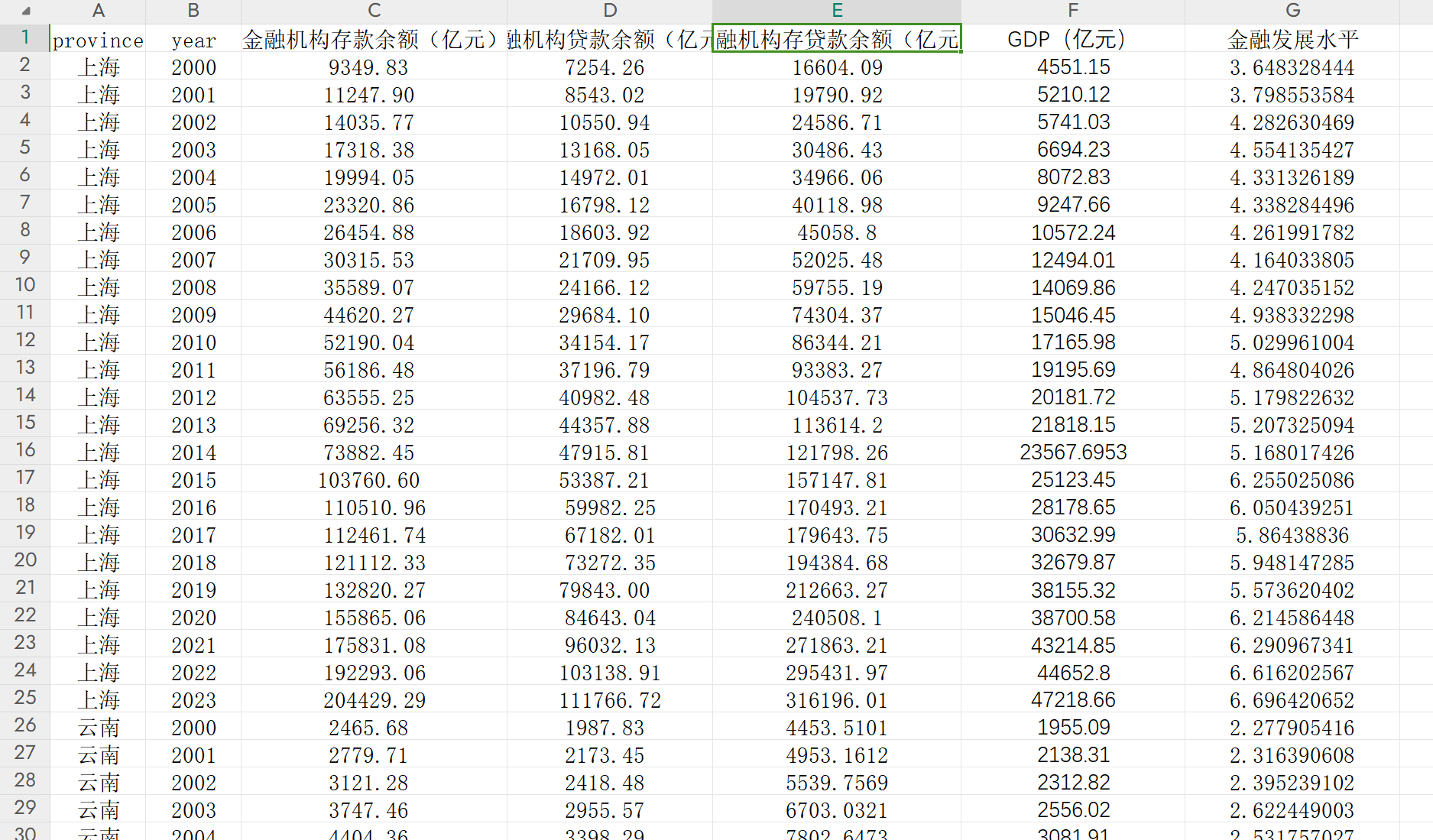
在 Spark 分布式计算 中,网络传输和序列化是数据处理的重要组成部分。Spark 通过将任务划分为多个分布式计算节点来处理数据,而序列化和网络传输直接影响计算性能和数据交互效率。
1. 序列化在 Spark 中的作用
序列化是 Spark 将数据对象转换为字节流以进行网络传输或存储的关键步骤。它贯穿于以下环节:
- 任务调度:Driver 将任务分发到 Executor 时,需序列化任务代码和依赖数据。
- 数据传输:在宽依赖(如
shuffle阶段)中,数据从一个节点发送到另一个节点。 - 缓存和存储:数据持久化到内存或磁盘时(如 RDD 缓存)需要序列化。
Spark 默认支持两种序列化机制:
配置示例:
spark.serializer=org.apache.spark.serializer.KryoSerializer
2. 网络传输在 Spark 中的作用
Spark 通过网络传输完成以下任务:
- 任务分发:Driver 向 Executor 分发任务时依赖网络。
shuffle阶段:将 map 阶段的输出数据传输到 reduce 阶段的节点。- 广播变量:Driver 向所有 Executor 发送共享变量。
- 节点间通信:包括心跳、任务状态汇报等。
网络传输的数据量和延迟直接影响任务执行时间。
3. 序列化与网络传输的关系
(1)数据体积和传输效率
序列化后数据的体积决定了传输效率。高效的序列化方式(如 Kryo 或 Avro)可以显著减少数据体积,降低网络带宽的占用。例如:
(2)CPU 消耗和传输延迟的权衡
(3)shuffle 阶段的关键角色
4. 优化 Spark 中的网络传输与序列化
- 启用 Kryo 序列化:通过
spark.serializer配置 Kryo,尤其适合大数据场景。 - 数据压缩:启用压缩减少传输数据量:
spark.shuffle.compress=true spark.broadcast.compress=true - 减少
shuffle数据量:优化 RDD 转换链,避免不必要的shuffle。 - 广播变量优化:对于大数据量广播,使用 Spark 的广播机制(如
Broadcast<T>)。 - 分区设计:合理设置分区数,避免单个 Executor 或任务传输过多数据。
示例分析
-
默认 Java 序列化与 Kryo 性能对比
-
shuffle阶段- 大量数据传输在宽依赖(如
groupByKey)时,启用 Kryo 和压缩后传输效率可提高 30%-50%。
- 大量数据传输在宽依赖(如
Spark 中序列化和网络传输的优化直接关系到分布式计算的整体性能。结合高效的序列化工具(如 Kryo)和合理的网络传输策略(如压缩、分区优化),可以显著提高数据处理效率。