论文地址:2203.05625 (arxiv.org)
代码地址:megvii-research/PETR: [ECCV2022] PETR: Position Embedding Transformation for Multi-View 3D Object Detection & [ICCV2023] PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images (github.com)
DETR3D由DETR框架扩展而来,对象查询预测的3D参考点,通过相机参数投影回图像空间,并用于从所有相机视图中对2D特征进行采样,如图1b。
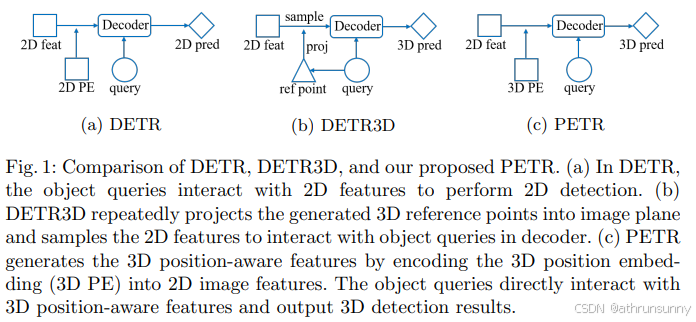
然而,DETR3D中的这种 2D 到 3D 转换可能会带来几个问题:
1、参考点的预测坐标可能不是那么准确,导致采样的特征超出目标区域。
2、只会收集投影点处的图像特征,这无法从全局视图中学习到更多的特征。
3、复杂的特征采样程序将阻碍检测器的实际应用。
与DETR3D 相比,本文所提出的 PETR 架构带来了许多优势 。它保留了原始 DETR 的端到端精神,同时避免了复杂的 2D 到 3D 投影和特征采样。在推理期间,可以离线生成 3D 位置坐标,并用作额外的输入位置嵌入。实际应用相对容易。
本文的主要贡献如下:
1、通过对 3D 坐标进行编码,将多视图特征转换为 3D 域。可以通过与 3D 位置感知特征交互来更新对象查询,并生成 3D 预测。
2、为多视图 3D 目标检测引入了新的 3D 位置感知表示。引入了一个简单的隐式函数,将 3D 位置信息编码为 2D 多视图特征。

PETR的整体架构如上,多视图图像由车载的六个相机获得,多视图图像被输入到骨干网络(例如 ResNet)以提取多视图 2D 图像特征。在 3D 坐标生成器中,所有视图共享的相机视锥体空间被离散化为 3D 网格。网格坐标由不同的相机参数转换,从而产生 3D 世界空间中的坐标。然后将 2D 图像特征和 3D 坐标输入到 3D 位置编码器中,以生成 3D 位置感知特征。从查询生成器生成的对象查询通过与 transformer 解码器中的 3D 位置感知特征交互进行更新。更新的query进一步用于预测 3D bbox和class。
3D Coordinates Generator
架构图左下角即为本文的创新点,

