一、什么是Dbsyncer
1、介绍

Dbsyncer是一款开源的数据同步中间件,提供MySQL、Oracle、SqlServer、PostgreSQL、Elasticsearch(ES)、Kafka、File、SQL等同步场景,支持上传插件自定义同步转换业务,提供监控全量和增量数据统计图、应用性能预警等。
2、特点
1、组合驱动,自定义库同步到库组合,关系型数据库与非关系型之间组合,任意搭配表同步映射2、关系实时监控,驱动全量或增量实时同步运行状态、结果、同步日志和系统日
项目地址:
https://gitee.com/ghi/dbsyncer
应用场景

3、下载安装包
- 安装JDK 1.8(省略详细)
- 下载安装包dbsyncer-x.x.x.zip(也可手动编译)
- 解压安装包,Window执行bin/startup.bat,Linux执行bin/startup.sh
- 打开浏览器访问:http://127.0.0.1:18686
- 账号和密码:admin/admin
4、阿里云镜像地址
docker pull registry.cn-hangzhou.aliyuncs.com/xhtb/dbsyncer:latest
docker pull registry.cn-hangzhou.aliyuncs.com/xhtb/dbsyncer-enterprise:latest
docker pull registry.cn-hangzhou.aliyuncs.com/lifewang/dbsyncer:latest
5、手动编译
先确保环境已安装JDK和Maven
$ git clone https://gitee.com/ghi/dbsyncer.git
$ cd dbsyncer
$ chmod u+x build.sh
$ ./build.sh
二、Dbsyncer的安装(这里只演示虚拟机的,java代码的这里不演示)
1.下载好安装包后,把安装包放在虚拟机的 /opt/momodules
然后在Linux执行bin/startup.sh,就可以进去web界面
2.然后解压到 /opt/installs下,不需要配置文件就可以启动他的web界面
3.进去web界面,地址为
http://192.168.150.120:18686
端口号为虚拟机的ip地址
账号密码为:admin
然后就能进入界面

mysql_to_mysql__68">三、mysql to mysql 的全量配置和数据演示
前期准备,在虚拟机的mysql创建一个库(这里为testmysql)然后创建表,导入数据,大概100万调数据
drop table if exists t;
CREATE TABLE t(id int NOT NULL AUTO_INCREMENT PRIMARY KEY comment '自增主键',dept tinyint not null comment '部门id',age tinyint not null comment '年龄',name varchar(30) comment '用户名称',create_time datetime not null comment '注册时间',last_login_time datetime comment '最后登录时间') comment '测试表';insert into testmysql values(1,1, 25, 'user_1', '2018-01-01 00:00:00', '2018-03-01 12:00:00');set @i=1;
select * from t;
#==================此处拷贝反复执行,直接符合预想的数据量===================
#执行20次即2的20次方=1048576 条记录
#执行23次即2的23次方=8388608 条记录
#执行24次即2的24次方=16777216 条记录
#......
insert into t(dept, age, name, create_time, last_login_time)
select left(rand()*10,1) as dept, #随机生成1~10的整数FLOOR(20+RAND() *(50 - 20 + 1)) as age, #随机生成20~50的整数concat('user_',@i:=@i+1), #按序列生成不同的namedate_add(create_time,interval +@i*cast(rand()*100 as signed) SECOND), #生成有时间大顺序随机注册时间date_add(date_add(create_time,interval +@i*cast(rand()*100 as signed) SECOND), interval + cast(rand()*1000000 as signed) SECOND) #生成有时间大顺序的随机的最后登录时间
from t;
select count(1) from t;
#==================此处结束反复执行=====================
然后再建一个数据库接收数据test02(要提前建好表)
drop table if exists t1;
CREATE TABLE t1 (id int NOT NULL AUTO_INCREMENT PRIMARY KEY comment '自增主键',dept tinyint not null comment '部门id',age tinyint not null comment '年龄',name varchar(30) comment '用户名称',create_time datetime not null comment '注册时间',last_login_time datetime comment '最后登录时间') comment '测试表';
创建好库后,需要给库单独一个用户授权,否则web界面链接不上去
CREATE USER 'ae86'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'ae86'@'%';
GRANT SELECT ON test03.* TO 'ae86'@'%';
flush privileges;grant process on *.* to ae86;
flush privileges;
show processlist
如果第一步执行不了的话,需要修改mysql的密码规则,然后修改
再开始数据同步之前,需要设置mysql的设置
官方使用手册:
介绍 - Wiki - Gitee.com
这里需要修改mysql的my.ini 或 my.cnf配置文件
我的my.cnf的位置在 /etc/my.cnf
然后把以下代码加进去
#log日志开启
log_bin=ON
#服务唯一ID
server_id=1
log-bin=mysql_bin
binlog-format=ROW
max_binlog_cache_size = 256M
max_binlog_size = 512M
expire_logs_days = 7
#监听同步的库, 多个库使用英文逗号“,”拼接
replicate-do-db=test03,testmysql,test02
下一步进去web界面添加链接
添加ip和库名

