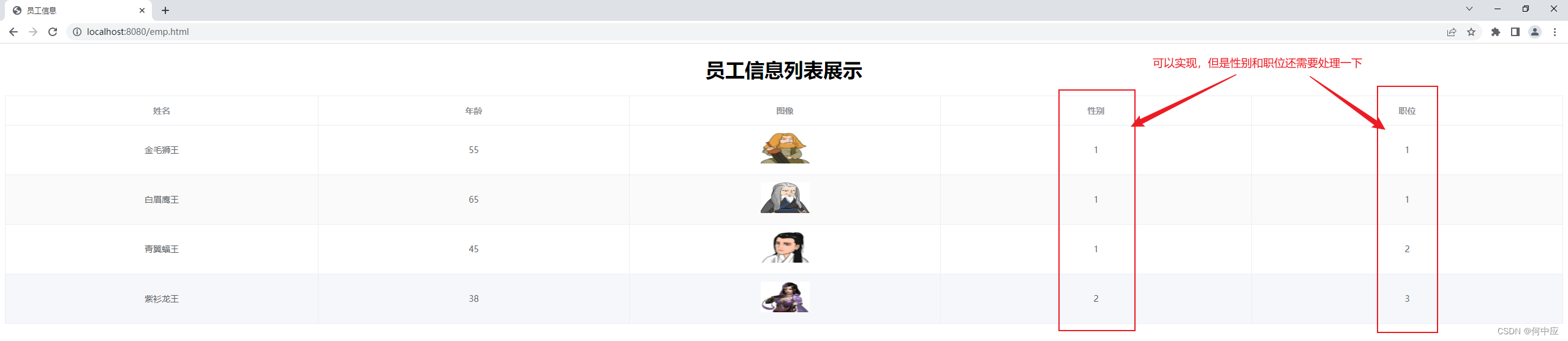
可以看到,功能实现了,只是员工的信息中,性别、职务分别是用数字表示的(以后数据库中也是类似这样表示的),因此还需对返回的数据进一步处理。比如性别中1表示男性,2表示女性;职务中,1表示总经理、2表示部门经理之类的;
@RequestMapping("/listEmp")public Result listEmp() {// 读取emp.xml文件中的信息String path = "C:\\Users\\1\\Desktop\\Emp\\emp.xml";List<Emp> list = XmlParserUtils.parse(path, Emp.class);// 对集合中的数据进行处理list.stream().forEach(emp -> {if ("1".equals(emp.getGender())){emp.setGender("男性");}if ("2".equals(emp.getGender())){emp.setGender("女性");}if ("1".equals(emp.getJob())){emp.setJob("总经理");}if ("2".equals(emp.getJob())){emp.setJob("部门经理");}if ("3".equals(emp.getJob())){emp.setJob("组员");}});// 将返回的员工信息集合封装成Result对象,返回给前端return Result.success("成功", list);}
