文章目录
目标:
理解:栈的定义与特点
掌握:基本运算的数据结构和算法实现
拓展:栈的经典应用斐波那契函数和归并算法的分治和递归思想
🥧栈的初步理解:
- 只允许在一端进行插入或删除的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。

🥧易错:如何判断栈满
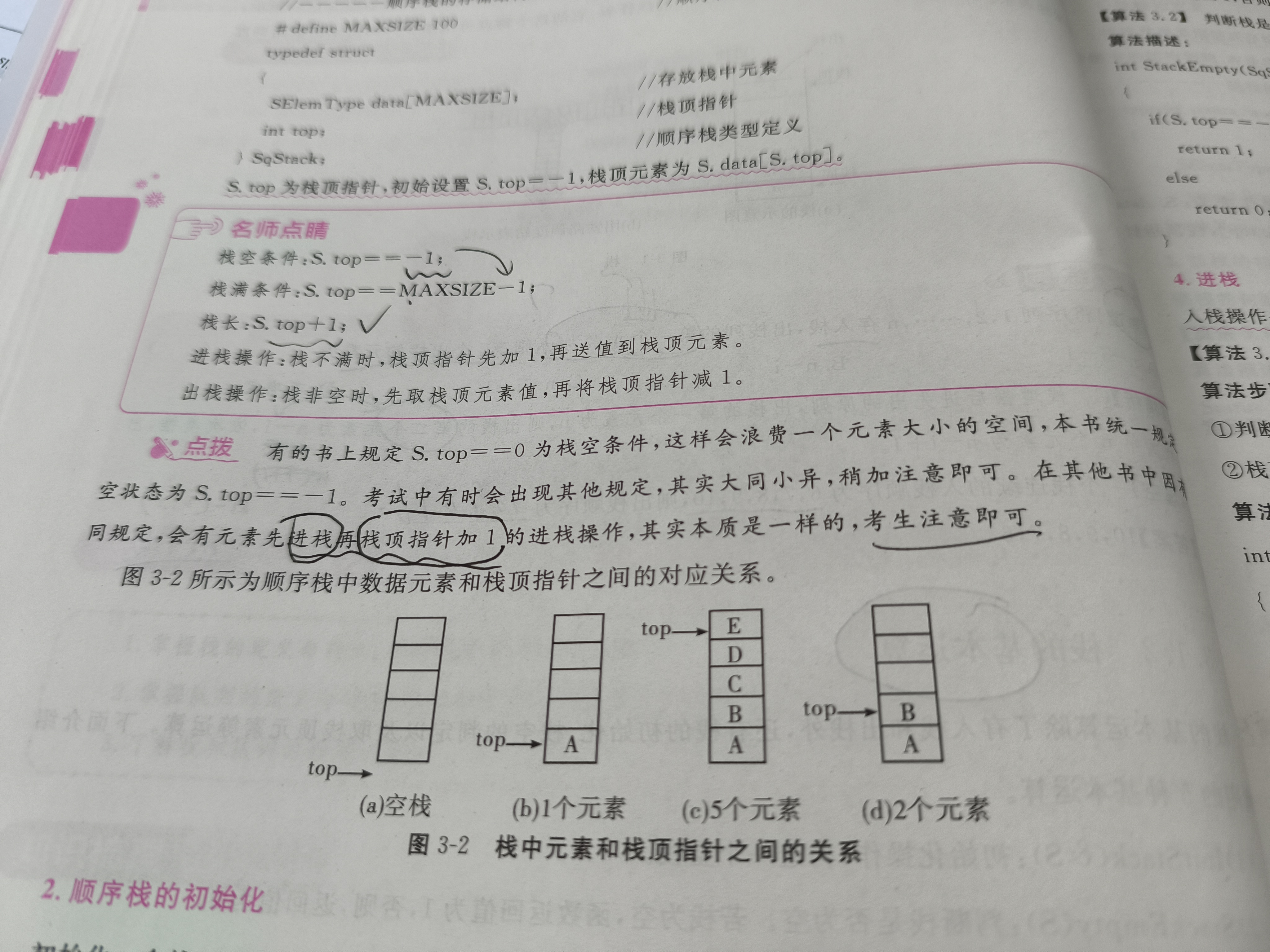
- S.top为栈顶元素,初始设置S.top=-1,栈顶元素为S.data
栈空条件:S.top == -1
栈长:S.top + 1
进栈操作:栈不满时,栈顶指针先加1,再送值到栈顶元素。
出栈操作:栈非空时,先取栈顶元素值,再将栈顶指针减1。
栈满条件:S.top == MAXSIZE - 1//MAXSIZE 是数组的大小,表示栈的最大容量。
🥧栈满理解
假设MAXSIZE 【这个栈最多可以装5个元素数据】为5,即数组可以存储5个元素。数组的索引如下:
- 索引0:第一个元素
- 索引1:第二个元素
- 索引2:第三个元素
- 索引3:第四个元素
- 索引4:第五个元素
当 S.top 为4时,表示栈中已经有5个元素(索引0到索引4),此时栈满。如果尝试再添加一个元素,将导致数组越界,这是一个严重的编程错误。
🥧栈的基本运算
InitStack(&S):初始化操作,构造一个空栈。
StackEmpty(S):判断栈是否为空。如果栈为空,返回1,否则返回0。
