在深度学习的计算机视觉任务中,提升图像分辨率和压缩特征图是重要需求。Pixel Shuffle和Pixel Unshuffle是在超分辨率、图像生成等任务中常用的操作,能够通过转换空间维度和通道维度来优化图像特征表示。本篇文章将深入介绍这两种操作的原理,并结合PyTorch实现可视化展示,希望能帮助大家更好地理解他们的用途与效果。
为什么需要Pixel Shuffle和Pixel Unshuffle
Pixel Shuffle是一种从特征图中提取空间信息的方法,主要应用于图像超分辨率等任务。超分辨率(Super-Resolution,SR)指的是通过机器学习算法生成比输入分辨率更好的图像。Pixel Shuffle操作可以帮助模型通过减少通道数、扩大空间分辨率来重建出更精细的图像。这不仅有效提升了模型的效果,还在一定程度上降低了计算成本。
相对应地,Pixel Unshuffle是Pixel Shuffle的逆操作,将空间维度重新映射回通道维度,这在特征压缩和编码解码任务中非常有用。
Pixel Shuffle和Pixel Unshuffle的原理解释及代码示例
Pixel Shuffle的工作原理
Pixel Shuffle是一种将通道维度转换为空间维度的操作,用于将特征图从较低的空间分辨率上采样到较高的分辨率。它的基本工作过程如下:
假设输入特征图的维度是 C × H × W C×H×W C×H×W,我们希望将其上采样到更高的空间分辨率 r H × r W rH×rW rH×rW,其中 r r r是放大倍率。Pixel Shuffle的操作步骤如下:
- 分解通道数:将特征图通道 C C C分解为 C ′ = C r 2 C'=\frac{C}{r^2} C′=r2C,其中 C ′ C' C′是新的通道数。
- 增加空间维度:将输入特征图的维度从 C × H × W C×H×W C×H×W变为 C ′ × r × r × H × W C'×r×r×H×W C′×r×r×H×W,其中 r × r r×r r×r是每个通道中的小块大小。
- 重排特征图:将 r × r r×r r×r的小块移动到空间维度上,形成一个大小为 C ′ × r H × r W C'×rH×rW C′×rH×rW的特征图。
通过上述过程,Pixel Shuffle可以将特征图的空间分辨率从 H × W H×W H×W放大到 r H × r W rH×rW rH×rW,同时减少通道数。
示例
假设输入特征图的维度是 4 × 2 × 2 4×2×2 4×2×2,我们希望放大2倍,即将分辨率换成 4 × 4 4×4 4×4。Pixel Shuffle操作过程如下:
- 原始特征图: 4 × 2 × 2 4×2×2 4×2×2
- 分解通道数: 4 4 4通道分解为 1 1 1通道的小块,即 1 × 2 × 2 × 2 × 2 1×2×2×2×2 1×2×2×2×2
- 重排特征图:重排为 1 × 4 × 4 1×4×4 1×4×4的特征图。
这个过程相当于将每个通道中的像素块分配到更大的空间位置,从而实现高效的上采样操作。
代码示例
在PyTorch中,我们可以使用torch.nn.PixelShuffle来实现。以下是一个代码示例,展示如何在PyTorch中应用Pixel Shuffle。
python">import torch
import torch.nn as nn# 创建一个示例张量
x = torch.randn(1, 4, 2, 2) # 输入形状 (batch, channels, height, width)# Pixel Shuffle 操作,使用上采样因子 2
pixel_shuffle = nn.PixelShuffle(2)
y = pixel_shuffle(x)print(f"输入形状: {x.shape}, 输出形状: {y.shape}")
