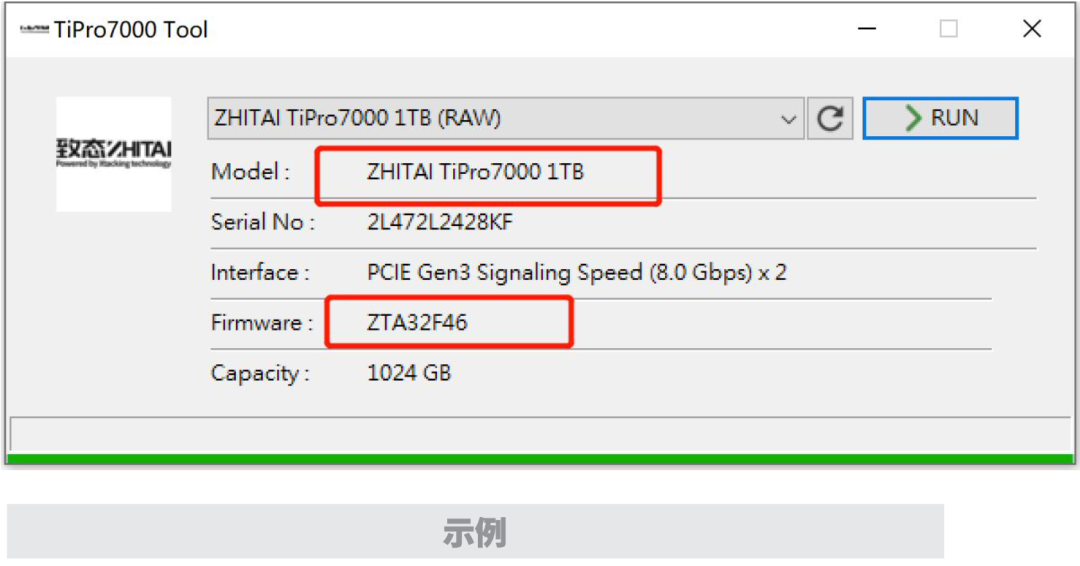
Improving GANs with A Dynamic Discriminator
公众号:EDPJ
目录
0. 摘要
1. 简介
2. 相关工作
3. 方法
3.1 基础
3.2 动态鉴别器
3.3 针对不同数据体系的两种方案
4. 实验
4.1 设置
4.2 实证研究
4.3 与现有方法的比较
4.4 DynamicD 的泛化性和兼容性
5. 结论
参考
附录
C. 对不同子网络的分析
D. 训练动态
F. 超参数分析
S. 总结
S.1 核心思想
S.2 具体操作
S.3 分析
0. 摘要
鉴别器通过区分真实样本和合成样本在训练生成对抗网络 (GAN) 中起着至关重要的作用。 虽然真实数据分布保持不变,但由于生成器的更新,合成分布不断变化,从而使判别器的二分类任务产生相应的变化。 我们认为,对容量进行即时调整的鉴别器可以更好地适应这种时变任务。 一项综合的实证研究证实,DynamicD 的训练策略可以提高综合性能,而不会产生任何额外的计算成本或训练目标。 开发了两种容量调整方案,用于在不同数据机制下训练 GAN:i) 给定足够数量的训练数据,判别器受益于逐渐增加的学习能力,以及 ii) 当训练数据有限时,逐渐减少层宽度可以减轻判别器的过拟合问题。 在一系列数据集上对 2D 和 3D 感知图像合成任务进行的实验证实了我们的 DynamicD 的普遍性以及它相对于基线的实质性改进。 此外,DynamicD 与其他鉴别器改进方法(包括数据增强、正则化器和预训练)具有协同作用,并且在结合用于学习 GAN 时带来持续的性能提升。
1. 简介
现有的图像分类研究指出,将模型容量与任务难度对齐是至关重要的,否则会出现欠拟合或过拟合的问题。
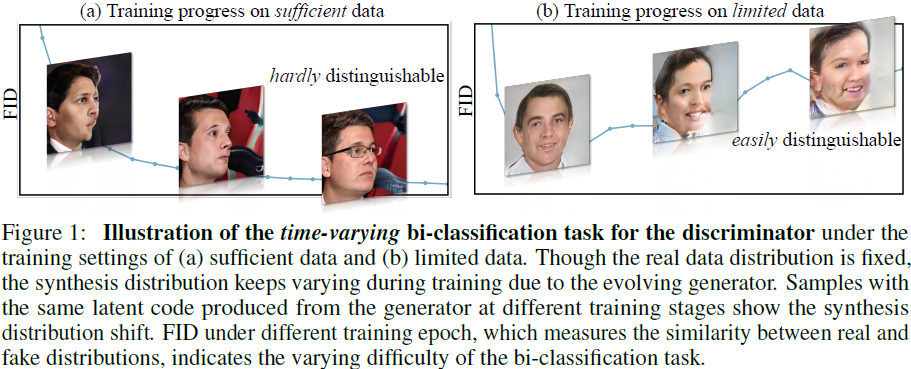
与训练数据在整个训练过程中保持固定的常见图像分类任务不同,GAN 训练似乎是时变的,因为生成器的合成质量在不断改进,如图 1 所示。这样,虽然真实数据分布保持不变,不同的合成分布仍然导致判别器的二分类任务发生变化。 这就很自然地提出了一个问题:具有固定容量的判别器是否满足这种动态训练环境的需求?
