声明:作者翻译论文仅为学习,如有侵权请联系作者删除博文,谢谢!
论文链接:arXiv:1705.08421 [cs.CV]
《AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions》论文翻译
- 摘要
- 介绍
- 相关工作
- 数据收集
- 动作词汇生成
- 影片和片段选择
- 人物边框注释
- 人的链接注释
- 动作标注
- 训练集、验证集和测试集
- AVA数据集的特征
- 多样性和困难
- 标注的统计数据
- 时间结构
- 行动定位模型
- 实验和分析
- 数据集和指标
- 与state-of-the-art的比较
- Ablation study
- 结论
- 引用论文
摘要
介绍了一种时空局部原子视觉行为视频数据集。AVA数据集在430个15分钟的视频剪辑中进行行为动作(action)标注,共定义了80个“原子”行为动作类别,这些动作在空间和时间上被定位,产生了158万个动作标签,每个人经常出现多个标签。我们的数据集的关键特征是:(1)定义了原子视觉动作,而不是复合动作;(2)精确时-空标注,每个人可能有多个标注;(3)对超过15分钟的视频片段进行详尽的注释;(4)被检测到的(同一个)人可以在连续段间连接起来;以及(5)使用电影来收集一系列不同的动作数据。这与现有的时-空动作识别数据集不同,后者通常在短视频剪辑中为复合动作提供稀疏注释。
AVA以其逼真的场景和动作的复杂性,暴露了动作识别的内在困难。为了证明这一点,我们提出了一种新的动作定位(action localization)方法,该方法基于当前最先进的方法,并在JHMDB和UCF101-24数据集上进行测试,展示了更好的性能。虽然在其他现有数据集上建立了一个新的技术水平,但在我们AVA上的总体结果却只有15.6%,这凸显了开发视频理解新方法的必要性。
介绍

我们引入了一个新的标注视频数据集AVA,以推进动作识别研究(见图1)。标注是以人为中心,采样频率为1 Hz(即每秒1帧)。每个人都是使用边界框定位,发出动作的演员会被添加标签(可能是多个):其中,一个动作(必需的)对应与演员的姿势(橙色文本)——站着,坐着,散步,游泳等等——也可能会有额外的动作:与物体的交互(红色文本)或与他人的交互(蓝色文本)。如果一帧中包含多个人,则每个人都应该被单独标注。
要标注一个人的动作,关键是标注词汇表(即动作的类别),而标注词汇表又由对动作进行分类的时间粒度决定。我们使用短的时间片段(以关键帧为中心的±1.5秒)来提供时间上下文,以便在中间帧标记动作。这使标注人能够使用位移的提示信息,来消除一些动作的歧义,比如“拿起或放下”等,这些歧义不能在静态帧中解决。我们保持时间上下文(3秒)相对简短,因为我们感兴趣的是(时间上)对物理动作的精确标注,这导致了“原子视觉动作”(AVA)。该词汇表由80种不同的原子视觉动作组成。我们的数据集来自于430个不同电影,每个电影截取15到30分钟的时间片段,给定1 Hz的采样频率,我们可以得到每个电影将近900个关键帧。在每个关键帧中,每个人都被标记为AVA词汇表中的(可能有多个)动作。每个人都被链接到连续的关键帧,以提供动作标签的短期序列(第4.3节)。我们现在推动AVA的主要设计选择。
![该图说明了活动的层次结构的本质。摘自Barker and Wright[3],第247页。](https://img-blog.csdnimg.cn/20200616230428142.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM0MjkyMDg3,size_16,color_FFFFFF,t_70#pic_center)
原子动作类别Barker和Wright[3]在他们对Kansas一个小镇居民日常生活中的“行为事件”的经典研究中,注意到了活动的分层性质(图2)。在细粒度的级别上,动作是由“原子体”移动或对物体的操作组成,但在较粗糙粒度的级别上,最自然的描述则是关于意图和目标导向的行为。
这种层次结构使得定义动作标签的词汇变得不适,导致动作识别领域的进展比物体识别要慢;详尽地列出高层次的行为事件,是不切实际的。然而,如果我们限制在精细的时间尺度,那么行动是非常自然的,并有清晰的视觉特征。在这里,我们将关键帧标注为1hz,因为它足够密集,可以捕获动作的完整语义内容,同时可以避免对动作边界进行不切实际的精确时间标注。THUMOS challenge[18]观察到动作边界(不像对象)本质上是模糊的,这导致标注人之间存在重大分歧。相比之下,注释人可以很容易地(使用±1.5s的上下文)确定一个帧是否包含给定的动作。AVA有效地将动作起始点和结束点定位到可接受的精确度(±0.5 s)。
以人为中心的行动时间序列。虽然像树木倒下这样的事件并不涉及到人,但我们关注的是作为单一主体的人的活动。在运动中可能会有很多人,或者两个人拥抱,我们分别对每个人单独处理。随时间分配给一个人的动作标签是时态建模的丰富数据来源(第4.3节)。
标注的电影。理想情况下,我们想要“in wild”的行为。我们没有这些,但电影可以作为一个近似,特别是当我们考虑到类型的多样性和国家的繁荣电影业。我们认为在这个过程中会有一些偏差。故事必须有趣,并且有一种通过镜头并置来交流的电影语言[2]的语法。也就是说,在每一个镜头中,我们都能看到人类行为的一个展开序列,在某种程度上代表了现实,就像有能力的演员所传达的那样。AVA补充了目前来自用户生成视频的数据集,因为我们希望电影包含更大范围的活动,以适合讲述不同的故事。