# 输入形状: torch.Size([1, 4, 2, 2]), 输出形状: torch.Size([1, 1, 4, 4]) 在这段代码,我们创建了一个形状为(1,4,2,2)的示例张量,将其通过Pixel Shuffle转换成形状为(1,1,4,4)的张量。这里的(2)是上采样因子,代表输出空间维度扩大2倍,而通道数被缩小为 2 2 2^2 22倍,即将4个通道转换为更大的空间维度,使得高分辨率图像生成称为可能。通过这种方式,网络可以利用更多的控价信息,生成更高质量的图像。
Pixel Unshuffle的工作原理
Pixel Unshuffle 是 Pixel Shuffle 的逆操作,用于将特征图从较高的空间分辨率下采样到较低的分辨率,将空间维度的高频信息重新映射回通道中。这种操作在编码解码模型(将高分辨率图像重新映射回多通道低分辨率特征图)、图像压缩等任务中非常实用。
假设输入特征图的维度是 C ′ × r H × r W C'×rH×rW C′×rH×rW,我们希望将其下采样至 C × H × W C×H×W C×H×W的特征图。Pixel Unshuffle 的具体操作步骤如下:
- 分解空间维度:将输入特征图的空间维度 r H × r W rH×rW rH×rW 分解为 H × W H×W H×W 和每个位置的小块大小 r × r r×r r×r。
- 增加通道数:将特征图的维度从 C ′ × r H × r W C'×rH×rW C′×rH×rW 变为 C × H × W C×H×W C×H×W,其中 C = C ′ × r 2 C=C'×r^2 C=C′×r2,即原始通道数。
- 重排通道:将空间维度的 r × r r×r r×r 小块重新映射到通道维度中,从而实现特征的压缩。
通过上述步骤,Pixel Unshuffle 将空间信息压缩回通道中,实现了图像特征的有效下采样。
示例
假设输入特征图的维度是 1 × 4 × 4 1×4×4 1×4×4,希望将其下采样到 4 4 4 通道,尺寸为 2 × 2 2×2 2×2。Pixel Unshuffle 的操作过程如下:
- 原始特征图: 1 × 4 × 4 1×4×4 1×4×4
- 分解空间维度:将空间维度 4 × 4 4×4 4×4 分解为 2 × 2 2×2 2×2 和 2 × 2 2×2 2×2的小块
- 增加通道数:将特征图的维度变为 4 × 2 × 2 4×2×2 4×2×2
这个过程相当于将空间中的信息“压缩”到通道中,从而获得较低分辨率但信息密集的特征图。
代码示例
以下代码展示了如何用Pixel Unshuffle恢复特征图
python">import torch
import torch.nn.functional as F# 假设 y (1,1,4,4)是 Pixel Shuffle 的输出
x_reconstructed = F.pixel_unshuffle(y, 2)
print(f"重新构建后的形状: {x_reconstructed.shape}")
# 重新构建后的形状: torch.Size([1, 4, 2, 2])
在这个示例中,pixel_unshuffle将分辨率降回Pixel Shuffle之前的形状,将空间维度信息重映射回通道中,从而实现特征图的压缩。
可视化展示
为了能够更直观地展示Pixel Shuffle的效果,我们可以通过一张实际图片来演示。以下代码将读取一张图片,通过Pixel Shuffle操作后进行对比可视化,方便理解其在上采样中的效果。假设我们读取的图片为

python">import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt# 1. 读取图片并预处理
img_path = 'your_image_path.jpg' # 替换为你的图片路径
image = Image.open(img_path).convert('RGB')# 2. 图像转换为张量,并调整形状以适应 Pixel Shuffle
transform = transforms.Compose([transforms.Resize((8, 8)), # 调整为较小尺寸以便观察transforms.ToTensor()