为了回答这个问题,我们通过使用动态鉴别器 (DynamicD) 训练 GAN 进行了全面的实证研究,其中在训练期间对其模型容量进行了即时调整。 我们首先研究一种简单的形式,其中鉴别器的层宽度是线性调整的。 在这样的设置下,由我们的 DynamicD 监督的生成器比使用固定鉴别器学习的生成器具有更好的合成性能,该鉴别器具有起始容量或结束容量。值得注意的是,我们提出的训练策略非常有效,因为它既不依赖额外的计算成本也不依赖额外的损失函数。 受此启发,我们提出了两种容量调整方案,并确认不同的训练数据机制有不同的偏好方案。
- 一方面,在图 1a 中有足够数量的训练数据,当生成器变得更有能力时,辨别任务变得越来越具有挑战性。 在这种情况下,鉴别器受益于与生成器匹配的扩大容量。
- 另一方面,由于图 1b 中的训练数据有限,模型训练的时间越长,判别器就越接近于记住整个数据集。 因此,逐渐降低模型容量的方案有助于鉴别器防止过度拟合。
我们在 2D 图像合成和 3D 感知图像合成这两个任务上评估我们的方法。 在广泛的数据集上,包括人脸、动物面孔、景色和合成的汽车,DynamicD 表现出相对基线的一致改进。 此外,我们表明 DynamicD 与改进 GAN 鉴别器的现有方法具有协同作用,包括数据增强、训练正则化器和预训练 。 它们结合起来会带来额外的性能提升,并为改进 GAN 训练开辟了一个新的维度。
2. 相关工作
生成对抗网络。最近在架构改进和训练方法方面的努力提供了吸引人的合成结果,甚至是 3D 可控性 。 基于这些,提出了各种技术来操纵语义和编辑真实图像。 此外,GAN 还可以改进各种判别任务。 在这项工作中,我们旨在从一个基本观点探索鉴别器的动态能力。 一些相关工作是渐进式增长(progressive growing)训练,它相应地从低分辨率到高分辨率调整生成器和鉴别器。 不同的是,我们不修改生成器,只专注于研究鉴别器的能力。
改进 GAN 中的鉴别器。 人们已经从各种角度尝试改进鉴别器。 一些文献探讨了数据增强如何帮助减轻鉴别器的过度拟合,这在低数据条件下非常有效。 然而,如果有足够的训练数据,改进变得有限甚至是负面的。 同时,之前的工作还努力为鉴别器加入各种正则或引入各种额外任务。 虽然鉴别器确实可以在某种程度上得到增强,但额外的计算是不可避免的。