详尽的动作标签。我们在所有关键帧中标注所有人的所有行为。这自然会导致不同行动类别间的Zipf法则类型的不平衡。典型的动作(站立或坐着)会比令人难忘的动作(danc- ing)多很多,但应该是这样的!识别模型需要在真实的“长尾”动作分布[15]上操作,而不是使用人工平衡的数据集搭建支架。另一个结果是,由于我们没有通过明确查询互联网视频资源,来检索某些特定动作类别的例子,于是就避免了某种偏见:打开一扇门是电影剪辑中经常发生的常见事件;然而,一个在YouTube上被标记为“开门”的行为可能是值得关注的,并使其成为非典型。
我们认为,AVA以其现实的复杂性,暴露了该领域中许多流行的数据集隐藏的行动识别的固有困难。在一段视频中,一个人在典型背景下执行一个视觉上明显的动作,比如游泳,很容易与一个正在跑步的人区分开来。与AVA相比,在AVA中,我们会遇到多个演员,他们的图像尺寸很小,表演的动作只有细微的不同,比如触摸和拿着一个物体。为了验证这一直觉,我们对JHMDB[20]、UCF101-24类[32]和AVA进行了比较。我们在建立在多帧方法的基础上[16,41],构建时-空动作定位的方法(见第5节),但将tubelet与I3D卷积[6]进行了分类。我们在JHMDB[20]和UCF101-24[32]上获得了最好的性能(见第6节),而在AVA上只有15.6%。
AVA数据集已经在https: //research.google.com/ava/上公开发布。
相关工作
动作识别的数据集。最流行的动作分类数据集,如KTH [35], Weizmann [4], Hollywood-2 [26], HMDB [24], UCF101[39],都是由短的视频片段组成,手工修剪以捕捉单个动作。这些数据集是“理想型的”适合训练完全监督、全剪辑、强制选择的视频分类器。最近,像TrecVid MED [29], Sports- 1M [21], YouTube-8M [1], Something-something [12], SLAC [48], Moments in Time[28],和Kinetics[22]这样的数据集中在大规模的视频分类上,通常带有自动生成的——因此可能有噪声的——标注。它们服务于一个有价值的目的,但解决了与AVA不同的需求。
最近的一些工作已经转向了时间定位。ActivityNet [5], THUMOS [18], MultiTHUMOS[46]和Charades[37]使用大量未修剪的视频,每个都包含多个动作,这些动作要么来自YouTube (ActivityNet, THUMOS, MultiTHUMOS),要么来自众包演员(哑谜游戏)。数据集为感兴趣的每个动作提供了时间(而不是空间)定位。AVA与它们不同,因为我们为每个执行动作的受试者提供了时-空标注,标注是超过15分钟的密集片段。
CMU[23]、MSR Actions[47]、UCF Sports[32]、JHMDB[20]等数据集为短视频提供了每帧的时-空标注。与我们的AVA数据集的主要区别是:动作的数量少;少量的视频剪辑;而且视频都很短。此外,动作是复合的(例如撑杆跳),而不是AVA中的原子动作。最近的扩展,如UCF101 [39], DALY[44]和Hol- lywood2Tubes[27]评估未修剪视频中的时-空定位,这使得任务变得非常困难,并导致性能下降。但是,它们的动作词汇表仍然限于有限数量的复合动作。此外,它们没有密集地覆盖动作;一个很好的例子是UCF101中的扣篮,其中只有扣篮球员被标注。但是,真实的应用程序通常需要对所有人的原子操作进行连续的标注,然后可以将其组合成更高级的事件。这促使AVA对15分钟的片段进行详尽的标注。
AVA也与静态图像动作识别数据集有关[7,9,13],但这些数据集有两方面的局限性。第一,动作的缺乏会使动作的消歧变得困难。其次,在静态图像中不可能将复合事件建模为原子动作序列。这可能超出了我们的讨论范围,但在许多实际应用中,AVA确实提供了训练数据,这显然是必需的。
时-空动作定位方法。最近的方法[11,30,34,43]依赖于对象检测器,经过训练可以在帧级用双流变体区分动作类,分别处理RGB和流数据。每帧检测的结果,通过动态规划[11,38]或跟踪[43]进行链接。所有这些方法都依赖于集成帧级检测。最近,多帧方法出现了:Tubelets[41]联合估计多个帧的定位和分类,T-CNN[16]使用3D卷积估计短管(short tubes),微管(micro-tubes)依赖于两个连续的帧[33]和姿态引导(pose-guided)的3D卷积将姿态添加到双流( two-stream)方法[49]。我们建立在时-空管的想法上,但采用了最先进的I3D卷积[6]和更快的R-CNN[31]的region proposals,取得了目前最好结果。
数据收集
AVA数据集的注释包括五个阶段:动作词汇的生成,电影和片段的选择,人物边框注释、人物的链接和动作标注。
动作词汇生成
我们遵循三个原则来生成我们的行动词汇。
第一个是一般性。我们收集日常生活场景中的一般动作,而不是特定环境中的特定活动(例如,在篮球场上打篮球)。
