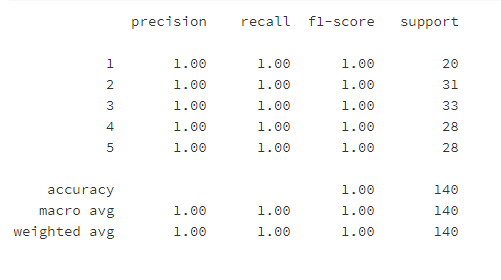
MinIO Enterprise Object Store 是用于创建和执行复杂数据工作流的基础组件。此事件驱动功能的核心是使用 Kafka 的 MinIO 存储桶通知。MinIO Enterprise Object Store 为所有 HTTP 请求(如 PUT、POST、COPY、DELETE、GET、HEAD 和 CompleteMultipartUpload)生成事件通知。您可以使用这些通知来触发相应的应用程序、脚本和 Lambda 函数,以便在对象上传触发事件通知后执行操作。事件通知为多个微服务提供了一个松散耦合的范例,用于交互和协作。在此范例中,微服务不会相互直接调用,而是使用事件通知进行通信。发送通知后,发送服务可以返回到其任务,而接收服务则执行操作。这种级别的隔离使维护代码变得更加容易 — 更改一项服务不需要更改其他服务,因为它们通过通知而不是直接调用进行通信。有几个用例依赖于 MinIO Enterprise Object Store 事件通知来执行数据工作流。例如,我们可以使用将存储在 MinIO Enterprise Object Store 中的对象的原始数据运行 AI/ML 管道。
-
每当添加原始对象时,都会触发处理数据的管道
-
根据添加的对象,模型将运行。
-
最终模型可以保存到 MinIO Enterprise Object Store 中的存储桶中,然后其他应用程序可以将其作为最终产品使用。
构建工作流程
我们将使用 MinIO Enterprise Object Store 和 Kafka 为假设的图像调整器应用程序构建一个示例工作流。它本质上是获取传入的图像并根据某些应用程序规范调整它们的大小,然后将它们保存到另一个可以投放它们的存储桶中。在现实世界中,这可能是为了调整图像大小并使其可供移动应用程序使用,或者只是调整图像大小以减轻动态调整图像大小时对资源的压力。它有几个组件,Kafka 和 MinIO Enterprise Object Store 一起使用来支持这个复杂的工作流程
-
MinIOEnterprise Object Store,创建者:传入的原始对象存储在 MinIO Enterprise Object Store 中。每当添加对象时,它都会向 Kafka 发送消息以代理特定主题。
-
Kafka,代理:代理维护队列的状态,存储传入消息,并使其可供使用者使用。
-
MinIO Enterprise Object Store,使用者:使用者将在队列中读取此消息,因为它们实时进入,处理原始数据,并将其上传到 MinIO Enterprise Object Store 存储桶。
MinIO Enterprise Object Store 是这一切的基础,因为它是此工作流的生产者和使用者。
使用 Kubernetes 集群
我们需要一个 Kubernetes 集群来运行我们的服务。您可以使用任何 Kubernetes 集群,但在此示例中,我们将使用 kind 集群。如果尚未安装 Kind,请按照此快速入门指南中的说明进行操作。使用以下类型的集群配置来构建具有多工作线程 Kubernetes 集群的简单单个 master。将此 yaml 保存为 kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
- role: worker启动集群(这可能需要几分钟时间)
$ kind create cluster --name minio-kafka --config kind-config.yaml… [truncated]Set kubectl context to "kind-minio-kafka"
You can now use your cluster with:kubectl cluster-info --context kind-minio-kafka… [truncated]验证集群是否已启动
$ kubectl get no
NAME STATUS ROLES AGE VERSION
minio-kafka-control-plane Ready control-plane 43s v1.24.0
minio-kafka-worker Ready <none> 21s v1.24.0
minio-kafka-worker2 Ready <none> 21s v1.24.0
minio-kafka-worker3 Ready <none> 21s v1.24.0安装 Kafka
Kafka 需要运行一些服务来支持它,然后才能运行。这些服务是:
-
证书
-
动物园管理员
让我们在 Kubernetes 集群中安装 cert-manager
$ kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.6.2/cert-manager.yaml检查状态以验证是否已创建 cert-manager 资源
$ kubectl get ns
NAME STATUS AGE
cert-manager Active 6s
default Active 20m