- 最近,研究人员开始充分利用大规模数据收集的预训练模型(例如,ImageNet)作为鉴别器的冻结特征提取器。
- Sauer 等人提出带有投影的预训练特征空间可以显着提高收敛速度。
- 与此同时,Kumari 等人通过集成多个现成的模型改进了 GAN 训练。
- 然而,最近的工作表明,使用 ImageNet 预训练模型可能会使指标在实践中不可靠。
模型增强。 与直接对数据操作的数据增强不同,模型增强直接增强神经 representation。一个代表性的例子是 Dropout,它随机消除神经网络的单元以缓解过度拟合问题。 为了更好的正则化和性能,提出了各种 dropout 操作,如 SpatialDropout、DropBlock 和 StochasticDepth。
- 最近,Cai 等人将网络增强引入到训练中以改进微型神经网络。
- 同时,Liu 等人证明模型增强可以很好地与对比学习一起工作。
- 模型增强的文献主要集中在改进判别模型上。Mordido 等人建议涉及多个鉴别器,然后选择鉴别器的一个子集来训练生成器。
- 不同的是,我们的方法侧重于一个鉴别器,并从递减和递增的角度研究不同容量的影响。
3. 方法
3.1 基础
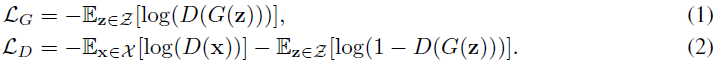
3.2 动态鉴别器
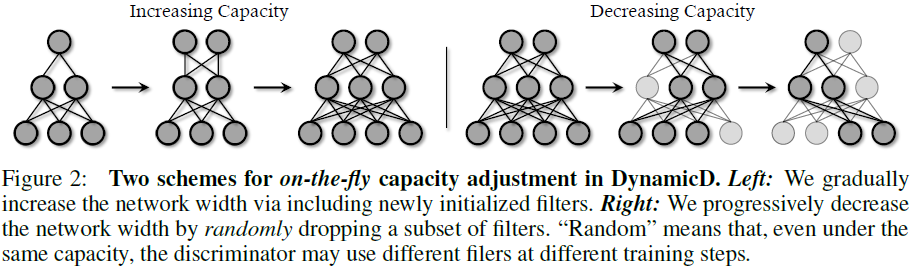
增加容量。 如果在我们的判别器较弱的情况下双分类任务变得具有挑战性,就会发生欠拟合,这样合成质量相对较低的生成器很容易骗过判别器。 因此,我们通过每几次迭代添加新初始化的神经滤波器来逐步增加鉴别器的容量。 也就是说,假设一层包含 M 个维度为 N 的神经滤波器,增加策略旨在引入 αM 个额外的滤波器,其中 α 表示扩展系数。
随着训练的进行,每 n 次迭代, α 线性增大,即鉴别器中所有层的容量同时增长(实际上 n = 1)。 在实践中,我们从标准鉴别器的一半容量开始,并确保最终容量与原始容量相同,以进行公平比较。
容量下降。 如果双分类任务相对简单,一个普通的判别器也可能会过度拟合,这似乎会记住训练集,合成质量将因此显着恶化。 为了缓解这种情况,我们随机消除了一些过滤器,因此层宽度逐渐缩小,如图 2 右侧所示。我们通过收缩系数 β 明确控制容量。