第二个是原子性。我们的action类具有清晰的视觉特征,并且通常独立于交互对象(例如,”拿着“而不是”拿着什么东西“)。这使我们的列表简短而完整。
最后一个是穷尽性。我们使用来自以前数据集的知识初始化了列表,并对该列表进行了几轮迭代,直到它覆盖了标注者标注的AVA数据集中约99%的动作。
词汇表中有14个pose类,49个person- object交互类和17个person-person交互类。
影片和片段选择
AVA数据集的原始视频内容来自YouTube。我们首先收集了一份来自不同国家的顶级演员名单。对于每个名字,我们都会发出一个YouTube搜索查询,检索多达2000个结果。我们只包括主题为“电影”或“电视”、时长超过30分钟、上传后至少1年、浏览量至少1000次的视频。我们进一步排除了黑白、低分辨率、动画、卡通和游戏视频,以及那些包含成人内容的视频。
为了在约束内创建具有代表性的数据集,我们的选择标准避免了通过操作关键字、使用自动操作分类器或强制统一的标签分布进行过滤。我们的目标是通过从大型电影行业中取样,创建一个国际性的电影收藏。然而,电影中对动作的描写存在偏差,如性别[10],不能反映人类活动的“真实”分布。
每个电影对数据集的贡献是相等的,因为我们只标注了从15分钟到30分钟的一小部分。我们跳过电影的开头,以避免标注标题或预告片。我们选择15分钟的持续时间,这样我们就能够在固定的标注时间预算下包含更多的电影,从而增加数据集的多样性。将每15分钟的片段以1秒的步长分割成897个重叠的3s电影片段。
人物边框注释
我们用一个边界框来定位一个人和他/她的动作。当一个关键帧中有多个主体(人)时,标注者分别对每个主体(人)进行动作标注,因此他们的动作标签可以不同。
由于边界框标注是手工密集型的,所以我们选择了一种混合方法。首先,我们使用Faster-RCNN检测器(person
detector )[31]生成一组初始人体边界框(bounding boxes)。我们设置了操作点,确保高精度。然后,标注者会对检测器未发现的其他边界框进行标注。这种混合方法确保了所有的边界框召回(这对于 benchmarking来说是必不可少的),同时最小化了手工标注的成本。这个手动标注会多获得5%的边界框,验证了我们的标注方案。在动作标注的下一阶段,标注者将标记并删除任何不正确的边界框。
人的链接注释
我们在短时间内将边界框连接起来,以获得人的动作轨迹 的ground-truth。我们使用人体嵌入法(person embedding)[45]来计算相邻关键帧中边界框之间的成对相似度,并用匈牙利算法(Hungarian algorithm)[25]求解最优匹配。虽然自动匹配通常很强大,但我们通过标注者验证每个匹配,进一步消除了误报(false positives)。这个过程的结果是81,000条轨迹,时间从几秒钟到几分钟不等。
动作标注
动作标签是由众包用户使用图3所示的界面生成的。

左边的面板显示了目标片段的中间帧(顶部)和作为循环嵌入视频的片段(底部)。覆盖在中间帧上的边界框指定需要标记其动作的人。在右边是可输入最多7个动作标签的文本框,包括1个姿势动作pose(必需)、3个人-物交互(可选)和3个人-人交互(可选)。如果没有动作词汇可以表述该动作,则标注者可以标记一个名为“other action”的box。此外,还可以标记包含阻塞或不适当内容或不正确边框的时间段(帧)。
在实践中,我们观察到,当他们要从80个类的大量词汇中找出所有正确的动作时,不可避免地会错过正确的动作。受到[36]的启发,我们将动作标注管道(pipeline)分为两个阶段:动作提出(proposal)和验证(verification)。我们首先要求多个标注者为每个问题提出动作候选项,因此联合这些候选项集合,比单个建议拥有更高的召回率。然后,标注者在第二阶段验证这些建议的候选项。结果显示使用这两阶段的方法有显著的提高,特别是在有较少例子的动作。具体分析见补充材料。平均来说,标注者在proposal阶段花22秒注释一个给定的视频片段,在verification阶段花19.7秒。
每个视频片段由三个独立的标注者进行标注,当一个动作标签被至少两个标注者验证时,我们才将其视为ground truth。标注者随机顺序显示片段。
训练集、验证集和测试集
我们的训练/验证/测试集在视频级别被分割,因此一个视频的所有片段只出现在一个分割中。430个视频被分成235个训练视频、64个验证视频和131个测试视频,大致以55:15:30的方式进行分割,得到211k的训练视频、57k的验证视频和118k的测试视频片段。
AVA数据集的特征
首先通过可视化实例对AVA数据集的多样性和难度建立直觉。然后,我们定量地描述了数据集上的标注。最后,我们探讨行动与时间结构。
多样性和困难

图4显示了在连续视频段中发生变化的原子操作的示例。除了边界框大小和电影技术的变化,许多类别需要区分细微的差别,比如“碰杯”和“喝酒”,或者利用时间背景,比如“打开”和“关闭”。
图4还显示了操作“open”的两个示例。即使在action类中,外观也会因上下文的巨大差异而变化:被打开的对象甚至可能会改变。广泛的类内多样性,可以让我们学习识别一个动作的关键时空部分的特征——比如打开一个的封条对应”open“。
标注的统计数据

图5显示了AVA中动作标注的分布情况。分布大致遵循Zipf定律。

图6说明了边界框(box)大小的分布。很大一部分人占据了整个帧的高度。然而,仍然有许多小尺寸的box。差异性较大可以用变焦水平和姿势来解释。例如,标签为“enter”的方框显示典型的行人高宽比为1:2,平均宽度为图像宽度的30%,平均高度为72%。另一方面,标有“躺/睡”的box接近正方形,平均宽度为58%,高度为67%。box的宽度分布很广,显示了人们在发出动作时所采取的各种姿势。
大多数person边界框都有多个标签。所有边界框都有一个姿态标签,28%的边界框至少有一个人-物交互标签,67%的边界框至少有一个人-物交互标签。
时间结构
AVA的一个关键特征是丰富的时间结构,从一个片段演化到另一个片段。既然我们把人连接在不同的片段之间,我们就可以通过观察同一个人的成对动作,来发现共同的连续动作。
我们采用Normalized Pointwise Mutual Information (NPMI)[8]对成对的动作进行排序。在语言学中,NPMI常用来表示两个单词之间的共现性质:
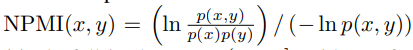
值一般会落在范围内(−1,1),−1表示从不共现的词对,0表示独立的词对,1表示总是共现的词对。
表1显示了同一个人在连续的一秒片段中对NPMI最高的成对动作。

在删除身份转换之后,出现了一些有趣的常见的时间模式。经常会出现从“看电话”到“接电话”、“摔倒”到“说谎”、或“听”到“说话”的过渡。我们也分析了人与人之间的动作对。
表2显示了由不同的人同时执行的NPMI最高的成对动作。

几个有意义的组合出现了,比如“ride”,“drive”,“play music”,“listen”,或者“take”,“give/serve”。尽管存在相对粗糙的时间采样,但原子动作之间的转换,为构建具有较长时间结构的更复杂的动作和活动模型,提供了优秀的数据。
行动定位模型
在流行的动作识别数据集(如UCF101或JHMDB)上的性能在最近几年有了相当大的提高,我们相信,这可以展现出更好性能的美好图景。当视频片段只涉及一个人,在具有点的背景场景中,做一些同样具有视觉特征的事情(比如游泳)时,就很容易准确地进行分类。当有多个演员,或者画面很小,或者表演的动作只有细微的不同,背景场景不足以告诉我们发生了什么时,困难就来了。AVA有很多这样的方面,我们会发现AVA的性能要差得多。事实上,这一发现被Charades dataset[37]的糟糕表现所预示。
为了证明我们的观点,我们开发了一种最先进的动作定位方法,其灵感来自于最近基于多帧时间信息的时空动作定位方法[16,41]。在这里,我们依靠基于I3D[6]的更大时间背景的影响来进行动作检测。我们的方法概述见图7。

在彭和施米德[30]之后,我们使用Faster-RCNN算法[31]对动作进行端到端定位和分类。然而,在他们的方法中,时间信息丢失在第一层,在第一层中多帧的输入是根据时间拼接在一起的。我们提出使用由Carreira和Zisserman[6]设计的Inception 3D (I3D)架构,来建模时间上下文。I3D架构是基于在Inception architecture [40]设计的,但是用3D卷积代替了2D卷积。时间信息在整个网络中被保存。I3D在广泛的视频分类benchmarks上实现了最先进的性能。
为了将I3D与更快的RCNN结合使用,我们对模型进行如下修改:
首先,我们将长度为T的输入帧输入到I3D模型中,在网络的Mixed 4e层提取尺寸为T’×W’×H’×C的3D feature maps。Mixed 4e输出feature map的stride为16,相当于ResNet的conv4块。
其次,在生成action proposal时,我们使用关键帧上的2D ResNet-50模型作为region proposal网络的输入,避免了输入长度不同的I3D对生成的action proposals质量的影响。
最后,对于所有时间的帧,我们将二维ROI Pooling应用于的相同空间位置,从而将ROI Pooling扩展到三维。为了了解光流对动作检测的影响,我们使用平均池将RGB流和光流流在feature map级别融合。
基础为了与AVA上基于帧的两流方法进行比较,我们实现了[30]的一个变种。我们使用Faster RCNN[31]和ResNet-50[14]共同学习 action proposals和动作标签。 action proposals仅通过RGB流获得。区域分类器以连续叠加5帧以上的光流特征作为输入RGB。在我们的I3D方法中,我们通过将conv4 feature map与平均pooling融合,共同训练RGB和光流streams。
实现细节。我们实现了FlowNet v2[19]来提取光流特征。我们用异步SGD训练 Faster-RCNN。对于所有的训练任务,我们使用一个验证集来确定训练步骤的数量,迭代次数从600K到1M不等。我们将输入分辨率固定为320 * 400像素。所有其他模型参数都是基于[17]的推荐值进行设置的,这些值经过了object detection的优化。ResNet-50网络使用ImageNet预训练模型进行初始化。对于光流流,我们复制conv1滤波器输入5帧。对于RGB和光流流,I3D网络使用Kinetics[22]预训练模型进行初始化。注意,尽管I3D是在64帧输入上预先训练的,网络在时间上是完全卷积的,可以接受任意数量的帧作为输入。在训练过程中,所有的特征层都是共同更新的。对输出的帧级检测结果进行后处理,非最大抑制,阈值0.6。
