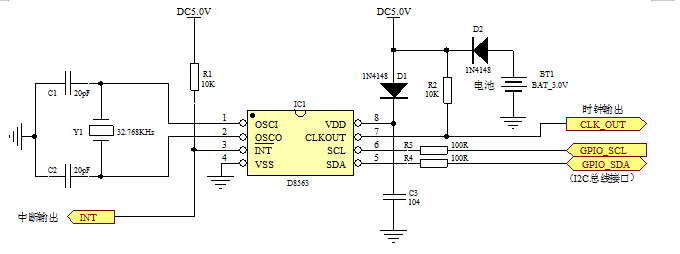
数据来源为sklean.datasets中的load_iris,代码如下:
python"># -*- coding:utf-8 -*-
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 参考:https://blog.csdn.net/weixin_66845445/article/details/138135601
class bayes_iris():def __init__(self):passdef loadData(self):iris = load_iris()dataSet = iris.datatarget = iris.targetX_train,X_test,y_train,y_test = train_test_split(dataSet, target, test_size=0.3,random_state=37)labels = np.array(sorted(list(set(y_train))))return X_train,X_test,y_train,y_test,labels'''分类值有三个,分别计算每个属性在三个分类值下的条件概率'''def cal(self,test,col_index,labels,X,y):result = np.zeros((labels.shape[0],),dtype=np.float64)for index ,label in zip(range(len(labels)), labels):arr = np.array(list(zip(*X[y == label])))[col_index,:]mean = np.mean(arr)std = np.std(arr)result[index] = (1 / (np.sqrt(2 * np.pi)* std)) * np.exp(-1* (((test - mean)**2) / (2 * (std**2))))return resultdef pred(self,X_train,X_test,y_train,labels):countAll = y_train.shape[0]P0 = len(y_train[y_train == 0]) / countAllP1 = len(y_train[y_train == 1]) / countAllP2 = len(y_train[y_train == 2]) / countAllP = np.array([P0,P1,P2]).reshape(3,1)y_pred = np.zeros(X_test.shape[0], dtype=np.int8)for i in range(X_test.shape[0]):# result.shape = (3,4)result = np.zeros((labels.shape[0],X_test.shape[1]), dtype=np.float64)for j in range(X_test.shape[1]):result[:,j] = self.cal(X_test[i,j],j,labels=labels, X=X_train,y=y_train)result = np.concatenate((P,result), axis=1)y_pred[i] = labels[np.argmax(np.prod(result, axis=1))]return y_predif __name__ == '__main__':iris = bayes_iris()X_train,X_test,y_train,y_test,labels = iris.loadData()y_pred = iris.pred(X_train,X_test,y_train,labels)print(accuracy_score(y_test, y_pred=y_pred))
输出结果如下:
1.0
参考:https://blog.csdn.net/weixin_66845445/article/details/138135601