与增加容量不同,我们根据经验发现减少所有层会使训练不稳定,尤其是在调整通常包含较少内核的较低层时。 因此,我们在多层之后应用这种递减方案。
这种递减方案不同于标准的 Dropout,因为我们的方法形成了一个“权重级别”的 dropout,它由训练 batch 中的所有实例共享,而 Dropout 更像是“特征级别”的每个实例正则化器。
在训练期间,β 也线性下降,导致鉴别器的能力下降。 值得注意的是,这种策略不仅缩小了网络宽度,而且在一定程度上通过随机删除引入了多个鉴别器。 补充材料中的分析表明,来自各种鉴别器的 representations 可以相互补充,防止严重记忆某种模式,即大大减轻过度拟合问题。
3.3 针对不同数据体系的两种方案
数据充足。从一个相对小的网络(原始网络的子集)开始训练,扩展系数 α 可以从 0.5 到 0 变化。最大的网络与原始网络一致。
数据有限。收缩系数 β 从 1.0 开始,然后逐渐下降到 0.5。 考虑到上述由所有层的容量减少引起的不稳定问题,我们排除了通常包含较少维数的低级层的减少策略。
4. 实验
4.1 设置
基线。没有自适应鉴别器增强 (ADA) 的 StyleGAN2 作为我们 2D 图像合成的主要基线。 我们还使用 StyleNeRF 进行了 3D 感知图像合成实验。 所有训练设置都严格遵循先有技术,以确保公平比较。
4.2 实证研究
实验结果如表 1 所示。

4.3 与现有方法的比较

4.4 DynamicD 的泛化性和兼容性

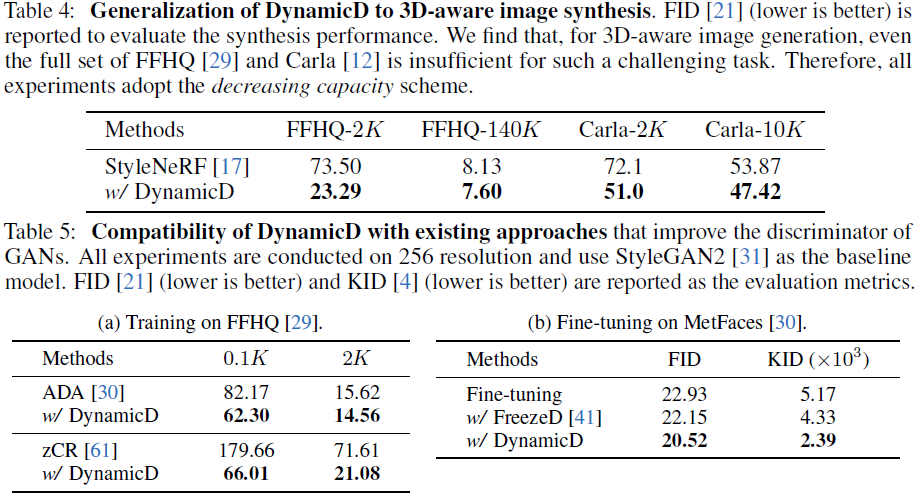
5. 结论
我们提出了一种改进 GAN 的通用方法 DynamicD。 通过调整两种不同方案下鉴别器的容量,我们可以显着提高图像合成质量并相应降低计算成本。 在广泛的数据集和生成任务上进行的实验证明了我们的 DynamicD 的有效性、通用性和兼容性,以及一致的性能提升。
讨论。 尽管在各种任务和数据集上的合成质量和性能都很吸引人,但我们的 DynamicD 仍然有一些局限性。 例如,当前形式的 DynamicD 通过扩展或缩小层宽度来调整网络容量。 没有探索其他因素(例如网络深度)的影响。 同时,目前的实验是在基于 CNN 的鉴别器上进行的。 基于 transformer 的鉴别器的收益仍然不确定且值得研究。 另一方面,虽然这项工作早期尝试证明两种动态方案在不同数据规模下的有效性,但一些自我调整或 AutoML 策略可能更有效。 此外,理论研究将使它更具吸引力,留待未来研究。
