引入selenium插件
- 首先到码云下载插件点击下载编辑到本地并导入到工作空间或安装到maven库
- 在spider-flow/spider-flow-web/pom.xml中引入插件
<!-- 引入selenium插件 -->
<dependency><groupId>org.spiderflow</groupId><artifactId>spider-flow-selenium</artifactId>
</dependency>-
在spider-flow/spider-flow-web/application.properties中配置驱动路径
-
chrome驱动下载地址:https://developer.chrome.com/docs/chromedriver/downloads?hl=zh-cn#chromedriver_900443024
- firefox驱动下载地址:https://github.com/mozilla/geckodriver/releases
安装错误处理
1、无法找到二进制文件
报错信息:
org.openqa.selenium.WebDriverException: Cannot find firefox binary in PATH. Make sure firefox is installed. OS appears to be: LINUX
Build info: version: 'unknown', revision: 'unknown', time: 'unknown'
System info: host: 'zyldev01', ip: '10.0.3.190', os.name: 'Linux', os.arch: 'amd64', os.version: '3.10.0-1160.el7.x86_64', java.version: '1.8.0_181'
Driver info: driver.version: FirefoxDriverat org.openqa.selenium.firefox.FirefoxBinary.<init>(FirefoxBinary.java:116)at java.util.Optional.orElseGet(Optional.java:267)at org.openqa.selenium.firefox.FirefoxOptions.getBinary(FirefoxOptions.java:218)at org.openqa.selenium.firefox.FirefoxDriver.toExecutor(FirefoxDriver.java:155)at org.openqa.selenium.firefox.FirefoxDriver.<init>(FirefoxDriver.java:120)at org.spiderflow.selenium.driver.FireFoxDriverProvider.getWebDriver(FireFoxDriverProvider.java:87)at org.spiderflow.selenium.executor.shape.SeleniumExecutor.execute(SeleniumExecutor.java:111)at org.spiderflow.core.Spider.lambda$executeNode$4(Spider.java:285)at com.alibaba.ttl.TtlRunnable.run(TtlRunnable.java:59)at org.spiderflow.concurrent.SpiderFlowThreadPoolExecutor$SubThreadPoolExecutor.lambda$submitAsync$0(SpiderFlowThreadPoolExecutor.java:152)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)该错误信息表明 WebDriver 无法找到 Firefox 浏览器的二进制文件,原因可能是 Firefox 浏览器没有正确安装,或者它没有添加到 PATH 环境变量中。解决此问题,可以通过以下几个步骤进行:
1)确保 Firefox 已安装
首先,请确认 Firefox 浏览器已正确安装在系统上。可以通过以下命令检查:
firefox --version如果系统提示 command not found 或类似错误,表示 Firefox 没有安装。你可以通过以下命令安装 Firefox:
对于基于 Debian 的系统(如 Ubuntu):
sudo apt update sudo apt install firefox对于基于 RHEL/CentOS 的系统:
sudo yum install firefox2)设置 Firefox 路径
如果 Firefox 已安装,但 WebDriver 仍然提示找不到 Firefox 二进制文件,则需要确保 Firefox 的安装路径添加到 PATH 环境变量中。
-
查找 Firefox 安装路径:
运行以下命令来查找 Firefox 的安装路径:
which firefox该命令会返回 Firefox 的完整路径,例如:
/usr/bin/firefox。 -
设置 Firefox 路径:
可以通过设置环境变量
webdriver.firefox.bin来指定 Firefox 的二进制文件路径。在 Selenium 测试脚本中,使用如下代码:System.setProperty("webdriver.firefox.bin", "/usr/bin/firefox");或者,如果你使用的是
FirefoxOptions:FirefoxOptions options = new FirefoxOptions(); options.setBinary("/usr/bin/firefox"); WebDriver driver = new FirefoxDriver(options);其中
/usr/bin/firefox替换为实际的 Firefox 安装路径。
3.)确保 FirefoxDriver 与 Firefox 版本匹配
确认你下载的 geckodriver(Firefox 的 WebDriver)与系统中安装的 Firefox 版本兼容。你可以通过以下命令检查 Firefox 的版本:
firefox --version然后下载与 Firefox 版本匹配的 geckodriver,可以从 GeckoDriver Releases 页面下载。
4) 添加 Firefox 路径到 PATH
如果你希望 Firefox 能在任何地方通过命令行访问,确保 Firefox 路径添加到系统的 PATH 环境变量中。你可以通过以下命令将其添加到 .bashrc 或 .bash_profile 文件中:
echo "export PATH=$PATH:/usr/bin" >> ~/.bashrc
source ~/.bashrc如果 Firefox 安装在其他路径,只需修改 /usr/bin 为实际路径。
5)确认 geckodriver 已正确安装
geckodriver 必须在 PATH 中,或者你可以手动设置其路径。你可以通过以下命令确认 geckodriver 是否已安装并正确配置:
geckodriver --version如果没有安装 geckodriver,可以从以下地址下载适合你操作系统的版本:
GeckoDriver 下载页面
确保 geckodriver 已添加到 PATH 中,或者在代码中显式设置其路径,例如:
System.setProperty("webdriver.gecko.driver", "/path/to/geckodriver");总结
- 确保 Firefox 已安装且可执行。
- 检查 Firefox 的路径并确保在环境变量
PATH中。 - 下载与 Firefox 版本兼容的
geckodriver并配置正确的路径。
按照这些步骤,你应该能够解决 Cannot find firefox binary in PATH 的问题。如果问题依然存在,可能需要重新检查 Firefox 和 geckodriver 的安装路径配置。
2、浏览器启动失败
报错:
org.openqa.selenium.WebDriverException: Process unexpectedly closed with status 1org.openqa.selenium.WebDriverException: Process unexpectedly closed with status 1 是 Selenium 中常见的错误之一。这个错误通常发生在 WebDriver 启动浏览器时,浏览器驱动(例如 chromedriver、geckodriver)未能正确启动,或者浏览器本身遇到了启动问题。错误的状态码 1 表示程序退出时发生了异常。
以下是一些常见的原因以及对应的解决方案:
1)浏览器和驱动不匹配
浏览器版本和 WebDriver 版本必须匹配。如果你使用的是较新的浏览器版本,但驱动程序版本较旧,或者反之,都可能导致 WebDriver 启动失败。
解决方法:
- 检查浏览器版本:查看你的浏览器(例如 Chrome 或 Firefox)版本。
- 下载兼容的 WebDriver 版本:根据你的浏览器版本下载与之匹配的 WebDriver。
比如:
- 对于 Chrome,你可以访问 chromedriver download 来下载适合你 Chrome 版本的
chromedriver。 - 对于 Firefox,你可以访问 geckodriver releases 来下载与 Firefox 版本匹配的
geckodriver。
2)驱动文件不可执行或权限问题
如果驱动程序文件没有正确的执行权限,Selenium 启动时会遇到问题。
解决方法: 你需要确保驱动程序文件具有可执行权限。在 Linux 或 macOS 系统中,可以运行以下命令来设置文件的执行权限:
chmod +x /path/to/your/driver
3) 缺少必要的依赖库(特别是在 Linux 上)
对于 Linux 系统,某些浏览器驱动(尤其是 chromedriver)可能需要依赖特定的库。如果这些库缺失,WebDriver 启动会失败。
解决方法: 你可以通过以下命令安装缺少的依赖库(例如,在 Ubuntu 上):
sudo apt-get install libnss3 libgdk-pixbuf2.0-0 libx11-xcb1
这些是 Chromium 和 chromedriver 通常需要的库。
4)浏览器启动异常
有时浏览器本身的问题(例如设置了某些配置)也会导致 WebDriver 启动失败。
还有就是如果你的爬虫平台布置在服务器上,你本地要调用浏览器的话,可能由于驱动差异会调用不起来
解决方法:
- 确保没有后台的浏览器实例运行。
- 尝试使用无头模式(headless mode)启动浏览器,特别是在 CI/CD 环境或没有图形界面的服务器上。
可以设置以下参数来启动无头模式:
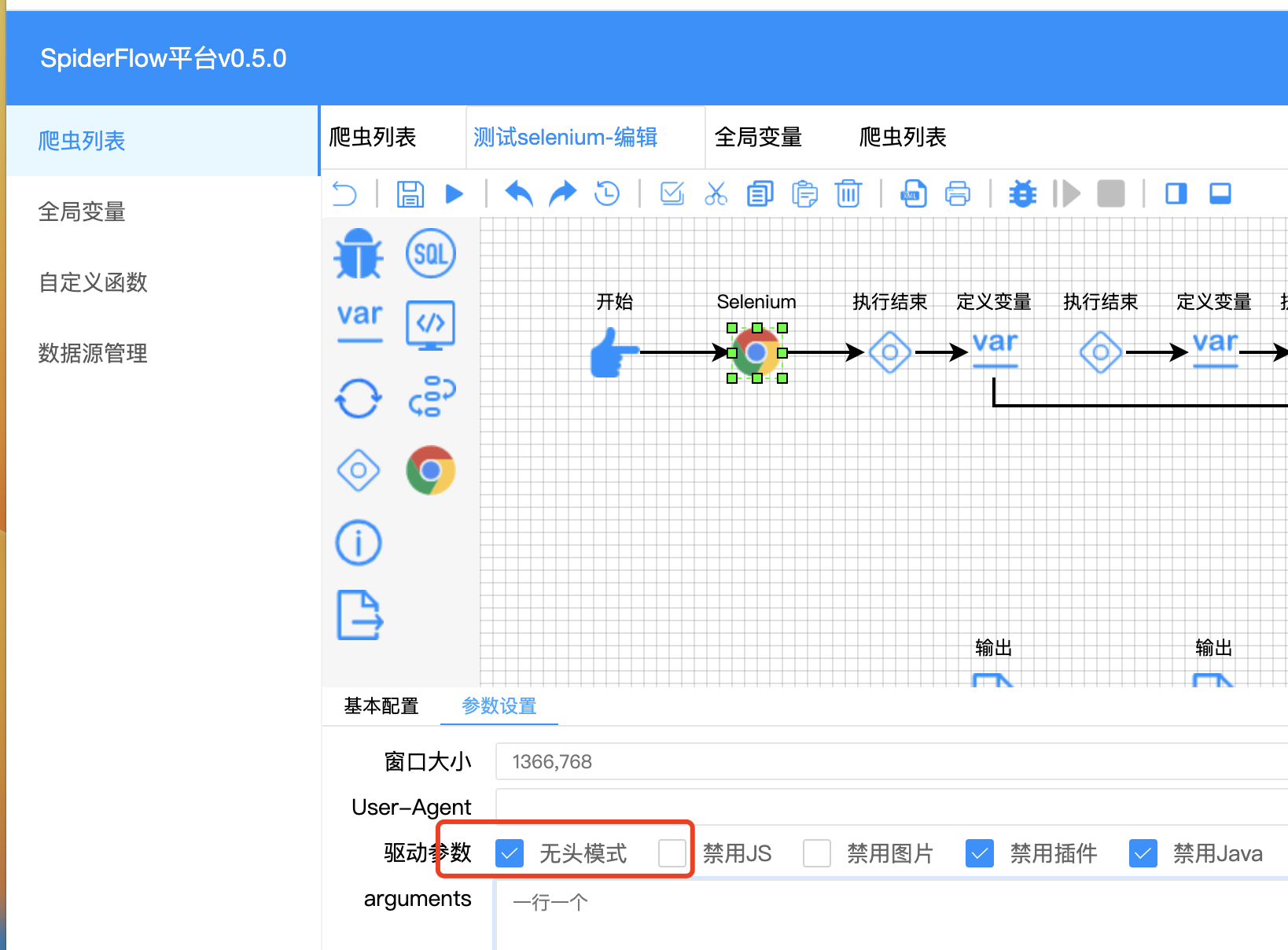
浏览器有头和无头模式了解
浏览器的“无头模式”(Headless Mode)和“有头模式”(Headed Mode)是指浏览器是否以图形用户界面(GUI)形式显示出来的两种运行方式。这两种模式的主要区别在于是否显示浏览器窗口。