Push(&S, x):入栈操作,在栈顶插入一个新元素x。
Pop(&S, &x):出栈操作,删除栈顶元素,并用x返回其值。
GetTop(S, &x):获取栈顶元素的值,返回栈顶元素,但不删除它。
📚栈操作的伪代码逻辑(顺序和链栈)
📕顺序栈运算实现:
- 栈是运算受限的线性表,它也有两种存储表示方式:分别称为顺序栈和链栈
顺序栈的表示:
顺序栈是利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,同时附设指针top指示当前栈顶元素的位置:
顺序栈的定义如下:
#define MAXSIZE.100.
typedef struct
{
SElemType dats【MAXSIZE】
Int top ;//栈顶指针
}SqStack;//顺序栈类型定义
顺序栈的初始化:
只需要将栈顶指针设置为-1即可
void InitStack(SwStack &S) //初始化栈
{
S.top=-1; //初始化栈顶指针
}
判断栈空:
栈S为空时,返回1,否则返回0
int StackEmpty(Sqstaxk S)
{
if(S.top==-1)return 1;
else
return 0;
}
进栈
入栈操作是在栈顶插入一个新的元素
步骤:
①判断栈是否满,若满则返回0
②栈顶指针加1,将新元素压入栈顶int Push(Sqlist &S,SElem Type x) { if(S.top == MAXSIZE-1)//要注意,栈满不能进栈return 0; ++(S.top);//先移动指针,再进栈 S.dara【S.top】 = x; return 1; }
