数组和切片
【1】、数组
1、什么是数组
一组数
-
数组需要是相同类型的数据的集合
-
数组是需要定义大小的
-
数组一旦定义了大小是不可以改变的。
package mainimport "fmt"// 数组
// 数组和其他变量定义没什么区别,唯一的就是这个是一组数,需要给一个大小 [6]int [10]string
// 数组是一个相同类型数据的==有序==集合,通过下标来取出对应的数据
// 数组几个特点:
// 1、长度必须是确定的,如果不确定,就不是数组,大小不可以改变
// 2、元素必须是相,同类型不能多个类型混合, [any也是类型,可以存放任意类型的数据]
// 3、数组的中的元素类型,可以是我们学的所有的类型,int、string、float、bool、array、slice、map
func main() {// 派生数据类型// 数组的定义:【数组大小size】变量的类型 我们定义了一组这个类型的数的集合,大小为size// 默认值是00000var arr1 [5]intarr1[0] = 1arr1[1] = 2arr1[2] = 3arr1[3] = 4arr1[4] = 5fmt.Println(arr1)for i := 0; i < len(arr1); i++ {fmt.Printf("%d\n", arr1[i])}// 数组中的常用方法 len()获取数组的长度 cap() 获取数组的容量fmt.Println("数组的长度:", len(arr1)) // 数组的长度: 5fmt.Println("数组的容量:", cap(arr1)) // 数组的容量: 5// 修改数组的值arr1[1] = 100fmt.Println(arr1)}2、初始化数组
package mainimport "fmt"func main() {// 数组的赋值初始化var arr1 = [5]int{0, 1, 2, 3, 4}fmt.Println(arr1)// 快速赋值arr2 := [5]int{0, 1, 2, 3, 4}fmt.Println(arr2)// 接受用户输入的数据,变为数组// ... 代表数组长度// Go的编译器会自动根据数组的长度来给 ... 赋值,自动推导长度// 注意点:这里的数组不是无限长的,也是固定的大小,大小取决于数组元素个数arr3 := [...]int{0, 1, 2, 3, 4, 5, 5, 5, 6, 7, 8, 9}fmt.Println(len(arr3), arr3)// 数组默认值,只给其中某几个元素赋值var arr4 [10]intfmt.Println(arr4)arr4[6] = 600arr4[5] = 500fmt.Println(arr4)
}3、遍历数组元素
package mainimport "fmt"/*
1、直接通过下标获取元素 arr[index]2、 0-len i++ 可以使用for循环来结合数组下标进行遍历3、for range:范围 (new)
*/
func main() {arr3 := [...]int{0, 1, 2, 3, 4, 5, 5}for i := 0; i < len(arr3); i++ {fmt.Println(arr3[i])}// goland 快捷方式 数组.for,未来循环数组、切片很多时候都使用for range// for 下标,下标对应的值 range 目标数组切片// 就是将数组进行自动迭代。返回两个值 index、value// 注意点,如果只接收一个值,这个时候返回的是数组的下标// 注意点,如果只接收两个值,这个时候返回的是数组的下标和下标对应的值for _, value := range arr3 {fmt.Println("value:", value)}
}4、数组是值类型

package mainimport "fmt"// 数组是值类型: 所有的赋值后的对象修改值后不影响原来的对象。
func main() {arr3 := [...]int{0, 1, 2, 3, 4, 5, 5}arr4 := [...]string{"111", "222"}fmt.Printf("%T\n", arr3)fmt.Printf("%T\n", arr4)arr5 := arr3arr3[6] = 7fmt.Printf("%T\n", arr3)fmt.Println(arr5) // 数组是值传递,拷贝一个新的内存空间
}5、数组排序
arr := [6]int{1,2,3,4,5,0}
// 升序 ASC : 从小到大 0,1,2,3,4,5 A-Z 00:00-24:00
// 降序 DESC : 从大到小 5,4,3,2,1,0// 冒泡排序
package mainimport "fmt"func main() {arr1 := [...]int{1, 2, 3, 4, 5, 0, 77, 95, 11, 23, 54, 88, 33, 10, 23, 19}//var temp int = 0for i := 0; i < len(arr1); i++ {for j := i + 1; j < len(arr1); j++ {if arr1[i] > arr1[j] {arr1[i], arr1[j] = arr1[j], arr1[i]}}}fmt.Println(arr1)
}6、多维数组
一维数组: 线性的,一组数
二维数组: 表格性的,数组套数组
三维数组: 立体空间性的,数组套数组套数组
xxxx维数组:xxx,数组套数组套数组.....
