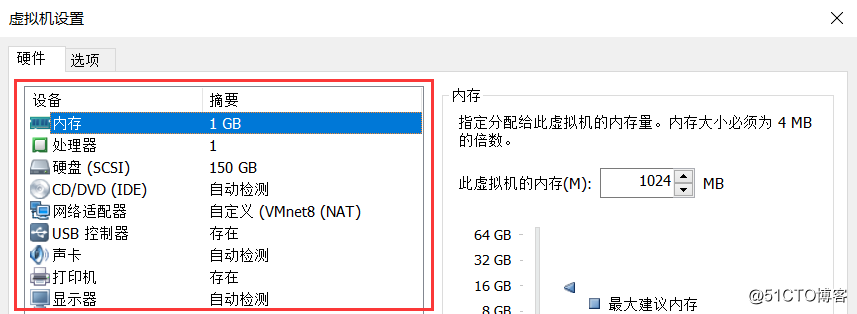
1、系统硬件(虚拟机分配)
CPU:Intel(R)_Core(TM) i5-3230M CPU @ 2.60GHz
内存:4GB
硬盘:20GB
2、系统软件
操作系统:CentOS-7-x86_64-Everything-1611
虚拟机:VMware 11.1.1 build-2771112
Hadoop版本:Hadoop 3.0.3
Java版本:Java-1.8.0_171
3、Hadoop环境配置
3.1 配置虚拟网络

本项目使用一个主机,两个从机,它们的名称以及IP地址确定如下:
| 名称 | IP地址 |
| Master | 192.168.102.100 |
| Slave1 | 192.168.102.201 |
| Slave2 | 192.168.102.202 |
3.2 主机网络的配置
(1)关闭SELINUX:vi /etc/selinux/config,设置SELINUX=disabled,保存退出,如下图所示:

(2)关闭防火墙,首先安装iptables,并启动服务:sudo yum install iptables-services。然后关闭防火墙:/sbin/service iptables stop;chkconfig --level 35 iptables off。执行完毕后查看防火墙状态:service iptables status,如下图所示

(3)修改静态IP地址,在命令行中输入vi /etc/sysconfig/network-scripts/ifcfg-ens33,IP配置信息如下

(4)修改主机名称:vim /etc/hostname
(5)修改host 映射:vi /etc/hosts

(6)重启网络service network restart,静态IP信息如下图所示

3.3 下载安装jdk,并且配置环境变量,完成安装
jdk环境变量的配置

3.4 安装配置hadoop
下载并解压Hadoop,修改hadoop-env.sh、core-site.xml、mapred-site.xml、workers、bash_profile等配置文件。
(1)修改hadoop-env.sh文件

(2)修改core-site.xml

(3)修改mapred-site.xml

(4)修改workers文件

(5)修改bash_profile文件

3.5 分布式集群的搭建
(1)克隆2个centos系统,至此可以看作3台服务器master、slave1、slave2。
(2)SSH免密码登录配置
默认启动ssh无密登录,每个系统都要对sshd_config文件进行配置vim /etc/ssh/sshd_config

进入/root/.ssh文件,输入ssh-keygen -t dsa,生成密钥,会在root文件夹里产生ssh文件。输入cat id_dsa.pub >> authorized_keys,将id_dsa.pub文件信息复制到authorized_keys文件中,输入scp authorized_keys slave2:~/.ssh,将authorized_keys复制到slave2。
然后输入ssh slave2 不用输入登录密码即可完成登录。同样的,对slave1完成ssh免密码登录配置。至此完成Hadoop在centos系统上的环境搭建
![]()
4、Hadoop平台的应用
4.1、Hadoop初始化
格式化hdfs,输入命令./hadoop namenode -format,格式化的过程状态如下图所示。

4.2、启动Hadoop。
(1) 在Hadoop主目录的sbin文件夹中,输入命令./start-all.sh

(2) jps查看Hadoop进程

4.3、上传任务文件到hdfs
(1)在本地系统创建任务文件
创建input文件夹,再在文件夹input中创建两个文本文件file1.txt和file2.txt,文件的内容如下图所示。

(2)上传文件
Hdfs系统创建h_input文件夹,在hadoop主目录下输入命令行bin/hdfs dfs -mkdir -p h_input 。将本地任务文件上传到hdfs,输入命令行bin/hadoop fs -put /home/lgy/input/file* h_input
(3)运行代码
运行统计单词代码,输入命令hadoop fs -cat h_output/part-r-00000,查看结果如下图所示

5 代码
import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class WordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context)throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);} //while} //map()} //static class TokenizerMapperpublic static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context)throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);} //reduce} //static class IntSumReducerpublic static void main(String[] args) throws Exception {Configuration conf = new Configuration();String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length != 2) {System.err.println("Usage: wordcount <in> <out>");System.exit(2);}Job job = new Job(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);} //main()} //class WordCount