文章目录
- 从硬件PCIE、NVLINK、RDMA原理到通信NCCL、MPI原理!
- 通信实现方式:机器内通信、机器间通信
- 通信实现方式:通讯协调
- 通信实现方式:机器内通信:PCIe
- 通信实现方式:机器内通信:NVLink
- 通信实现方式:机器间通信:RDMA(直连模式)
- 通信协调:软件篇
- 通信协调:软件篇:MPI
- MPI:集合通信
- MPI:进程启动与收发数据顺序:broadcast
- MPI:进程启动与收发数据顺序:gather
- 通信协调:软件篇:NCCL
- 点对点通信、集合式通信
- 分布式训练系统
- 集中式通信方式:一对多 broadcast
- 集中式通信方式:一对多 scatter
- 集中式通信方式:多对一 reduce
- 集中式通信方式:多对一 gather
- 集中式通信方式:多对多 all reduce
- 集中式通信方式:多对多 all gather
- 集中式通信方式:多对多 reduce scatter
- 集中式通信方式:多对多 all to all
NCCLMPI_2">从硬件PCIE、NVLINK、RDMA原理到通信NCCL、MPI原理!
通信实现方式:机器内通信、机器间通信
计算机通网络通讯中最重要的两个衡量指标是:带宽、延迟

内存共享:比如 多个应用共享手机里面的同一块内存
PCIe:最明显的方式就是 gpu 与 cpu 之间的通信,大部分都通过之间的PCIe插槽进行的
NVLink(直连模式):GPU 与 GPU 之间进行一个互通

Q:不同机柜之间的GPU的访问,不是通过NVSwitch进行全互联的吗。那这个机器间的通信,都传输什么信息呢?通讯、互传数据、等待和同步相关的问题,这些信息是走什么传输的呢?
---- 如果是NVLink通信的话,它应该还是属于 机器内通信,而不是机器间通讯(TCP/IP、RDMA)
蓝色的线:通过网线进行连接
AI集群里面,可能更多的用到 RDMA 的网络模型通信
通信实现方式:通讯协调

通信实现方式:机器内通信:PCIe

通信实现方式:机器内通信:NVLink

通信实现方式:机器间通信:RDMA(直连模式)


(1)左边的图是TCP/IP,右边的是RDMA
(2)左边的几个蓝色方框,在传递的时候 需要经过好几次的用户的内存拷贝,对大数据执行起来会非常的缓慢,数据量越大的时候,这个延迟是很难去接受的!
(3)而RDMA新的协议,就是用户直接跳过kernel层,直接传到远端的服务器,数据绕过CPU,直接通过RDMA设备,对远端的虚拟内存直接进行访问读和写;
(4)既然是机器间通信,那么不同机器间是通过以太网连接的
(5)Q:RDMA是通过网线连接的吗?

通信协调:软件篇

通信协调:软件篇:MPI



OSI只是一个模型概念,并不提供具体的实现方法。实际上的网络的标准是TCP/IP


MPI:集合通信


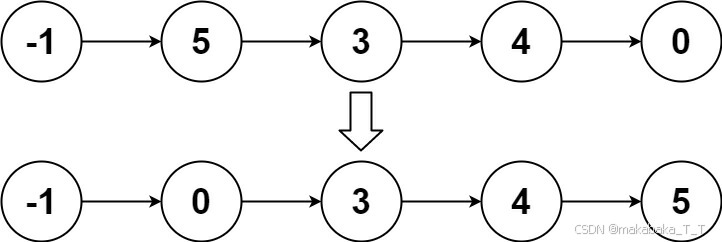
MPI:进程启动与收发数据顺序:broadcast

MPI:进程启动与收发数据顺序:gather



优化通信框架的性能,那不就是用到了之前学习到的 二叉树的结构了


NCCL_68">通信协调:软件篇:NCCL

(1)对网络拓扑进行一个感知,topo是长什么样子的,回环是怎么组织的
(2)对网络拓扑进行一个搜索,找到一个最好的通信的策略
(3)使能CUDA的kernel 对数据进行通信

