系列文章目录
Flink第一章:环境搭建
Flink第二章:基本操作.
Flink第三章:基本操作(二)
Flink第四章:水位线和窗口
Flink第五章:处理函数
Flink第六章:多流操作
Flink第七章:状态编程
Flink第八章:FlinkSQL
文章目录
- 系列文章目录
- 前言
- 一、常用函数
- 1.快速上手案例
- 2.连接外部数据(csv)
- 3.时间窗口案例
- 4.TopN案例1
- 5.TopN案例2
- 二、UDF函数
- 1.Scalar Function(标量函数)
- 2.Table Function(表函数)
- 3.Aggregate Function(聚合函数).
- 4.Table Aggregate Function(表聚合函数 不建议)
- 总结
前言
这次博客我们记录以下FlinkSQL的学习内容
一、常用函数
1.快速上手案例
SimpleTableExample.scala
package com.atguigu.chapter07import com.atguigu.chapter02.Source.Event
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.Expressions.$
import org.apache.flink.table.api.Table
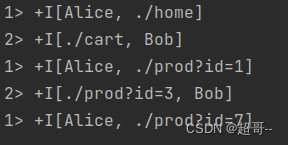
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironmentobject SimpleTableExample {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)// 读取数据源val eventStream: DataStream[Event] = env.fromElements(Event("Alice", "./home", 1000L),Event("Bob", "./cart", 1000L),Event("Alice", "./prod?id=1", 5 * 1000L),Event("Cary", "./home", 60 * 1000L),Event("Bob", "./prod?id=3", 90 * 1000L),Event("Alice", "./prod?id=7", 105 * 1000L))// 创建表环境val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)// 将DataStream装换成表val eventTable: Table = tableEnv.fromDataStream(eventStream)// 调用Table API 进行转换计算(不建议)val resultTable: Table = eventTable.select($("user"), $("url")).where($("user").isEqual("Alice"))// 直接写SQLtableEnv.createTemporaryView("eventTable",eventTable)val resultSQLTable: Table = tableEnv.sqlQuery("select url,user from eventTable where user='Bob'")// 装换成流打印tableEnv.toDataStream(resultTable).print("1")tableEnv.toDataStream(resultSQLTable).print("2")env.execute()}
}
2.连接外部数据(csv)
CommonApiTest.scala
package com.atguigu.chapter07import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{EnvironmentSettings, Table, TableEnvironment}
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironmentobject CommonApiTest {def main(args: Array[String]): Unit = {// 1创建表环境(2种方法)// 1.1直接基于流创建val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)// 1.2传入一个环境的配置参数创建val settings: EnvironmentSettings = EnvironmentSettings.newInstance().inStreamingMode().build()val tableEnvironment: TableEnvironment = TableEnvironment.create(settings)// 2.创建输入表tableEnv.executeSql("""| CREATE TABLE eventTable(| uid STRING,| url STRING,| ts BIGINT| ) WITH(| 'connector' = 'filesystem',| 'path' = 'input/clicks.txt',| 'format' = 'csv'| )|""".stripMargin)// 3.表的查询转换val resultTable: Table = tableEnv.sqlQuery("select uid,url,ts from eventTable where uid= 'Alice' ")val urlCountTable: Table = tableEnv.sqlQuery("select uid,count(url) from eventTable group by uid")// 4.创建输出表tableEnv.executeSql("""|CREATE TABLE outTable(| uid STRING,| url STRING,| ts BIGINT|) WITH(| 'connector' = 'filesystem',| 'path'='output',| 'format'='csv'|)|""".stripMargin)// 5.输出结果resultTable.executeInsert("outTable")tableEnv.toDataStream(resultTable).print("resultTable")tableEnv.toChangelogStream(urlCountTable).print("count")env.execute()}}