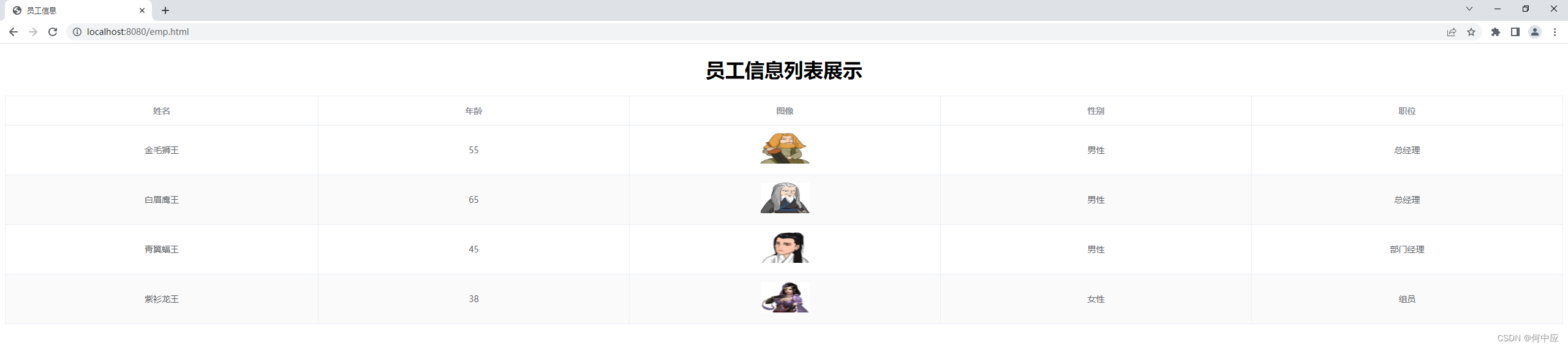
处理后重新启动,可以看到,达到预想的结果了。
小结
目前的开发结构,可以看出功能内的代码逻辑性差,结构松散,违背单一职责原则,业务稍有改动,类中的代码都需要同步修改(比如xml文件路径更改了,职务中的数字表示的含义发生变化了,类中的代码都有同步修改),这是非三层架构开发的缺点。
分析
通过分析以上代码,一个查询功能的操作分为三步:
第一步,读取xml文件(访问数据库),获取员工信息;【数据访问层】
第二步,对数据进行处理,将员工信息中的性别、职务转换为文字表述;【业务逻辑层】
第三步,将查询结果封装成一个Result对象,返回给前端;【控制层/页面层】
如果以后所有的请求都按照这三步来划分,将请求一层一层去处理。就便于管理代码,提高代码的维护性,这就是三层架构开发。
三层架构开发
在前面的基础上,把查询员工信息功能的代码分成三部分:
控制层/页面层(Controller):接收请求,调用业务逻辑对象处理,返回处理结果;
业务逻辑层(Service):调用数据访问对象查询数据,处理数据;
数据访问层(Dao):解析emp.xml文件,读取员工信息;
修改代码如下:
控制层/页面层(Controller):接收请求,响应数据
import com.essay.domain.Emp;
import com.essay.service.EmpService;
import com.essay.service.impl.EmpServiceImpl;
