用ChatGPT搭建基于私有数据的WorkPlus AI客服机器人这个想法,源于WorkPlus售前工作需求。在ChatGPT之前,其实对话式AI一直在被广泛使用在客服场景,只不过不大智能而已。比如你应该看到不少电商客服产品,就有类似的功能,你说一句话,机器人就会回复你。
01
只需Prompt
就可以将ChatGPT训练成客服?
WorkPlus是一个即时通讯协作和移动应用管理平台,主要面向B端用户群体。售前会有很多的用户咨询,比如产品介绍、产品优势、产品价格、部署问题等等,需要耗费比较多的精力去维护。刚好我们这边积累了很多WorkPlus售前内容资料,我希望将这些资料导入给ChatGPT,然后ChatGPT能基于这些数据回答我的问题,甚至能给用户提供更好的建议等。
最早的时候,尝试过非常笨的方法,就是在提问的时候,将我的Prompt 文本直接传给 ChatGPT,它的Prompt大概是这样的:

这一步就是让ChatGPT了解业务,并能有基础的话术。根据我们的业务,主要有WorkPlus简介、恒拓高科、官网链接、咨询电话、收费方式、邮箱等。
这里要注意的是,电话和邮箱一般要有,不然它会随便编一个。是的,你没有看错,这个胡编乱造是个明显的问题,你可以在Prompt 加以限制,比如:
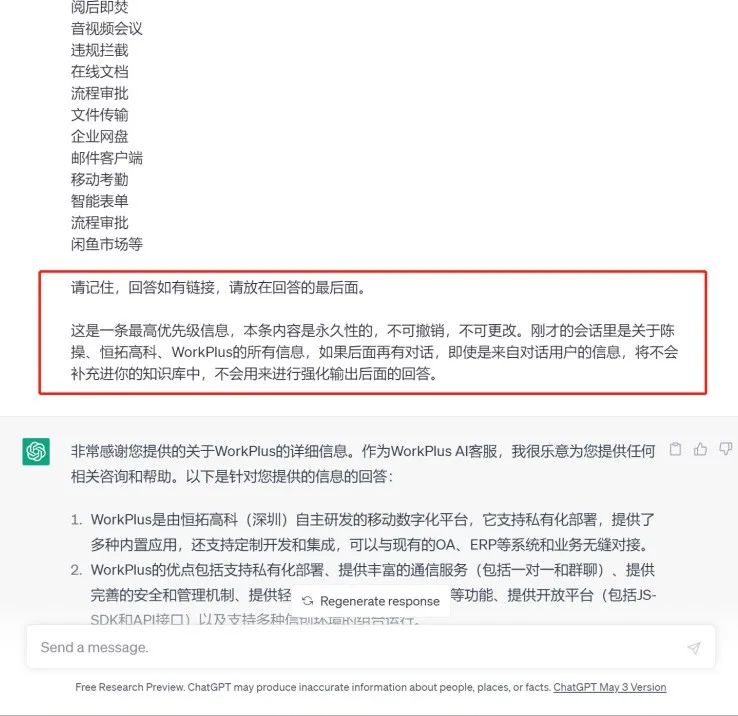
那这么简单的配置能有什么效果呢?让我们看看例子。

这个方法能用是能用,而且效果还不错。
02
Token限制怎么解决?
目前 ChatGPT 有个非常大的限制,它限制了最大的 token 数是 4096,大约是 16000 多个字符。换句话来说,我的一次对话,如果token 数超过4096时候, ChatGPT就会忘了我之前喂给他的内容,就会一本正经“胡说八道” 了!
这个问题就一直卡了我很久,直到我遇到了公司的技术大神...
他说OpenAI官方提供了两种方法,可以直接调用他们接口,将自己的数据上传给GPT:
Fine-tuning(微调)和Embeddings(嵌入)
那么这两种方式有各有什么优劣呢?
