最近由于在做的电子商务网站,前台要频繁的进行搜索商品,列出符合条件的商品,由于商品数量之大,考虑到要用lucene来显示搜索功能,本文将通过一个简单的例子来告诉你lucene的实现和使用Paoding进行中文分词,当然这是个简单的例子不会包括商品的分类和规格相关属性的查询,主要帮助大家理解和怎么使用lucene进行搜索的实现。
准备工作,首先你要去google一下,下载lucene的jar包lucene-core-3.1.0.jar和paoding-analysis.jar,同时我们要用到json进行封装返回的数据 也可以是xml,我用的json,用到jar包为json-lib-2.2.2-jdk15.jar,同时json还会依赖commons-logging-1.1.jar,ezmorph-1.0.4.jar,commons-beanutils-1.7.0.jar,commons-lang-2.3.jar,commons-collections-3.2.jar,在完成整个例子最后我回提供给外部一个servlet接口供外部进行访问 并返回json格式的结果。
这里还要说lucene和Paoding整合的一个细节
就是要在你下载Paoding之后 ,进行解压,里面有个dic目录 ,这个目录的位置就是要在环境变量设置PAODING_DIC_HOME 的值
同时要将class文件下的paoding-dic-home.properties拷贝到你的工程的src下,里面paoding.dic.home=dic的目录
我的paoding-dic-home.properties为:
paoding.dic.home=F\:\\TDDOWNLOAD\\paoding-analysis-2.0.4-beta\\dic#values are "system-env" or "this";
#if value is "this" , using the paoding.dic.home as dicHome if configed!
#paoding.dic.home.config-fisrt=system-env#dictionary home (directory)
#"classpath:xxx" means dictionary home is in classpath.
#e.g "classpath:dic" means dictionaries are in "classes/dic" directory or any other classpath directory
#paoding.dic.home=dic#seconds for dic modification detectione
#paoding.dic.detector.interval=60下面整个工程的包结构
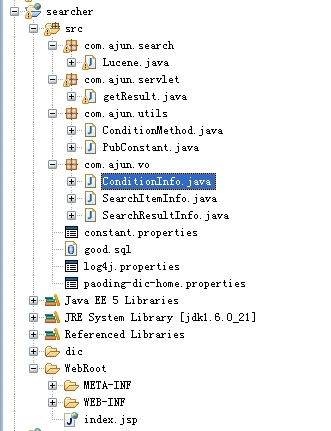
下面介绍包结构和相关类得作用:
com.ajun.search.Lucene.java主要进行建立索引和删除索引,查询的功能。
com.ajun.servlet.getResult.java 供外部调用的servlet,会返回json格式的结果集。
com.ajun.vo
ConditionInfo.java 用于进行将搜索条件封装为对象。
SearchItemInfo.java 单个查询结果对象
SearchResultInfo.java 查询结果集合对象
com.ajun.utils
ConditionMethod.java 用于将条件对象字符串转换为条件对象 或者将条件对象转换为条件字符串,此时会用java反射。
PubConstant.java 用于获得配置文件中一些常量。
废话少说现在上代码:
首先你要创建一个表good 用于创建索引的数据源
create database goodsearch;
use goodsearch;create table good
(id int not null auto_increment,#idname varchar(300),#商品名字price double,#单价imgurl varchar(100) ,uptime datetime,primary key(id)
);
insert into good values(null,'摩托罗拉(Motorola)ME811 3G手机(黑色)CDMA2000/CDMA 电信定制',3990.34,'img/ass/ss/.jpg',now());
insert into good values(null,'Htc G1手机 黑色',1985.34,'img/ass/ss/.jpg',now());
insert into good values(null,'Htc G2手机 黑色',1886.32,'img/ass/ss/.jpg',now());
insert into good values(null,'摩托罗拉(Motorola)MT720 3G手机(黑色)TD-SCDMA/GSM',17.34,'img/ass/ss/.jpg',now());
insert into good values(null,'摩托罗拉(Motorola)XT702 3G手机(黑色)WCDMA/GSM',19.34,'img/ass/ss/.jpg',now());
insert into good values(null,'HTC A8180 Desire渴望 3G手机',22.34,'img/ass/ss/.jpg',now());
insert into good values(null,'索尼爱立信(Sony Ericsson)MT15i 3G手机(蓝色)',25.34,'img/ass/ss/.jpg',now());
insert into good values(null,'三星(SAMSUNG)S5660 3G手机(黑色)WCDMA/GSM',135.34,'img/ass/ss/.jpg',now());
insert into good values(null,'索尼爱立信(Sony Ericsson)MT15i 3G手机(红色)',1205.34,'img/ass/ss/.jpg',now());
insert into good values(null,'黑莓 rss0177 黑色',15.34,'img/ass/ss/.jpg',now());
insert into good values(null,'苹果(APPLE)iPhone 4 16G版 3G手机(黑色)',4999.34,'img/ass/ss/.jpg',now());
insert into good values(null,'诺基亚(NOKIA)5233 GSM手机(黑)非定制机',1225.34,'img/ass/ss/.jpg',now());
insert into good values(null,'苹果(APPLE)iPhone 4 16G版 3G手机(白色)WCDMA/GSM',123.89,'img/ass/ss/.jpg',now());
insert into good values(null,'诺基亚(NOKIA)5233 GSM手机(白)非定制机返140元京券,再送超值读卡器',123.34','img/ass/ss/.jpg',now());
insert into good values(null,'中兴(ZTE)U880 3G手机(灰色)TD-SCDMA/GSM',150.34,'img/ass/ss/.jpg',now());