])img_tensor = transform(image).unsqueeze(0) # 增加 batch 维度# 3. 增加通道以便演示 Pixel Shuffle(例如转为 4 通道)
img_tensor = img_tensor.repeat(1, 4, 1, 1) # 这里将通道数扩展到4# 4. 执行 Pixel Shuffle 操作
pixel_shuffle = nn.PixelShuffle(2)
img_shuffled = pixel_shuffle(img_tensor)# 5. 可视化原图与 Pixel Shuffle 后的图像
fig, axs = plt.subplots(1, 2, figsize=(10, 5))# 原图
axs[0].imshow(transforms.ToPILImage()(img_tensor.squeeze(0)[:3, :, :])) # 只取前3个通道
axs[0].set_title("Original")# Pixel Shuffle 后的图
axs[1].imshow(transforms.ToPILImage()(img_shuffled.squeeze(0)[:3, :, :])) # 只取前3个通道
axs[1].set_title("Pixel Shuffle")plt.show()在这段代码中,我们读取一张图片并将其转换为张量格式,扩展通道数以符合 Pixel Shuffle 的输入要求。通过 Pixel Shuffle 操作,图像的空间分辨率增加,而通道数减少。经过代码处理后的结果为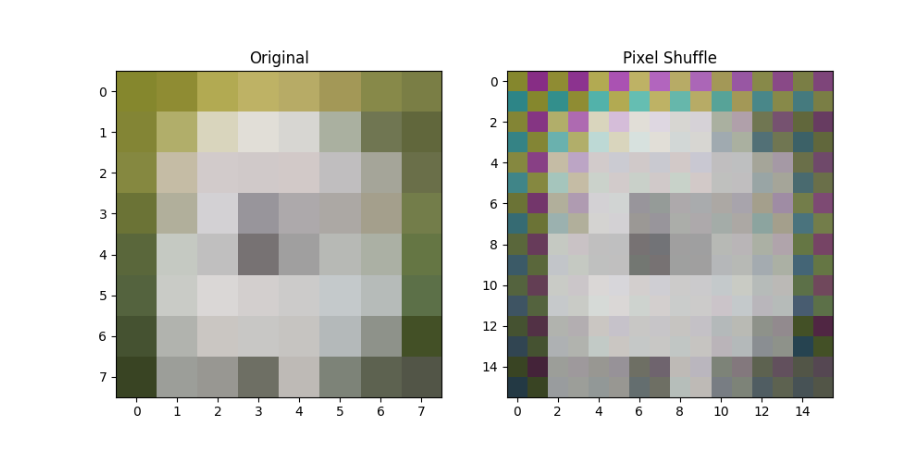
可视化后可以清晰看到,Pixel Shuffle 操作有效地上采样了图片,使其更加细化并且包含更丰富的细节信息。
Pixel Shuffle 与 Pixel Unshuffle 的实际应用
在实际应用中,Pixel Shuffle 常用于超分辨率任务,例如在著名的 EDSR(Enhanced Deep Residual Networks for Single Image Super-Resolution)或 SRGAN(Super-Resolution Generative Adversarial Network)模型中,Pixel Shuffle 是提升图像质量的关键组件之一。Pixel Unshuffle 则适用于特征图压缩和编码场景,帮助模型更高效地处理高维特征。
总结
Pixel Shuffle:用于上采样,将通道维度转换为空间维度,提升图像分辨率。
Pixel Unshuffle:用于下采样,将空间维度转换为通道维度,降低图像分辨率进行特征压缩。
Pixel Shuffle 和 Pixel Unshuffle 通过在通道维度和空间维度之间进行信息重排,使得模型在不引入额外插值误差的情况下,实现高效的上采样和下采样操作。
参考文献
- Shi, Wenzhe, et al. “Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016): 1874-1883.
- Yu, Jiahui, et al. “Wide Activation for Efficient and Accurate Image Super-Resolution.” arXiv preprint arXiv:1808.08718 (2018).
(2016): 1874-1883. - Yu, Jiahui, et al. “Wide Activation for Efficient and Accurate Image Super-Resolution.” arXiv preprint arXiv:1808.08718 (2018).
- Lim, Bee, et al. “Enhanced Deep Residual Networks for Single Image Super-Resolution.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (2017): 136-144.