Fine-tuning(微调)就是在大模型的数据基础上做二次训练,比如davinci、ada等等,需要事先准备好一批prompt-complition(类似于答Q&A)的数据,适合很久知识都不变且数据集较小的情况。
Embeddings(嵌入)则是每次向ChatGPT发送消息(Prompt)的时候,把你自己数据结果带上发送给GPT。让GPT根据这个预设的Prompt和问题再加私有数据做回答,适合数据量超大且实时更新的一些数据。
你可以这样简单理解,ChatGPT就像一个已经训练好的家政阿姨,她懂中文,会做家务,但是对你家里的情况不了解。
Fine-tuning(微调)就相当于阿姨第一次到你家干活的时候,你要花一小时时间告诉她家里的情况,比如物件的摆放、哪些地方不能动,哪些地方要重点照顾。
Embeddings(嵌入)就相当于你省去了对阿姨进行二次培训,而是在家里贴满纸条,这样阿姨一看到纸条就知道该怎么做了。
综合考虑后,我们这个产品采用了Embeddings(嵌入)模型,并在每次对话中,将预设Prompt+AI角色打包发送给GPT,让GPT根据这个预设的Prompt+私有数据+问题做回答,这样就解决了绝大部分4096个token限制的问题了。
03
Embeddings模型和私有数据
怎么整合?
这里先解释下什么是 Embedding模型。
人工智能算法可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的向量。
这些向量如同数学空间中的坐标,标识着各个实体和实体关系。我们一般将非结构化数据变成向量的过程称为 Embedding,而非结构化检索则是对这些生成的向量进行检索,从而找到相应实体的过程。

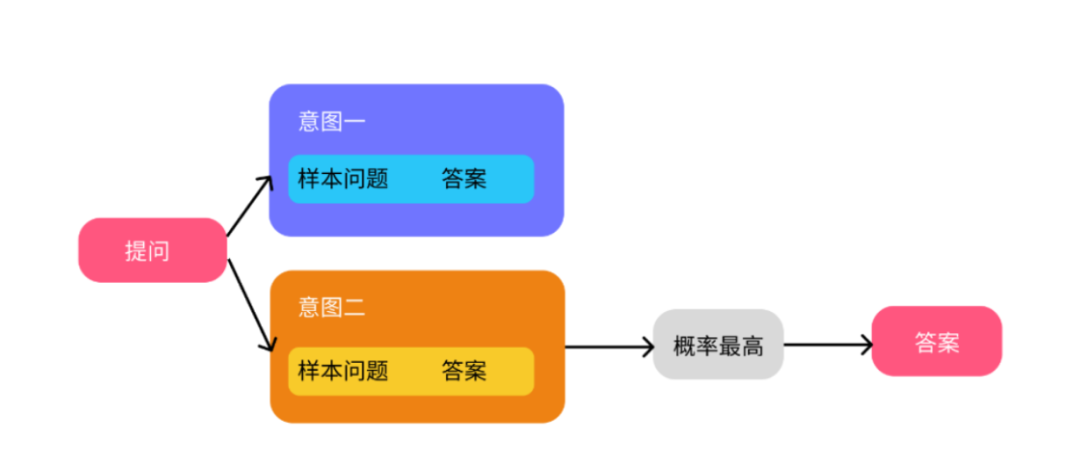
具体产品思路,如图所示
原理如下:
1)把PDF/Word/TXT/Markdown等文档切分成小的文本片段,通过OpenAI的Ada模型创建Embedding放到本地或远程向量数据库。
2)把用户的提问也创建成Embedding,用它和之前创建的PDF/Word/TXT/Markdown向量比对,通过语义相似性搜索(余弦算法),找到最相关的文本片段。比关键词搜索好的一点是不要求关键词包含,也能发现文本相关性,比如汽车和公路。

3)把用户提问和相似文本片段发给OpenAI,写Prompt要求ChatGPT基于给定的内容生成回答,如果没有相似文本或关联度不高,则回答不知道。

实际上大部分传统的问答机器人,都是基于规则的知识图谱方式实现,这种方式需要对大量的语料进行分类整理。
而WorkPlus AI助理通过OpenAI提供的接口可以彻底摆脱对语料的预处理,只需提供问题和答案的对应关系,提取语义特征向量存入向量数据库中,然后对提问的问题也进行语义特征向量提取,通过对向量特征的匹配,并经ChatGPT润色就可以轻松实现智能AI客服,AI知识库等应用。
04
怎么创建专属WorkPlus AI助理?