1. 有头模式(Headed Mode)
- 定义:有头模式是浏览器的常规运行模式,指的是浏览器启动时会弹出一个可视的窗口,用户可以看到浏览器的图形界面并与之交互。
- 特点:
- 浏览器窗口可见,用户可以直接操作。
- 页面加载、渲染和交互都可以通过图形界面直观地进行。
- 适用于需要与页面直接交互的场景(例如手动测试、用户实际使用的场景等)。
- 使用场景:
- 自动化测试时调试,开发人员希望通过可视化界面查看页面元素的变化。
- 需要与浏览器进行实时交互的场景。
2. 无头模式(Headless Mode)
- 定义:无头模式是指浏览器启动时不显示图形界面,而是在后台运行,所有的渲染和操作都是在无图形界面的环境下进行的。
- 特点:
- 浏览器没有窗口显示,也不能与其交互。
- 通常更快速,因为不需要渲染图形界面,减少了系统资源的占用。
- 非常适合自动化测试和大规模的网页抓取。
- 能够在没有显示器或图形界面的环境中运行(如服务器环境、Docker 容器等)。
- 使用场景:
- 自动化测试:当需要在后台执行大量的浏览器测试时,无头模式可以提高执行速度。
- 网页抓取(Web Scraping):爬虫程序通常会用无头模式来抓取网页内容,而不需要浏览器界面。
- CI/CD 流水线:在持续集成或自动化部署中,通常采用无头模式来运行自动化测试,以提高效率。
无头模式的优点:
- 性能更高:由于不需要渲染和显示浏览器界面,系统资源占用较少,运行速度较快。
- 适用于无图形界面环境:在服务器、虚拟机、容器(如 Docker)等没有图形界面的环境中,可以通过无头模式运行浏览器。
- 更适合批量任务:例如自动化测试、网页抓取等任务,因为这些任务通常不需要人工交互,且需要高效处理大量页面。
无头模式的缺点:
- 无法直接查看页面:在调试时如果出现问题,无法通过浏览器的界面进行直观检查。
- 可能存在兼容性问题:某些功能或页面的行为在有头模式和无头模式下可能有所不同,尤其是与页面渲染和交互有关的复杂功能。
总结
- 有头模式:浏览器正常显示图形界面,适用于需要人工交互或调试的场景。
- 无头模式:浏览器不显示图形界面,适用于后台任务,如自动化测试、网页抓取等,通常可以提高性能和效率。
你可以根据实际需求来选择使用哪种模式。如果是自动化测试且不需要查看页面细节,推荐使用无头模式;如果是调试或需要人工交互,则应该使用有头模式。
节点说明
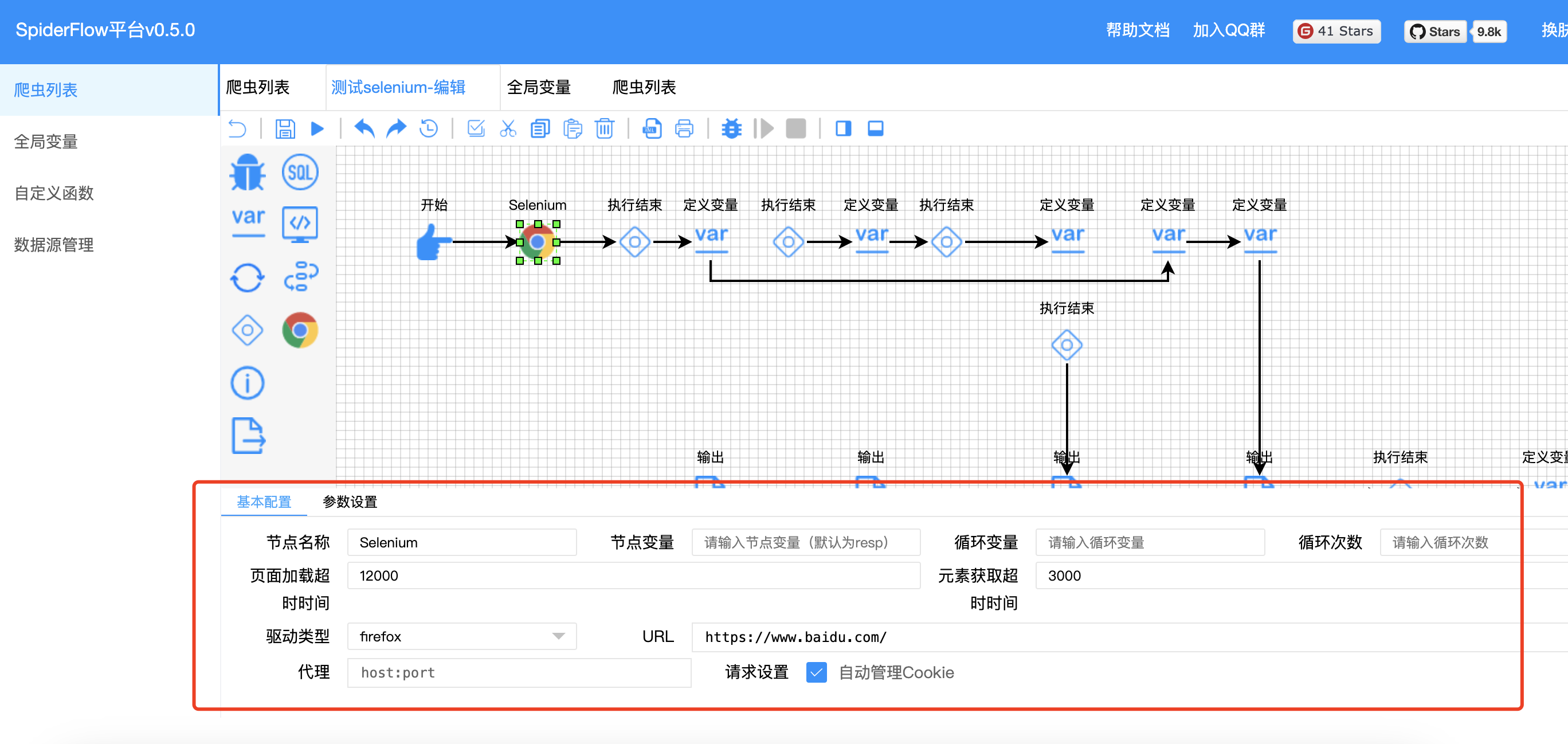
- 页面加载超时时间,单位为毫秒
- 元素获取超时时间,单位为毫秒
- URL:起始地址
- 节点执行完毕后,会产生
resp类型为SeleniumResponse的变量
SeleniumResponse 属性
| 字段名称 | 字段类型 | 字段描述 |
|---|---|---|
| html | String | 页面HTML |
| json | JSONObject/JSONArray | 内容转json结果 |
| cookies | Map<String,String> | cookies |
| url | String | 当前页面的URL |
| title | String | 当前页面的标题 |
SeleniumResponse 方法
switchTo
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| index/iframeName/WebElement | 要切换的iframe | 否 |
${resp.switchTo(index)}TIP
返回值类型:SeleniumResponse
switchToDefault
切换至默认,即从iframe里切换回来
${resp.switchToDefault()}selector