AVA与现有动作检测数据集的一个关键区别是,AVA的动作标签不是相互排斥的。为了解决这个问题,我们将标准的softmax损失函数替换为二值Sigmoid损失的和,每个类一个。我们对AVA使用Sigmoid损失,对所有其他数据集使用softmax损失。
链接。一旦我们有了每帧级的检测结果,我们就把它们连接起来,构建动作管(action tubes)。我们是基于得到的所有tubes的平均分数,来评判视频级别的动作检测性能。我们使用与[38]中描述的相同的链接算法,只是我们不应用时间标记。由于AVA标注为1hz,而且每个管可能有多个标签,我们修改了视频级评估协议来估计一个上限。我们使用ground truth链接来推断detection链接,当计算一个类在ground truth tube和一个detection tube之间的IoU得分时,我们只考虑该类标记的tube片段。
实验和分析
我们现在实验性地分析AVA的关键特征,并激发动作理解的挑战。
数据集和指标
AVA benchmark。由于AVA中的标签分布大致遵循Zipf定律(图5),并且对少量示例的评估可能不可靠,因此我们选择使用在验证和测试分割中至少有25个实例的类,来进行benchmark性能测试。我们的benchmark测试由总共210,634个训练示例、57,371个验证示例和117,441个测试示例组成。除非另有说明,我们报告在训练集上训练的结果和在验证集上评估的结果。我们随机选择10%的训练数据进行模型参数调整。
数据集。除了AVA之外,我们还对标准视频数据集进行了分析,以比较难度。JHMDB[20]由超过21类的928个修剪剪辑的视频组成。在我们的ablation study中,对上述视频进行了切片(split),但是结果是超过三个切片(split)的平均值,并将该值和当前最优结果进行比较。对于UCF101,我们使用Singh等人[38]提供的包含3207个视频的24类子集的时空标注。我们对标准的官方的切片1进行实验。
指标。对于评估,我们在可能的情况下遵循标准做法。我们分别报告了在帧级和视频级的IoU性能。对于帧级IoU,我们遵循PASCAL VOC挑战[9]所使用的标准规则,并使用IoU阈值0.5报告平均精度(AP)。对于每个类,我们计算平均精度,并报告所有类的平均值。对于视频级IoU,我们计算ground truth tubes和linked detection tubes之间的3D IoUs,阈值为0.5。mAP是通过对所有类求平均来计算的。
与state-of-the-art的比较
表3显示了我们的模型在两个标准视频数据集上的性能。

我们的3D双流模型在UCF101和JHMDB上获得了最先进的性能,在frame-mAP和video-mAP度量上,都优于已经建立的基线(baseline)。
然而,在识别原子行为时,情况就不那么乐观了。

由表4可知,同一模型在AVA验证集(frame-mAP为15.6%,video-mAP为12.3%,IoU为0.2,video-mAP为17.9%)和测试集(frame-mAP为14.7%)上性能较差。我们将此归因于AVA背后的设计原则:我们收集的词汇中,上下文和物体线索对动作识别的区别性不强。相反,识别细粒度的细节和丰富的时间模型,需要在AVA上成功,这给视觉动作识别带来了新的挑战。在本文的其余部分,我们分析了AVA的挑战所在,并讨论了如何继续前进。
Ablation study
时间信息对识别AVA类别有多重要? 表4显示了时间长度和模型类型的影响。在JHMDB和UCF101-24上,所有3D模型的性能都优于2D baseline。对于AVA来说,3D模型在使用超过10帧之后表现更好。我们还可以看到,对所有数据集,增加时间窗口的长度让3D双流模型表现更好。正如预期的那样,结合RGB和光流特性提高了单输入模态的性能。此外,如果时间窗口更大,模型在AVA比JHMDB和UCF101性能提高更多,后两者的性能在20帧时达到饱和。这一收益和表1中连续的动作表明,利用AVA中丰富的时间背景,可以获得进一步的收益。
定位VS识别的挑战? 表5比较了端到端动作定位和识别和“与类无关”的动作定位的性能。

我们可以看到,尽管在AVA上动作定位比在JHMDB上更具挑战性。但在AVA上,仅仅定位和端到端检测(定位+识别)性能的差距接近60%,而在JHMDB和UCF101上,差距不到15%。这表明AVA的主要困难在于动作分类而不是定位。图9显示了高得分的假警报示例,表明识别的困难在于细粒度的细节。

结论
本文介绍了AVA数据集,该数据集在不同的15分钟的电影片段中,以1hz的频率对原子行为进行时空标注。此外,在标准数据集上,我们还提出了一种优于state-of-the-art的方法来作为baseline。这种方法突出了AVA数据集的难度,因为它的性能明显低于UCF101或JHMDB,强调了开发新的动作识别方法的必要性。
