代码功能
- 数据准备
加载数据:从公开的航空旅客人数数据集(Airline Passengers Dataset)中读取时间序列数据。
对数变换和平稳化:对数据应用 log1p 函数减少趋势和波动,使模型更容易学习规律。
归一化处理:将数据缩放到 [0, 1] 区间,以适应神经网络训练。 - 数据集创建
滑动窗口机制:使用过去 seq_length(12个月)作为输入,预测下一个月的值。
划分数据集:将时间序列数据划分为训练集(80%)和测试集(20%)。 - 模型定义
LSTM 模型:
输入特征维度:每个月的数据点作为输入特征(维度为 1)。
隐藏层维度:每层隐藏层包含 128 个神经元。
层数:10 层 LSTM 堆叠,增加模型的表达能力。
全连接层(FC Layer):LSTM 的输出通过全连接层,生成最终预测值。 - 模型训练
损失函数:使用均方误差(MSE),衡量预测值与真实值之间的误差。
优化器:使用 Adam 优化器,动态调整学习率提高收敛速度。
GPU 加速:如果设备支持,则将模型和数据移至 GPU,显著加速训练。
训练过程中,模型使用批量数据更新权重,逐步最小化损失函数。 - 模型评估
预测值生成:在测试集上进行预测。
反归一化和还原对数变换:将预测值和真实值转换回原始规模,便于直观对比。
性能评估:计算均方误差(MSE),衡量模型的预测准确性。 - 可视化结果
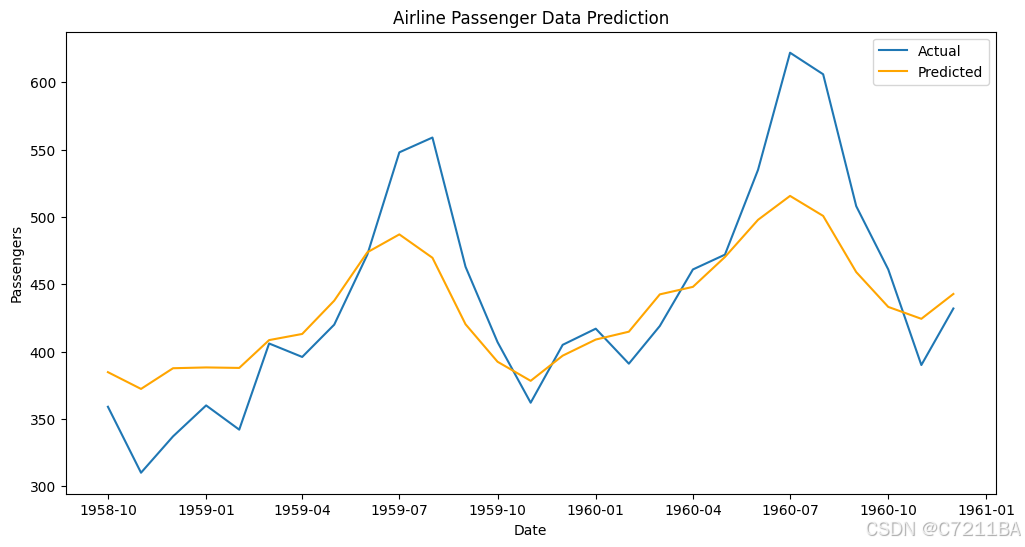
实际值 vs. 预测值:绘制原始数据的真实值与预测值对比图,直观展现模型效果。
代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch import nn
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from torch.utils.data import DataLoader, TensorDataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv"
data = pd.read_csv(url, parse_dates=['Month'], index_col='Month')
data_values = data['Passengers'].values.astype(float).reshape(-1, 1)
data_log = np.log1p(data_values)
scaler = MinMaxScaler(feature_range=(0, 1))
normalized_data = scaler.fit_transform(data_log)
def create_dataset(data, seq_length):X, y = [], []for i in range(len(data) - seq_length):X.append(data[i:i + seq_length])y.append(data[i + seq_length])return np.array(X), np.array(y)seq_length = 12
X, y = create_dataset(normalized_data, seq_length)
train_size = int(len(X) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32)
train_dataset = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
class LSTMModel(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, num_layers):super(LSTMModel, self).__init__()self.hidden_dim = hidden_dimself.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True, dropout=0.2)self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):h0 = torch.zeros(num_layers, x.size(0), self.hidden_dim).to(x.device)c0 = torch.zeros(num_layers, x.size(0), self.hidden_dim).to(x.device)out, _ = self.lstm(x, (h0, c0))out = self.fc(out[:, -1, :])return out
input_dim = 1
hidden_dim = 128
output_dim = 1
num_layers = 10
learning_rate = 0.0001
num_epochs = 300
model = LSTMModel(input_dim, hidden_dim, output_dim, num_layers)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
for epoch in range(num_epochs):model.train()for X_batch, y_batch in train_loader:X_batch, y_batch = X_batch.to(device), y_batch.to(device)outputs = model(X_batch)optimizer.zero_grad()loss = criterion(outputs, y_batch)loss.backward()optimizer.step()if (epoch + 1) % 10 == 0:print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
model.eval()
with torch.no_grad():y_pred = model(X_test.to(device)).cpu().numpy()
y_test_inv = scaler.inverse_transform(y_test.numpy())
y_pred_inv = scaler.inverse_transform(y_pred)
mse = mean_squared_error(np.expm1(y_test_inv), np.expm1(y_pred_inv))
print(f"Mean Squared Error: {mse:.4f}")
plt.figure(figsize=(12, 6))
plt.plot(data.index[-len(y_test):], np.expm1(y_test_inv), label='Actual')
plt.plot(data.index[-len(y_test):], np.expm1(y_pred_inv), label='Predicted', color='orange')
plt.title('Airline Passenger Data Prediction')
plt.xlabel('Date')
plt.ylabel('Passengers')
plt.legend()
plt.show()


![[开源] 告别黑苹果!用docker安装MacOS体验苹果系统](https://img-blog.csdnimg.cn/228bc0de51b54cc4bd6b7be05bbe086b.png)