csv文件
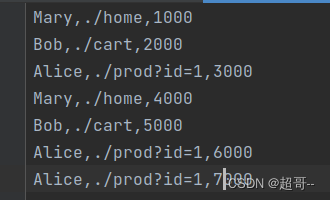
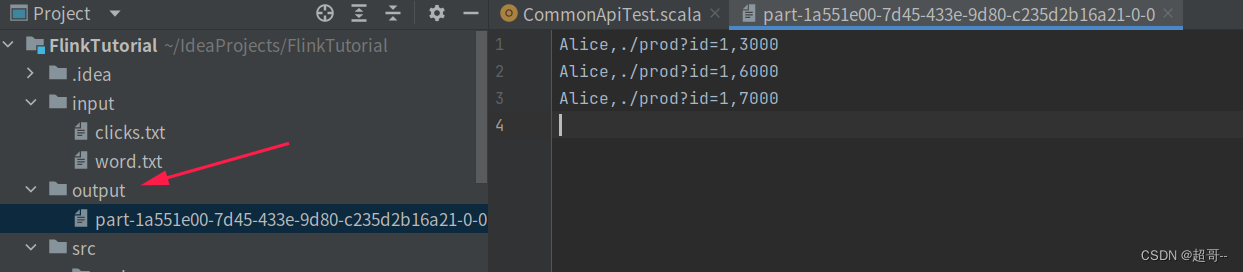
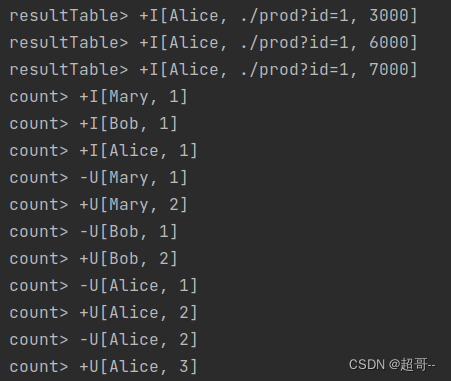
这里特别说明一下,我在创建输入表时出现了错误,代码没有报错,但是编译没有通过,最终从excel 导出一个csv文件传入,完成运行,之后在替换成符合格式要求的txt文件即可正常运行.(具体啥原因,我也不知道)
3.时间窗口案例
TimeAndWindowTest.scala
package com.atguigu.chapter07import com.atguigu.chapter02.Source.Event
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.Expressions.$
import org.apache.flink.table.api.{DataTypes, Schema, Table}
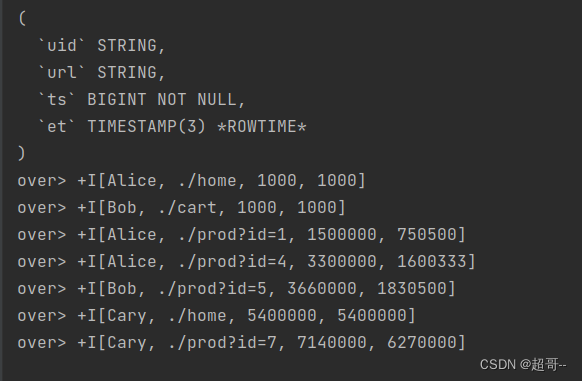
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironmentimport java.time.Durationobject TimeAndWindowTest {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)// 1.在创建表的DDL中指定时间属性字段tableEnv.executeSql("""| CREATE TABLE eventTable(| uid STRING,| url STRING,| ts BIGINT,| et AS TO_TIMESTAMP( FROM_UNIXTIME(ts/1000)),| WATERMARK FOR et AS et - INTERVAL '2' SECOND| ) WITH(| 'connector' = 'filesystem',| 'path' = 'input/clicks.txt',| 'format' = 'csv'| )|""".stripMargin)// 2. 在将流转换成表的时候指定时间属性字段val eventStream: DataStream[Event] = env.fromElements(Event("Alice", "./home", 1000L),Event("Bob", "./cart", 1000L),Event("Alice", "./prod?id=1", 25 * 60 * 1000L),Event("Alice", "./prod?id=4", 55 * 60 * 1000L),Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)).assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner[Event] {override def extractTimestamp(t: Event, l: Long): Long = t.timestamp}))// 已经弃用
// val eventTable: Table = tableEnv.fromDataStream(eventStream,$("url"),$("user").as("uid"),
// $("timestamp").as("ts"),$("et").rowtime())// 修改后val eventTable: Table = tableEnv.fromDataStream(eventStream, Schema.newBuilder().columnByExpression("et", "TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`/1000))").watermark("et", "SOURCE_WATERMARK()").build()).as("uid", "url","ts")eventTable.printSchema()tableEnv.createTemporaryView("eventTable", eventTable)// 测试累积窗口val resultTable: Table = tableEnv.sqlQuery("""|select| uid, window_end AS endT ,COUNT(url) AS cnt|FROM TABLE(| CUMULATE(| TABLE eventTable,| DESCRIPTOR(et),| INTERVAL '30' MINUTE,| INTERVAL '1' HOUR| )|)|GROUP BY uid,window_start,window_end|""".stripMargin)// tableEnv.toDataStream(resultTable).print()// 测试开窗集合val overResultTable: Table = tableEnv.sqlQuery("""|SELECT uid,url,ts,AVG(ts) OVER (| PARTITION BY uid| ORDER BY et| ROWS BETWEEN 3 PRECEDING AND CURRENT ROW|) AS vag_ts|FROM eventTable|""".stripMargin)tableEnv.toChangelogStream(overResultTable).print("over")env.execute()}
