一 背景
docker 下的nginx的服务,在一些情况下访问请求会反馈比较慢,根据网文学习下,记录下一些实验过程。
二 验证环境
docker 太难下载了,找了一个老的环境的nginx,导入到系统中来:
// 导入nginx
# docker load -i nginx.tar.gz
// 启动nginx 以本地端口启动
# docker run -d -p 8153:80 --name my-nginx nginx查看验证下web是否启动
[root@nms ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f5de348d753e nginx "/docker-entrypoint.…" About a minute ago Up About a minute 0.0.0.0:8153->80/tcp my-nginx
7a2a244a57f8 splos:5.1nms "/bin/sh /etc/rcS_do…" 2 weeks ago Up 23 hours 5.1nms
[root@nms ~]# netstat -antp|grep 8153
tcp6 0 0 :::8153 :::* LISTEN 2480/docker-proxy # 访问也是正常的
[root@nms ~]# curl http://127.0.0.1:8153
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>body {width: 35em;margin: 0 auto;font-family: Tahoma, Verdana, Arial, sans-serif;}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p><p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p><p><em>Thank you for using nginx.</em></p>
</body>
</html>用ab测试下web的性能:
// -c 是5000个并发,一共发起请求10w个 -r 接受到错误仍然继续,-s 超时时间为2s
# ab -c 5000 -n 100000 -r -s 2 http://10.xx.xx.xxx:8153/
Document Path: /
Document Length: 612 bytesConcurrency Level: 5000
Time taken for tests: 9.158 seconds
Complete requests: 100000
Failed requests: 5397(Connect: 0, Receive: 0, Length: 2741, Exceptions: 2656)
Write errors: 0
Total transferred: 82191460 bytes
HTML transferred: 59528016 bytes
Requests per second: 10919.47 [#/sec] (mean)
Time per request: 457.898 [ms] (mean)
Time per request: 0.092 [ms] (mean, across all concurrent requests)
Transfer rate: 8764.52 [Kbytes/sec] receivedConnection Times (ms)min mean[+/-sd] median max
Connect: 0 255 741.4 5 7029
Processing: 18 112 277.4 50 7372
Waiting: 0 107 266.6 48 6758
Total: 27 367 817.0 57 8660Percentage of the requests served within a certain time (ms)50% 5766% 6675% 24980% 44990% 105995% 142998% 306299% 3272100% 8660 (longest request)注意看下几个关键指标:
Requests per second: 10919.47 [#/sec] (mean) 每秒平均请求数量10919.47
Time per request: 457.898 [ms] (mean) 每个请求的平均延迟为457ms
Connect: 0 255 741.4 5 7029: 建立链接的平均延迟255ms再启动一个直接映射本地端口的nginx的容器:
// 启动一个直接映射端口的nginx容器
# docker run -d -p 9123:80 --network=host --privileged --name my-nginx-host1 nginx本想这样启动将容器的80端口映射到9123 ,结果没效果,设置了host网络后,映射端口的配置失效,更改如下:
// 拷贝一个nginx.conf 然后直接做文件映射替换原来的文件,结果如下
[root@nms ~]# docker run -d --network=host --privileged --name my-nginx-host4 -v /root/nginx.conf:/etc/nginx/nginx.conf nginx用ab这个工具继续测试:
// 说明同上
[root@localhost spiderflow]# ab -c 5000 -n 100000 -r -s 2 http://10.xx.xx.xxx:9153/
// 关键信息如下
Document Path: /
Document Length: 612 bytesConcurrency Level: 5000
Time taken for tests: 5.356 seconds
Complete requests: 100000
Failed requests: 16296(Connect: 0, Receive: 25, Length: 8192, Exceptions: 8079)