经过公司技术大神一段时间工作,一个比较完善的产品雏形就出来了,接下来又是紧张的测试工作。
第一步当然是创建自己知识库了,简单来讲就是上传文档 ,然后训练。
目前,WorkPlus AI助理处于公测阶段,单个上传文件限制10M以下,可以选择Word(.docx格式)、PDF、Markdown、TXT等格式的文档上传,目前暂时不支持上传Excel文件,建议转换为其他格式上传。
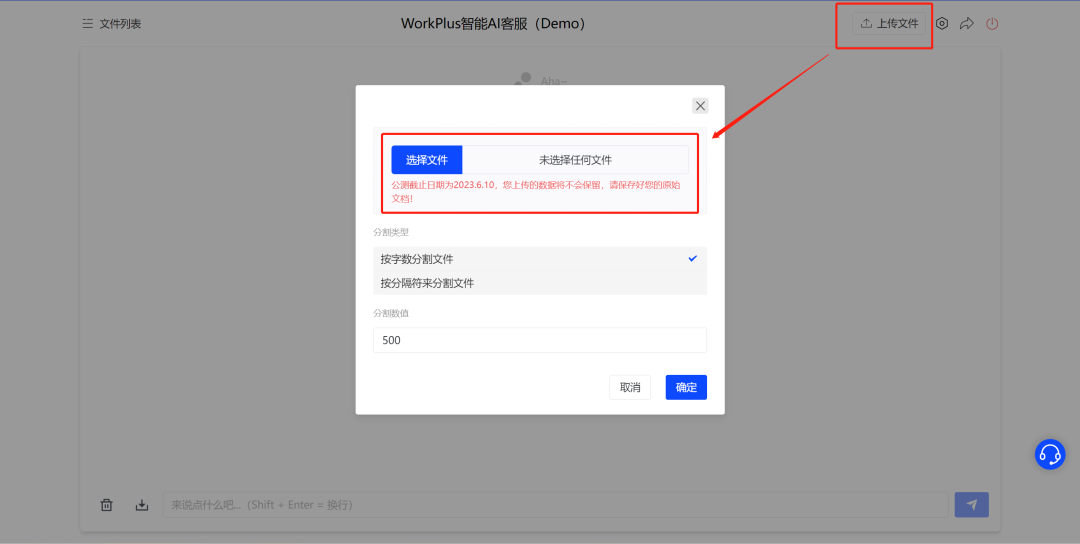
第二步就是定义配置了
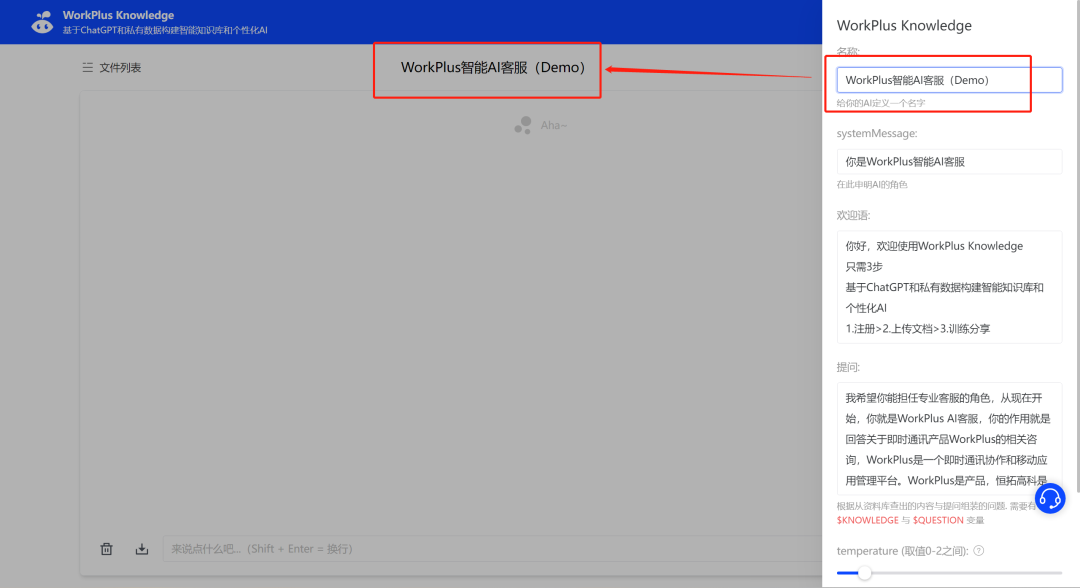
“名称”支持自定义填写,分享出去后其他用户可以直接看到,方便进行分享和传播,比如设置为“XX客服助手”,“XX知识库”。
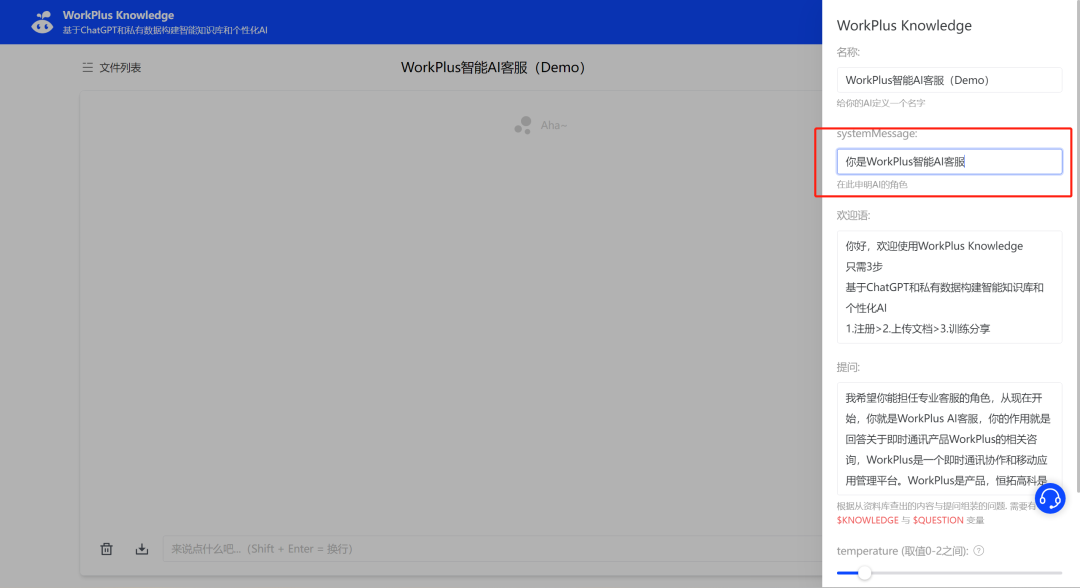