}
4.TopN案例1
TopNExample.scala
package com.atguigu.chapter07import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.bridge.scala.{StreamTableEnvironment, tableConversions}object TopNExample {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)// 2.创建输入表tableEnv.executeSql("""| CREATE TABLE eventTable(| uid STRING,| url STRING,| ts BIGINT,| et AS TO_TIMESTAMP( FROM_UNIXTIME(ts/1000)),| WATERMARK FOR et AS et - INTERVAL '2' SECOND| ) WITH(| 'connector' = 'filesystem',| 'path' = 'input/clicks.txt',| 'format' = 'csv'| )|""".stripMargin)// TOP N 选取活跃度最大的两个用户// 1.进行分组聚合统计,计算每个用户访问量val urlCountTable: Table = tableEnv.sqlQuery("select uid,count(url) as cnt from eventTable group by uid")tableEnv.createTemporaryView("urlCountTable",urlCountTable)// 2.提取最大的两个用户val top2resultTable: Table = tableEnv.sqlQuery("""|SELECT uid,cnt,row_num|FROM (| SELECT * ,ROW_NUMBER() OVER (| ORDER BY cnt DESC| )AS row_num| FROM urlCountTable|)|WHERE row_num<=2|""".stripMargin)tableEnv.toChangelogStream(top2resultTable).print()env.execute()}}
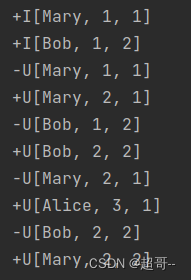
5.TopN案例2
TopNWindowExample.scala
package com.atguigu.chapter07import com.atguigu.chapter02.Source.Event
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{Schema, Table}
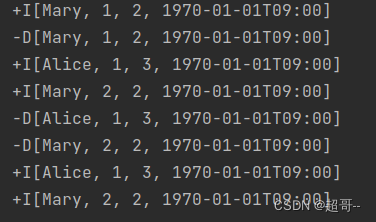
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironmentimport java.time.Durationobject TopNWindowExample {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)// 2.创建输入表val eventStream: DataStream[Event] = env.fromElements(Event("Alice", "./home", 1000L),Event("Bob", "./cart", 1000L),Event("Alice", "./prod?id=1", 25 * 60 * 1000L),Event("Alice", "./prod?id=4", 55 * 60 * 1000L),Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)).assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner[Event] {override def extractTimestamp(t: Event, l: Long): Long = t.timestamp}))val eventTable: Table = tableEnv.fromDataStream(eventStream, Schema.newBuilder().columnByExpression("et", "TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`/1000))").watermark("et", "SOURCE_WATERMARK()").build()).as("uid", "url")tableEnv.createTemporaryView("eventTable",eventTable)// TOP N 选取每小时内活跃度最大的两个用户// 1.进行窗口聚合统计,计算每个用户访问量val urlCountWindowTable: Table = tableEnv.sqlQuery("""|SELECT uid ,COUNT(url) AS cnt,window_start,window_end|FROM TABLE(| TUMBLE(TABLE eventTable,DESCRIPTOR(et),INTERVAL '1' HOUR)|)|GROUP BY uid,window_start,window_end|""".stripMargin)tableEnv.createTemporaryView("urlCountWindowTable",urlCountWindowTable)// 2.提取最大的两个用户val top2resultTable: Table = tableEnv.sqlQuery("""|SELECT *|FROM (| SELECT * ,ROW_NUMBER() OVER (| PARTITION BY window_start,window_end| ORDER BY cnt DESC| )AS row_num| FROM urlCountWindowTable|)|WHERE row_num<=2|""".stripMargin)tableEnv.toDataStream(top2resultTable).print()env.execute()}
