1 Introduction
在note1 已经明确了生成模型,是通过概率分布来拟合数据,这个部分采用自回归的模型结构来拟合数据。主要任务包括:选择什么样的自回归模型结构和设计什么样的loss函数来让模型收敛。
自回归模型结构的理论基础还是贝叶斯概率结合马尔可夫假设(未来状态只和历史的有限个状态相关):
p ( x 1 , x 2 , x 3 , . . . , x n ) = p ( x 1 ) p ( x 2 ∣ x 1 ) p ( x 3 ∣ x 1 , x 2 ) . . . p ( x n ∣ x 1 , . . . , x n − 1 ) p(x_1,x_2,x_3,...,x_n)=p(x_1)p(x_2|x_1)p(x_3|x_1,x_2)...p(x_n|x_1,...,x_{n-1}) p(x1,x2,x3,...,xn)=p(x1)p(x2∣x1)p(x3∣x1,x2)...p(xn∣x1,...,xn−1)
2 模型结构
2.1 FVSBN(Fully Visible Sigmoid Belief Network)
直接从贝叶斯概率公式延伸,用简单的逻辑回归来实现贝叶斯概率网络

最原始的结构:
p ( x n ∣ x 1 , x 2 , . . . , x n − 1 ) = σ ( α 0 + ∑ 1 n α i x i ) p(x_n|x_1,x_2,...,x_{n-1})=\sigma(\alpha_0+\sum_1^n \alpha_i x_i) p(xn∣x1,x2,...,xn−1)=σ(α0+1∑nαixi)
作为算法我们需要研究一下这种方法所需要的参数数量,假定有n个状态变量:
x ^ 1 \hat{x}_1 x^1参数是 α 0 \alpha_0 α0, x ^ 2 \hat{x}_2 x^2的参数是 α 0 , α 1 \alpha_0, \alpha_1 α0,α1,所以一共有 1 + 2 + . . . + n = ( n + 1 ) n 2 1+2+...+n=\frac{(n+1)n}{2} 1+2+...+n=2(n+1)n个alpha变量,如果每个alpha是d维的,则一共有 ( n + 1 ) n 2 d \frac{(n+1)n}{2}d 2(n+1)nd个参数。
2.2 NADE(Neural Autoregressive Density Estimation)
FVSBN 这里有几个问题是很好处理的:
1)计算复杂度是o(n^2)的,对于稍微复杂一点的问题,如mnist(n=784)也是不能接受的;
2)可以将早期神经网络的隐藏层引入进去;
h i = σ ( [ w 1 , w 2 , . . . , w i − 1 ] [ x 1 x 2 . . . x i − 1 ] ) x ^ n = σ ( α i h i + b i ) \begin{aligned} h_i &=\sigma([w_1,w_2,...,w_{i-1}] \begin{bmatrix} x_1 \\ x_2 \\ ... \\ x_{i-1} \end{bmatrix}) \\ \hat{x}_n & = \sigma(\alpha_i h_i+b_i) \end{aligned} hix^n=σ([w1,w2,...,wi−1] x1x2...xi−1 )=σ(αihi+bi)

重新来统计一下参数量:
隐藏层有nd个参数,输出层有nd个参数,参数量是O(nd)相对于之前提升明显。
- 输出状态的类别大于2
在nade的基础上,如果需要输出多个类别,比如说255个灰度图,那么在输出层使用softmax就可以:
S o f t m a x ( a ⃗ ) = ( e a 1 ∑ i e a i , e a 2 ∑ i e a i , . . . , e a n ∑ i e a i Softmax(\vec{a})=(\frac{e^{a_1}}{\sum_i e^{a_i}},\frac{e^{a_2}}{\sum_i e^{a_i}},...,\frac{e^{a_n}}{\sum_i e^{a_i}} Softmax(a)=(∑ieaiea1,∑ieaiea2,...,∑ieaiean - 输出连续分布
如果输出的状态变量是连续变量,这个时候需要模型输出均值和方差。
x ^ i = ( μ i 1 , . . . , μ i k , σ i 1 , . . . , σ i k ) = α i h i + b i \hat{x}_i=(\mu_i^1,...,\mu_i^k,\sigma_i^1,...,\sigma_i^k)=\alpha_i h_i + b_i x^i=(μi1,...,μik,σi1,...,σik)=αihi+bi
2.3 autoencoder
NADE 从网络结构上来说就是将MLP根据先验知识进行了mask,但是这样网络结构太复杂了。

2.4 NLP 领域的RNN
在transformer 一统之前,在NLP领域,自回归生成模型的主流模型是RNN。
