前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐
又到了学Python时刻~

你还在为一个一个下载壁纸而烦恼吗,那有没有更加简单的方法呢?
跟着我,一起来看看我是如何批量下载的吧
环境使用:
-
python3.8 | Anaconda
-
pycharm
相关模块:
-
requests >>> pip install requests
-
parsel
模块安装方法:win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名, 回车
插 件:
xpath helper扩展工具包
安装步骤:点击文章下方名片加入后找助理老师获取xpath helper扩展工具包(注意:不要解压)
》》 打开Google浏览器 --> 更多工具 --> 扩展程序 --> 打开开发者模式 --> 把xpath helper扩展工具包直接拖入 --> 刷新
使用方法:快捷键 ctrl+shift+X
基本思路
1.网页的图片怎么来的?
写代码(爬虫): 网页源代码 浏览器 --> 解析数据
第一页 --> 41页
-
发送请求
-
响应数据
-
解析数据 图片
-
保存数据
代码
import requests # 需要下载 知道 1 不知道 2 pip install requests win+R --> cmd
import re # 正则 不需要下载
import parsel #数据解析 需要下载

# 伪装
headers = {# 用户代理 浏览器基本的身份信息'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求 response数据请求状态
response = requests.get(url,headers)
# print 打印输出 <Response [200]> 响应对象 200 状态码 成功
print(response)
"""
2.响应数据 网页源代码
"""
# print(response.text)
"""
3.解析数据 图片 re
"""
# .*? 精准查找
re_data = re.findall('<a href="(.*?)" target="_blank"rel="bookmark">(.*?)</a>',response.text)
print(re_data)
# for循环
for link,title in re_data:# print(link)response_1 = requests.get(link, headers).text# print(response_1)# 解析数据 标签详情页selector = parsel.Selector(response_1)# css:定位 img_url 图片链接img_url = selector.css('.entry-content img::attr(src)').getall()# print(img_url)for img in img_url:print(img)img_name = img.split('/')[-1]# content 二进制content = requests.get(img,headers).content
"""4.保存数据"""with open('img\\'+ img_name, mode='wb') as file:file.write(content)
效果
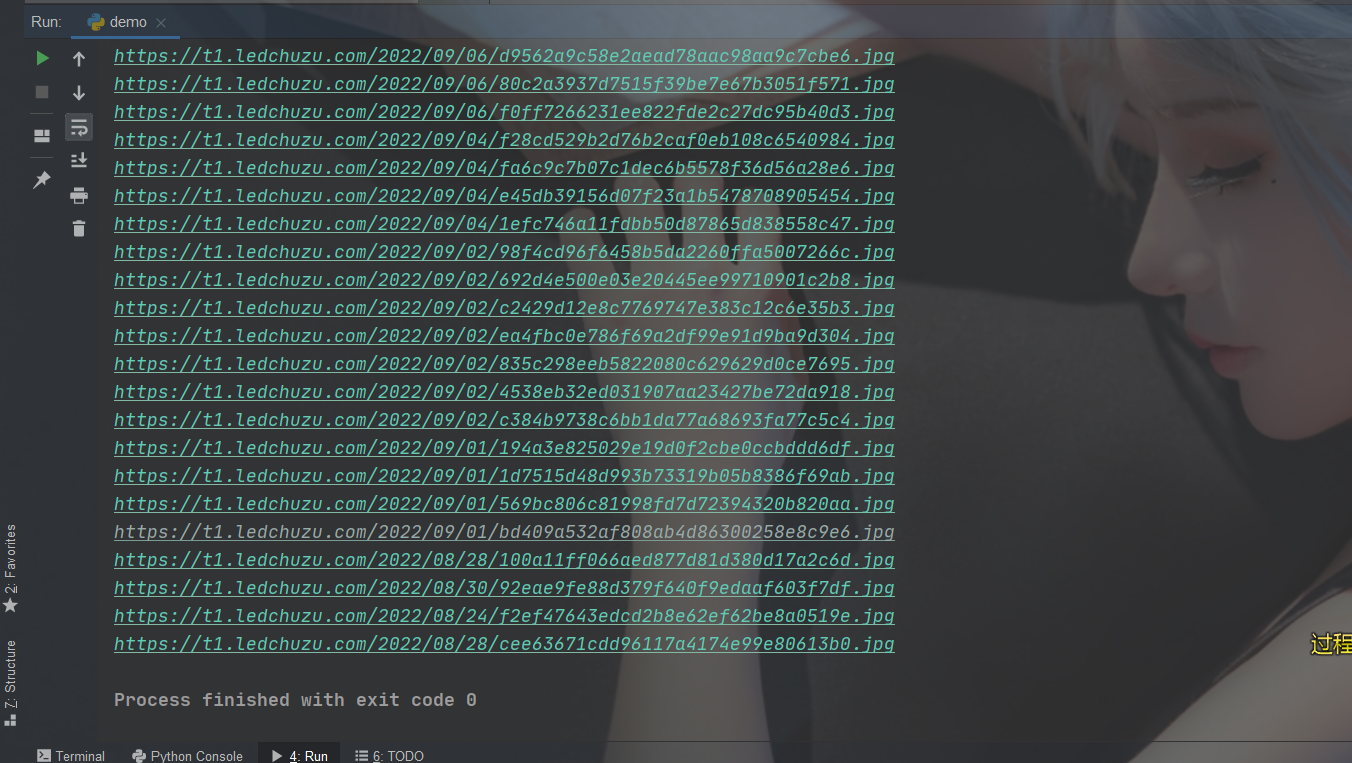
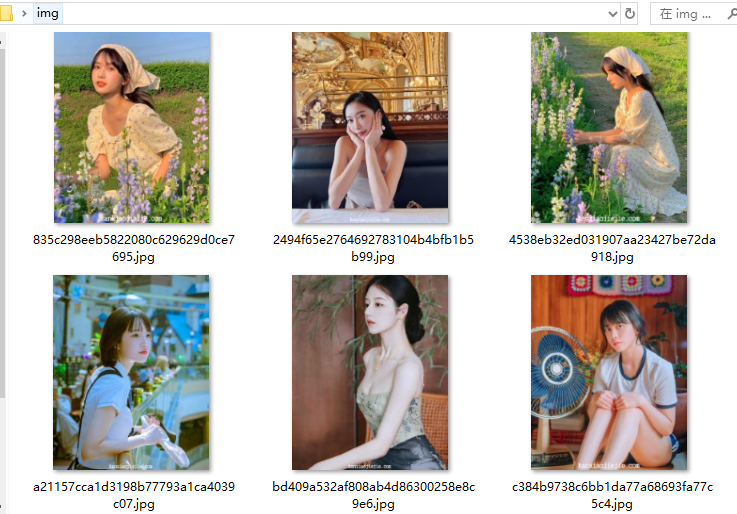








文章看不懂,我专门录了对应的视频讲解,本文只是大致展示,完整代码和视频教程点击下方蓝字
点击 蓝色字体 自取,我都放在这里了。
尾语 💝
感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。
最后,博主要一下你们的三连呀(点赞、评论、收藏),不要钱的还是可以搞一搞的嘛~
不知道评论啥的,即使扣个6666也是对博主的鼓舞吖 💞 感谢 💐