insert into good values(null,'三星(SAMSUNG)S5830 3G手机(黑色)WCDMA/GSM',5.34,'img/ass/ss/.jpg',now());
insert into good values(null,'诺基亚(NOKIA)C5-03 标准版 3G手机(黑色)WCDMA/GSM 非定制机',145.34,'img/ass/ss/.jpg',now());
insert into good values(null,'HTC S710e 3G手机 WCDMA/GSM 非定制机',151.34,'img/ass/ss/.jpg',now());
insert into good values(null,'三星(SAMSUNG)S5570 3G手机(石灰绿)WCDMA/GSM',215.34,'img/ass/ss/.jpg',now());
insert into good values(null,'诺基亚(NOKIA)E63 3G手机(红)WCDMA/GSM 非定制机',415.34,'img/ass/ss/.jpg',now());
insert into good values(null,'联想(Lenovo)C101 乐phone 3G手机(墨砚黑)CDMA2000/CDMA 电信定制',615.34,'img/ass/ss/.jpg',now());
insert into good values(null,'摩托罗拉(Motorola)ME525 3G手机(黑)WCDMA/GSM 非定制机',1455.34,'img/ass/ss/.jpg',now());
insert into good values(null,'诺基亚(NOKIA)C6-01 3G手机(黑)WCDMA/GSM 非定制机返200元京券!',1235.34,'img/ass/ss/.jpg',now());
insert into good values(null,'华为(HUAWEI)U8800 3G手机(黑色)WCDMA/GSM 联通定制',1335.33,'img/ass/ss/.jpg',now());下面介绍Lucene.java源码
package com.ajun.search;import java.io.File;
import java.io.IOException;
import java.io.StringReader;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;import net.paoding.analysis.analyzer.PaodingAnalyzer;import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.TermAttribute;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.NumericField;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.SortField;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopFieldDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.LockObtainFailedException;
import org.apache.lucene.util.Version;import com.ajun.utils.ConditionMethod;
import com.ajun.utils.PubConstant;
import com.ajun.vo.ConditionInfo;
import com.ajun.vo.SearchItemInfo;
import com.ajun.vo.SearchResultInfo;/** @author ajun * @date 2011-07-31*/
public class Lucene {public static String indexPath;//索引库的路径public static String url;//连接数据库的地址public static String uName;//数据库用户名public static String uPwd; //数据库密码static Analyzer analyzer=null;//分词器static boolean keyword_search=false;static{getParameters();}public static void getParameters(){ indexPath=PubConstant.getValue("search_indexPath");url = PubConstant.getValue("mysql_Url");uName=PubConstant.getValue("mysql_UserName");uPwd=PubConstant.getValue("mysql_Password"); }/*** 生成索引库 goodId为0时候重新建立索引 大于 生成新的索引* @param goodId 商品id*/public static void createIndex(int goodId){Connection conn=null;IndexWriter writer =null;PreparedStatement ps=null;ResultSet rs=null;try {Class.forName("com.mysql.jdbc.Driver");conn=DriverManager.getConnection(url,uName,uPwd);File indexDir=new File(indexPath);if(!indexDir.exists()){indexDir.mkdirs();}String sql = "select id ,name,price,imgurl,uptime from good g ";if(Lucene.analyzer==null){analyzer = new PaodingAnalyzer();//建立索引之前要进行分词}if(goodId==0){writer = new IndexWriter(FSDirectory.open(indexDir), analyzer, true, MaxFieldLength.UNLIMITED); }else{writer = new IndexWriter(FSDirectory.open(indexDir), analyzer, false, MaxFieldLength.UNLIMITED);sql +=" and g.id="+goodId;}ps = conn.prepareStatement(sql); rs = ps.executeQuery();if(rs!