h t + 1 = t a n h ( w h h h t + w x h x t + 1 ) h 0 = b 0 o t + 1 = w h y h t + 1 \begin{aligned} h_{t+1} &=tanh(w_{hh}h_t + w_{xh}x_{t+1}) \\ h_0 & = b_0 \\ o_{t+1} & = w_{hy}h_{t+1} \end{aligned} ht+1h0ot+1=tanh(whhht+wxhxt+1)=b0=whyht+1

2.5 图像领域的pixCNN
类似于MADE, 对输入的图像在输入层的时候添加带mask的卷积。


2.6 声音领域的wavenet
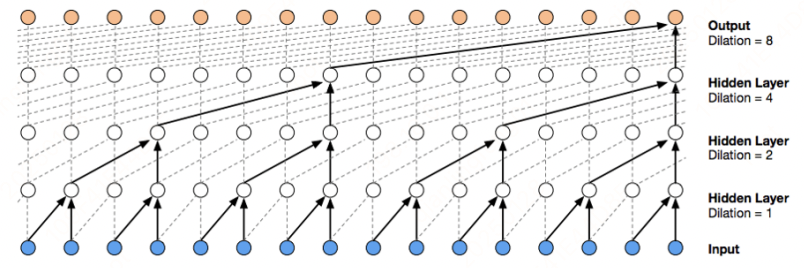
3 参数迭代
3.1 用熵比较分布的距离
先来看熵的定义,直觉上来说,概率越低的数据需要的比特越多,统计一下整个数据所需要的比特数就行了。有两种方式可以进行统计,全部统计和分层抽样统计。
− E x p d a t a l o g p d a t a ( x ) = − 1 D ∑ l o g p d a t a ( x ) = − ∑ p d a t a ( x ) l o g p d a t a ( x ) \begin{aligned} -E_{x~p_{data}}logp_{data}(x) &=-\frac{1}{D}\sum logp_{data}(x) \\ & = -\sum p_{data}(x)logp_{data}(x) \end{aligned} −Ex pdatalogpdata(x)=−D1∑logpdata(x)=−∑pdata(x)logpdata(x)
现在有两个分布,如果需要比较一下两个分布的差异,从熵的角度就一目了然了。如果他们的概率分布接近,那么他们的熵就应该很接近。
D ( p ∣ ∣ q ) = E x − p ( l o g p ( x ) − l o g q ( x ) ) = E x − p l o g p ( x ) q ( x ) = ∑ x p ( x ) l o g p ( x ) q ( x ) \begin{aligned} D(p||q) &=E_{x-p}(logp(x)-logq(x)) \\ &=E_{x-p}log\frac{p(x)}{q(x)} \\ & = \sum_x p(x)log\frac{p(x)}{q(x)} \\ \end{aligned} D(p∣∣q)=Ex−p(logp(x)−logq(x))=Ex−plogq(x)p(x)=x∑p(x)logq(x)p(x)
对于数据拟合问题:
D ( p d a t a ∣ ∣ p θ ) = ∑ x ( p d a t a l o g p d a t a − p d a t a l o g p θ ) = c o n s t − ∑ x p d a t a l o g p θ \begin{aligned} D(p_{data}||p_{\theta}) & = \sum_x (p_{data}logp_{data}-p_{data}logp_{\theta})\\ & = const -\sum_x p_{data}logp_{\theta} \end{aligned} D(pdata∣∣pθ)=x∑(pdatalogpdata−pdatalogpθ)=const−x∑pdatalogpθ
为了将KL散度尽量小,需要将 ∑ x p d a t a l o g p θ \sum_x p_{data}logp_{\theta} ∑xpdatalogpθ尽量大,这也是极大似然。极大似然可以用采样的角度来理解,也就是将所有数据统计,然后再取平均;或者进行抽样采样,并且加上对应的分布概率。
E x − p d a t a [ l o g P θ ( x ) ] = ∑ x p d a t a l o g p θ = 1 D ∑ x ∈ D l o g P θ ( x ) \begin{aligned} E_{x-p_{data}}[logP_{\theta}(x)] & = \sum_x p_{data}logp_{\theta} \\ & = \frac{1}{D}\sum_{x \in D} logP_{\theta}(x) \end{aligned} Ex−pdata[logPθ(x)]=x∑pdatalogpθ=D1x∈D∑logPθ(x)
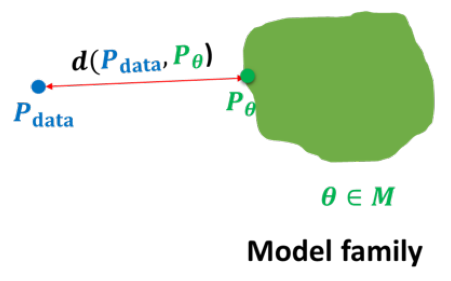
这里还有个问题 p d a t a p_{data} pdata是全体数据,模型训练的时候,只能通过monte carlo方法进行估计。
3.2 极大似然解析解
例如说硬币问题,假定使用概率分布
P θ ( x ) = { θ if x = H 1 − θ else x = T P_{\theta}(x)= \begin{cases} \theta & \text{if } x=H \\ 1-\theta & \text{else } x=T \end{cases} Pθ(x)={θ1−θif x=Helse x=T
后验结果:D={H,H,T,H,T}