import com.essay.utils.Result;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;/*** 控制层/页面层(Controller)*/
@RestController
public class EmpContorller {/*** 创建业务逻辑对象*/private EmpService empService = new EmpServiceImpl();@RequestMapping("/listEmp")public Result listEmp() {// 调用service去处理逻辑List<Emp> list = empService.listEmp();// 返回响应结果return Result.success("成功", list);}
}
业务逻辑层(Service):逻辑处理
import com.essay.dao.EmpDao;
import com.essay.dao.impl.EmplDaoImpl;
import com.essay.domain.Emp;
import com.essay.service.EmpService;import java.util.List;/*** 业务逻辑层(Service)*/
public class EmpServiceImpl implements EmpService {/*** 创建数据访问对象*/private EmpDao empDao = new EmplDaoImpl();/*** 处理查询所有员工的业务*/@Overridepublic List<Emp> listEmp() {// 数据来源于DaoList<Emp> list = empDao.listEmp();// 对集合中的数据进行处理list.stream().forEach(emp -> {if ("1".equals(emp.getGender())) {emp.setGender("男性");}if ("2".equals(emp.getGender())) {emp.setGender("女性");}if ("1".equals(emp.getJob())) {emp.setJob("总经理");}if ("2".equals(emp.getJob())) {emp.setJob("财务");}if ("3".equals(emp.getJob())) {emp.setJob("组员");}});return list;}
}
数据访问层(Dao):数据访问
import com.essay.dao.EmpDao;
import com.essay.domain.Emp;
import com.essay.utils.XmlParserUtils;import java.util.List;/*** 数据访问层(Dao)*/
public class EmplDaoImpl implements EmpDao {@Overridepublic List<Emp> listEmp() {// 读取emp.xml文件中的信息String