Write errors: 0
Total transferred: 77597195 bytes
HTML transferred: 56200572 bytes
Requests per second: 18670.58 [#/sec] (mean)
Time per request: 267.801 [ms] (mean)
Time per request: 0.054 [ms] (mean, across all concurrent requests)
Transfer rate: 14148.28 [Kbytes/sec] receivedConnection Times (ms)min mean[+/-sd] median max
Connect: 0 139 442.0 5 3036
Processing: 11 58 113.6 31 1663
Waiting: 0 49 108.7 27 1653
Total: 16 196 480.4 37 4651Percentage of the requests served within a certain time (ms)50% 3766% 5675% 10080% 13790% 44395% 104198% 182599% 3036100% 4651 (longest request)可以看到通过配置host网络方式,即端口直接映射到主机上,不做端口转换的情况下,性能会提升不少;
Requests per second: 18670.58 [#/sec] (mean) 平均请求数量从1w左右提升到了1.8w
Time per request: 267.801 [ms] (mean) 每个请求平均延迟也从457ms降低到了267ms
Connect: 0 139 442.0 5 3036 平均建链延迟从255ms降低到139ms不过这个异常数也更多,异常数更改-s后面的超时时间,可以显著降低,这个先不关注; 需要环境建立好了之后就可以排查原因了。
三 问题排查
3.1 抓包排查问题
排查网络问题,抓包一般必不可少,我们先来抓点包看看什么情况:
[root@nms ~]# tcpdump -i ens192 tcp port 8153 -w a.pcap用wireshark打开分析: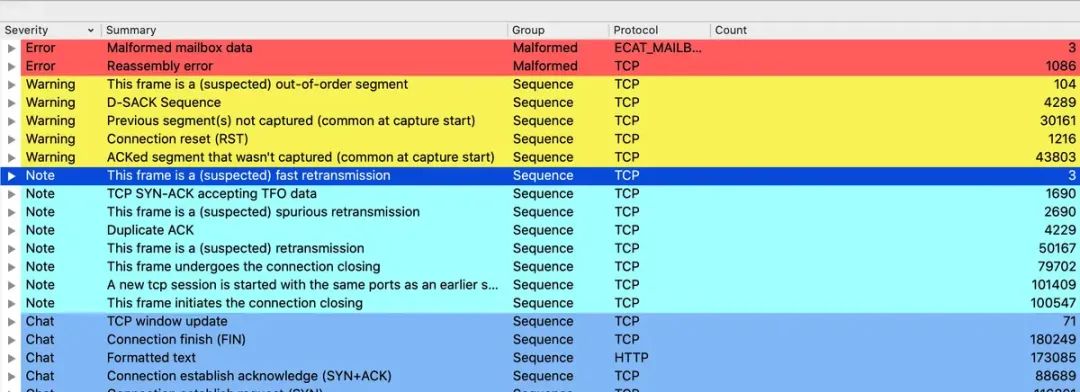
从信息来看不少包重组失败,实际看下来,有各种重传错误,REST包等,如下: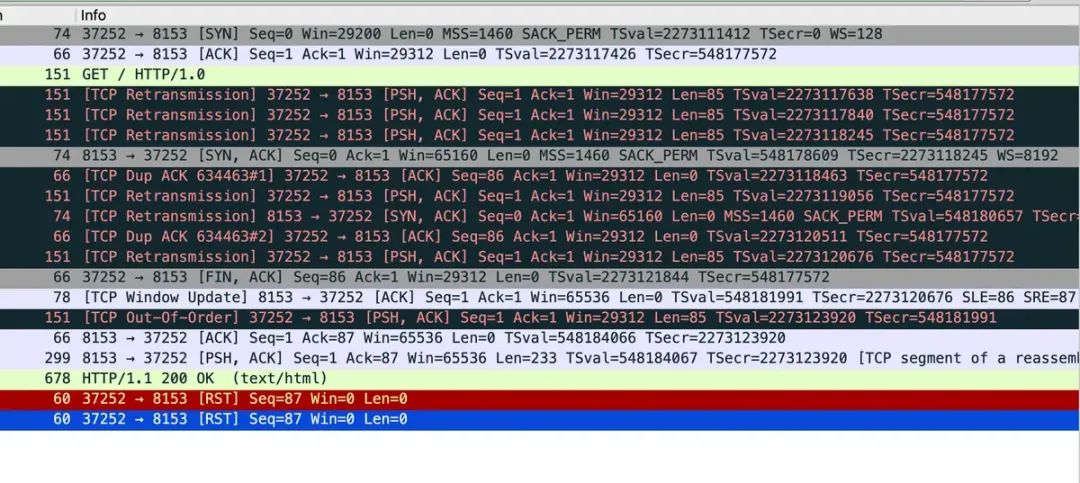
3.2 丢包原因分析
从上面报文重组失败的情况来看,显然是发生了丢包,因为程序是一样的,运行环境是一样的,所以丢包肯定只能是内核里面丢包,需要排查具体哪里丢的,什么原因丢的。 可以使用动态追踪工具来排查丢包原因,eBPF 在centos下相对来说安装比较麻烦,我们用systemstap,追踪脚本如下:
#! /usr/bin/env stap############################################################
# Dropwatch.stp
# Author: Neil Horman <nhorman@redhat.com>
# An example script to mimic the behavior of the dropwatch utility
# http://fedorahosted.org/dropwatch
############################################################# Array to hold the list of drop points we find
global locations# Note when we turn the monitor on and off
probe begin { printf("Monitoring for dropped packets\n") }
probe end { printf("Stopping dropped packet monitor\n") }# increment a drop counter for every location we drop at
probe kernel.trace("kfree_skb") { locations[$location] <<< 1 }# Every 5 seconds report our drop locations
probe timer.sec(5)
{printf("\n")foreach (l in locations-) {printf("%d packets dropped at %s\n",@count(locations[l]), symname(l))}delete locations
}简单来说,就是打印内核调用kfree_skb的位置,这些位置即是丢包的位置; 打印的结果类似:
// 执行
stap -g --all-modules dropwatch.stp12 packets dropped at nf_hook_slow
11 packets dropped at ip_rcv_finish
8 packets dropped at ip6_mc_input
1 packets dropped at icmpv6_rcv9 packets dropped at nf_hook_slow
6 packets dropped at ip6_mc_input
5 packets dropped at ip_rcv_finish
1 packets dropped at tcp_v6_rcv19 packets dropped at ip_rcv_finish
12 packets dropped at nf_hook_slow
8 packets dropped at ip6_mc_input