按照我们的极大似然的思路, 后面下角标表示状态维度,上角标表示不同的样本。
1 D ∑ x ∈ D l o g P θ ( x ) = 1 5 ∑ x l o g P θ ( x 1 ) + l o g P θ ( x 2 ) + . . . + l o g P θ ( x 5 ) = 1 5 ∑ x l o g P θ ( x ( 1 ) ) P θ ( x ( 2 ) ) . . . P θ ( x ( 5 ) ) = 1 5 ∑ x l o g ( θ θ ( 1 − θ ) θ ( 1 − θ ) ) \begin{aligned} \frac{1}{D}\sum_{x \in D} logP_{\theta}(x) &=\frac{1}{5}\sum_x logP_{\theta}(x_1) +logP_{\theta}(x_2)+...+logP_{\theta}(x_5)\\ & = \frac{1}{5}\sum_x logP_{\theta}(x^{(1)}) P_{\theta}(x^{(2)}) ...P_{\theta}(x^{(5)}) \\ & = \frac{1}{5}\sum_xlog(\theta \theta (1-\theta) \theta (1-\theta)) \end{aligned} D1x∈D∑logPθ(x)=51x∑logPθ(x1)+logPθ(x2)+...+logPθ(x5)=51x∑logPθ(x(1))Pθ(x(2))...Pθ(x(5))=51x∑log(θθ(1−θ)θ(1−θ))
变成了要搞一个 θ \theta θ使得这个KL散度最大,这个问题比较简单,可以通过一阶导=0的方式来得到解析解,这里是 θ = 0.6 \theta=0.6 θ=0.6
3.3 极大似然估计数值解
对于复杂问题,现在是没有解析解,那么这个时候只能先把loss(KL散度)计算出来,然后用auto-diff等工具进行梯度回传,来更新参数 θ \theta θ.
对于一个维度是n的变量,根据前面提到的贝叶斯概率
P ( x 1 , x 2 , . . . , x n ) = p ( x 1 ) p ( x 2 ∣ x 1 ) . . . p ( x n ∣ x 1 , x 2 , . . . , x n − 1 ) = ∏ i = 1 n p ( x i ∣ x < i ; θ i ) \begin{aligned} P(x_1,x_2,...,x_n)& =p(x_1)p(x_2|x_1)...p(x_n|x_1,x_2,...,x_{n-1}) \\ & = \prod_{i=1}^n p(x_i|x_{<i};\theta_i) \end{aligned} P(x1,x2,...,xn)=p(x1)p(x2∣x1)...p(xn∣x1,x2,...,xn−1)=i=1∏np(xi∣x<i;θi)
前面我们知道
1 D ∑ x ∈ D l o g P θ ( x ) = 1 m ∑ x l o g P θ ( x ( 1 ) ) P θ ( x ( 2 ) ) . . . P θ ( x ( m ) ) = 1 m ∑ x l o g ∏ m P θ ( x ( i ) ) \begin{aligned} \frac{1}{D}\sum_{x \in D} logP_{\theta}(x) & = \frac{1}{m}\sum_x logP_{\theta}(x^{(1)}) P_{\theta}(x^{(2)}) ...P_{\theta}(x^{(m)}) \\ & = \frac{1}{m}\sum_x log\prod_m P_{\theta}(x^{(i)}) \end{aligned} D1x∈D∑logPθ(x)=m1x∑logPθ(x(1))Pθ(x(2))...Pθ(x(m))=m1x∑logm∏Pθ(x(i))
我们在定义极大似然的loss的时候,直接用
L ( θ , D ) = ∏ j = 1 m P θ ( x ( j ) ) = ∏ j = 1 m ∏ i = 1 n P θ ( x i ( j ) ∣ x < i ( j ) ; θ i ) 1 D ∑ x ∈ D l o g P θ ( x ) = 1 m ∑ j = 1 m l o g ∏ i = 1 n P θ ( x i ( j ) ∣ x < i ( j ) ; θ i ) = 1 m ∑ j = 1 m ∑ i = 1 n l o g P θ ( x i ( j ) ∣ x < i ( j ) ; θ i ) \begin{aligned} L(\theta, D) &= \prod_{j=1}^m P_{\theta}(x^{(j)}) \\ & = \prod_{j=1}^m \prod_{i=1}^n P_{\theta}(x_i^{(j)}|x_{<i}^{(j)};\theta_i) \\ \frac{1}{D}\sum_{x \in D} logP_{\theta}(x) & = \frac{1}{m}\sum_{j=1}^m log \prod_{i=1}^n P_{\theta}(x_i^{(j)}|x_{<i}^{(j)};\theta_i) \\ & = \frac{1}{m}\sum_{j=1}^m\sum_{i=1}^n log P_{\theta}(x_i^{(j)}|x_{<i}^{(j)};\theta_i) \end{aligned} L(θ,D)D1x∈D∑logPθ(x)=j=1∏mPθ(x(j))=j=1∏mi=1∏nPθ(xi(j)∣x<i(j);θi)=m1j=1∑mlogi=1∏nPθ(xi(j)∣x<i(j);θi)=m1j=1∑mi=1∑nlogPθ(xi(j)∣x<i(j);θi)
用sgd的方法进行参数迭代:
∇ 1 D ∑ x ∈ D l o g P θ ( x ) = 1 m ∑ j = 1 m ∑ i = 1 n ∇ l o g P θ ( x i ( j ) ∣ x < i ( j ) ; θ i ) \begin{aligned} \nabla \frac{1}{D}\sum_{x \in D} logP_{\theta}(x) & = \frac{1}{m}\sum_{j=1}^m\sum_{i=1}^n \nabla log P_{\theta}(x_i^{(j)}|x_{<i}^{(j)};\theta_i) \end{aligned} ∇D1x∈D∑logPθ(x)=m1j=1∑mi=1∑n∇logPθ(xi(j)∣x<i(j);θi)
3.4 具体的例子
自回归的典型例子有,nlp中的gpt, 视频生成,自动驾驶中的世界模型等;
3.4.1 gpt的loss
gpt一般会将状态离散化,例如gpt3 会离散成50000个不同的token,然后给出这些不同的token的概率估计,只需要看一下真值对应的概率分布 P θ ( x i ( j ) ) P_{\theta}(x_i^{(j)}) Pθ(xi(j))。
P θ ( x i ( j ) ) = e x i ( j ) ∑ k e x i k ( j ) l o g P θ ( x i ( j ) ) = x i ( j ) − l o g ∑ k e x i k ( j ) \begin{aligned} P_{\theta}(x_i^{(j)}) &=\frac{e^{x_i^{(j)}}}{\sum _k e^{x_{ik}^{(j)}}} \\ logP_{\theta}(x_i^{(j)}) &=x_{i}^{(j)}-log\sum _k e^{x_{ik}^{(j)}} \end{aligned} Pθ(xi(j))logPθ(xi(j))=∑kexik(j)exi(j)=xi(j)−logk∑exik(j)
所以需要极大似然 x i ( j ) − l o g ∑ k e x i k ( j ) x_{i}^{(j)}-log\sum _k e^{x_{ik}^{(j)}} xi(j)−log∑kexik(j), 在定义loss的时候,则用 l o g ∑ k e x i k ( j ) − x i ( j ) log\sum _k e^{x_{ik}^{(j)}}-x_{i}^{(j)} log∑kexik(j)−xi(j) 也就是交叉熵。
3.4.2 连续分布的loss
对于连续分布,假定模型预测的是高斯分布的 μ , σ \mu, \sigma μ,σ, 真值是 x i ( j ) x_i^{(j)} xi(j), 需要使用高斯密度函数来估计概率。对应的极大似然估计是:
P θ ( x i ( j ) ) = 1 2 π σ e − ( x i ( j ) − μ ) 2 / ( 2 σ 2 ) l o g P θ ( x i ( j ) ) = − ( x i ( j ) − μ ) 2 / ( 2 σ 2 ) − l o g 2 π σ \begin{aligned} P_{\theta}(x_i^{(j)}) &= \frac{1}{\sqrt{2\pi}\sigma}e^{-(x_i^{(j)}-\mu)^2/(2\sigma^2)} \\ logP_{\theta}(x_i^{(j)}) & = -(x_i^{(j)}-\mu)^2/(2\sigma^2)-log\sqrt{2\pi}\sigma \end{aligned} Pθ(xi(j))logPθ(xi(j))=2πσ1e−(xi(j)−μ)2/(2σ2)=−(xi(j)−μ)2/(2σ2)−log2πσ
这个极大似然轨迹,在模型训练的时候,取相反树就是NLL loss
N L L = ( x i ( j ) − μ ) 2 / ( 2 σ 2 ) + l o g 2 π σ NLL=(x_i^{(j)}-\mu)^2/(2\sigma^2)+log\sqrt{2\pi}\sigma NLL=(xi(j)−μ)2/(2σ2)+log2πσ
3.5 如何减小参数过拟合
- 减小参数
参数共享、更小的参数 - 模型结构
使用奥卡姆剃须刀原理 - 使用正则化
objective(x,M)=loss(x,M)+R(M) - 验证集
比较训练集和验证集上的表现。