分别将对应的库添加进去
然后添加驱动,创建链接

先择对应的库,然后选择对应的表

按照图片位置,一次点击,配置是默认配置
点击右上角齿轮,启动数据同步
 在界面可以看见进度,也可以看监控界面
在界面可以看见进度,也可以看监控界面


在监控界面可以看到之间的操作

任务成功,这时候可以去MySQL中就可以看到已经同步的数据

mysql_to_mysql__186">四、mysql to mysql 的增量配置和演示
和全量配置一样,但是有不同的是,在增量配置之前要把,mysql的binlog开启
此操作在 /etc/my.cnf 下加入
3先查看是否开启
SHOW VARIABLES LIKE 'log_bin';
#开启
log_bin=ON
数据准备
常见test03库,创建t3和t3—ord表
drop table if exists t3;
CREATE TABLE t3 (id int NOT NULL AUTO_INCREMENT PRIMARY KEY comment '自增主键',dept tinyint not null comment '部门id',age tinyint not null comment '年龄',name varchar(30) comment '用户名称',create_time datetime not null comment '注册时间',last_login_time datetime comment '最后登录时间') comment '测试表';insert into t3 values(1,1, 25, 'user_1', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
insert into t3 values(2,2, 26, '测试同步', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
insert into t3 values(3,3, 26, '测试同步', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
insert into t3 values(4,4, 26, '测试同步', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
select * from t3;drop table if exists t3_ord;
CREATE TABLE t3_ord (id int NOT NULL AUTO_INCREMENT PRIMARY KEY comment '自增主键',dept tinyint not null comment '部门id',age tinyint not null comment '年龄',name varchar(30) comment '用户名称',create_time datetime not null comment '注册时间',last_login_time datetime comment '最后登录时间') comment '测试表';
insert into t3_ord values(1,1, 25, 'user_1', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
select * from t3_ord;
创建表之后进入web界面,添加驱动
按照顺序一次点点点

更改定时任务(我这里是5秒一次)

正则表达式



开启任务后,向t3添加数据后,t3的数据可以同步到t3—ord中
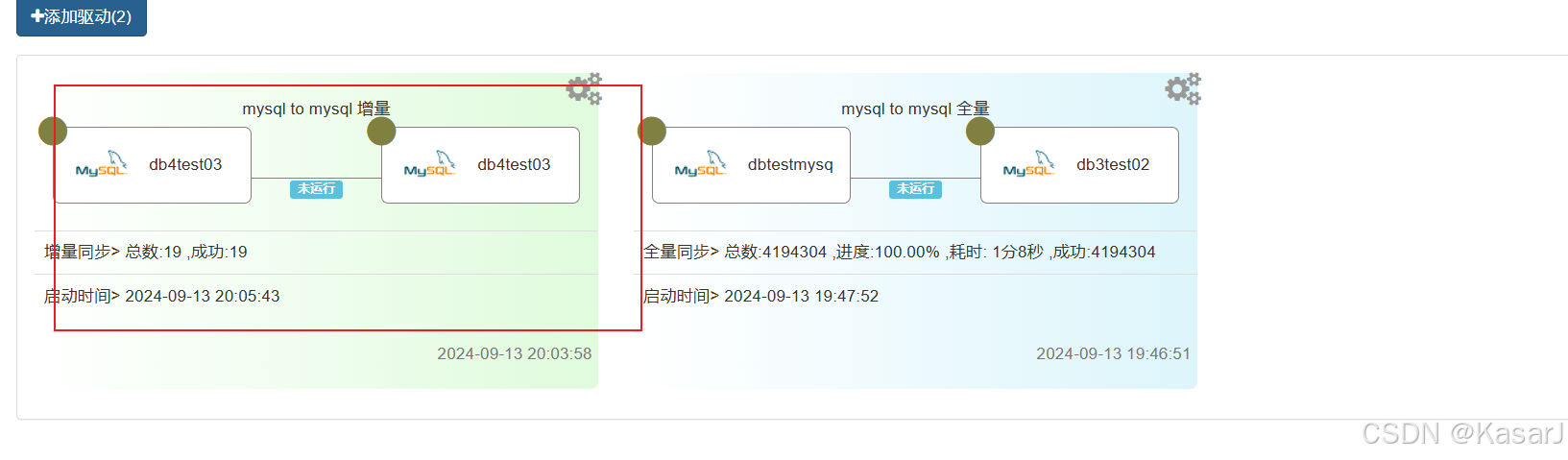
定时任务要手动关闭,不关闭会一直执行。