该部分相应的代码如下:
def position_embeding(self, img_feats, img_metas, masks=None): # img_feats:[torch.Size([1, 6, 256, 20, 50]), torch.Size([1, 6, 256, 10, 25])]eps = 1e-5pad_h, pad_w, _ = img_metas[0]['pad_shape'][0] # (320, 800, 3)B, N, C, H, W = img_feats[self.position_level].shape # torch.Size([1, 6, 256, 20, 50])coords_h = torch.arange(H, device=img_feats[0].device).float() * pad_h / Hcoords_w = torch.arange(W, device=img_feats[0].device).float() * pad_w / Wif self.LID:index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()index_1 = index + 1bin_size = (self.position_range[3] - self.depth_start) / (self.depth_num * (1 + self.depth_num))coords_d = self.depth_start + bin_size * index * index_1 # 深度信息else:index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()bin_size = (self.position_range[3] - self.depth_start) / self.depth_numcoords_d = self.depth_start + bin_size * indexD = coords_d.shape[0]# coords = torch.stack(torch.meshgrid([coords_w, coords_h, coords_d])).permute(1, 2, 3, 0) # W, H, D, 3 # torch.Size([50, 20, 64, 3])torch_1_10 = check_version(torch.__version__, '1.10.0')if not torch_1_10: # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibilitycoords = torch.stack(torch.meshgrid([coords_w, coords_h, coords_d])).permute(1, 2, 3, 0).contiguous() # W, H, D, 3 torch.Size([50, 20, 64, 3])else:coords = torch.stack(torch.meshgrid([coords_w, coords_h, coords_d], indexing='ij')).permute(1, 2, 3, 0).contiguous() # W, H, D, 3 torch.Size([50, 20, 64, 3])coords = torch.cat((coords, torch.ones_like(coords[..., :1])), -1) # torch.Size([50, 20, 64, 4]) 转为齐次coords[..., :2] = coords[..., :2] * torch.maximum(coords[..., 2:3], torch.ones_like(coords[..., 2:3])*eps)# coords:一开始在50*20尺寸的特征图上每个网格处均匀分布了64个伪3d空间点(x,y,z,1)【因为此时还是在像素坐标系下】,深度信息z为假设值,最大范围为点云空间的最大值(61.2-1)内(为接近60的浮点数),之后在x,y上乘深度z,则以z的倍率产生视锥(对应论文的图例)img2lidars = []for img_meta in img_metas:img2lidar = []for i in range(len(img_meta['lidar2img'])):img2lidar.append(np.linalg.inv(img_meta['lidar2img'][i])) # 旋转矩阵为正交矩阵,R.T = R 像素坐标到雷达坐标的旋转矩阵 将像素点转换为3d空间点img2lidars.append(np.asarray(img2lidar))img2lidars = np.asarray(img2lidars)img2lidars = coords.new_tensor(img2lidars) # (B, N, 4, 4) # torch.Size([1, 6, 4, 4])coords = coords.view(1, 1, W, H, D, 4, 1).repeat(B, N, 1, 1, 1, 1, 1) # torch.Size([50, 20, 64, 4])->torch.Size([1, 6, 50, 20, 64, 4, 1])img2lidars = img2lidars.view(B, N, 1, 1, 1, 4, 4).repeat(1, 1, W, H, D, 1, 1) # torch.Size([1, 6, 4, 4])->torch.Size([1, 6, 50, 20, 64, 4, 4])coords3d = torch.matmul(img2lidars, coords).squeeze(-1)[..., :3] # 将像素坐标转为3d空间点coords3d[..., 0:1] = (coords3d[..., 0:1] - self.position_range[0]) / (self.position_range[3] - self.position_range[0]) # 将空间点归一化到点云最大范围内,预设为122.4(61.2 - -61.2)coords3d[..., 1:2] = (coords3d[..., 1:2] - self.position_range[1]) / (self.position_range[4] - self.position_range[1])coords3d[..., 2:3] = (coords3d[..., 2:3] - self.position_range[2]) / (self.position_range[5] - self.position_range[2]) # 高度范围为20(10 - -10)coords_mask = (coords3d > 1.0) | (coords3d < 0.0) # 用于过滤点云范围之外的点 torch.Size([1, 6, 50, 20, 64, 3])coords_mask = coords_mask.flatten(-2).sum(-1) > (D * 0.5) # torch.Size([1, 6, 50, 20])coords_mask = masks | coords_mask.permute(0, 1, 3, 2) # 用于过滤图像padding部分所对应的点coords3d = coords3d.permute(0, 1, 4, 5, 3, 2).contiguous().view(B*N, -1, H, W) # torch.Size([1, 6, 50, 20, 64, 3])->torch.Size([6, 192, 20, 50])coords3d = inverse_sigmoid(coords3d)coords_position_embeding = self.position_encoder(coords3d) # 通过卷积进行编码 torch.Size([6, 256, 20, 50])# Sequential((0): Conv2d(192, 1024, kernel_size=(1, 1), stride=(1, 1)) (1): ReLU() (2): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1)))return coords_position_embeding.view(B, N, self.embed_dims, H, W), coords_mask # torch.Size([1, 6, 256, 20, 50]) torch.Size([1, 6, 20, 50])其中预设的3d空间点先由backbone提取到的特征图尺寸来确定,比如VoVNet提取的倒数第二层的特征图大小(20*50),此处以输入的图像尺寸(320*800)为例,并由20*50的特征图大小生成均匀的网格(类似yolov5中anchor的生成方式)。
由于深度信息未知,深度由如下方式设置
index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()
index_1 = index + 1
bin_size = (self.position_range[3] - self.depth_start) / (self.depth_num * (1 + self.depth_num))
coords_d = self.depth_start + bin_size * index * index_1 # 深度信息主要就是根据点云的x的最大值以及预设的深度(64)来计算每个bin的大小,生成离散化的点,之后再乘上由深度产生的index得到预设的深度coords_d,coords_d方向沿与图像平面正交的轴。之后将coords_w, coords_h, coords_d合并成一个3d点坐标coords。
coords:一开始在50*20尺寸的特征图上每个网格处均匀分布了64个伪3d空间点(x,y,z,1)【因为此时还是在像素坐标系下】,深度信息z为假设值,最大范围为点云空间的最大值(61.2-1)内(为接近60的浮点数),之后在x,y上乘深度z,则以z的倍率产生视锥(对应论文的图例)
简单讲下坐标系的转换:

可以将代码中的lidar坐标系看成这里的世界坐标系,实际上NuScenes数据集有自己的世界坐标系。
要计算世界坐标系下的一点(X, Y, Z)到像素坐标系下的位置(u,v),可用以下公式求得:

其中:


此处的对应代码中'lidar2img',其中的K需要转到4*4的齐次矩阵。
coords3d = torch.matmul(img2lidars, coords)
这一步就是将 coords这个像素坐标系下的3d点转到lidar坐标系下,之后再对3D点进行归一化,

之后过滤超出图像的点以及位于相机后方的点。
3D Position Encoder

本文所提出的3D位置编码如上图所示,多视图 2D 图像特征被输入到 1 × 1 卷积层以进行降维。将 3D 坐标生成器生成的 3D 坐标通过多层感知转换为 3D position embedding。3D position embedding与同一视图的 2D 图像特征进行叠加,从而生成 3D 位置感知特征。
Analysis on 3D PE
为了演示 3D PE 的效果,作者在前视图中随机选择三个点的PE,并计算这三个点与所有多视图 PE 之间的 PE 相似性。如图 4 所示,靠近这些点的区域往往具有更高的相似性。例如,当在前视图中选择左点时,前左视图的右侧区域将具有相对较高的响应。它表示 3D PE 隐式地建立了 3D 空间中不同视图的位置相关性。

Experiments

在NuScenes验证集上的结果:

在NuScenes测试集上的结果:

消融实验:








