列表,我们使用for循环来取值,我们把每个值都取到,不需要关心每一个值的位置,因为只能顺序的取值,并不能跳过任何一个去取其他位置的值。那么我们为什么可以使用for循环来取值,for循环内部是怎么工作的呢?
迭代器:
示例1:
for i in [1, 2, 3, 4]:print(i)如果我们换成:
for i in 1234:print(i)
iterable: 可重复的,可迭代的。
什么叫可迭代的?
字符串、列表、元组、字典、集合都可以被for循环,说明它们是可迭代的。
from collections.abc import Iterablel = [1, 2, 3, 4]
t = (1, 2, 3, 4)
d = {1: 2, 3: 4}
s = {1, 2, 3, 4}# 判断对象是否是可迭代对象
print(isinstance(l, Iterable))
print(isinstance(t, Iterable))
print(isinstance(d, Iterable))
print(isinstance(s, Iterable))判断对象是否是可迭代对象。
可以将某个数据集内的数据“一个挨着一个地取出来”, 就叫做迭代。
可迭代协议:
假如我们自己写一个数据类型,我们希望这个数据类型里面的东西可以使用for被一个一个地取出来,那么我们就必须满足for的要求,这个要求就叫做“协议”。
可以被迭代要满足的要求就叫做可迭代协议。可迭代协议非常简单,就是内部实现了__iter__方法。要想可迭代,内部必须有一个__iter__方法:
print(dir([1, 2]))
print(dir((1, 2)))
print(dir({1: 2}))
print(dir({1, 2}))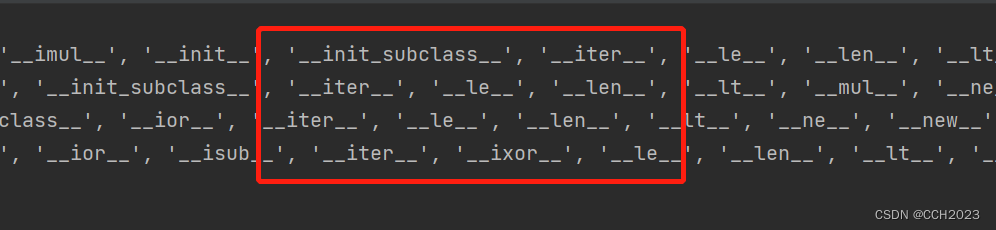
那么, __iter__做了什么事情呢?得到了一个list_iterator。
iterator:迭代器
迭代器协议:
在列表迭代器中多了三个方法:
iter_l = [1,2,3,4,5,6].__iter__()
#获取迭代器中元素的长度
print(iter_l.__length_hint__())
#根据索引值指定从哪里开始迭代
print('*',iter_l.__setstate__(4))
#一个一个的取值
print('**',iter_l.__next__())
print('***',iter_l.__next__())在for循环中,就是在内部调用了__next__方法才能取到一个一个的值。
迭代器遵循迭代器协议:必须拥有__iter__方法和__next__方法。
那为什么要有for循环?
for循环就是基于迭代器协议提供了一个统一的可以遍历所有对象的方法,即在遍历之前,先调用对象的__iter__方法将其转换成一个迭代器,然后使用迭代器协议去实现循环访问,这样所有的对象就都可以通过for循环来遍历了。