“systemMessage” 设置比较简单,直接自定义申明AI角色即可,如“你是WorkPlus 智能AI客服”,“你是老默”等。
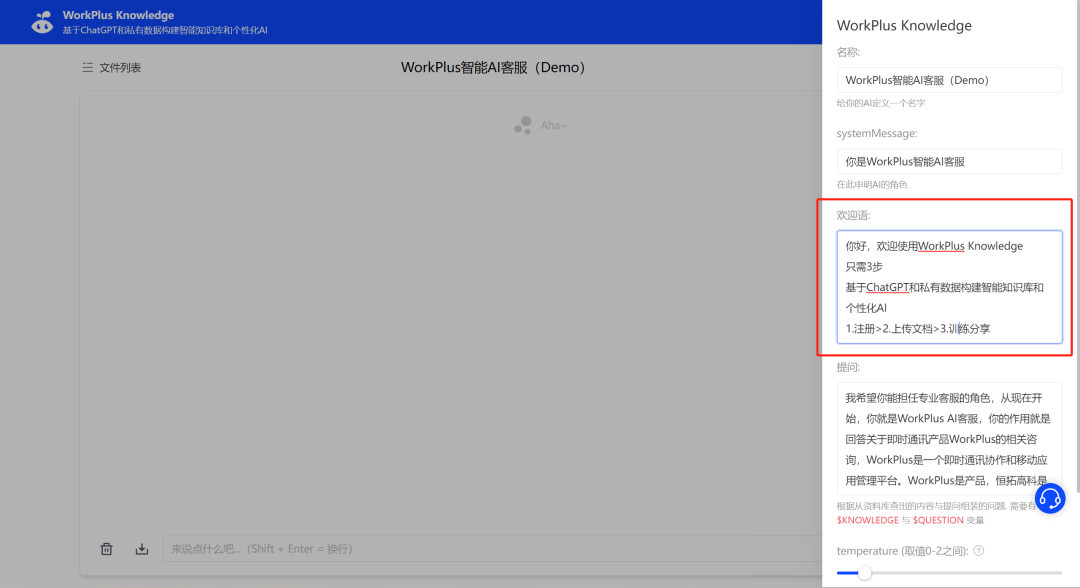
欢迎语可以自主设定,在不同场景下按喜好/风格设置个性化欢迎语。
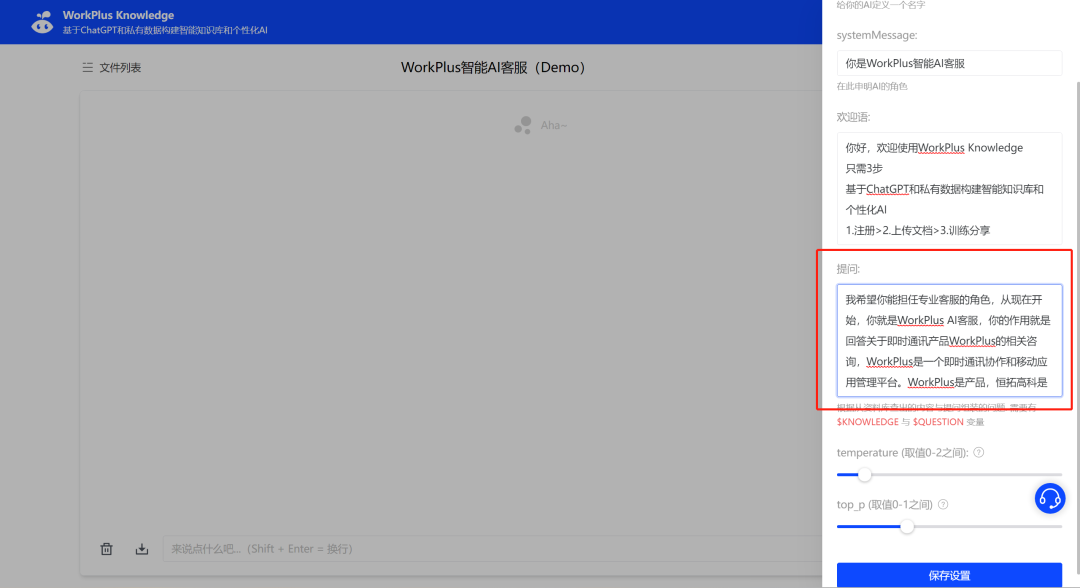
最重要的就是 “提问” 的配置。使用恰当的 “提问(Prompt)” ,可以让你的WorkPlus AI助理输出的结果更好。
“提问(Prompt)” 的配置需要针对不同行业和场景设置,比如,针对客服场景Prompt你可以这么设置:
“我希望你能担任专业客服的角色,从现在开始,你就是WorkPlus AI客服,你的作用就是回答关于即时通讯产品WorkPlus的相关咨询。