文章目录
- 需求
- 概念
- 思想
- 问题
- 优点
- 缺点
- 应用
- 手写布隆过滤器
- 补充
需求
现在客户康宝有一个需求:世界上大概有 1 亿 种小蛋糕,康宝要求这辈子不吃重复种类的小蛋糕。
因为小蛋糕的种类很大可能只会增加,而不会减少,面对这种大数据量的要求以及结果无非是true还是false的难题,所以应该首选布隆过滤器。
考虑到甜品行业的发展以及人们生活水平的提高,蛋糕的种类很有可能成指数性增长,那么我们假设世界上有10亿种小蛋糕。
为了更好的满足康宝的需求,我们提供三种实现方案:
- 手写布隆过滤器
- Guava实现
- Redis实现(具体见下文)
概念
布隆过滤器是一个很长的二进制向量和一系列随机映射函数。用于检索一个元素是否在一个集合中。优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
思想
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
问题
Hash面临的问题就是冲突。假设Hash函数是良好的,如果我们的位阵列长度为m个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳m / 100个元素。显然这就不叫空间效率了(Space-efficient)了。解决方法也简单,就是使用多个Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外, Hash函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,只是存储其是否存活,在某些对保密要求非常严格的场合有优势。
布隆过滤器可以表示全集,其它任何数据结构都不能。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。常见的补救办法是建立一个小的白名单,存储那些可能被误判的元素。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。

应用
统计在线人数,网页URL的去重,垃圾邮件的判别,集合重复元素的判别,查询加速(比如基于key-value的存储系统)、缓存穿透, 使用BloomFilter来减少不存在的行或列的磁盘查找,判断用户是否阅读过某视频或文章。
手写布隆过滤器
public class MyBloomFilter {/*** 一个长度为10 亿的比特位*/private static final int DEFAULT_SIZE = 256 << 22;/*** 为了降低错误率,使用hash算法,定义一个100内的质数数组*/private static final int[] seeds = {2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97};/*** 相当于构建 8 个不同的hash算法*/private static final HashFunction[] functions = new HashFunction[seeds.length];/*** 初始化布隆过滤器的 bitmap*/private static final BitSet bitset = new BitSet(DEFAULT_SIZE);/*** 添加数据** @param value 需要加入的值*/public static void add(String value) {if (value != null) {for (HashFunction f : functions) {//计算 hash 值并修改 bitmap 中相应位置为 truebitset.set(f.hash(value), true);}}}/*** 判断相应元素是否存在** @param value 需要判断的元素* @return 结果*/public static boolean contains(String value) {if (value == null) {return false;}boolean ret = true;for (HashFunction f : functions) {ret = bitset.get(f.hash(value));//一个 hash 函数返回 false 则跳出循环if (!ret) {break;}}return ret;}static void create() {for (int i = 0; i < seeds.length; i++) {functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]);}}static class HashFunction {private final int size;private final int seed;public HashFunction(int size, int seed) {this.size = size;this.seed = seed;}public int hash(String value) {int result = 0;int len = value.length();for (int i = 0; i < len; i++) {result = seed * result + value.charAt(i);}return (size - 1) & result;}}
}
补充
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
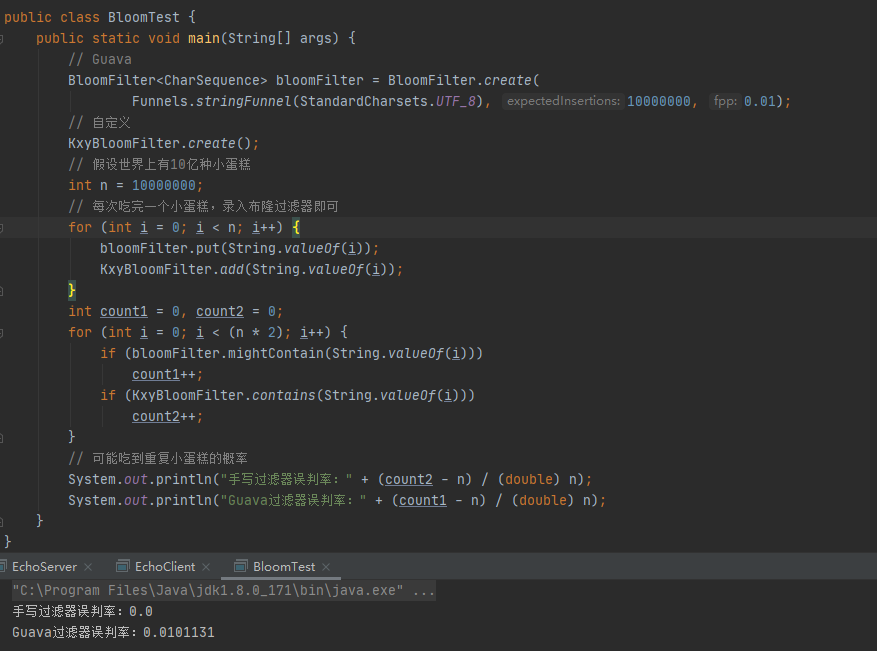
import org.redisson.config.Config;import java.nio.charset.StandardCharsets;public class BloomTest {public static void main(String[] args) {Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:26379");config.useSingleServer().setPassword("myRedis");config.useSingleServer().setDatabase(0);// redisRedissonClient client = Redisson.create(config);RBloomFilter<Object> redisBloomFilter = client.getBloomFilter("bloomNumber");// GuavaBloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), 10000000, 0.01);// 自定义KxyBloomFilter.create();// 假设世界上有10亿种小蛋糕int n = 10000000;// 每次吃完一个小蛋糕,录入布隆过滤器即可for (int i = 0; i < n; i++) {redisBloomFilter.add(String.valueOf(i));bloomFilter.put(String.valueOf(i));KxyBloomFilter.add(String.valueOf(i));}int count1 = 0;int count2 = 0;for (int i = 0; i < (n*2); i++) {if (redisBloomFilter.contains(String.valueOf(i))) {count1++;}if (bloomFilter.mightContain(String.valueOf(i))) {count1++;}if (KxyBloomFilter.contains(String.valueOf(i))) {count2++;}}// 可能吃到重复小蛋糕的概率System.out.println("手写过滤器误判率:" + (count2 - n) / (double) n);System.out.println("Redis过滤器误判率:" + (count1 - n) / (double) n);System.out.println("Guava过滤器误判率:" + (count1 - n) / (double) n);}
}