未来的工作包括基于原子行为建模更复杂的活动。目前的视觉分类技术可能使我们能够在粗糙的场景/视频层面上,对“在餐厅吃饭”等事件进行分类,但基于AVA的精细时空粒度的模型有助于理解个体行为。这些是向计算机灌输“社会视觉智能”的关键步骤——理解人类正在做什么,他们下一步可能做什么,以及他们试图实现什么。
引用论文
[1] S. Abu-El-Haija, N. Kothari, J. Lee, P. Natsev, G. Toderici, B. Varadarajan, and S. Vijayanarasimhan. YouTube8M: A large-scale video classification benchmark. arXiv:1609.08675, 2016. 2
[2] D. Arijon. Grammar of the film language. Silman-James Press, 1991. 2
[3] R. Barker and H. Wright. Midwest and its children: The psychological ecology of an American town. Row, Peterson and Company, 1954. 2
[4] M. Blank, L. Gorelick, E. Shechtman, M. Irani, and R. Basri. Actions as space-time shapes. In ICCV, 2005. 2
[5] F. Caba Heilbron, V. Escorcia, B. Ghanem, and J. C. Niebles. ActivityNet: A large-scale video benchmark for human activity understanding. In CVPR, 2015. 2
[6] J. Carreira and A. Zisserman. Quo vadis, action recognition? A new model and the Kinetics dataset. In CVPR, 2017. 2, 3, 6
[7] Y.-W. Chao, Z. Wang, Y. He, J. Wang, and J. Deng. HICO: A benchmark for recognizing human-object interactions in images. In ICCV, 2015. 3, 8
[8] K.-W. Church and P. Hanks. Word association norms, mutual information, and lexicoraphy. Computational Linguistics, 16(1), 1990. 5
[9] M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge: A retrospective. IJCV, 2015. 3, 7
[10] Geena Davis Institute on Gender in Media. The Reel Truth: Women Aren’t Seen or Heard. https://seejane. org/research-informs-empowers/data/, 2016. 3
[11] G. Gkioxari and J. Malik. Finding action tubes. In CVPR, 2015. 3
[12] R. Goyal, S. E. Kahou, V. Michalski, J. Materzynska, S. Westphal, H. Kim, V. Haenel, I. Frund, P. Yianilos, ¨ M. Mueller-Freitag, F. Hoppe, C. Thurau, I. Bax, and R. Memisevic. The “something something” video database for learning and evaluating visual common sense. In ICCV, 2017. 2, 8
[13] S. Gupta and J. Malik. Visual semantic role labeling. CoRR, abs/1505.04474, 2015. 3
[14] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. 6
[15] G. V. Horn and P. Perona. The devil is in the tails: Finegrained classification in the wild. arXiv:1709.01450, 2017. 2
[16] R. Hou, C. Chen, and M. Shah. Tube convolutional neural network (T-CNN) for action detection in videos. In ICCV, 2017. 2, 3, 6, 7
[17] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, and K. Murphy. Speed/accuracy trade-offs for modern convolutional object detectors. In CVPR, 2017. 6
