研究背景
- 研究问题:如何准确预测旋转机械(如轴承)的剩余使用寿命(RUL),这对于设备可靠性和减少工业系统中的意外故障至关重要。
- 研究难点:该问题的研究难点包括:训练和测试阶段数据分布不一致、长期RUL预测的泛化能力有限。
- 相关工作:现有工作主要包括基于模型的方法、数据驱动的方法和混合方法。基于模型的方法依赖于历史数据构建数学或物理模型,但难以准确开发。混合方法结合了数据驱动和模型驱动的方法,但仍需要深入的失效机制分析和广泛的先验知识。数据驱动的方法依赖于监测数据,具有自动学习和提取模式的优势,但在处理数据分布变化和长期预测方面存在局限性。
LM4RUL框架【用于基于预训练的大语言模型(LLM)进行轴承RUL预测】在FEMTO数据集上六个跨条件RUL预测任务中,LM4RUL在所有任务中均表现最佳。与DDAN方法相比,在Task 3中,LM4RUL的性能提高了至少16.22%。
在XJTU-SY数据集上三个跨条件RUL预测任务中,LM4RUL也取得了最佳预测性能。与DDAN方法相比,其预测性能平均提高了36.8%。
如何利用LM用于解决轴承RUL预测问题

LM4RUL框架,用于解决轴承RUL预测问题。具体来说,
- 本地尺度感知表示(LSPR)组件:
本地尺度感知表示(LSPR)组件通过对振动数据进行分块处理,提取时间频率特征,并通过补丁操作将局部退化信息封装成序列输入到预训练的LLM中。具体步骤如下:- FPT检测:首先,使用FPT(First Point of Significant Degradation)检测方法确定轴承开始显著退化的时间点,以界定数据范围。
- 特征提取:使用短时傅里叶变换(STFT)从振动信号中提取时频域特征,公式如下:
X ( t , f ) = ∫ − ∞ + ∞ x ( τ ) w ( τ − t ) e − i 2 π f τ d τ X(t, f)=\int_{-\infty}^{+\infty} x(\tau) w(\tau-t) e^{-i 2\pi f\tau} d\tau X(t,f)=∫−∞+∞x(τ)w(τ−t)e−i2πfτdτ
其中, x ( t ) x(t) x(t) 是信号, w ( τ − t ) w(\tau-t) w(τ−t) 是窗口函数, f f f 表示频率。 - 补丁操作:将提取的时频特征图按固定长度窗口分割成多个子序列,并将每个子序列转换为时间频率特征图。然后将所有特征图沿时间方向拼接,形成退化特征图。接着,将这些特征图重新组织成大小为 D × N × P D \times N \times P D×N×P 的矩阵,其中 D D D 是特征维度, N N N 是时间维度, P P P 是补丁大小。通过补丁操作,模型能够聚焦于局部尺度的退化特征,并将其与全局退化趋势关联起来,从而捕捉更长的历史序列中的退化信息。
通过这些步骤,LSPR组件能够有效地将局部退化信息转化为适合LLM处理的序列,增强了LLM在捕捉长时间窗口内的退化趋势和关键退化模式方面的能力,从而提高了轴承RUL预测的准确性。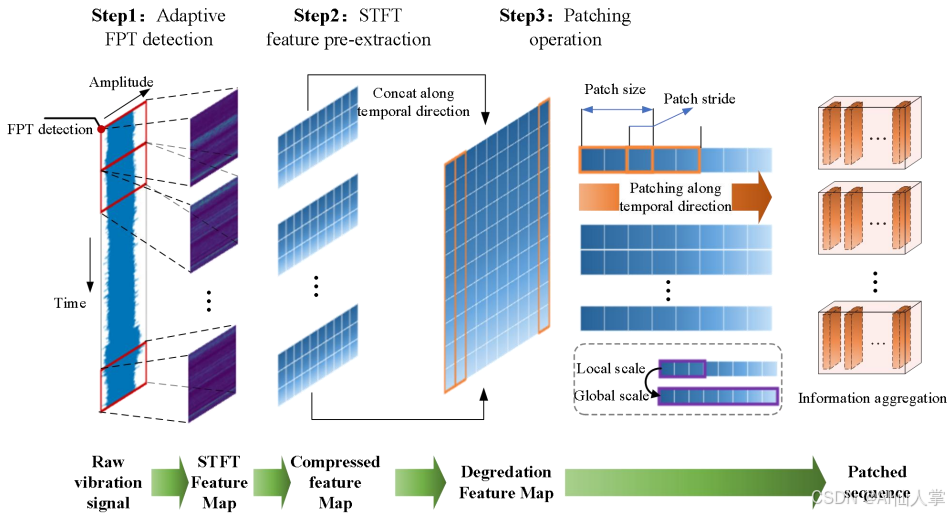
-
混合嵌入学习(FPLM-HEL)组件:FPLM-HEL组件选择性冻结和微调预训练模型的层,保留预测知识并有效建模退化过程中的复杂非线性关系。FPLM-HEL采用三重嵌入方法,增强模型提取和学习抽象退化特征的能力。具体设计如下:
- 输入嵌入模块:将补丁后的退化特征序列输入到输入嵌入模块,提取局部敏感特征和全局退化特征,并结合绝对位置信息和相对时间信息进行编码和嵌入。
- FPLM模块:FPLM模块包含多个堆叠的FPLM块,每个块包含多头自注意力机制和前馈神经网络。在微调阶段,只更新部分层的参数,保留预训练的多头注意力和前馈网络的通用预测知识。具体公式如下:
x ^ j ( i ) = γ j × ( x j ( i ) − E [ x t:L ( i ) ] Var [ x t:L ( i ) ] + ϵ ) + β j \hat{x}_{j}^{(i)}=\gamma_{j}\times\left(\frac{x_{j}^{(i)}-E\left[x_{\text{t:L}}^{(i)}\right]}{\sqrt{\operatorname{Var}\left[x_{\text{t:L}}^{(i)}\right]+\epsilon}}\right)+\beta_{j} x^j(i)=γj×⎝⎜⎜⎛Var[xt:L(i)]+ϵxj(i)−E[xt:L(i)]⎠⎟⎟⎞+βj
其中, γ j , β j \gamma_{j},\beta_{j} γj,βj 表示可学习的仿射变换参数, ϵ \epsilon ϵ 表示很小的正数以避免分母为零。 - 相对位置编码:为了使FPLM模块能够感知相对时间信息,引入了基于旋转矩阵的相对位置编码。