=null){while(rs.next()){int id = rs.getInt("id");String name = rs.getString("name");double price = rs.getDouble("price");Date d = rs.getDate("uptime");Document doc = new Document();add(doc,"goodId",String.valueOf(id),2,2f);add(doc,"name",name,1,1f);//需要搜索数字范围字段需要添加成NumericField 字段//add(doc,"price",String.valueOf(price),2,1f);doc.add(new NumericField("price", Field.Store.YES, true).setDoubleValue(price));//和添加其他feild不同啊doc.add(new NumericField("uptime", Field.Store.YES, true).setLongValue(d.getTime()));//如果添加完4个if(doc.getFields().size()==4){writer.addDocument(doc);//添加索引片段}}}rs.close();ps.close();conn.close();} catch (SQLException e) {e.printStackTrace();} catch (ClassNotFoundException e) {e.printStackTrace();}catch (CorruptIndexException e) {e.printStackTrace();} catch (LockObtainFailedException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally{try {if(rs!=null){rs.close();rs = null;}if(ps!=null){ps.close();ps = null;}if(rs!=null){conn.close();conn = null;}} catch (SQLException e) {e.printStackTrace();}try {writer.commit();if (goodId == 0)writer.optimize();//合并索引writer.close();} catch (CorruptIndexException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}/*** * @param doc* @param field 字段名字* @param fieldValue 字段值* @param type * @param boost*/public static void add(Document doc, String field, String fieldValue, int type, float boost){/***Field.Store.COMPRESS:压缩保存,用于长文本或二进制数据 Field.Store.YES:保存Field.Store.NO:不保存Field.Index.NO:不建立索引 Field.Index.TOKENIZED:分词,建索引Field.Index.UN_TOKENIZED:不分词,建索引Field.Index.NO_NORMS:不分词,建索引.但是Field的值不像通常那样被保存,而是只取一个byte,这样节约存储空间Field.TermVector.NO:不保存term vectors Field.TermVector.YES:保存term vectorsField.TermVector.WITH_POSITIONS:保存term vectors.(保存值和token位置信息) Field.TermVector.WITH_OFFSETS:保存term vectors.(保存值和Token的offset)Field.TermVector.WITH_POSITIONS_OFFSETS:保存term vectors.(保存值和token位置信息和Token的offset)*/try{fieldValue=fieldValue==null?"":fieldValue;Field f;switch (type){case 1: f = new Field(field, fieldValue, Field.Store.YES, Field.Index.ANALYZED, Field.TermVector.WITH_POSITIONS_OFFSETS);break;case 2:/** 这个域里面添加内容 "Field.Store.YES"表示域里面的内容将被存储到索引* "Field.Index.TOKENIZED"表示域里面的内容将被索引,以便用来搜索*/f = new Field(field, fieldValue, Field.Store.YES, Field.Index.NOT_ANALYZED);//不分词 但是索引break;case 3: f = new Field(field, fieldValue, Field.Store.YES, Field.Index.NO);//保存 但是不建立索引break;case 4: f = new Field(field, fieldValue, Field.Store.NO, Field.Index.ANALYZED, Field.TermVector.WITH_POSITIONS_OFFSETS);break;case 5: f = new Field(field, fieldValue, Field.Store.NO, Field.Index.NOT_ANALYZED);//不分词 但是索引break; default: f = new Field(field, fieldValue, Field.Store.YES, Field.Index.NO);//不建立索引break;}f.setBoost(boost);doc.add(f);}catch (Exception ex) {}}/*** 删除某个商品的索引* @param goodId* @return*/public static boolean delete(int goodId) {Analyzer an = new StandardAnalyzer(Version.LUCENE_CURRENT);File path = new File(indexPath);IndexReader ireader = null;try {ireader = IndexReader.open(FSDirectory.open(path), false);/*** Term是搜索的最小单位,代表某个 Field 中的一个关键词,如:<title, lucene>* new Term( "title", "lucene" );* new Term( "id", "5" );* new Term( "id", UUID );*/Term t = new Term("goodId", String.valueOf(goodId));ireader.deleteDocuments(t);//删除含有这个goodId的documentreturn true;} catch (CorruptIndexException e) {return false;} catch (IOException e) {return false;} finally {if (ireader != null)try {ireader.close();} catch (IOException e) {e.printStackTrace();}an.close();}}/*** 搜索 * @param condition 条件对象* @return 结果集合*/@SuppressWarnings("deprecation")public static SearchResultInfo search(ConditionInfo condition){Date start=new Date();//搜索开始时间SearchResultInfo sr = new SearchResultInfo();/*** "与或"搜索—BooleanQuery* BooleanQuery也是实际开发过程中经常使用的一种Query。