出栈:
出栈:栈顶元素删除
步骤:
①判断栈是否为空,若空则返回0
②栈顶元素出栈,栈顶指针减1int Pop(Sqstack &S,SElem Type &x) //结构体是整个栈,还有一个指针元素 if(S.top==-1)return 0;x,=S.data[S.top]; //先去出元素,再移动指针--(S.top):return 1;
取栈顶元素
- 当栈非空时,此操作返回当前栈顶元素的值,栈顶指针保持不变
int Get(Sqstack S,SElem Type &x)//返回S的栈顶元素,用x记录栈顶元素
{
if(S.top==-1) //栈空return 0;x = S.data[S.top];return 1;
}
📕链栈的表示和实现:
链栈定义:
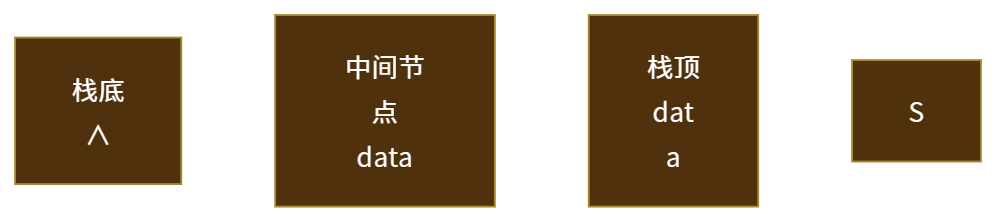
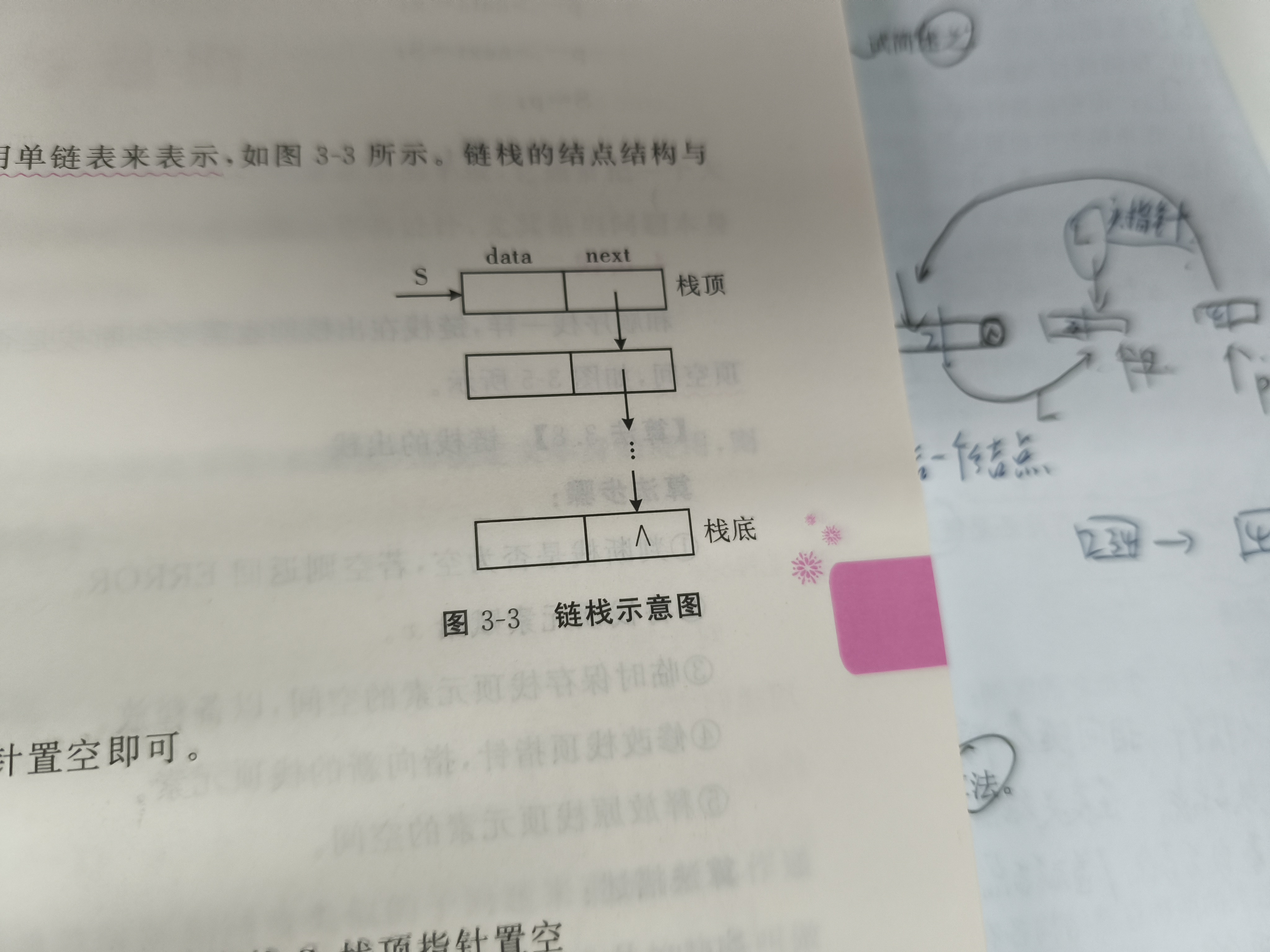
链栈是指采用链式存储结构实现的栈。通常链栈用单链表表示
链栈的节点结构:与单链表的结构相同,用StackNode表示
//链栈的存储结构 typedef struct StackNode {Selem Type data;struct StackNode *next; }Stack,*LinkStack;