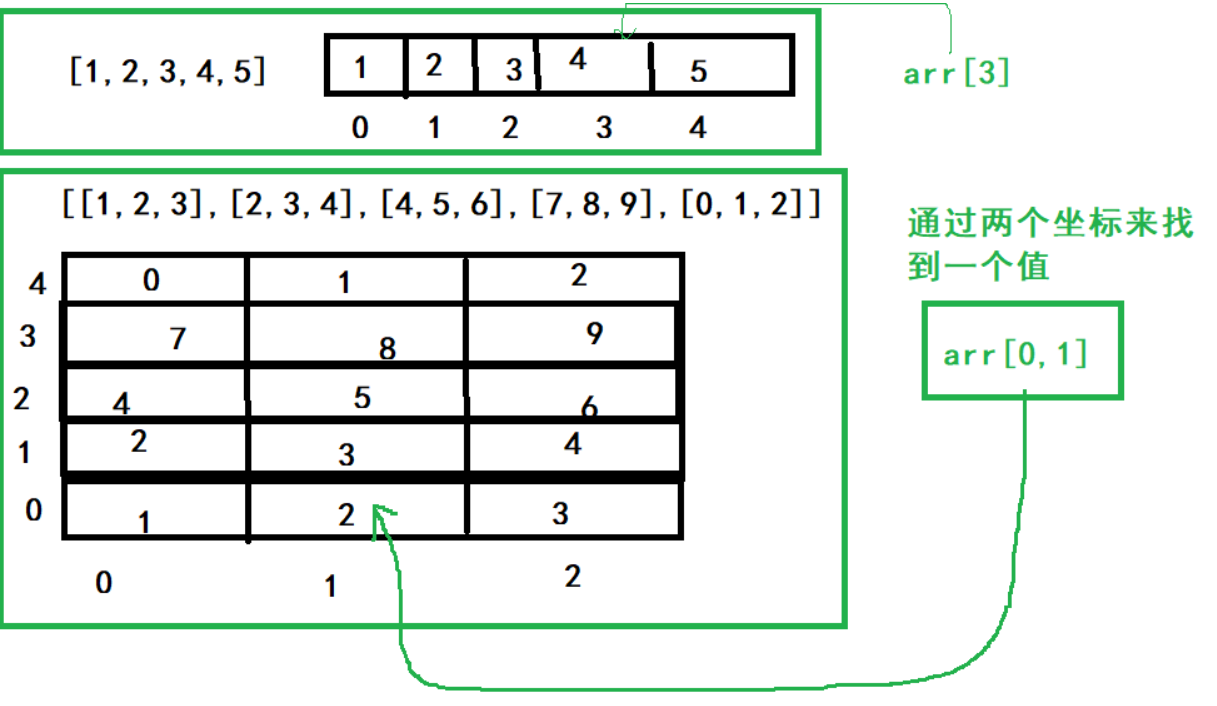
package mainimport "fmt"func main() {// 定义一个多维数组 二维arr := [3][4]int{{0, 1, 2, 3}, // arr[0] //数组{4, 5, 6, 7}, // arr[1]{8, 9, 10, 11}, // arr[2]}// 二维数组,一维数组存放的是一个数组fmt.Println(arr[0])// 要获取这个二维数组中的某个值,找到对应一维数组的坐标,arr[0] 当做一个整体fmt.Println(arr[0][1])fmt.Println("------------------")// 如何遍历二维数组for i := 0; i < len(arr); i++ {for j := 0; j < len(arr[i]); j++ {fmt.Println(arr[i][j])}}// for rangefor i, v := range arr {fmt.Println(i, v)}
}【2】、切片
Go 语言切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型 切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
切片是一种方便、灵活且强大的包装器,切片本身没有任何数据,他们只是对现有数组的引用。
切片与数组相比,不需要设定长度,在[]中不用设定值,相对来说比较自由
从概念上面来说 slice 像一个结构体,这个结构体包含了三个元素:
-
指针:指向数组中 slice 指定的开始位置
-
长度:即slice的长度
-
最大长度:也就是 slice 开始位置到数组的最后位置的长度
1、切片的定义
package mainimport "fmt"func main() {var s1 []int // 变长,长度是可变的fmt.Println(s1)// 切片空的判断,初始化切片中,默认是nilif s1 == nil {fmt.Println("s1是空的")}fmt.Printf("%T\n", s1)s2 := []int{1, 2, 3, 4}fmt.Println(s2[2])}2、make来创建切片
package mainimport "fmt"func main() {// make()// make([]Type,length,capacity) // 创建一个切片,长度,容量s1 := make([]int, 5, 10)fmt.Println(s1)fmt.Println(len(s1), cap(s1))// 思考:容量为10,长度为5,我能存放6个数据吗?s1[0] = 10s1[7] = 200 // index out of range [7] with length 5// 切片的底层还是数组 [0 0 0 0 0] [2000]// 直接去赋值是不行的,不用用惯性思维思考fmt.Println(s1)// 切片扩容}3、切片扩容
package mainimport "fmt"func main() {s1 := make([]int, 0, 5)// 切片扩容,append()s1 = append(s1, 1, 2)fmt.Println(s1)s2 := []int{100, 200, 300, 400}// 切片扩容之引入另一个切片。// slice = append(slice, anotherSlice...)// ... 可变参数 ...xxx// [...] 根据长度变化数组的大小定义// anotherSlice... , slice...解构,可以直接获取到slice中的所有元素s1 = append(s1, s2...)fmt.Println(s1)
}4、遍历切片
package mainimport "fmt"func main() {s1 := make([]int, 0, 5)fmt.Println(s1)// 切片扩容,append()s1 = append(s1, 1, 2)fmt.Println(s1)// 问题:容量只有5个,那能放超过5个的吗? 可以,切片是会自动扩容的。s1 = append(s1, 2, 3, 3, 4, 4, 5, 6, 6, 7, 7)fmt.Println(s1)// 切片扩容之引入另一个切片。// new : 解构 slice.. ,解出这个切片中的所有元素。s2 := []int{100, 200, 300, 400}// slice = append(slice, anotherSlice...)// ... 可变参数 ...xxx// [...] 根据长度变化数组的大小定义// anotherSlice... , slice...解构,可以直接获取到slice中的所有元素// s2... = {100,200,300,400}s1 = append(s1, s2...)// 遍历切片for i := 0; i < len(s1); i++ {fmt.Println(s1[i])}for i := range s1 {fmt.Println(s1[i])}
