专家经验评分,无论是风控初期冷启动情况,还是对于数据量较少的信贷场景,典型如小微信贷场景等,都是较为不错的实现方法,本次文章我们将介绍两种最常用到的专家经验评分卡。分别是:
①基于ODDS的专家经验的评分卡
②基于层次分析法的专家经验的评分卡
一:基于ODDS的专家经验的评分卡
用违约率跟ODDS就能做具体的变量打分。这个内容在之前的文章有介绍过:基于ODDS的专家经验的评分卡先展示下评分结果,再拆解下具体的算法过程。具体的表格的呈现结果:

上面展示的结果,主要由两部分组成:
Part1:每个变量的评分,而且具体同个变量,因为不同的取值都会有不同的分值;
Part2:评分之后的额度授信情况。
以下详细来介绍Part1,如何进行变量的评分。
1.1.ODDSODDS,比率。基于部分读者因为没有做过模型,为了将此概念介绍清楚,详细介绍下他的来源。Odds,可能性,机会,机率,概率,统计学上称为发生比。Wiki这样解释:在统计和概率理论中,一个事件或者一个陈述的发生比(英语:odds)是该事件发生和不发生的比率,公式为:P/(1-P),P是该事件或陈述的概率)。例如,如果一个人随机选择一星期7天中的一天,选择星期日的发生比是:
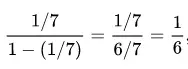
不选择星期日的发生比6:1。发生比其实是一种相对概率。一般来说,普通大众不太使用发生比来描述概率。发生比可以用小数表示,也可以用比率表示。例如0.25或者1:4。那ODDS跟我们此次所使用的算法又有什么关系?做过模型的同学就比较了解,在评分模型使用的逻辑回归的算法中求出来的概率P,如上面介绍,在经过转化之后就能转化成ODDS,如下:

而odd是加上LN转换之后才能变成每个多项式的累加:
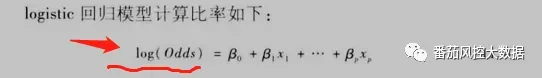
所以,ODDS显得特别重要。原来算出来P之后,还需要算出1-P,才能得到ln(odds),最后才能算出来整个模型的分值。1.2.违约率巧妙运用接下来的一个步骤,是整一part最关键的一步:引入每个变量的违约率。

最后我们在基于经验的转化为标准化的分数的时候,我们巧妙的引入每个变量的逾期率,让逾期率替换掉逻辑回归跑出来的整体违约率,并求出求具体的ODDS。
1.3.确定A跟B的系数最后关键的一步了,求标准分数转换中的A跟B.首先先介绍下A跟B是什么样的系数。
因为标准的分数转化实际如下所示,具体的分值前都带有系数A跟B,大家可以理解为调整的系数,此系数的作用为方便调整分数的比例跟大小等。

试想一下,如果没有A跟B,直接score=B1X1+B2X2+B3*X3,不能让我们随着自己的喜好偏移和缩小倍数,因此我们发明了A跟B这两个系数。那如何求A跟B的系数,在标准的评分模型中,根据两个等式就能知道如果求系数,如:

上图中,P、log、pdo都是已知的,所以有两个一元一次方程求两个系数,能得到结果。所以参考这样的思路模式,我们将求系数的方法运用到此次的经验评分中。我们依葫芦画瓢,也将违约率跟ODDS的两个等式列好,两个等式分是,设定的最高分、与设定的平均分,还有对应的ODDS:
上述图表中,最右边标黄的odds是根据公式算出来的,各位读者,理解完ODDS的求导后,应该能根据逾期率来算这个odds了。并且通过设置的最高分与平均分,这两者关系求出A与B的值。
二:基于层次分析法的专家经验的评分卡
基于层次分析法(AHP)是在业务初期没有表现数据,决定用该方法来确定客户的风险情况。层次分析法,是目前最简单的方法。
目前该流程主要有两个步骤:
①定权重
②算评分
2.1.定权重
根据各因素相对重要性对其进行打分,确定各因素相对重要性的权重(采用1-9标度法),如下表:
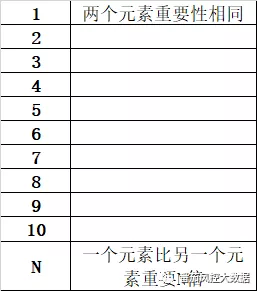
以上采取的用人工经验来量化比较两个元素重要性,当A维度跟B维度同等重要就标识为1,如果A维度比B维度稍为重要就为2,然后重要性依次往上叠加,最高量化值为10。
于是根据这个量化比较情况,可以得到以下分析数据。本次我们以某车贷的数据来稍作重要性解释。在评估维度中主要涉及以下维度:
a.是否有车
b.教育程度
C.手机验证性
d.运营商联系人归属地与申请地一致的比例
e.性别
f.家庭联系人运营商中常用联系人主叫时长占比
h.外部通用评分
i.内部评分
g.线上评分
k.车辆估值
根据以上评估,得到以下分析报表:

一致性检验
两两比较矩阵的元素是通过两个因素比较得到的,而在很多这样的比较中,往往可能得到一些不一致性的结论。
例如,当因素A、B、C的重要性很接近的时候,在两两比较时,可能得出A比B重要,B比C重要,而C又比A重要等矛盾的结论,这在因素的数目多的时候更容易发生。
在做一致性检验的时候,本次我们引入矩阵规范化,得到结果数据如下:
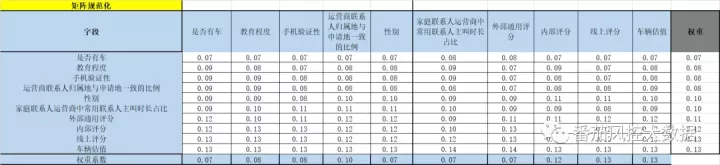
本次通过一致性校验,我们发现权重中的一致性结果分析如下:

通过查询CR相关的评估相关表,如下:
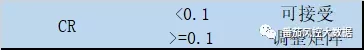
CR=0.001<0.1
即通过一致性检验。
其中:IR的取值如下表:
2.2.算评分
在算出以上的评估的权重后,最重要的部分就是根据权重定出以下的各维度的分数:

专家经验评分,无论是哪种方式都是对目前数据量较少的信贷场景较有用的处理方法,特别是在小微场景中,因为小微企业的数据量相比零售信贷少,许多业务模式也在较早期,于是就给专家经验的评分带来需求场景。
关于以上所涉及到的两大专家经验的评分报表,看得是否过瘾,本次文档参阅至至星球文档:

而关于以上内容中具体的方法讲解,可关注:《小微风控训练营》。
我们会更详细为大家讲解细则化的内容,包括一致性的计算过程,如何更好地衡量两个维度之间的重要性等。

~原创文章
…
end