kube-node-lease Active 20m
kube-public Active 20m
kube-system Active 20m
local-path-storage Active 20m$ kubectl get po -n cert-manager
NAME READY STATUS RESTARTS AGE
cert-manager-74f9fd7fb6-kqhsq 1/1 Running 0 14s
cert-manager-cainjector-67977b8fcc-k49gj 1/1 Running 0 14s
cert-manager-webhook-7ff8d87f4-wg94l 1/1 Running 0 14s使用 Helm 图表安装 zookeeper。如果您尚未安装 helm,可以按照 helm 文档中的安装指南进行操作。
$ helm repo add pravega https://charts.pravega.io
"pravega" has been added to your repositories$ helm repo update$ helm install zookeeper-operator --namespace=zookeeper --create-namespace pravega/zookeeper-operator… [truncated]$ kubectl --namespace zookeeper create -f - <<EOF
apiVersion: zookeeper.pravega.io/v1beta1
kind: ZookeeperCluster
metadata:name: zookeepernamespace: zookeeper
spec:replicas: 1
EOF您应该会看到与此类似的输出,这意味着集群创建正在进行中。
zookeepercluster.zookeeper.pravega.io/zookeeper created
验证 zookeeper 操作员和集群 Pod 是否都在运行
$ kubectl -n zookeeper get po
NAME READY STATUS RESTARTS AGE
zookeeper-0 1/1 Running 0 31s
zookeeper-operator-5857967dcc-kfxxt 1/1 Running 0 3m4s现在我们已经解决了所有先决条件,让我们安装实际的 Kafka 集群组件。Kafka 有一个名为 Koperator 的 Operator,我们将使用它来管理 Kafka 安装。Kafka 集群大约需要 4-5 分钟才能启动。
$ kubectl create --validate=false -f https://github.com/banzaicloud/koperator/releases/download/v0.21.2/kafka-operator.crds.yaml$ helm repo add banzaicloud-stable https://kubernetes-charts.banzaicloud.com/$ helm repo update
… [truncated]$ helm install kafka-operator --namespace=kafka --create-namespace banzaicloud-stable/kafka-operator… [truncated]$ kubectl create -n kafka -f https://raw.githubusercontent.com/banzaicloud/koperator/master/config/samples/simplekafkacluster.yaml执行 kubectl -n kafka get po 确认 Kafka 已启动。Kafka 需要几分钟时间才能运行。请稍候,然后再继续。
配置 Kafka 主题
让我们先配置 Topic,然后再在 MinIO 中配置它;该主题是先决条件。
创建名为 my-topic 的主题
$ kubectl apply -n kafka -f - <<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:name: my-topic
spec:clusterRef:name: kafkaname: my-topicpartitions: 1replicationFactor: 1config:"retention.ms": "604800000""cleanup.policy": "delete"
EOF它应返回以下输出。否则,主题创建不成功。如果不成功,请等待几分钟,让 Kafka 集群联机,然后再次重新运行它。
kafkatopic.kafka.banzaicloud.io/my-topic created
在接下来的几个步骤中,我们需要一个 Kafka Pod 的 IP 和端口
要获取 IP,请执行以下操作:
$ kubectl -n kafka describe po kafka-0- | grep -i IP:
IP: 10.244.1.5IP: 10.244.1.5注意:您的 IP 会有所不同,并且可能与上述 IP 不匹配。我们感兴趣的是几个端口
$ kubectl -n kafka get po kafka-0- -o yaml | grep -iA1 containerport- containerPort: 29092name: tcp-internal
--- containerPort: 29093name: tcp-controller… [truncated]-
tcp-internal 29092:当您作为使用者处理传入到 Kafka 集群的消息时,使用此端口。
-
tcp-controller 29093:这是当生产者(如 MinIO)想要向 Kafka 集群发送消息时使用的端口。
这些 IP 和端口可能会在您自己的设置中发生变化,因此请务必为您的集群获取正确的值。
安装 MinIO
我们将 MinIO 安装在与其他资源相同的 Kubernetes 集群中其自己的命名空间中。获取 MinIO 存储库
$ git clone https://github.com/minio/operator.git
应用资源以安装 MinIO
$ kubectl apply -k operator/resources$ kubectl apply -k operator/examples/kustomization/tenant-lite验证 MinIO 是否已启动并正在运行。您可以获取 MinIO 控制台的端口,在本例中为 9443。
$ kubectl -n tenant-lite get svc | grep -i consolestorage-lite-console ClusterIP 10.96.0.215 <none> 9443/TCP 6m53s
设置 kubernetes 端口转发:我们在这里为主机选择了端口 39443,但这可以是任何东西,只需确保在通过 Web 浏览器访问控制台时使用相同的端口。
$ kubectl -n tenant-lite port-forward svc/storage-lite-console 39443:9443Forwarding from 127.0.0.1:39443 -> 9443Forwarding from [::1]:39443 -> 9443
使用以下凭证通过 Web 浏览器访问
网址:https://localhost:39443
用户: minio
通行证: minio123
配置 MinIO 生产者
我们将配置 MinIO 以将事件发送到我们之前使用 mc 管理工具创建的 Kafka 集群中的 my-topic。我在这里启动了一个 Ubuntu Pod,这样我就有一个干净的工作区可以工作,更重要的是,我可以访问集群中的所有 Pod,而无需将每个单独的服务端口转发。
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:name: ubuntulabels:app: ubuntu
spec:containers:- image: ubuntucommand:- "sleep"- "604800"imagePullPolicy: IfNotPresentname: ubunturestartPolicy: Always
EOFshell 放入 Ubuntu Pod 中,以确保其已启动
$ kubectl exec -it ubuntu -- /bin/bashroot@ubuntu:/#如果您看到任何前缀为 root@ubuntu:/ 的命令,则表示它正在此 ubuntu pod 中运行。使用以下命令获取 mc 二进制文件并安装
root@ubuntu:/# apt-get update
apt-get -y install wget
wget https://dl.min.io/client/mc/release/linux-amd64/mc
chmod +x mc
mv mc /usr/local/bin/
验证是否已正确安装
root@ubuntu:/# mc --versionmc version RELEASE.2022-08-05T08-01-28Z (commit-id=351d021b924b4d19f1eb716b9e2bd74644c402d8)Runtime: go1.18.5 linux/amd64Copyright (c) 2015-2022 MinIO, Inc.License GNU AGPLv3 <https://www.gnu.org/licenses/agpl-3.0.html>
配置 mc admin 以使用我们的 MinIO 集群
- mc alias set <alias_name> <minio_tenant_url> <minio_username> <minio_password>
在我们的例子中,这将转化为
root@ubuntu:/# mc alias set myminio https://minio.tenant-lite.svc.cluster.local minio minio123Added `myminio` successfully.
