3D 生成重建032-Find3D去找到它身上的每一份碎片吧
文章目录
- 0 论文工作
- 1 论文方法
- 2 实验结果
0 论文工作
该论文研究三维开放世界部件分割问题:基于任何文本查询分割任何物体中的任何部件。以往的方法在物体类别或部件词汇方面存在局限性。最近人工智能的进步在二维图像中展现了有效的开放世界识别能力。受此启发,提出了一种开放世界直接预测模型,用于三维部件分割,可对任何物体进行零样本应用。该方法叫FIND3D,在一个大型互联网三维资产数据集上训练了一个通用类别点嵌入模型,无需任何人工标注。它结合了一个由基础模型驱动的用于数据标注的数据引擎和一种对比训练方法。
实际上这个当法的策略跟我们前面提到的将SAM知识蒸馏到3D空间的工作相近,主要体现在目标上的不同。不同的是该方法借助这种标注结果去训练一个3d分割大模型
paper
github
相关论文
langsplat
LERF
gaussian grouping
feature 3DGS
SA3D
1 论文方法


FIND3D旨在解决现有三维部件分割方法在物体类别和部件词汇上的局限性问题。它通过以下三个关键步骤实现目标:
数据引擎: 利用2D基础模型(SAM和Gemini)自动标注来自互联网的大规模三维资产,生成包含150万个部件标注的数据集。这个数据引擎无需人工标注,极大提升了数据获取效率。
模型训练: 基于标注数据,训练一个基于Transformer的点云模型。采用对比学习方法,解决部件层次结构和歧义问题,提高模型的泛化能力。
零样本预测: FIND3D能够对任何物体和任意文本查询进行零样本预测,直接输出部件分割结果。
自动数据标注: FIND3D的数据引擎实现了对三维数据的自动标注,避免了耗时的人工标注过程,极大地降低了数据获取成本,并使得训练大规模模型成为可能。
基于Transformer的点云模型和对比学习: 使用基于Transformer的架构处理点云数据,能够有效地捕捉点与点之间的长程依赖关系。同时,采用对比学习方法,有效地解决了部件层次结构和歧义问题,提高了模型的鲁棒性和准确性。
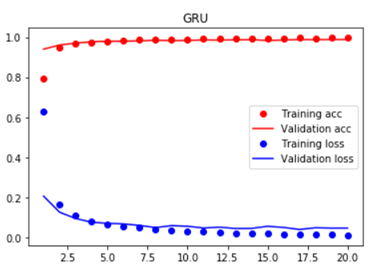
2 实验结果



![CTF-WEB: php-Session 文件利用 [第一届国城杯 n0ob_un4er 赛后学习笔记]](https://i-blog.csdnimg.cn/direct/3e6ff6d74aa94f0fbefabf2e15da0567.png)