论文速读|LOGO -- Long context aliGnment via efficient preference Optimization
论文信息:

简介:
这篇论文试图解决长上下文模型(Long-context Models, LCMs)在处理长输入序列时的生成性能问题。尽管LCMs在定位上下文中的token级显著信息方面表现出色,但它们在实际任务中的生成性能并不令人满意,可能会产生错位的响应,例如幻觉和不遵循指令。这些问题限制了LCMs在实际长上下文任务中的应用。随着大型语言模型(LLMs)的快速发展,处理长上下文(甚至超过100M tokens)已成为LLMs的基本能力。这不仅为LLMs解锁了新的任务和应用,例如代码分析,同时也消除了以前需要克服上下文长度限制的复杂工具链和繁琐的工作流程。然而,现有的LCMs在长上下文任务中的表现并不理想,这促使研究者寻求更有效的方法来提升这些模型的生成能力。本文介绍了一种名为LOGO(Long cOntext aliGnment via efficient preference Optimization)的训练策略,它是首个引入偏好优化以实现长上下文对齐的方法。
论文方法:
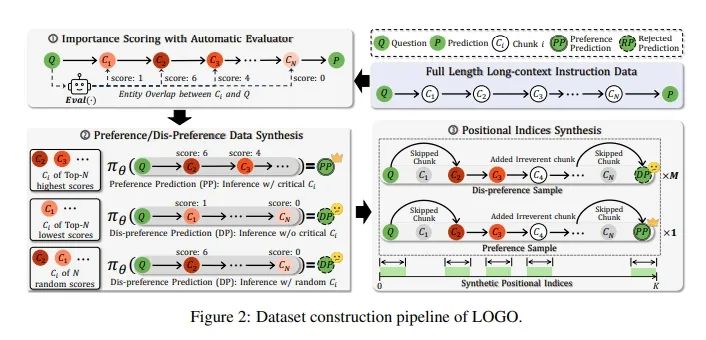
论文设计了一个训练目标,旨在引导LCMs区分偏好预测(即正确的输出)和非偏好预测(例如幻觉等错位输出)。这个目标是基于直接偏好优化(Direct Preference Optimization, DPO)和简单偏好优化(Simple Preference Optimization, SimPO)改进而来,它通过最大化偏好响应的对数似然来训练模型,同时最小化非偏好响应的对数似然。提出了一个与训练目标相匹配的数据构建流程,该流程仅涉及开源模型。为了提高训练效率并克服长序列数据引起的GPU内存限制,LOGO采用了无参考训练目标和位置索引合成方法。具体来说,LOGO通过以下步骤构建训练数据:1)将上下文分割成等长块,并使用自动评估器为每个块分配重要性得分。2)根据模型预测生成偏好和非偏好数据。3)通过为每个块分配不同的合成位置索引来模拟长序列输入,而不需要改变实际输入序列。
论文实验:
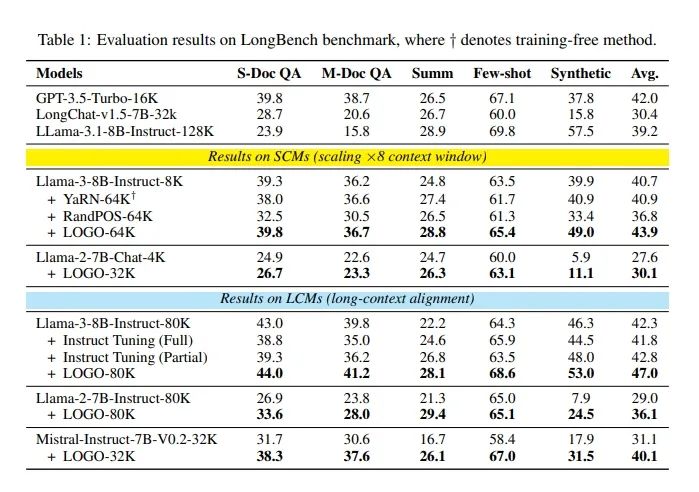
根据Table 1,本文的实验主要围绕评估LOGO训练策略在长上下文任务中的性能。实验涉及了多个不同的模型和训练方法,包括长上下文模型(LCMs)和短上下文模型(SCMs),以及它们在应用LOGO策略后的性能对比。实验使用了LongBench基准测试套件,该套件包含16个不同的数据集,涵盖6个任务类别:单文档问答(S-Doc QA)、多文档问答(M-Doc QA)、摘要(Summ)、少样本学习(Few-shot)、合成任务(Synthetic)和代码任务(Code)。由于代码测试数据主要涉及大约4000个token的上下文,而训练数据未覆盖此领域,因此实验中排除了代码类别。表中列出了不同模型在LongBench基准测试中的平均得分。例如,GPT-3.5-Turbo-16K模型在所有任务中的平均得分为42.0,而Llama-3.1-8B-Instruct-128K模型的平均得分为39.2。对于短上下文模型(SCMs),LOGO策略能够显著提升模型在长上下文任务中的表现。例如,Llama-3-8B-Instruct-8K模型在应用LOGO后,其在64K上下文长度下的性能从40.7提高到43.9。对于长上下文模型(LCMs),LOGO同样能够提升模型性能。例如,Llama-3-8B-Instruct-80K模型在应用LOGO后,其平均得分从42.3提高到47.0。
论文链接:
https://arxiv.org/abs/2410.18533
原文来自:
NLP论文速读|LOGO: 基于高效偏好优化的长上下文对齐