}5、扩容的内存分析
// 1、每个切片引用了一个底层的数组
// 2、切片本身不存储任何数据,都是底层的数组来存储的,所以修改了切片也就是修改了这个数组中的数据
// 3、向切片中添加数据的时候,如果没有超过容量,直接添加,如果超过了这个容量,就会自动扩容,成倍的增加, copy
// - 分析程序的原理
// - 看源码
//
// 4、切片一旦扩容,就是重新指向一个新的底层数组。
package mainimport "fmt"func main() {s2 := []int{1, 2, 3}fmt.Println(len(s2), cap(s2))fmt.Printf("%p\n", s2)s2 = append(s2, 4, 5)fmt.Println(len(s2), cap(s2))fmt.Printf("%p\n", s2)s2 = append(s2, 4, 5)fmt.Println(len(s2), cap(s2))fmt.Printf("%p\n", s2)s2 = append(s2, 4, 5)fmt.Println(len(s2), cap(s2))fmt.Printf("%p\n", s2)s2 = append(s2, 4, 5)fmt.Println(len(s2), cap(s2))fmt.Printf("%p\n", s2)s2 = append(s2, 4, 5)fmt.Println(len(s2), cap(s2))fmt.Printf("%p\n", s2)s2 = append(s2, 4, 5)fmt.Println(len(s2), cap(s2))fmt.Printf("%p\n", s2)/* 3 30xc0001260785 60xc0001440307 120xc0001020609 120xc00010206011 120xc00010206013 240xc00015200015 240xc000152000*/
}slice扩容的具体实现
主要使用到了make方法和copy方法
package mainimport "fmt"func main() {s2 := []int{1, 2, 3}fmt.Printf("len:%d,cap:%d,%v\n", len(s2), cap(s2), s2)s3 := make([]int, len(s2), cap(s2)*2)copy(s3, s2)fmt.Printf("len:%d,cap:%d,%v\n", len(s3), cap(s3), s3)
}6、使用数组创建切片
package mainimport "fmt"func main() {arr := [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}// 数组的截取// 通过数组创建切片s1 := arr[:5] // 1-5s2 := arr[3:8] // 4-8s3 := arr[5:] // 6-10s4 := arr[:] // 0-10fmt.Println(s1)fmt.Println(s2)fmt.Println(s3)fmt.Println(s4)// 查看容量和长度// 截取后切片的长度就是截取数组的元素个数,切片的容量就是从截取数组的开始位置到数组的最后位置fmt.Printf("s1 len:%d, cap:%d\n", len(s1), cap(s1)) // s1 len:5, cap:10fmt.Printf("s2 len:%d, cap:%d\n", len(s2), cap(s2)) // s2 len:5, cap:7fmt.Printf("s3 len:%d, cap:%d\n", len(s3), cap(s3)) // s3 len:5, cap:5fmt.Printf("s4 len:%d, cap:%d\n", len(s4), cap(s4)) // s4 len:10, cap:10// 切片的内存地址,就是截取数组开始的地址 cap(切片)=len(数组) 他们的内存地址就相同fmt.Printf("%p,%p\n", s1, &arr) // 0xc000016230,0xc000016230fmt.Printf("%p,%p\n", s2, &arr[3]) // 0xc000016248,0xc000016248fmt.Printf("%p,%p\n", s2, &arr[3]) // 0xc000016248,0xc000016248fmt.Printf("%p,%p\n", s3, &arr[5]) // 0xc000016258,0xc000016258fmt.Printf("%p,%p\n", s4, &arr[0]) // 0xc000016230,0xc000016230// 修改数组的内容, 切片也随之发生了变化 (切:切片不保存数据-->底层的数组 )arr[2] = 100fmt.Println(arr) // [1 2 100 4 5 6 7 8 9 10]fmt.Println(s1) // [1 2 100 4 5]fmt.Println(s2) // [4 5 6 7 8]fmt.Println(s3) // [6 7 8 9 10]fmt.Println(s4) // [1 2 100 4 5 6 7 8 9 10]fmt.Println("--------------------------------------------")// 修改切片的内容,发现数组也随之发生了变化。