链栈初始化
- 同理,链栈的初始化操作就是构造一个空栈,直接将栈顶指针置空即可
Stack InitStack(LinkStack &S) //构造一个空栈S,栈顶指针置空{S=NULL;return OK;
}
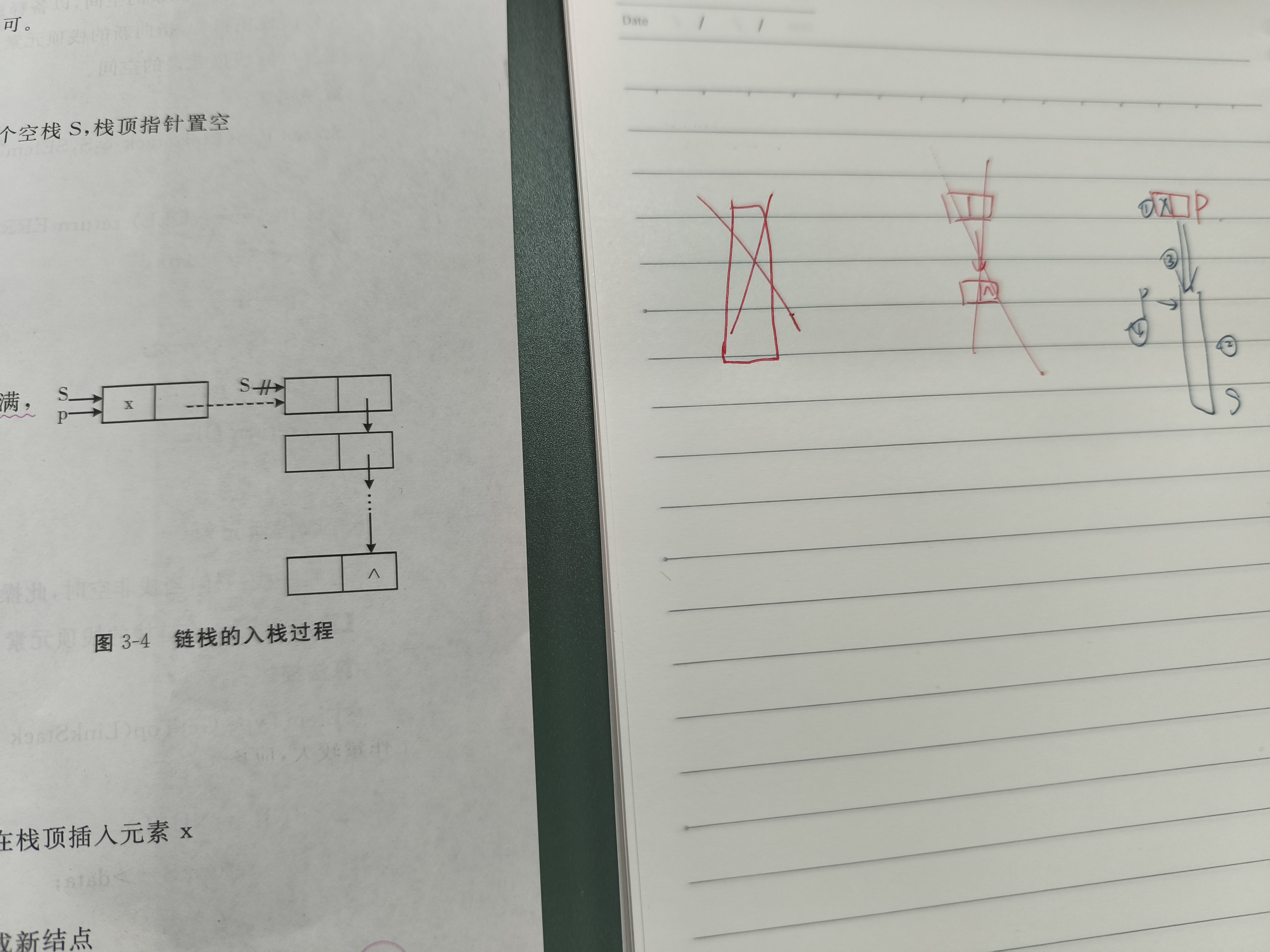
入栈
步骤:
算法描述:
Statue Push(LinkStack &S,SElemType x) //栈顶插入元素x
{
p=new StackNode; //生成新节点
p→data=x; //将新节点数据域置为x
p→next=S; //将新节点插入栈顶
S=p; //修改栈顶指针为p
return OK;
}
出栈
算法步骤:
①判断栈是否为空,若空则返回ERROR
②将栈顶元素赋给x:为什么还需要赋值?
③临时保存栈顶元素空间,以备释放:临时释放
④修改栈顶指针,指向新的栈顶元素
⑤释放原栈顶元素的空间
算法描述:
Status Pop(LinkStack&SElem Type &x)
{
if(S==NULL).return ERROR;
x=S→data;
p=S;
S=S→next; //修改栈顶部元素
delete p; //释放原栈顶元素空间
return OK;
}
取栈顶元素
与顺序栈一样,当栈非空,此操作返回当前栈顶元素的值,栈顶指针S保持不变
因为只是取值
SElemType GetTop(LinkStack S) //返回S的栈顶元素,不修改栈顶指针
{
if(!!=NULL)
return S→data; //返回栈顶元素的值,栈顶指针不变
}
📕区分链栈和顺序栈
- 顺序栈入栈操作不同在于,链栈在入栈前不需要判断栈是否满,只需要为入栈元素动态分配一个结点空间