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| cssSelector | 要获取的cssSelector | 否 |
TIP
返回值类型:WebElement
- 获取页面上的第一个div
${resp.selector('div')}selectors
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| cssSelector | 要获取的cssSelector | 否 |
TIP
返回值类型:WebElements
- 获取页面上的所有div
${resp.selectors('div')}xpath
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| xpath | 要获取的xpath | 否 |
TIP
返回值类型:WebElement
- 获取页面上的第一个div
${resp.xpath('//div')}xpaths
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| xpath | 要获取的xpath | 否 |
TIP
返回值类型:WebElements
- 获取页面上的所有div
${resp.xpaths('//div')}executeScript
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| script | js脚本 | 否 |
| List<Object> | 参数 | 否 |
TIP
返回值类型:Object
- 执行js
${resp.executeScript('return "hello spider-flow-" + arguments[0];',['selenium'])}quit
- 退出浏览器
${resp.quit()}
toUrl
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| url | 要跳转的url | 否 |
- 跳转到百度
${resp.toUrl('https://www.baidu.com')}
loadCookies
- 将cookie加载至cookieContext中,以便后续自动管理cookie
${resp.loadCookies()}WebElement 方法
html
TIP
返回值类型:String
- 获取节点的html
${elementVar.html()}text
TIP
返回值类型:String
- 获取节点的text
${elementVar.text()}
attr
TIP
返回值类型:String
- 获取节点的href属性
${elementVar.attr('href')}
selector
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| cssSelector | 要获取的cssSelector | 否 |
TIP
返回值类型:WebElement
- 获取该节点下的第一个div
${elementVar.selector('div')}
selectors
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| cssSelector | 要获取的cssSelector | 否 |
TIP
返回值类型:WebElements
- 获取获取该节点下的所有div
${elementVar.selectors('div')}xpath
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| xpath | 要获取的xpath | 否 |
TIP
返回值类型:WebElement