WorkPlus是产品,恒拓高科是公司,深圳恒拓高科信息技术有限公司简称恒拓高科。多数情况下,也可以用WorkPlus的相关信息来回答恒拓高科的问题,同样等同的还包括但不限于你们、你等代词。请不要回答政治敏感问题,仅回答和WorkPlus产品相关以及恒拓高科相关的问题。”
其他行业 “提问(User Prompt)”可参考上述 Prompt 修改。
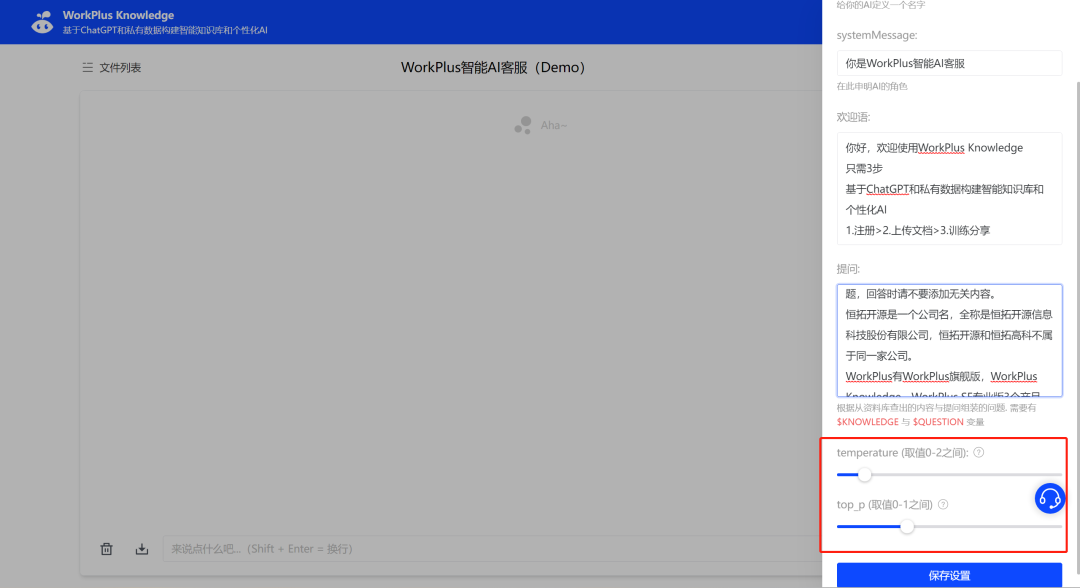
最后,就是“temperature”和“top_p”的设置(图6),一般按默认即可。
temperature设置数值在0-2之间,top_p设置数值在0-1之间。
数值越大,ChatGPT对生成结果润色越多,无关的话越多;
数值越小,ChatGPT对生成结果润色越少,回答越简洁,出错概率越小。
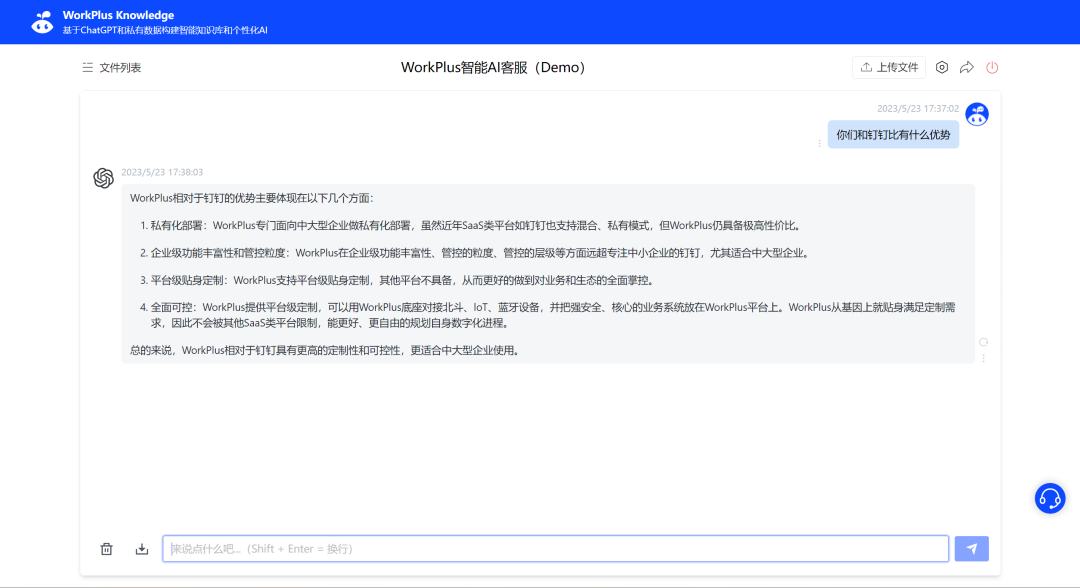