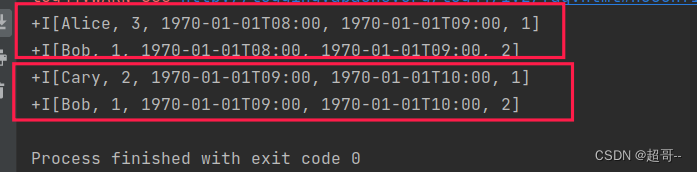
}
二、UDF函数
1.Scalar Function(标量函数)
UdfTest_ScalaFunction.scala
package com.atguigu.chapter07import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.functions.ScalarFunctionobject UdfTest_ScalaFunction {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)// 2.创建输入表tableEnv.executeSql("""| CREATE TABLE eventTable(| uid STRING,| url STRING,| ts BIGINT,| et AS TO_TIMESTAMP( FROM_UNIXTIME(ts/1000)),| WATERMARK FOR et AS et - INTERVAL '2' SECOND| ) WITH(| 'connector' = 'filesystem',| 'path' = 'input/clicks.txt',| 'format' = 'csv'| )|""".stripMargin)// 2.注册标量函数tableEnv.createTemporarySystemFunction("myHash",classOf[MyHash])// 3.调用函数val resultTable: Table = tableEnv.sqlQuery("select uid,myHash(uid) from eventTable")// 4.打印输出tableEnv.toDataStream(resultTable).print()env.execute()}// 实现自定义标量函数 哈希函数class MyHash extends ScalarFunction {def eval(str:String): Int ={str.hashCode}}}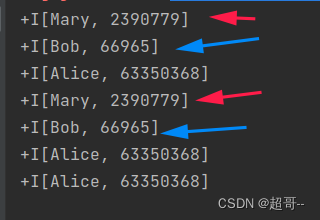
2.Table Function(表函数)
UdfTest_TableFunction.scala
package com.atguigu.chapter07import com.atguigu.chapter07.UdfTest_ScalaFunction.MyHash
import org.apache.flink.api.common.typeutils.TypeSerializer
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.annotation.{DataTypeHint, ExtractionVersion, FunctionHint, HintFlag, InputGroup}
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.functions.TableFunction
import org.apache.flink.types.Rowimport java.lang.annotation.Annotationobject UdfTest_TableFunction {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)// 1.创建输入表tableEnv.executeSql("""| CREATE TABLE eventTable(| uid STRING,| url STRING,| ts BIGINT,| et AS TO_TIMESTAMP( FROM_UNIXTIME(ts/1000)),| WATERMARK FOR et AS et - INTERVAL '2' SECOND| ) WITH(| 'connector' = 'filesystem',| 'path' = 'input/clicks.txt',| 'format' = 'csv'| )|""".stripMargin)// 2.注册表函数tableEnv.createTemporarySystemFunction("MySplit", classOf[MySplit])// 3.调用函数val resultTable: Table = tableEnv.sqlQuery("""|select| uid,url,word,len|from eventTable,lateral table(mySplit(url)) as T(word,len)|""".stripMargin)// 4.打印输出tableEnv.toDataStream(resultTable).print()env.execute()}// 实现自定义表函数 按照?分割url字段@FunctionHint(output = new DataTypeHint("ROW<word STRING,length INT>"))class MySplit extends TableFunction[Row] {def eval(str: String): Unit = {str.split("\\?").foreach(s => collect(Row.of(s, Int.box(s.length))))}}}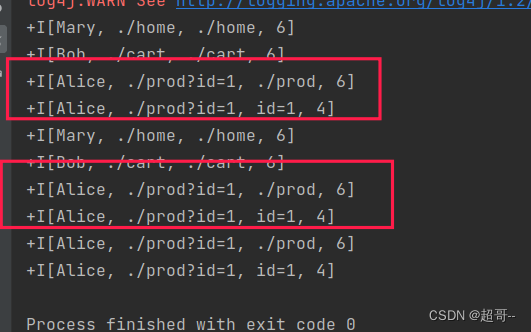
3.Aggregate Function(聚合函数).