- 可逆实例归一化层(RIN):使用可逆实例归一化层去除数据输入阶段的不稳定性,保留退化特征的通用预测知识。

-
两阶段微调:通过一种两阶段微调策略,逐步激活FPLM-HEL的领域适应能力,并转移预训练的广义预测知识。第一阶段是有监督微调(SFT),保留所有预训练的预测知识;第二阶段是提示微调(PT),使用少量目标域的退化样本引导LLM进行预测。
具体步骤如下:- 监督微调(SFT):在SFT阶段,使用源域数据集对模型进行微调,保留所有预训练的预测知识,并将其转移到下游的RUL预测任务中。SFT阶段的损失函数如下:
L S F T = 1 N s ∑ i = 1 N s ( r S ( i ) − r ~ S ( i ) ) 2 \mathcal{L}_{SFT}=\frac{1}{N_s}\sum_{i=1}^{N_s}\left(r_{\mathcal{S}}^{(i)}-\tilde{r}_{\mathcal{S}}^{(i)}\right)^2 LSFT=Ns1i=1∑Ns(rS(i)−r~S(i))2
其中, N s N_s Ns 是源域数据集的大小, r ~ S ( i ) \tilde{r}_{\mathcal{S}}^{(i)} r~S(i) 是模型预测的RUL值, r S ( i ) r_{\mathcal{S}}^{(i)} rS(i) 是实际的RUL值。 - 提示微调(PT):在PT阶段,使用目标域中的少量退化样本对模型进行微调,激活其泛化能力。PT阶段的损失函数如下:
L P T = 1 N t ∑ i = 1 N t ( r T ( i ) − r ~ T ( i ) ) 2 \mathcal{L}_{PT}=\frac{1}{N_{t}}\sum_{i=1}^{N_{t}}\left(r_{T}^{(i)}-\tilde{r}_{T}^{(i)}\right)^{2} LPT=Nt1i=1∑Nt(rT(i)−r~T(i))2
其中, N t N_{t} Nt 是目标域数据集的大小, r ~ T ( i ) \tilde{r}_{T}^{(i)} r~T(i) 是模型预测的RUL值, r T ( i ) r_{T}^{(i)} rT(i) 是实际的RUL值。
两阶段微调策略的优势在于:
- 逐步适应:通过SFT阶段,模型首先在源域数据上充分学习和适应,保留了预训练的通用预测知识。然后,通过PT阶段,模型在目标域数据上进行微调,进一步激活其泛化能力,适应不同的数据分布。
- 减少计算开销:仅对目标域中的少量样本进行微调,避免了全量数据微调的高计算开销,提高了计算效率。
- 提高泛化能力:两阶段微调策略使模型能够在不同数据分布下逐步适应和学习,从而提高了模型的泛化能力和预测精度。
通过这种设计,LM4RUL框架能够在跨条件数据分布下实现高效的RUL预测,展示了其在实际工业应用中的广泛应用前景。
- 监督微调(SFT):在SFT阶段,使用源域数据集对模型进行微调,保留所有预训练的预测知识,并将其转移到下游的RUL预测任务中。SFT阶段的损失函数如下:
公式解释:
- FPT检测通过计算RMS的 3 σ 3\sigma 3σ区间阈值来确定:
c v t = μ t − 1 ± 3 σ t − 1 = 1 t − 1 ∑ i < t R M S i ± 3 1 t − 1 ∑ i < t ( R M S i − μ t − 1 ) 2 c v_t=\mu_{t-1}\pm 3\sigma_{t-1}=\frac{1}{t-1}\sum_{i<t} R M S_i\pm 3\sqrt{\frac{1}{t-1}\sum_{i<t}\left(R M S_i-\mu_{t-1}\right)^2} cvt=μt−1±3σt−1=t−11i<t∑RMSi±3t−11i<t∑(RMSi−μt−1)2 - 使用STFT提取时频域特征:
X ( t , f ) = ∫ − ∞ + ∞ x ( τ ) w ( τ − t ) e − i 2 π f τ d τ X(t, f)=\int_{-\infty}^{+\infty} x(\tau) w(\tau-t) e^{-i 2\pi f\tau} d\tau X(t,f)=∫−∞+∞x(τ)w(τ−t)e−i2πfτdτ - 能量分布:
E ( t , f ) = ∣ X ( t , f ) ∣ 2 E(t, f)=|X(t, f)|^{2} E(t,f)=∣X(t,f)∣2 - 通过拼接操作将退化特征映射重新组织:
x p ( i ) = ( x p 1 ( i ) , x p 2 ( i ) , … , x p ( i ) ) x_{p}^{(i)}=\left(x_{p 1}^{(i)}, x_{p 2}^{(i)},\ldots, x_{p}^{(i)}\right) xp(i)=(xp1(i),xp2(i),…,xp(i))