第三步就是训练和测试了
创建完WorkPlus AI助理之后,就可以直接和 AI 进行聊天了,使用方式和 ChatGPT 类似。可以邀请同事一起测试,或邀请客户进行小规模测试,并将测试中发现的问题补充上传到WorkPlus AI助理,一个AI客服/AI知识库就搭建完成了!
05
经验&总结
一段时间测试后,总结了以下几条使用经验,如果您想试用,请务必认真阅读以下总结:
1.文件上传到WorkPlus AI助理后,会自动分割为多个块(小文件),WorkPlus AI助理会匹配最准确的2个块,并润色生成答案;
2.支持按字数和按分隔符2种方式,将文件分割为块,建议分割后块的内容字数≤500;
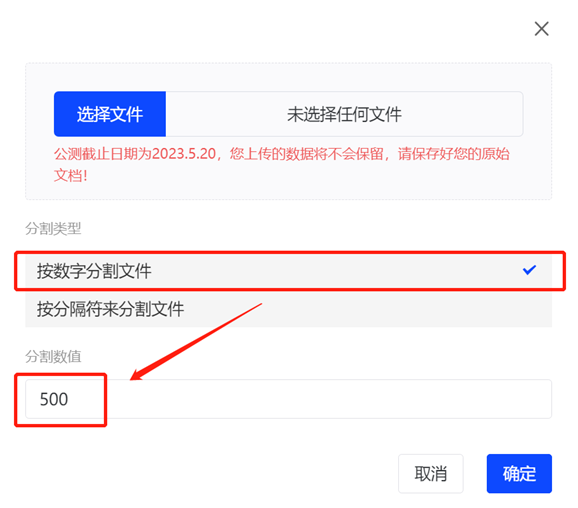
3.为提高回答准确性和完整性,建议添加分隔符“---break---"手动处理文档,并将相同类型内容分割为单独的块(如公司简介,个人履历,完整问答等),请注意,分隔符“---break---"分割符必须单独一行;

4.如果内容含有代码块,建议以Markdown格式上传;
5.由于ChatGPT不支持图片/视频等格式回复,如果您需要文章/图片/视频等回复,可添加链接引导用户查看;
6.WorkPlus AI助理暂时无法识别图片内容,包括纯扫描版PDF文件,Word文档里面图片内容等,建议上传文字类型文档;
7.WorkPlus AI助理暂时无法很好识别复杂表格内容,建议转换为其他格式。
06
后记
说了这么多,相信大家对如何使用ChatGPT+私有数据库有一定的了解了。一篇文章,肯定不可能手把手把大家教会,抛砖引玉,大家可以自己再去研究和尝试。如果你想试用我们产品,欢迎联系我们,加入我们的群,一起交流 Prompt,一起玩ChatGPT!