* 它其实是一个组合的Query,在使用时可以把各种Query对象添加进去并标明它们之间的逻辑关系* BooleanClause.Occur.MUST 搜索结果必须满足该 Term* BooleanClause.Occur.MUST_NOT 搜索结果必须排除该 Term* BooleanClause.Occur.SHOULD 搜索结果可以满足该 Term* 利用这三个值可以在 TermQuery 之间构造多种逻辑关系* BooleanClause.Occur.MUST 和 BooleanClause.Occur.MUST 组合在一起:逻辑与 * BooleanQuery q=new BooleanQuery();* Query q1 = new BooleanQuery(Term);* q.add(q1,Occur.MUST )* Query q2 = new BooleanQuery(Term);* q.add(q2,Occur.MUST )* BooleanClause.Occur.MUST_NOT :逻辑非* BooleanClause.Occur.SHOULE :逻辑或**/BooleanQuery bq = new BooleanQuery();if(!ConditionInfo.isEmpty(condition.getGoodId())){//按词条搜索—TermQueryTermQuery tq=new TermQuery(new Term("goodId",condition.getGoodId()));bq.add(tq, Occur.MUST);// 搜索结果必须满足该 Term}if(!ConditionInfo.isEmpty(condition.getMinPrice()) || !ConditionInfo.isEmpty(condition.getMaxPrice())){double minPrice=0f;double maxPrice=99999999f;if(!ConditionInfo.isEmpty(condition.getMinPrice()))minPrice=Double.valueOf(condition.getMinPrice());if(!ConditionInfo.isEmpty(condition.getMaxPrice()))maxPrice=Double.valueOf(condition.getMaxPrice());//BooleanQuery pricebq=new BooleanQuery();Query q = NumericRangeQuery.newDoubleRange("price",minPrice,maxPrice, true, true);// Occur.SHOULD搜索结果可以满足该 Termbq.add(q,Occur.MUST);}if(!ConditionInfo.isEmpty(condition.getWithoutWords())){TermQuery tq=new TermQuery(new Term("name",condition.getWithoutWords()));bq.add(tq, Occur.MUST_NOT);}IndexSearcher search =null;IndexReader reader=null;try {File path = new File(indexPath);Directory dir = FSDirectory.open(path);reader = IndexReader.open(dir);search = new IndexSearcher(reader);String sortname=condition.getOrderbyName();String sortvalue=condition.getOrderbyValue();if(ConditionInfo.isEmpty(condition.getOrderbyName())){sortname = "uptime";} boolean order = false;if(sortvalue.equals("asc") || sortvalue.equals("") || ConditionInfo.isEmpty(condition.getOrderbyName())){order = false;}else if(sortvalue.equals("desc")){order= true;}//由于只是价格和时间进行排序int sortType=SortField.LONG;if(!ConditionInfo.isEmpty(condition.getOrderbyName()) && "price".equals(sortname)){sortType=SortField.FLOAT;}//中间参数表示排序字段类型,true 表示降序 false 升序SortField SortField_1 = new SortField(sortname, sortType, order); SortField[] sortField_arr = new SortField[]{SortField_1};Sort sort = new Sort(sortField_arr);if(!ConditionInfo.isEmpty(condition.getKeyWords())){if(analyzer==null){analyzer = new PaodingAnalyzer();}QueryParser parser = new QueryParser(Version.LUCENE_CURRENT,"name", analyzer);Query query = parser.parse(condition.getKeyWords()); bq.add(query, Occur.MUST);TokenStream ts =analyzer.tokenStream("", new StringReader(condition.getKeyWords())) ; ts.reset();TermAttribute termAtt = (TermAttribute) ts.addAttribute(TermAttribute.class);List<String> words=new ArrayList<String>();while (ts.incrementToken()) {words.add(termAtt.term());}sr.setSplitWords(words);}TopFieldDocs topdoc = search.search(bq,null,Integer.parseInt(condition.getPageIndex())*Integer.parseInt(condition.getPageSize()), sort);ScoreDoc[] hits= topdoc.scoreDocs;if(hits!