^CStopping dropped packet monitor通过上面脚本我们知道具体的丢包函数集中在:nf_hook_slow ,这个函数是 Netfilter 框架的一部分,它负责执行挂钩(hooking)到内核网络层的自定义函数,这些函数通常用于包过滤、网络地址转换(NAT)、数据包修改等。另外换个思路,但是我们注意到上面的测试情况,在同一台主机上,同一个镜像,唯一的区别就是一个做了端口映射,一个直接通过主机网络,通过主机网络这种方式直接在主机的默认网络空间开的端口,没有经过NAT转换,也就是说NAT转换造成的性能差异,我们先看看NAT转换的配置:
# 即显示NAT转换表 -n 表示不做ip转成域名、-L显示列表 -t nat 只查询nat表;
#iptables -nL -t nat我们知道docker如果默认的网络的IP是内部172的IP段,和外部服务交互的时候,需要将172这个ip转成主机的IP,这就要做SNAT转换; 另外外部服务回消息的时候,要通过DNAT转成内部的端口。 我们来看下NAT表内容:
[root@nms ~]# iptables -nL -t nat
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DOCKER all -- 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCALChain INPUT (policy ACCEPT)
target prot opt source destination Chain OUTPUT (policy ACCEPT)
target prot opt source destination
DOCKER all -- 0.0.0.0/0 !127.0.0.0/8 ADDRTYPE match dst-type LOCALChain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.17.0.0/16 0.0.0.0/0
MASQUERADE tcp -- 172.17.0.3 172.17.0.3 tcp dpt:80Chain DOCKER (2 references)
target prot opt source destination
RETURN all -- 0.0.0.0/0 0.0.0.0/0
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8153 to:172.17.0.3:80其中比较关键的配置:MASQUERADE all -- 172.17.0.0/16 0.0.0.0/0 表示从容器IP段172.17.0.0/16 发出来的所有包(目的地址不做限制,协议不限制)都做源地址伪造,即源地址替换为本机地址;MASQUERADE tcp -- 172.17.0.3 172.17.0.3 tcp dpt:80 这条规则比较少见,对于tcp协议,源地址为172.17.0.3 地址,(即咱们前面启动的nginx容器,映射的端口为8153端口)访问的目的地址为:172.17.0.3 地址,tcp端口为80的时候,将做源地址伪造,举例:
172.17.0.3:1234------> 172.17.0.3:80即172.17.0.3连接本机的80端口,会被规则改变成:
10.xx.xx.xx:1234------> 172.17.0.3:80这条没看出来有啥重要作用,感觉不映射也问题不大,毕竟都是本机访问,连网卡都不用走吧,为什么需要,知道的兄弟告知下。
重要的还有下面一条规则:
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8153 to:172.17.0.3:80即在tcp报文中,任意ip访问任意ip的时候,如果tcp的目的端口是8153,将它转发给容器的172.17.0.3 的80端口,上面的RETURN表示其他情况直接返回正常流程处理。
通过上面可知,docker访问外部的时候,源IP地址被转换为主机的ip,返回的时候通过DNAT配置把映射主机的端口,映射到具体的容器的端口上,这里是80端口。
通过上面分析,只是梳理了一下Docker容器的网络包转发的流程,并没有找到慢的原因。
3.2 NAT转换性能排查
由于我们上面几乎可以肯定是NAT转换问题,那问题就转到如何排查的,通过上面的规则分析,请求和返回的时候都需要做NAT地址信息的转换,转换的时候是需要保存每个连接的状态,跟踪连接的状态的,才能根据映射端口映射到正确的容器的正确端口上去。
cat /proc/net/nf_conntrack四 问题解决
4.1 systemtap安装
在centos下安装:
yum install systemtap kernel-devel yum-utils kernel4.2 systemtap 丢包打印 只有地址没有打印函数名
错误现象:
[root@miao miao]# ./dropwatch.stp
Monitoring for dropped packets
18 packets dropped at 0xffffffff8341ab57
17 packets dropped at 0xffffffff8342704d
24 packets dropped at 0xffffffff8342704d
8 packets dropped at 0xffffffff8341ab57
8 packets dropped at 0xffffffff8341ab57
3 packets dropped at 0xffffffff8342704d
1 packets dropped at 0xffffffff834df57c
...原因就是缺少内核符号表:
vim /etc/yum.repos.d//CentOS-Linux-Debuginfo.repo将里面的enable改成1. 安装内核符号表:
debuginfo-install -y kernel-$(uname -r)
// 或安装
yum install kernel-debuginfo kernel-devel// 执行准备
stap-prep
sysctl -w kernel.printk="7 4 1 7"