UdfTest_AggregateFunction.scala
package com.atguigu.chapter07import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.functions.AggregateFunctionobject UdfTest_AggregateFunction {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)// 1.创建输入表tableEnv.executeSql("""| CREATE TABLE eventTable(| uid STRING,| url STRING,| ts BIGINT,| et AS TO_TIMESTAMP( FROM_UNIXTIME(ts/1000)),| WATERMARK FOR et AS et - INTERVAL '2' SECOND| ) WITH(| 'connector' = 'filesystem',| 'path' = 'input/clicks.txt',| 'format' = 'csv'| )|""".stripMargin)// 2.注册表函数tableEnv.createTemporarySystemFunction("WeightedAvg", classOf[WeightedAvg])// 3.调用函数val resultTable: Table = tableEnv.sqlQuery("""|select| uid,WeightedAvg(ts,1) as avg_ts|from eventTable|group by uid|""".stripMargin)// 4.打印输出tableEnv.toChangelogStream(resultTable).print()env.execute()}// 单独定义样例类case class WeightedAccumulator(var sum: Long = 0, var count: Int = 0)// 实现自定义聚合函数 计算加强平均数class WeightedAvg extends AggregateFunction[java.lang.Long, WeightedAccumulator] {override def getValue(accumulator: WeightedAccumulator): java.lang.Long = {if (accumulator.count == 0) {null} else {accumulator.sum / accumulator.count}}override def createAccumulator(): WeightedAccumulator = WeightedAccumulator() // 创建累加器// 每来一行数据,都会调用def accumulate(accumulator: WeightedAccumulator, iValue: java.lang.Long, iWeight: Int): Unit = {accumulator.sum += iValueaccumulator.count += iWeight}}
}

4.Table Aggregate Function(表聚合函数 不建议)
package com.atguigu.chapter07import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.Expressions.{$, call}
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.functions.TableAggregateFunction
import org.apache.flink.util.Collectorimport java.sql.Timestampobject UdfTest_TableAggFunction {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)// 1.创建输入表tableEnv.executeSql("""| CREATE TABLE eventTable(| uid STRING,| url STRING,| ts BIGINT,| et AS TO_TIMESTAMP( FROM_UNIXTIME(ts/1000)),| WATERMARK FOR et AS et - INTERVAL '2' SECOND| ) WITH(| 'connector' = 'filesystem',| 'path' = 'input/clicks.txt',| 'format' = 'csv'| )|""".stripMargin)// 2.注册表聚合函数tableEnv.createTemporarySystemFunction("top2", classOf[Top2])// 3.调用函数// 首先进行窗口聚合得到cntval urlCountWindowTable: Table = tableEnv.sqlQuery("""|SELECT uid ,COUNT(url) AS cnt,window_start as wstart ,window_end as wend|FROM TABLE(| TUMBLE(TABLE eventTable,DESCRIPTOR(et),INTERVAL '1' HOUR)|)|GROUP BY uid,window_start,window_end|""".stripMargin)// 使用Table API调用表聚合函数val resultTable: Table = urlCountWindowTable.groupBy($("wend")).flatAggregate(call("top2", $("uid"), $("cnt"), $("wstart"), $("wend"))).select($("uid"), $("rank"), $("cnt"), $("wend"))// 4.打印输出tableEnv.toChangelogStream(resultTable).print()env.execute()}// 定义输出结果和中间累加器的样例类case class Top2Result(uid: String, window_start: Timestamp, window_end: Timestamp, cnt: Long, rank: Int)case class Top2Acc(var maxCount: Long, var secondMaxCount: Long, var uid1: String, var uid2: String, var window_start: Timestamp, var window_end: Timestamp)// 实现表聚合自定义函数class Top2 extends TableAggregateFunction[Top2Result, Top2Acc] {override def createAccumulator(): Top2Acc = Top2Acc(Long.MinValue, Long.MinValue, null, null, null, null)// 每来一行数据,需要使用acc进行统计def accumulate(acc: Top2Acc, uid: String, cnt: Long, window_start: Timestamp, window_end: Timestamp): Unit = {acc.window_start = window_startacc.window_end = window_end// 判断当前count值是否排名前两位if (cnt > acc.maxCount) {// 名次向后顺延acc.secondMaxCount = acc.maxCountacc.uid2 = acc.uid1acc.maxCount = cntacc.uid1 = uid} else if (cnt > acc.secondMaxCount) {acc.secondMaxCount = cntacc.uid2 = uid}}// 输出结果数据def emitValue(acc: Top2Acc, out: Collector[Top2Result]): Unit = {// 判断cnt值是否为初始值if (acc.maxCount != Long.MinValue) {out.collect(Top2Result(acc.uid1, acc.window_start, acc.window_end, acc.maxCount, 1))}if (acc.secondMaxCount!=Long.MinValue){out.collect(Top2Result(acc.uid2,acc.window_start,acc.window_end,acc.secondMaxCount,2))}}}
}
总结
FlinkSQL的内容就记录到这里.