=null && hits.length>0){int begin = (Integer.parseInt(condition.getPageIndex()) - 1) * Integer.parseInt(condition.getPageSize());int end = Integer.parseInt(condition.getPageIndex()) * Integer.parseInt(condition.getPageSize()); int min = Math.min(end, topdoc.totalHits);sr.setTotalCount((topdoc.totalHits > 100 * Integer.parseInt(condition.getPageSize())) ? (100 * Integer.parseInt(condition.getPageSize())) : topdoc.totalHits);sr.setPageSize(Integer.parseInt(condition.getPageSize()));sr.setPageIndex(Integer.parseInt(condition.getPageIndex()));sr.setRealCount(topdoc.totalHits);int totalpage = topdoc.totalHits % Integer.parseInt(condition.getPageSize()) == 0 ? (topdoc.totalHits / Integer.parseInt(condition.getPageSize())) : ((topdoc.totalHits / Integer.parseInt(condition.getPageSize())) + 1);sr.setPageCount((totalpage > 100 ? 100 : totalpage));//限制只有100页List<SearchItemInfo> list=new ArrayList<SearchItemInfo>();for(int i = begin; i < min; i++){Document hitDoc = search.doc(hits[i].doc);SearchItemInfo item = new SearchItemInfo();item.setId(Integer.parseInt(hitDoc.get("goodId")));String name=hitDoc.get("name");item.setName(name); String price=hitDoc.get("price");item.setPrice(price);list.add(item); } keyword_search=false;sr.setItemLists(list); }} catch (CorruptIndexException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} catch (ParseException e) {e.printStackTrace();}finally{if(reader !=null){try {reader.close();} catch (IOException e) {e.printStackTrace();}}if(search !=null){try {search.close();} catch (IOException e) {e.printStackTrace();}}}Date end=new Date();System.out.println("Time used:"+String.valueOf(end.getTime()-start.getTime())+"ms,searchUrl:"+ConditionMethod.getConditionUrl(condition));return sr;}}
package com.ajun.vo;/*我们可以用这个类 进行搜索条件的拼装 很方便啊* @author ajun * @date 2011-07-31*/
public class ConditionInfo {public String keyWords="";//搜索的关键字public String withoutWords="";//要过滤的关键字public String goodId="";//商品idpublic String minPrice="";//最小价格public String maxPrice="";//最大价格public String orderbyName="uptime";//排序字段 默认是更新时间public String orderbyValue="desc";//desc降序 asc升序public String pageSize="20";//每页显示多少条 默认20public String pageIndex="1";//页码开始位置public String getGoodId() {return goodId;}public void setGoodId(String goodId) {this.goodId = goodId;}public String getMinPrice() {return minPrice;}public void setMinPrice(String minPrice) {this.minPrice = minPrice;}public String getMaxPrice() {return maxPrice;}public void setMaxPrice(String maxPrice) {this.maxPrice = maxPrice;}/*** @return the keyWords*/public String getKeyWords() {return keyWords;}/*** @param keyWords the keyWords to set*/public void setKeyWords(String keyWords) {this.keyWords = keyWords.replaceAll("\\*|\\?|\\@|\\#|\\%|\\~|\\$|\\^|\\&|\\(|\\)|\\_|\\+|\\-|\\!", "");}/*** 排除关键词* @return the withoutWords*/public String getWithoutWords() {return withoutWords;}/*** 排除关键词* @param withoutWords the withoutWords to set*/public void setWithoutWords(String withoutWords) {this.withoutWords = withoutWords.replaceAll("\\*|\\?|\\@|\\#|\\%|\\~|\\$|\\^|\\&|\\(|\\)|\\_|\\+|\\-|\\!", "");}/*** 排序名称,即使用哪个字段排序* 排序用的字段有(即orderbyName的值有以下几种): uptime(上架时间,默认排序字段) * @return the orderbyName*/public String getOrderbyName() {return orderbyName;}/*** 排序名称,即使用哪个字段排序* 排序用的字段有(即orderbyName的值有以下几种): uptime(上架时间,默认排序字段)* @param orderbyName the orderbyName to set*/public void setOrderbyName(String orderbyName) {this.orderbyName = orderbyName;}/*** 排序值,可以是asc desc 空。