💡栈与递归与分治法
栈的一个重要应用是在程序设计语言中实现递归。
递归函数的定义:可以理解为函数在自己调用自己。
✍运用递归定义函数
例子:斐波那契函数,就是将复杂问题分解成几个/一个相对简单且解法相同的类似的子问题,这种分解-求解的策略叫做“分治法”。
斐波那契额数列由0和1开始,之后的每个数都是前两个数的和

✍分治法
- “分治法”需要满足的条件:
1、能将一个问题转变成一个新问题,而新问题与原问题的解法
2、可以通过上述转化而使问题简化
3、必须有一个明确的递归出口,或称之为递归的边界
经典例子:归并排序
-
问题分解:将原问题拆分为多个子问题(如归并排序将数组分为左右两半)。
将数组从中间位置(mid = left + (right - left)/2)分为左右两半。 -
递归求解:对子问题调用同一函数(如分别排序左右子数组)。
对左右子数组递归调用归并排序,直到子数组长度为1。 -
最后进行结果合并:将子问题解合并为原问题解(如合并已排序的子数组)。
✍归并算法
- 理解什么是归并
- 问题描述:把两个已经有序的数组a数组和b数组合并到一起,按照从小到大排序
-

- 目标:合并操作
步骤一:
1.定义一个额外的数组c存放a和b合并之后的数组
2.两个指针分别指向两个数组,比较出来两个数组中最小的元素
3.规律:每次比较的其实都是最前面的第一个元素进行比大小

步骤二(第一轮排序)——此时11个子序列
1.分成两两一组,同样先开一个临时数组保存结果,然后进行大小比较 从小到大

- 分析:此时得到了6个有序的子序列

步骤三(第三轮排序)——此时6个子序列
1.同样是开辟临时数组进行存储,然后进行排序(测试,临时数组的长度至少是2+2=4)
以此类推,你会发现,这个过程是重复的,知道最后归并到只有一个子序列的时候,整个序列也就排好序了

- 这个例子中总共会进行4次归并操作
时间和空间复杂度分析:

代码展示
#include <stdio.h>
#include <stdlib.h>// 合并两个有序子数组(核心逻辑)void merge(int* arr, int left, int mid, int right) {int size = right - left + 1;int* temp = (int*)malloc(size * sizeof(int)); // 动态分配临时数组 if (temp == NULL) {fprintf(stderr, "内存分配失败\n");exit(1);}int i = left, j = mid + 1, k = 0;// 双指针比较填充临时数组 while (i <= mid && j <= right) {temp[k++] = (arr[i] <= arr[j]) ? arr[i++] : arr[j++];}// 处理剩余元素 while (i <= mid) temp[k++] = arr[i++];while (j <= right) temp[k++] = arr[j++];// 回写数据到原数组 for (int p = 0; p < size; p++) {arr[left + p] = temp[p];}free(temp); // 释放内存 }// 递归排序函数 void mergeSort(int* arr, int left, int right) {if (left >= right) return; // 终止条件:子数组不可再分 int mid = left + (right - left) / 2; // 防溢出中间点 mergeSort(arr, left, mid); // 递归左半部分 mergeSort(arr, mid + 1, right);// 递归右半部分 merge(arr, left, mid, right); // 合并子数组
}// 测试代码
int main() {int arr[] = {12, 11, 13, 5, 6, 7};int n = sizeof(arr) / sizeof(arr[0]);printf("原始数组: ");for (int i = 0; i < n; i++) printf("%d ", arr[i]);mergeSort(arr, 0, n - 1);printf("\n排序结果: ");for (int i = 0; i < n; i++) printf("%d ", arr[i]);printf("\n");return 0;
}
效果展示:

✏️思考:如何一句实现入栈
元素 x 进栈
S.data[++S.top] = x; // 仅一句即实现进栈操作
这行代码首先将栈顶指针 S.top 加1,然后将元素 x 存入新的栈顶位置。
元素 x 出栈
x = S.data[S.top--]; // 仅一句即实现出栈操作
这行代码首先从栈顶位置取出元素,然后将其赋值给 x,最后将栈顶指针 S.top 减1。
✏️出栈元素下标小测试
将序列1, 2, …, n存入栈,出栈序列的第一个元素为n,则第i个出栈的元素为多少?
A. n - i - 1
B. n - i
C. n - i + 1
D. 不确定
答案:C
解释:
栈遵循后进先出的原则,出栈的第一个元素为n,那么第二个元素应该是n-1,依此类推,第i个出栈的元素应该是n - i + 1
参考:
- https://www.bilibili.com/video/BV1em1oYTEFf/?spm_id_from=333.337.top_right_bar_window_history.content.click&vd_source=a3c586fed65f87bb08210d97921e6847
- 《数据结构与算法》教材
- https://labuladong.online/algo/essential-technique/understand-recursion/
- https://www.bilibili.com/video/BV1BWNSeuEsi?spm_id_from=333.788.player.switch&vd_source=a3c586fed65f87bb08210d97921e6847

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}