[18] H. Idrees, A. R. Zamir, Y. Jiang, A. Gorban, I. Laptev, R. Sukthankar, and M. Shah. The THUMOS challenge on action recognition for videos “in the wild”. CVIU, 2017. 2
[19] E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox. FlowNet 2.0: Evolution of optical flow estimation with deep networks. In CVPR, 2017. 6
[20] H. Jhuang, J. Gall, S. Zuffi, C. Schmid, and M. Black. Towards understanding action recognition. In ICCV, 2013. 2, 3, 7
[21] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014. 2
[22] W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev, M. Suleyman, and A. Zisserman. The Kinetics human action video dataset. arXiv:1705.06950, 2017. 2, 6
[23] Y. Ke, R. Sukthankar, and M. Hebert. Efficient visual event detection using volumetric features. In ICCV, 2005. 3
[24] H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre. HMDB: A large video database for human motion recognition. In ICCV, 2011. 2
[25] H. W. Kuhn. The Hungarian method for the assignment problem. Naval Research Logistics (NRL), 2(1-2):83–97, 1955. 4
[26] M. Marszalek, I. Laptev, and C. Schmid. Actions in context. In CVPR, 2009. 2
[27] P. Mettes, J. van Gemert, and C. Snoek. Spot On: Action localization from pointly-supervised proposals. In ECCV, 2016. 3
[28] M. Monfort, B. Zhou, S. A. Bargal, T. Yan, A. Andonian, K. Ramakrishnan, L. Brown, Q. Fan, D. Gutfruend, C. Vondrick, et al. Moments in time dataset: one million videos for event understanding. 2
[29] P. Over, G. Awad, M. Michel, J. Fiscus, G. Sanders, W. Kraaij, A. Smeaton, and G. Quenot. TRECVID 2014 – ´ an overview of the goals, tasks, data, evaluation mechanisms and metrics, 2014. 2
[30] X. Peng and C. Schmid. Multi-region two-stream R-CNN for action detection. In ECCV, 2016. 3, 6, 7
[31] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015. 3, 4, 6
[32] M. Rodriguez, J. Ahmed, and M. Shah. Action MACH: a spatio-temporal maximum average correlation height filter for action recognition. In CVPR, 2008. 2, 3
[33] S. Saha, G.Sing, and F. Cuzzolin. AMTnet: Action-microtube regression by end-to-end trainable deep architecture. In ICCV, 2017. 3
[34] S. Saha, G. Singh, M. Sapienza, P. Torr, and F. Cuzzolin. Deep learning for detecting multiple space-time action tubes in videos. In BMVC, 2016. 3