通过运行以下命令验证配置是否按预期工作;您应该会看到类似于 8 drives online, 0 drives offline
root@ubuntu:/# mc admin info myminio… [truncated]Pools:1st, Erasure sets: 1, Disks per erasure set: 88 drives online, 0 drives offline
通过 mc admin 在 MinIO 中设置 Kafka 配置。您需要使用
root@ubuntu:/# mc admin config set myminio \
notify_kafka:1 \
brokers="10.244.1.5:29093" \
topic="my-topic" \
tls_skip_verify="off" \
queue_dir="" \
queue_limit="0" \
sasl="off" \
sasl_password="" \
sasl_username="" \
tls_client_auth="0" \
tls="off" \
client_tls_cert="" \
client_tls_key="" \
version="" --insecure您必须特别注意其中一些配置
-
brokers=“10.244.1.5:29093”:这些是格式 server1:port1,server2:port2,serverN:portN 为 .注意:如果你决定提供多个 Kafka 服务器,你需要提供所有服务器的 IP;如果你给出一个部分列表,它将失败。你可以提供单个服务器,但缺点是如果该服务器宕机,则配置将不知道集群中的其他 Kafka 服务器。正如我们之前提到的,有两个端口:TCP 内部 29092 和 TCP 控制器 29093。由于我们将 MinIO 配置为 Producer,因此我们将使用 29093。
-
topic=“my-topic”:主题名称应与我们之前在 Kafka 集群中创建的主题匹配。提醒一下,MinIO 不会自动创建此主题;它必须事先可用。
-
notify_kafka:1:这是稍后将用于实际添加事件的配置名称。
有关这些参数的更多详细信息,请访问我们的文档。成功后,您应该会看到下面的输出
Successfully applied new settings.
根据需要,让我们重新启动 admin 服务
root@ubuntu:/# mc admin service restart myminioRestart command successfully sent to `myminio`. Type Ctrl-C to quit or wait to follow the status of the restart process.....Restarted `myminio` successfully in 2 seconds
在 MinIO 中创建一个名为 images 的存储桶。这是 Raw 对象将存储的位置。
root@ubuntu:/# mc mb myminio/images --insecureBucket created successfully `myminio/images`.
我们希望将发送到队列的消息限制为仅.jpg图像;这可以根据需要进行扩展,例如,如果要将消息设置为基于其他文件扩展名(如 .png)触发。
root@ubuntu:/# mc event add myminio/images arn:minio:sqs::1:kafka --suffix .jpgSuccessfully added arn:minio:sqs::1:kafka# Verify it has been added properly
root@ubuntu:/# mc event list myminio/imagesarn:minio:sqs::1:kafka s3:ObjectCreated:*,s3:ObjectRemoved:*,s3:ObjectAccessed:* Filter: suffix=".jpg"
有关如何使用 MinIO 配置 Kafka 的更多详细信息,请访问我们的文档。
构建 MinIO 使用者
如果我们真的有一个脚本,可以使用由 MinIO 生成的这些事件并对这些对象执行一些操作,那就太酷了。那么为什么不这样做呢?这样,我们就可以全面了解工作流程。在仍然登录到我们的 ubuntu pod 时,安装 python3 和 python3-pip 以运行我们的脚本。由于这是 Ubuntu 的最小版本,我们还需要 vim 来编辑我们的脚本。
root@ubuntu:/# apt-get -y install python3 python3-pip vim
对于我们的 Python 使用者脚本,我们需要通过 pip 安装一些 Python 包
root@ubuntu:/# pip3 install minio kafka-pythonCollecting minioDownloading minio-7.1.11-py3-none-any.whl (76 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 76.1/76.1 KB 4.1 MB/s eta 0:00:00Collecting kafka-pythonDownloading kafka_python-2.0.2-py2.py3-none-any.whl (246 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 246.5/246.5 KB 8.6 MB/s eta 0:00:00Collecting certifiDownloading certifi-2022.6.15-py3-none-any.whl (160 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 160.2/160.2 KB 11.6 MB/s eta 0:00:00Collecting urllib3Downloading urllib3-1.26.11-py2.py3-none-any.whl (139 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 139.9/139.9 KB 18.4 MB/s eta 0:00:00Installing collected packages: kafka-python, urllib3, certifi, minioSuccessfully installed certifi-2022.6.15 kafka-python-2.0.2 minio-7.1.11 urllib3-1.26.11如果您看到上述消息,则表示我们已成功安装脚本所需的依赖项。我们将在此处显示整个脚本,然后引导您了解正在运行的不同组件。现在,将此脚本另存为 minio_consumer.py