* @return the orderbyValue*/public String getOrderbyValue() {return orderbyValue;}/*** 排序值,可以是asc desc 空。* @param orderbyValue the orderbyValue to set*/public void setOrderbyValue(String orderbyValue) {this.orderbyValue = orderbyValue;}/*** @return the pageSize*/public String getPageSize() {return pageSize;}/*** @param pageSize the pageSize to set*/public void setPageSize(String pageSize) {this.pageSize = pageSize;}/*** @return the pageIndex*/public String getPageIndex() {return pageIndex;}/*** @param pageIndex the pageIndex to set*/public void setPageIndex(String pageIndex) {this.pageIndex = pageIndex;}/*** 判断是否为空* @param s* @return*/public static boolean isEmpty(String s){if(s ==null || "".equals(String.valueOf(s))){return true;}return false;}
}
SearchItemInfo类 查询结果类 ,封装了和商品相关的属性
package com.ajun.vo;/** @author ajun * @date 2011-07-31*/
public class SearchItemInfo
{private int id;private String name;private String imgurl;private String price;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getImgurl() {return imgurl;}public void setImgurl(String imgurl) {this.imgurl = imgurl;}public String getPrice() {return price;}public void setPrice(String price) {this.price = price;}}SearchResultInfo.java类 结果集对象 其中包含了和分页相关的属性、结果对象集合
package com.ajun.vo;import java.util.List;/** @author ajun * @date 2011-07-31*/
public class SearchResultInfo {private int totalCount;//总记录数private int pageCount;//总页数 最大为100private int pageSize;//每页显示多少条private int pageIndex;//页码private List<SearchItemInfo> itemLists;//结果集合private int realCount;//真实记录数private List<String> splitWords;//用于进行高亮显示的词语集合public int getTotalCount() {return totalCount;}public void setTotalCount(int totalCount) {this.totalCount = totalCount;}public int getPageCount() {return pageCount;}public void setPageCount(int pageCount) {this.pageCount = pageCount;}public int getPageSize() {return pageSize;}public void setPageSize(int pageSize) {this.pageSize = pageSize;}public int getPageIndex() {return pageIndex;}public void setPageIndex(int pageIndex) {this.pageIndex = pageIndex;}public List<SearchItemInfo> getItemLists() {return itemLists;}public void setItemLists(List<SearchItemInfo> itemLists) {this.itemLists = itemLists;}public int getRealCount() {return realCount;}public void setRealCount(int realCount) {this.realCount = realCount;}public List<String> getSplitWords() {return splitWords;}public void setSplitWords(List<String> splitWords) {this.splitWords = splitWords;}}
ConditionMethod.java 用于将条件字符串和条件对象互相转换的辅助类 如:---10.00-300.00-uptime-desc-20-1和条件对象转换
package com.ajun.utils;
import java.io.UnsupportedEncodingException;
import java.lang.reflect.*;import com.ajun.vo.ConditionInfo;/** @author ajun * @date 2011-07-31*/
public class ConditionMethod {/*** 将条件对象转换为类似于* ---10.00-300.00-uptime-desc-20-1这样形式,条件对象的值用‘-’相隔* @param c* @return*/public static String getConditionUrl(ConditionInfo c){Class<?> class1=c.getClass();Field[] fields=class1.getFields(); StringBuilder sb=new StringBuilder();for(int i=0;i<fields.length;i++){Object o=null;try {o = fields[i].get(c);} catch (IllegalArgumentException e) {e.printStackTrace();} catch (IllegalAccessException e) {e.printStackTrace();}sb.append(o==null?"":o).append("-"); }if(sb.length()>0)sb.deleteCharAt(sb.length()-1);try {return java.net.URLEncoder.encode(sb.toString(),"utf-8");} catch (UnsupportedEncodingException e) {e.printStackTrace();}return null;}/*** 将条件字符创转换为条件对象* @param condition* @return*/public static ConditionInfo getConditionInfo(String condition){ Class<?