[35] C. Schuldt, I. Laptev, and B. Caputo. Recognizing human actions: a local SVM approach. In ICPR, 2004. 2
[36] G. Sigurdsson, O. Russakovsky, A. Farhadi, I. Laptev, and A. Gupta. Much ado about time: Exhaustive annotation of temporal data. In Conference on Human Computation and Crowdsourcing, 2016. 4
[37] G. Sigurdsson, G. Varol, X. Wang, A. Farhadi, I. Laptev, and A. Gupta. Hollywood in homes: Crowdsourcing data collection for activity understanding. In ECCV, 2016. 2, 6
[38] G. Singh, S. Saha, M. Sapienza, P. Torr, and F. Cuzzolin. Online real-time multiple spatiotemporal action localisation and prediction. In ICCV, 2017. 3, 7
[39] K. Soomro, A. Zamir, and M. Shah. UCF101: A dataset of 101 human actions classes from videos in the wild. Technical Report CRCV-TR-12-01, University of Central Florida, 2012. 2, 3
[40] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In CVPR, 2016. 6
[41] V.Kalogeiton, P. Weinzaepfel, V. Ferrari, and C. Schmid. Action tubelet detector for spatio-temporal action localization. In ICCV, 2017. 2, 3, 6, 7
[42] L. Wang, Y. Qiao, X. Tang, and L. Van Gool. Actionness estimation using hybrid fully convolutional networks. In CVPR, 2016. 7
[43] P. Weinzaepfel, Z. Harchaoui, and C. Schmid. Learning to track for spatio-temporal action localization. In ICCV, 2015. 3
[44] P. Weinzaepfel, X. Martin, and C. Schmid. Towards weaklysupervised action localization. arXiv:1605.05197, 2016. 3
[45] L. Wu, C. Shen, and A. van den Hengel. PersonNet: Person re-identification with deep convolutional neural networks. arXiv preprint arXiv:1601.07255, 2016. 4
[46] S. Yeung, O. Russakovsky, N. Jin, M. Andriluka, G. Mori, and L. Fei-Fei. Every moment counts: Dense detailed labeling of actions in complex videos. IJCV, 2017. 2
[47] J. Yuan, Z. Liu, and Y. Wu. Discriminative subvolume search for efficient action detection. In CVPR, 2009. 3
[48] H. Zhao, Z. Yan, H. Wang, L. Torresani, and A. Torralba. SLAC: A sparsely labeled dataset for action classification and localization. arXiv preprint arXiv:1712.09374, 2017. 2
[49] M. Zolfaghari, G. Oliveira, N. Sedaghat, and T. Brox. Chained multi-stream networks exploiting pose, motion, and appearance for action classification and detection. In ICCV, 2017. 3