from minio import Minio
import urllib3from kafka import KafkaConsumer
import json# Convenient dict for basic config
config = {"dest_bucket": "processed", # This will be auto created"minio_endpoint": "minio.tenant-lite.svc.cluster.local","minio_username": "minio","minio_password": "minio123","kafka_servers": "10.244.1.5:29092","kafka_topic": "my-topic", # This needs to be created manually
}# Since we are using self-signed certs we need to disable TLS verification
http_client = urllib3.PoolManager(cert_reqs='CERT_NONE')
urllib3.disable_warnings()# Initialize MinIO client
minio_client = Minio(config["minio_endpoint"],secure=True,access_key=config["minio_username"],secret_key=config["minio_password"],http_client = http_client)# Create destination bucket if it does not exist
if not minio_client.bucket_exists(config["dest_bucket"]):minio_client.make_bucket(config["dest_bucket"])print("Destination Bucket '%s' has been created" % (config["dest_bucket"]))# Initialize Kafka consumer
consumer = KafkaConsumer(bootstrap_servers=config["kafka_servers"],value_deserializer = lambda v: json.loads(v.decode('ascii'))
)consumer.subscribe(topics=config["kafka_topic"])try:print("Ctrl+C to stop Consumer\n")for message in consumer:message_from_topic = message.valuerequest_type = message_from_topic["EventName"]bucket_name, object_path = message_from_topic["Key"].split("/", 1)# Only process the request if a new object is created via PUTif request_type == "s3:ObjectCreated:Put":minio_client.fget_object(bucket_name, object_path, object_path)print("- Doing some pseudo image resizing or ML processing on %s" % object_path)minio_client.fput_object(config["dest_bucket"], object_path, object_path)print("- Uploaded processed object '%s' to Destination Bucket '%s'" % (object_path, config["dest_bucket"]))except KeyboardInterrupt:print("\nConsumer stopped.")- 我们将导入在此过程中之前安装的 pip 包
from minio import Minio
import urllib3from kafka import KafkaConsumer
import json- 我们不是每次都修改代码中的参数,而是在这个 config dict 中展示了一些常见的可配置参数。
config = {"dest_bucket": "processed", # This will be auto created"minio_endpoint": "minio.tenant-lite.svc.cluster.local","minio_username": "minio","minio_password": "minio123","kafka_servers": "10.244.1.5:29092","kafka_topic": "my-topic", # This needs to be created manually- 我们启动的 MinIO 集群正在使用自签名证书。尝试连接时,我们需要确保它接受自签名证书。
http_client = urllib3.PoolManager(cert_reqs='CERT_NONE')
urllib3.disable_warnings()
- 我们将检查用于存储已处理数据的目标存储桶是否存在;如果没有,那么我们将继续创建一个。
if not minio_client.bucket_exists(config["dest_bucket"]):minio_client.make_bucket(config["dest_bucket"])print("Destination Bucket '%s' has been created" % (config["dest_bucket"]))
- 配置要连接的 Kafka 代理以及要订阅的主题