path = "C:\\Users\\1\\Desktop\\Emp\\emp.xml";List<Emp> list = XmlParserUtils.parse(path, Emp.class);return list;}
}
实际上,会给业务逻辑层(Service)、数据访问层(Dao)各自创建一个接口,让其实现类去执行操作;
业务逻辑对象(Service)接口
import com.essay.domain.Emp;import java.util.List;/*** 业务逻辑对象(Service)接口*/
public interface EmpService {/*** 查询所有员工信息* @return*/List<Emp> listEmp();
}
数据访问层(Dao)接口
import com.essay.domain.Emp;import java.util.List;/*** 数据访问对象接口*/
public interface EmpDao {/*** 查询所有员工信息* @return*/List<Emp> listEmp();
}
增加注解
虽然使用了三层架构,但层与层之间的耦合性还是很高的,如果项目中开发了多套ServiceImpl(业务处理方案),想要在多套处理方案中切换的话,就只能修改代码,手动选择其中的一套。

这时就可以使用Spring提供的注解,来帮我们自动创建、使用对象,
@Repository注解:表示当前类为数据访问层对象

@Service注解:表示当前类为业务逻辑层对象

@Controller注解:表示当前类为控制/页面层对象(@RestController包括了@Controller,所以使用@RestController也可以)
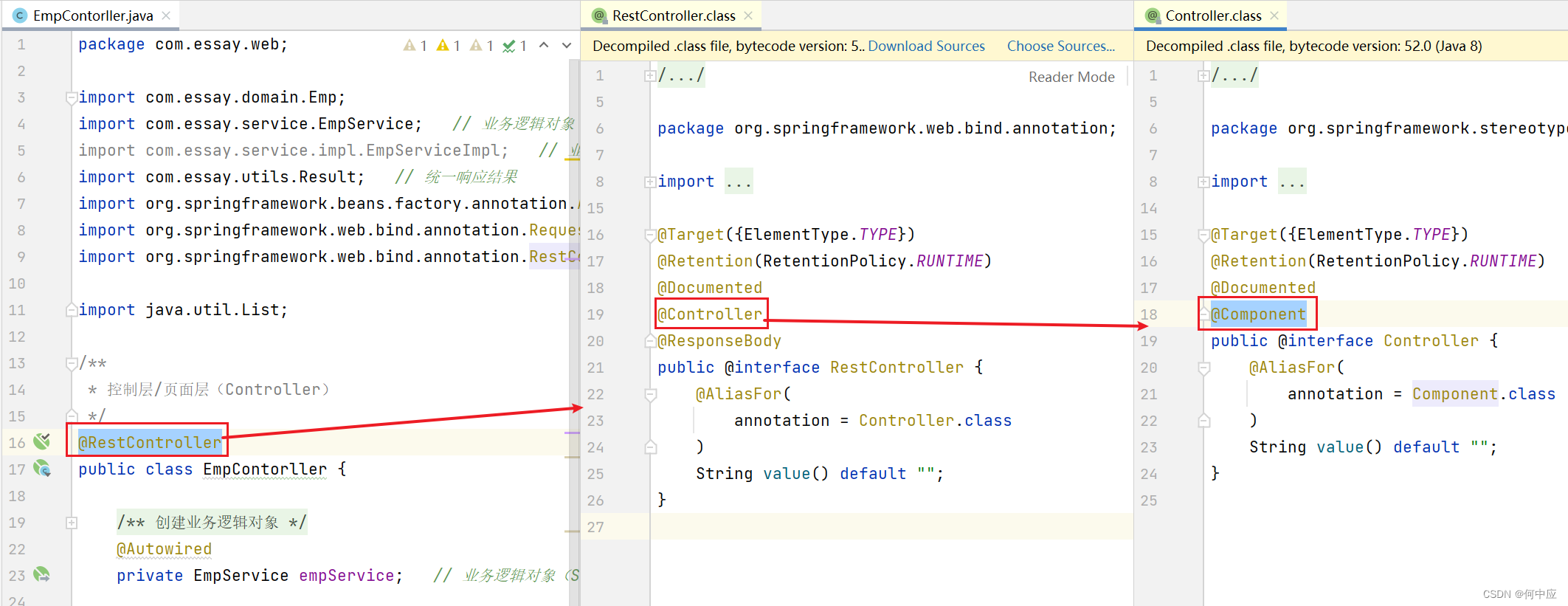
然后需要创建对象时,使用@AutoWired注解,程序会自动根据类型寻找对应的类对象


启动
大功告成,启动
到此,基于SpringBoot的三层架构开发的查询所有员工信息的功能就完成了。
控制反转&依赖注入
上面所用到的注解,是Spring的一个特性,即控制反转&依赖注入。
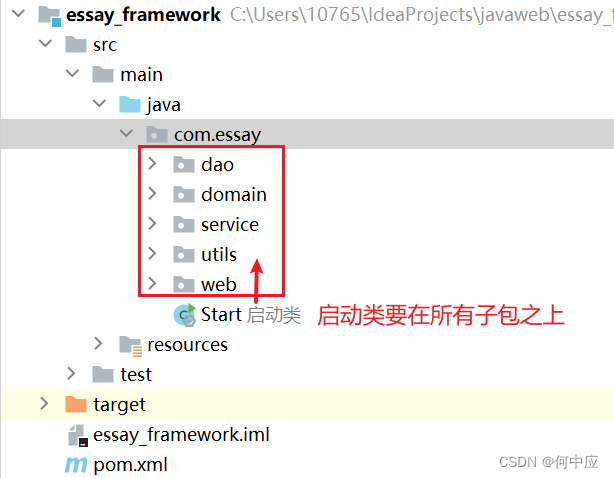
在程序启动时,启动类会扫描本包和子包,识别到对应注解(@Service、@Repository等)的类,将类创建到IOC容器中,这个过程称为控制反转;之后在需要使用到对象时(@Autowired),会从IOC容器中取出来,这个过程称为依赖注入。
因为启动类启动时只会扫描子包,所以启动类不能放在某个包里面,或者说启动类要在所有子包之上,否则本包之外和启动类之上的包中标记的注解不会生效。
启动程序后,可以在Actuator的Beans中找到我们三层架构的类对象;
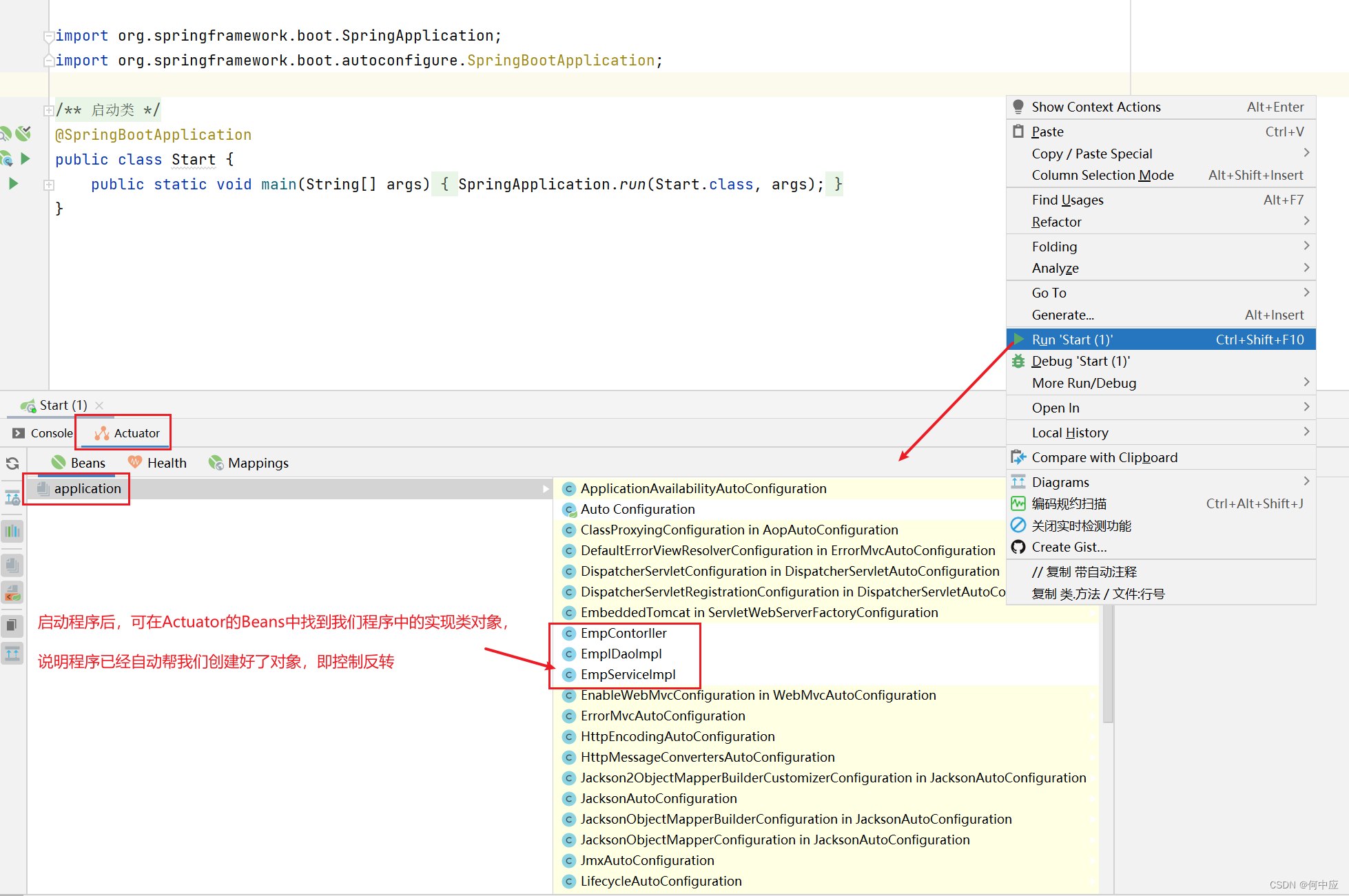
@Autowired注解,默认是按照类型进行,如果存在多个相同类型的bean,程序会报错
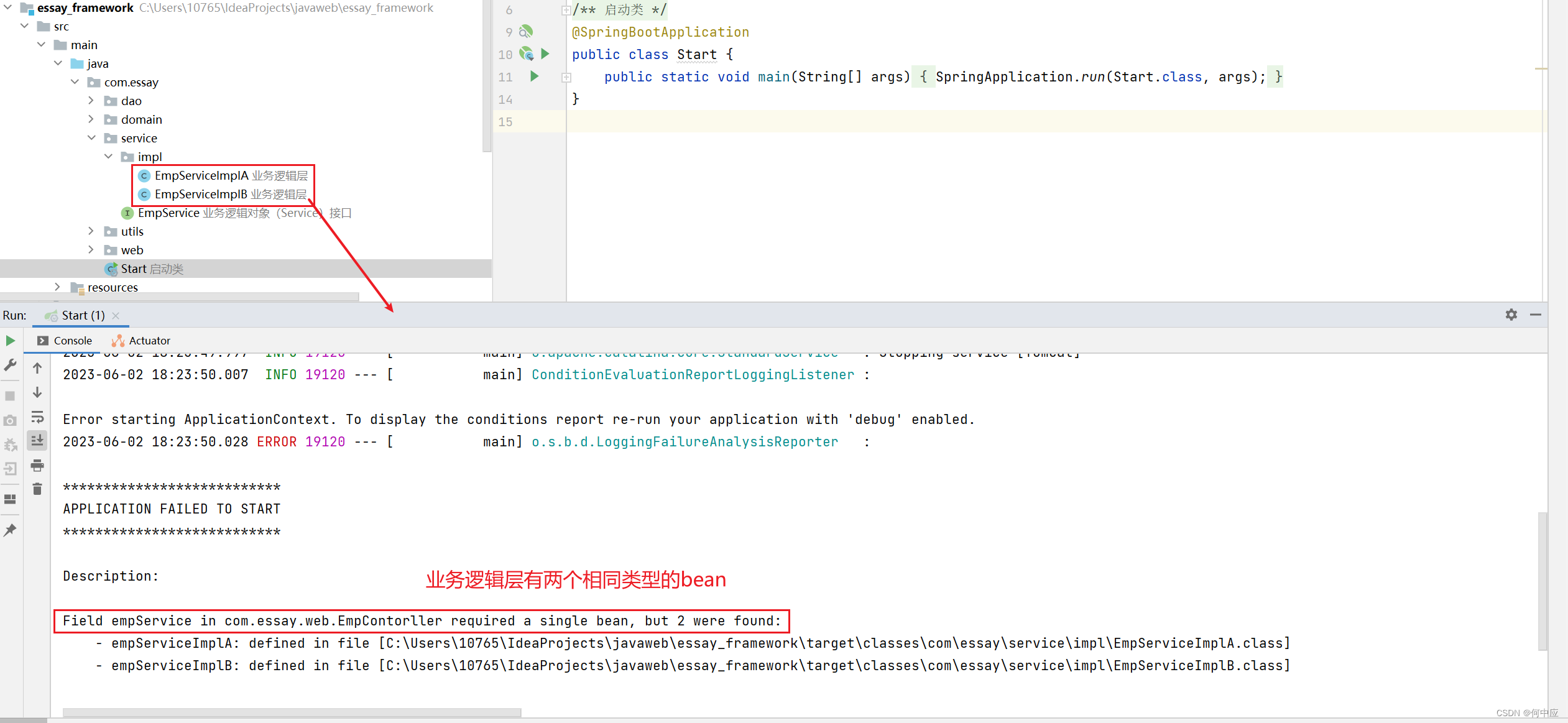
可以通过以下方式解决:
(1)使用@Primary注解,设置“主要的bean”,发生重名时,优先使用该bean;

(2)使用@Qualifier注解,指名取指定的bean;如果类没有设置名称的话,@Qualifier里面填需要使用的bean类名(bean名为类名的首字母小写)
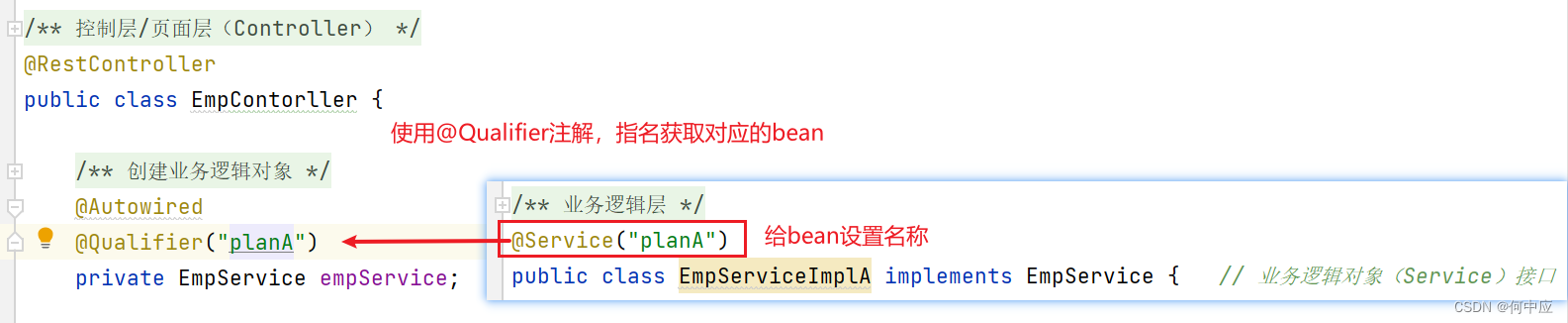
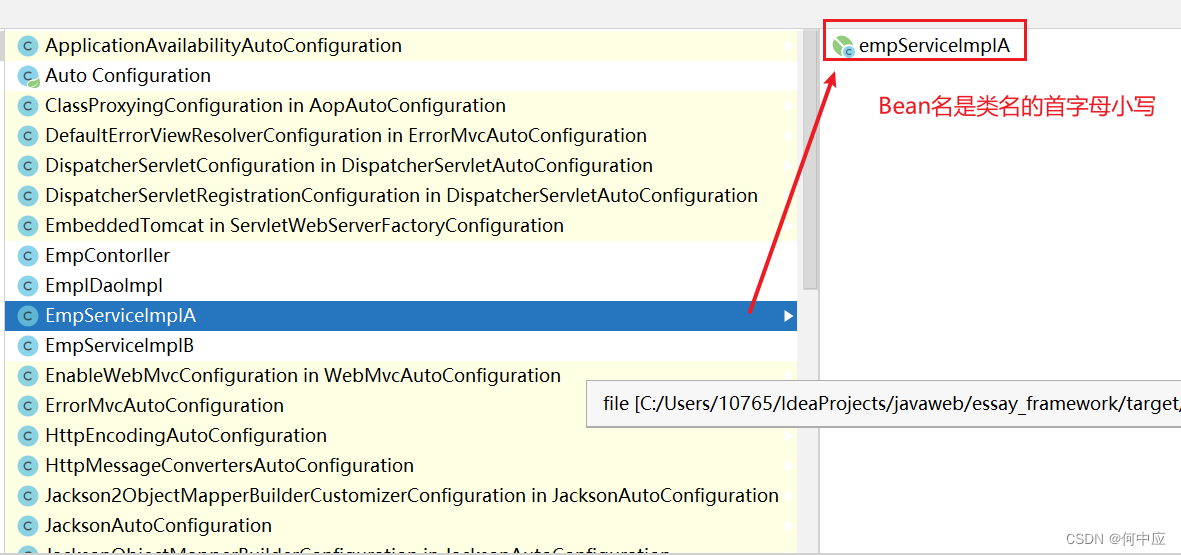
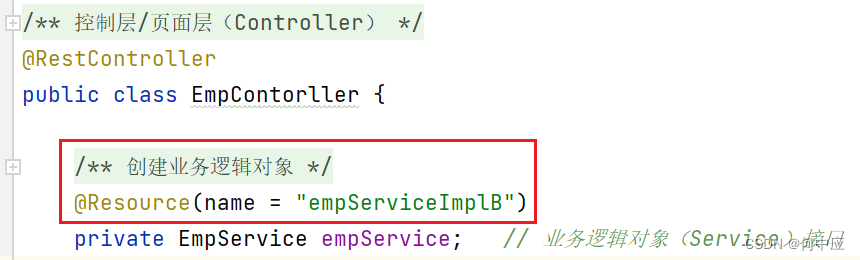
(3)使用JDK的@Resource注解,指名取指定的类对象;因为不属于Spring的注解,故不推荐使用;
总结
三层架构开发,把一个前端请求分为三个部分,层层递进,增强了代码的逻辑,提高了代码的复用性,便于后续的维护。
另外,使用统一响应结果,统一了返回给前端页面的结果,减少了前后端开发人员的交流成本,也更规范了程序开发。
最后,在三层架构的基础上,使用Spring注解,将管理对象的工作交给了IOC容器,降低了层与层之间依赖、关联程度,实现了系统的高内聚低耦合。
参考:【黑马程序员2023新版JavaWeb开发教程,实现javaweb企业开发全流程(涵盖Spring+MyBatis+SpringMVC+SpringBoot等)】 https://www.bilibili.com/video/BV1m84y1w7Tb/?p=79&share_source=copy_web&vd_source=8d1a3172aa5ba3ea7bdfa82e535732a8 (P73-79)