> class1;try {class1 = Class.forName("com.ajun.vo.ConditionInfo");Object tObject=class1.newInstance(); String[] urls=condition.split("\\-",100); Field[] fields=class1.getFields();if(fields.length!=urls.length)return null;for(int i=0;i<fields.length;i++){Field field=fields[i];field.setAccessible(true); field.set(tObject, urls[i]);} return (ConditionInfo) tObject;} catch (ClassNotFoundException e) {e.printStackTrace();} catch (InstantiationException e) {e.printStackTrace();} catch (IllegalAccessException e) {e.printStackTrace();}return null;}
}
PubConstant.java读取常量的辅助类
package com.ajun.utils;import java.io.IOException;
import java.util.Properties;/** @author ajun * @date 2011-07-31*/
public class PubConstant {private static Properties properties= new Properties();static{try {properties.load(PubConstant.class.getClassLoader().getResourceAsStream("constant.properties"));} catch (IOException e) {e.printStackTrace();}}public static String getValue(String key){String value = (String)properties.get(key);return value.trim();}
}
至此整个代码以完成,下面提供外部调用的servlet
package com.ajun.servlet;import java.io.IOException;
import java.io.PrintWriter;import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;import net.sf.json.JSONObject;import com.ajun.search.Lucene;
import com.ajun.utils.ConditionMethod;
import com.ajun.vo.ConditionInfo;
import com.ajun.vo.SearchResultInfo;
/** @author ajun * @date 2011-07-31*/
public class getResult extends HttpServlet {public void doGet(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException {this.doPost(request, response);}public void doPost(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException {response.setContentType("text/json");PrintWriter out = response.getWriter();String condition = request.getParameter("condition");if(condition!=null && !"".equals(condition.trim())){condition = new String(condition.getBytes("iso-8859-1"),"utf-8");ConditionInfo info = ConditionMethod.getConditionInfo(condition);SearchResultInfo s = Lucene.search(info);out.println(JSONObject.fromObject(s));}out.flush();out.close();}
}
下面写个方法测试一下吧:
public static void main(String [] args){createIndex(0);ConditionInfo con = new ConditionInfo();//con.setGoodId("1");con.setMinPrice("10.00");con.setMaxPrice("300.00");con.pageIndex="1";con.setPageSize("5");//con.setKeyWords("电信定制");SearchResultInfo res = search(con);if(res!=null && res.getItemLists()!=null){for(SearchItemInfo item : res.getItemLists()){System.out.println("name==>"+item.getName()+" price==>"+item.getPrice() +" ID==>"+item.getId());}}}结果为:
Time used:1734ms,searchUrl:---10.00-300.00-uptime-desc-20-1
name==>摩托罗拉(Motorola)MT720 3G手机(黑色)TD-SCDMA/GSM price==>17.34 ID==>4
name==>摩托罗拉(Motorola)XT702 3G手机(黑色)WCDMA/GSM price==>19.34 ID==>5
name==>HTC A8180 Desire渴望 3G手机 price==>22.34 ID==>6
name==>索尼爱立信(Sony Ericsson)MT15i 3G手机(蓝色) price==>25.34 ID==>7
name==>三星(SAMSUNG)S5660 3G手机(黑色)WCDMA/GSM price==>135.34 ID==>8
name==>黑莓 rss0177 黑色 price==>15.34 ID==>10
name==>苹果(APPLE)iPhone 4 16G版 3G手机(白色)WCDMA/GSM price==>123.89 ID==>13
如果大家要源代码请到我的资源中进行下载吧.....