参考
Yang C, Shen Y, Xu Y, et al. Improving gans with a dynamic discriminator[J]. arXiv preprint arXiv:2209.09897, 2022.
附录
C. 对不同子网络的分析
如第 3 节所述,我们的递减策略将涉及多个子网。 为了分析各种子网的行为,我们利用 Grad-CAM 来可视化空间注意力。 图 S1 显示了基线的注意力图和我们在 FFHQ-2K 上的方法。 请注意,我们在一个训练步骤中观察并比较了不同方法的视觉注意力。
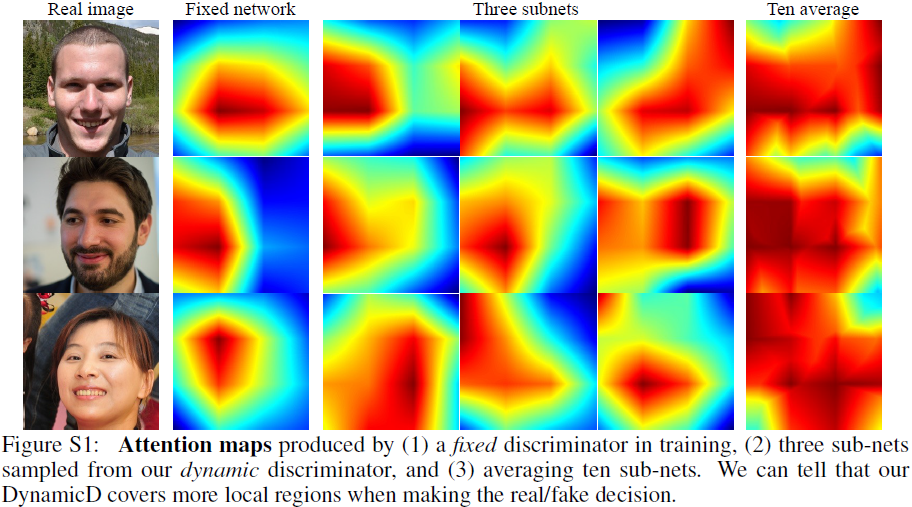
给定真实图像,固定鉴别器更喜欢某个空间位置。 也就是说,空间焦点在很大程度上决定了这个图像是真实的还是假的。 然而,从容量递减的鉴别器中随机抽取的子集会以不同的方式进行关注。 来自十个子网的平均注意力图表明,这些不同的网络可以在一定程度上相互补充,帮助判别器查看更多区域来做出决定。
D. 训练动态

在本节中,我们绘制了几种设置下的时变 FID 曲线以供进一步分析。 首先,图 S4 显示了两个有限数据集和两个足够数据集下的性能曲线。 显然,在训练的一开始,我们的方法几乎没有优势,因为由于子网采样,并非所有参数都得到训练。 但经过短暂的预热,我们的方法始终优于基线。 在某种程度上,我们可以说我们的方法可以稍微加快收敛速度,因为我们的方法通常需要更少的时间来达到相同的 FID。
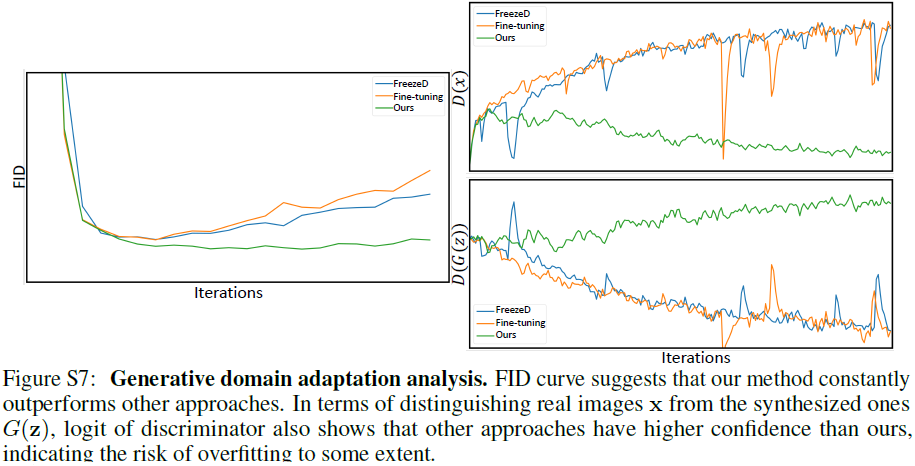
此外,我们还在图 S7 的生成域适应任务中展示了鉴别器的 FID 和 logits(即鉴别器的输出)。 显然,FreezeD 和基线(即直接微调)似乎过度拟合,因为它们的 FID 逐渐上升,对真/假二分类的置信度越来越高。 相反,随着判别器容量的逐步限制,一定程度上缓解了过拟合。
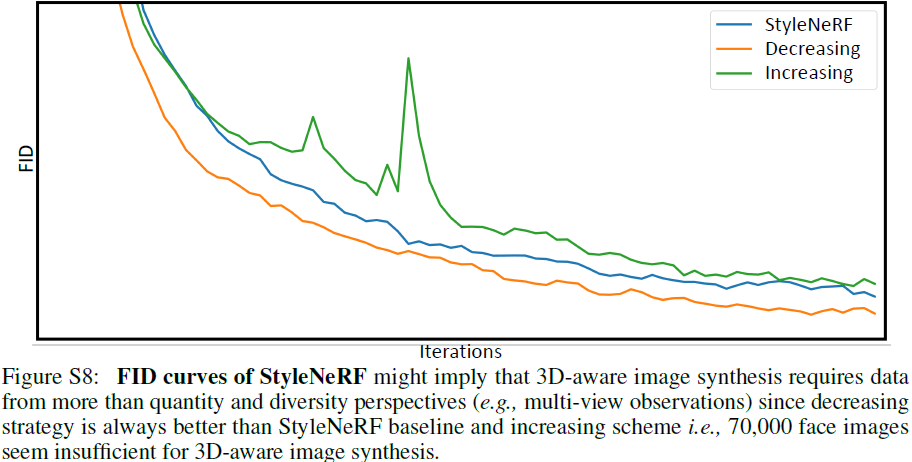