点对点通信、集合式通信




分布式训练系统


对模型进行切分,每个服务器又需要相互通信,把一个大的网络模型切分成很多小的网络模型,每个小的网络模型之间是相互依赖的,需要就需要跨节点对数据进行同步
涉及到同步,中间的过程就需要通信,跨节点的通信,跨网络的通信,跨卡的通信;
集中式通信方式:一对多 broadcast
(1)把 NPU0 的数据同步到其他 3 份里面

集中式通信方式:一对多 scatter

集中式通信方式:多对一 reduce

集中式通信方式:多对一 gather

集中式通信方式:多对多 all reduce


集中式通信方式:多对多 all gather

集中式通信方式:多对多 reduce scatter

集中式通信方式:多对多 all to all
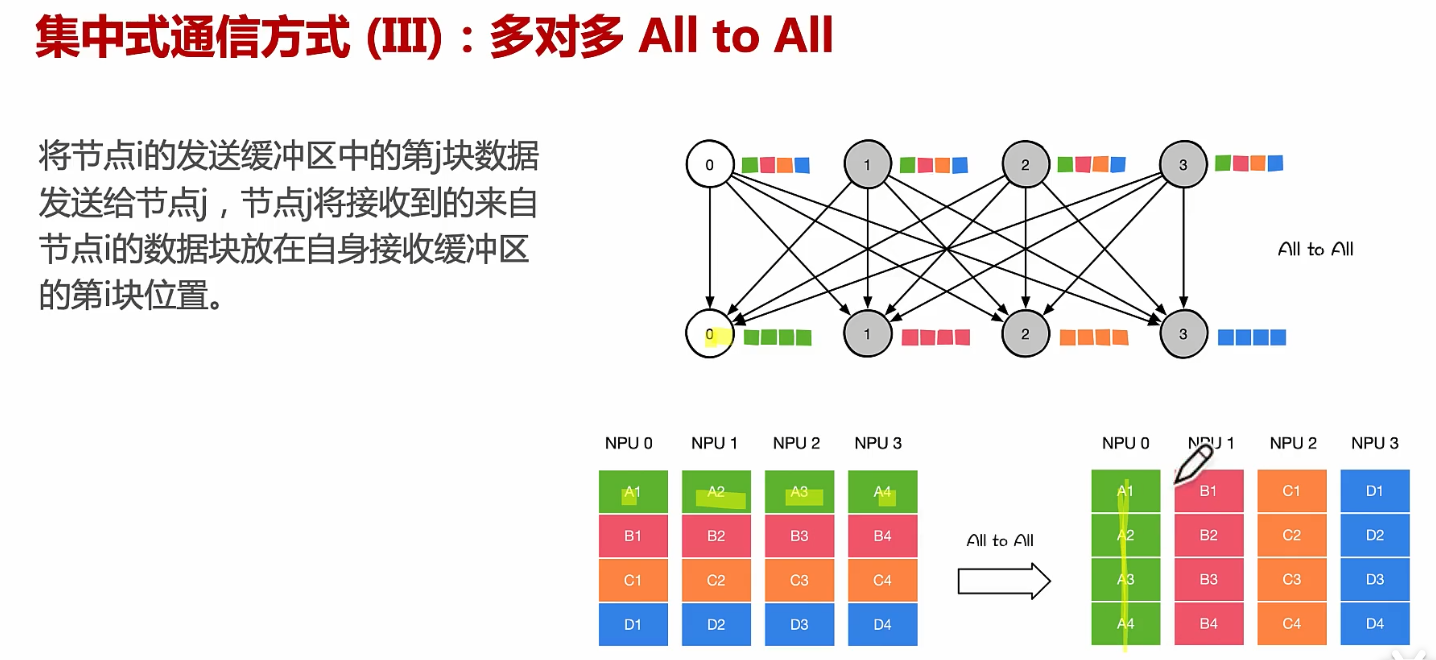
假设每个NPU上面都有一个A的数据,A的数据在计算完之后,希望进行通讯,都变成一块卡的数据,再进行聚类处理