consumer = KafkaConsumer(bootstrap_servers=config["kafka_servers"],value_deserializer = lambda v: json.loads(v.decode('ascii'))
)consumer.subscribe(topics=config["kafka_topic"])
- 当您停止使用者时,它通常会吐出堆栈跟踪,因为使用者应该永远运行使用消息。这将使我们能够干净地退出消费者
try:print("Ctrl+C to stop Consumer\n")… [truncated]except KeyboardInterrupt:print("\nConsumer stopped.")如前所述,我们将持续等待,听取有关该主题的新消息。一旦我们得到一个主题,我们就会将其分解为三个部分
-
request_type:HTTP 请求的类型:GET、PUT、HEAD
-
bucket_name:添加新对象的存储桶的名称
-
object_path:存储桶中添加对象的对象的完整路径
for message in consumer:message_from_topic = message.valuerequest_type = message_from_topic["EventName"]bucket_name, object_path = message_from_topic["Key"].split("/", 1)
- 每次您提出任何请求时,MinIO 都会向主题添加一条消息,该消息将由我们的 minio_consumer.py 脚本读取。因此,为了避免无限循环,我们只在添加新对象时进行处理,在本例中为请求类型 PUT。
if request_type == "s3:ObjectCreated:Put":minio_client.fget_object(bucket_name, object_path, object_path)- 您可以在此处添加客户代码来构建 ML 模型、调整图像大小和处理 ETL/ELT 作业。
print("- Doing some pseudo image resizing or ML processing on %s" % object_path)- 处理完对象后,它将被上传到我们之前配置的目标存储桶。如果存储桶不存在,我们的脚本将自动创建它。
minio_client.fput_object(config["dest_bucket"], object_path, object_path)print("- Uploaded processed object '%s' to Destination Bucket '%s'" % (object_path, config["dest_bucket"]))你有它。除了一些样板代码之外,我们基本上在做两件事:
-
侦听有关 Kafka 主题的消息
-
将对象放入 MinIO 存储桶
该脚本并不完美 — 您需要添加一些额外的错误处理,但它非常简单。其余部分您可以使用自己的代码库进行修改。有关更多详细信息,请访问我们的 MinIO Python SDK 文档。
使用 MinIO 事件
我们已经构建了它,现在让我们看看它的实际效果。创建两个终端:
-
终端 1 (T1):minio_consumer.py 运行的 Ubuntu Pod
-
终端 2 (T2):带有 mc 的 Ubuntu Pod。
打开 T1 并运行我们之前使用 python3 编写的 minio_consumer.py 脚本。如果任何时候要退出脚本,可以键入 Ctrl+C
root@ubuntu:/# python3 minio_consumer.pyCtrl+C to stop Consumer
现在让我们打开 T2 并将一些对象 PUT 到我们之前使用 mc 创建的 MinIO 图像存储桶中。首先创建一个测试对象
root@ubuntu:/# touch rose.jpg
root@ubuntu:/# echo "a" > rose.jpg
将测试对象上传到 images 存储桶的几个不同路径
root@ubuntu:/# mc cp rose.jpg myminio/images --insecure/rose.jpg: 2 B / 2 B ┃▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓┃ 55 B/s 0sroot@ubuntu:/# mc cp rose.jpg myminio/images/deeper/path/rose.jpg --insecure/rose.jpg: 2 B / 2 B ┃▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓┃ 63 B/s 0s在运行 MinIO 使用者脚本的另一个终端 T1 中,您应该会看到一些类似于下面的消息
root@ubuntu:/# python3 minio_consumer.py… [truncated]- Doing some pseudo image resizing or ML processing on rose.jpg- Uploaded processed object 'rose.jpg' to Destination Bucket 'processed'- Doing some pseudo image resizing or ML processing on deeper/path/rose.jpg- Uploaded processed object 'deeper/path/rose.jpg' to Destination Bucket 'processed'
我们还应该验证已处理的对象是否已上传到已处理的存储桶
root@ubuntu:/# mc ls myminio/processed[2022-08-12 01:03:46 UTC] 2B STANDARD rose.jpgroot@ubuntu:/# mc ls myminio/processed/deeper/path[2022-08-12 01:09:04 UTC] 2B STANDARD rose.jpg
如您所见,我们已成功将对象从未处理的原始数据上传到已处理的存储桶。
使用通知在 MinIO Enterprise Object Store 上构建工作流
我们在这里展示的只是您可以通过此工作流程实现的目标的一个示例。通过利用 Kafka 的持久消息传递和 MinIO Enterprise Object Store 的弹性存储,您可以构建复杂的 AI 应用程序,这些应用程序由可以扩展并跟上工作负载的基础设施提供支持,例如:
-
机器学习模型
-
图像大小调整
-
处理 ETL / ELT 作业