正如在第 4.4 节中提到的,我们凭经验发现降低容量在完整 FFHQ 上效果更好。 在这里,我们分别在图 S8 中绘制了 StyleNeRF 基线、容量增加的 StyleNeRF 和容量减少的 StyleNeRF 的 FID 曲线。 这表明 70,000 张人脸图像似乎也不足以进行 3D 感知图像合成,因为减少策略总是优于 StyleNeRF 基线和增加方案。
F. 超参数分析
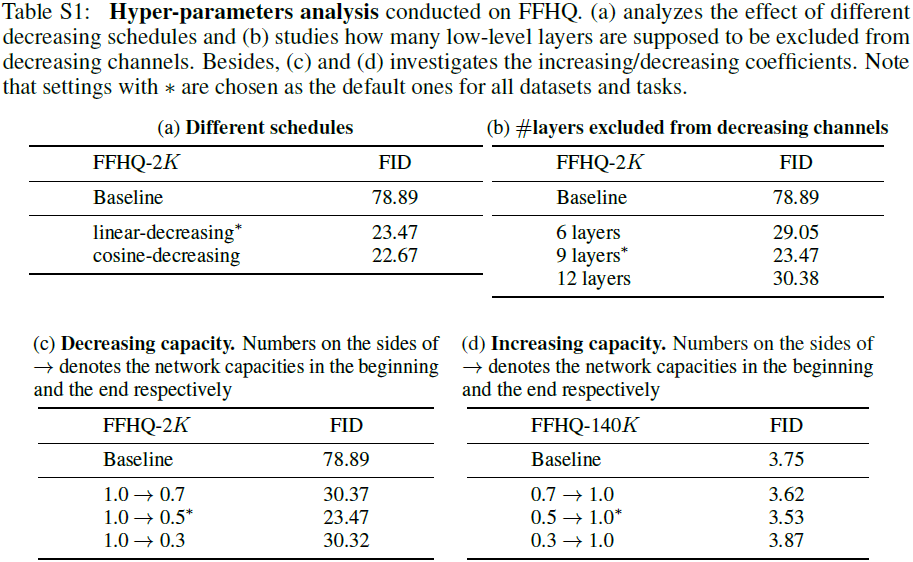
表 S1 展示了对 FFHQ 的多个超参数的分析。 显然,我们的方法对不同的超参数并不高度敏感,例如递减方法、应该从递减通道中排除多少层以及递减/递增系数。 特别是,在 FFHQ 上选择的超参数在各种数据集和任务中保持相同。
S. 总结
S.1 核心思想
在 GAN 训练过程中,虽然真实数据分布保持不变,但由于生成器的更新,合成分布不断变化,从而使判别器的二分类任务产生相应的变化。
对此,作者提出了动态鉴别器(DynamicD),如图 2 所示。
- 当数据充足时,逐渐增大鉴别器网络的宽度,从而避免欠拟合;
- 当数据不足时,逐渐减小鉴别器网络的宽度,从而避免过拟合。
S.2 具体操作
数据充足。应逐渐增大网络容量。从一个相对小的网络(原始网络的子集,例如,一半)开始训练,每几次迭代添加 αM 个新初始化的神经元,扩展系数 α 可以从 0.5 到 0 变化,M 为初始(小)网络的宽度。最大的网络与原始网络一致。
数据不足。应逐渐减小网络容量。通过随机删除一些神经元,来减小网络宽度。收缩系数 β 从 1.0 开始,然后逐渐下降到 0.5。
与增加容量不同,作者发现减少所有层会使训练不稳定,尤其是通常包含较少神经元的较低层。 因此,作者排除了这些低级层的缩减方案。
这种递减方案不同于标准的 Dropout,因为该方法形成了一个 “权重级别” 的 dropout,它由训练 batch 中的所有实例共享,而 Dropout 更像是 “特征级别” 的每个实例正则化器。
缩减策略不仅缩小了网络宽度,而且在一定程度上通过随机删除引入了多个鉴别器。分析表明,来自各种鉴别器的 representations 可以相互补充,防止严重记忆某种模式,即大大减轻过拟合问题。
S.3 分析
相比于基线模型(例如,StyleGAN2),本方法可以稍微加快收敛速度,通常需要更少的时间来达到相同的 FID。直观地理解就是,无论缩减还是扩张,需要训练的总参数量都比原模型小。