(本质:修改的都是底层的数组)s2[2] = 80fmt.Println(arr) // [1 2 100 4 5 80 7 8 9 10]fmt.Println(s1) // [1 2 100 4 5]fmt.Println(s2) // [4 5 80 7 8]fmt.Println(s3) // [80 7 8 9 10]fmt.Println(s4) // [1 2 100 4 5 80 7 8 9 10]fmt.Println("--------------------------------------------")// 切片扩容,如果容量超过了cap,那么不会影响原数组,因此此时s1指向的是一个新的数组s1 = append(s1, 11, 12, 13, 14, 15, 16)fmt.Println(arr) // [1 2 100 4 5 80 7 8 9 10]fmt.Printf("s1:%p,arr:%p\n", s1, &arr) // s1:0xc0000d4000,arr:0xc0000ac0f0}7、切片:引用类型
package mainimport "fmt"func main() {arr1 := [3]int{1, 2, 3}arr2 := arr1fmt.Println("arr1:", arr1, "arr2:", arr2)fmt.Printf("arr1:%p,arr2:%p\n", &arr1, &arr2) // arr1:0xc0000aa078,arr2:0xc0000aa090arr1[1] = 10fmt.Println("arr1:", arr1, "arr2:", arr2) // [3 4 5] [3 4 5]fmt.Println("---------------------------------")s1 := make([]int, 0, 5)s1 = append(s1, 3, 4, 5)s2 := s1fmt.Println(s1, s2)fmt.Printf("s1:%p,s2:%p\n", s1, s2) //s1:0xc0000c8030,s2:0xc0000c8030s1[1] = 30fmt.Println(s1, s2) // [3 30 5] [3 30 5]
}8、深拷贝、浅拷贝
深拷贝:拷贝是数据的本身
-
值类型的数据,默认都是深拷贝,array、int、float、string、bool、struct....
浅拷贝:拷贝是数据的地址,会导致多个变量指向同一块内存。
-
引用类型的数据: slice、map
-
因为切片是引用类的数据,直接拷贝的是这个地址
切片怎么实现深拷贝 copy
package mainimport "fmt"func main() {// 将原来切片中的数据拷贝到新切片中s1 := []int{1, 2, 3, 4}s2 := make([]int, 0) // len:0 cap:0for i := 0; i < len(s1); i++ {s2 = append(s2, s1[i])}fmt.Println(s1, s2)fmt.Printf("%p,%p\n", s1, s2)s1[2] = 200fmt.Println(s1, s2)
}9、函数中参数传递问题
按照数据的存储特点来分:
-
值类型的数据:操作的是数据本身、int 、string、bool、float64、array...
-
引用类型的数据:操作的是数据的地址 slice、map、chan....
值传递
引用传递
package mainimport "fmt"func main() {// 值传递arr := [3]int{1, 2, 3}fmt.Println(arr)update(arr)fmt.Println(arr)// 引用传递s1 := []int{4, 5, 6}fmt.Println(s1)update_s(s1)fmt.Println(s1)
}func update(arr [3]int) {fmt.Println(arr)arr[1] = 100fmt.Println(arr)
}
func update_s(s1 []int) {fmt.Println(s1)s1[1] = 20fmt.Println(s1)
}文章转载自:Linux小菜鸟
原文链接:https://www.cnblogs.com/xuruizhao/p/18544832
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构