- 获取获取该节点下的第一个div
${elementVar.xpath('//div')}
xpaths
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| xpath | 要获取的xpath | 否 |
TIP
返回值类型:WebElements
- 获取获取该节点下的所有div
${elementVar.xpaths('//div')}
screenshot
TIP
返回值类型:byte[]
- 对该节点进行截图
${elementVar.screenshot()}click
TIP
返回值类型:WebElement
- 对该节点进行点击
${elementVar.click()}sendKeys
TIP
返回值类型:WebElement
- 对该节点进行模拟按键
${elementVar.sendKeys('hello spider-flow')}clickAndHold
release
move
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| offset_x | offset x | 是 |
| offset_y | offset y | 是 |
TIP
在该节点上模拟鼠标移动,当offset_x和offset_y为空时,则模拟鼠标移动到该节点上
doubleClick
pause
perform
TIP
以上6个方法是配套使用,调用perform时才是真正执行动作
- 模拟鼠标移动到该节点上,等待500ms在点击,等待500ms在移动,最后释放(模拟拖拽滑块条)
${elementVar.move().pause(500).clickAndHold().pause(500).move(200,0).release().perform()}WebElements 方法
html
TIP
返回值类型:List<String>
- 获取节点的html
${elementsVar.html()}text
TIP
返回值类型:List<String>
- 获取节点的text
${elementsVar.text()}attr
TIP
返回值类型:List<String>
- 获取节点的href属性
${elementsVar.attr('href')}selector
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| cssSelector | 要获取的cssSelector | 否 |
TIP
返回值类型:WebElement
- 获取该节点下的第一个div
${elementsVar.selector('div')}selectors
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| cssSelector | 要获取的cssSelector | 否 |
TIP
返回值类型:WebElements
- 获取获取该节点下的所有div
${elementsVar.selectors('div')}xpath
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| xpath | 要获取的xpath | 否 |
TIP
返回值类型:WebElement
- 获取获取该节点下的第一个div
${elementsVar.xpath('//div')}xpaths
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| xpath | 要获取的xpath | 否 |
TIP
返回值类型:WebElements
- 获取获取该节点下的所有div
${elementsVar.xpaths('//div')}





