侯捷 | C++ | 内存管理 | 学习笔记(一)
第一章节 primitives
重点:技术的演进
new delete针对一个对象->static alloctor针对一个类->globa allocator针对一个标准库,里面有16个链表(static alloctor只有一个链表)
本部分介绍到static alloctor
文章目录
- 侯捷 | C++ | 内存管理 | 学习笔记(一)
- 第一章节 primitives
- 零.new和delete概述
- `new`的底层机制和工作原理
- `delete`的底层机制和工作原理
- 注意事项
- 一、new()和delete()
- 1. new()
- 2.delete()
- 3.new[ ]和delete[ ]
- 4.placement new(定位new)
- 一、定义与原理
- 二、使用方法
- 三、注意事项
- 四、示例
- 二、重载
- 1.new()和delete()
- 2.allocator()和deallocator()
- 3.new_handler
零.new和delete概述
C++中的new和delete是用于动态内存分配和释放的操作符,它们的底层机制和工作原理相对复杂,但也可以简单清晰地解释。
new的底层机制和工作原理
- 内存分配:
- 当使用
new操作符时,它首先会调用底层的内存分配函数(如operator new),这个函数通常是对malloc的封装。malloc会从堆中分配足够的内存空间。 - 如果内存分配失败,
operator new会抛出一个std::bad_alloc异常,而不是像malloc那样返回NULL。
- 当使用
- 对象构造:
- 内存分配成功后,
new会调用对象的构造函数来初始化分配的内存区域。对于内置类型(如int、char等),这一步可能只是简单地设置值;而对于自定义类型,则会调用其构造函数。
- 内存分配成功后,
- 返回指针:
- 最后,
new返回一个指向已分配并初始化对象的指针。
- 最后,
delete的底层机制和工作原理
- 对象析构:
- 当使用
delete操作符时,它首先会调用对象的析构函数来清理对象中的资源。这一步对于自定义类型尤其重要,因为析构函数通常包含释放动态分配资源(如内存、文件句柄等)的代码。
- 当使用
- 内存释放:
- 析构函数调用完成后,
delete会调用底层的内存释放函数(如operator delete),这个函数通常是对free的封装。free会将之前分配的内存空间归还给堆管理器。
- 析构函数调用完成后,
- 指针置空(可选):
- 虽然
delete本身不会将指针置为空(nullptr),但这是一个良好的编程习惯。在释放内存后,将指针置为空可以避免悬空指针(dangling pointer)问题,即指针仍然指向已释放的内存区域。
- 虽然
注意事项
- 匹配使用:确保使用
new分配的内存使用delete释放,使用new[]分配的内存使用delete[]释放。不匹配使用会导致未定义行为。 - 不要重复释放:不要对同一个内存块调用
delete(或delete[])多次。 - 避免使用已释放的内存:一旦内存被
delete释放,就不要再尝试访问它。
在C++内存分配当中分为四个阶层:
1.调用容器
2.使用new关键词
3.直接调用malloc和free
4.调用与系统绑定的内存分配函数
这四个阶层有层层包含的关系:
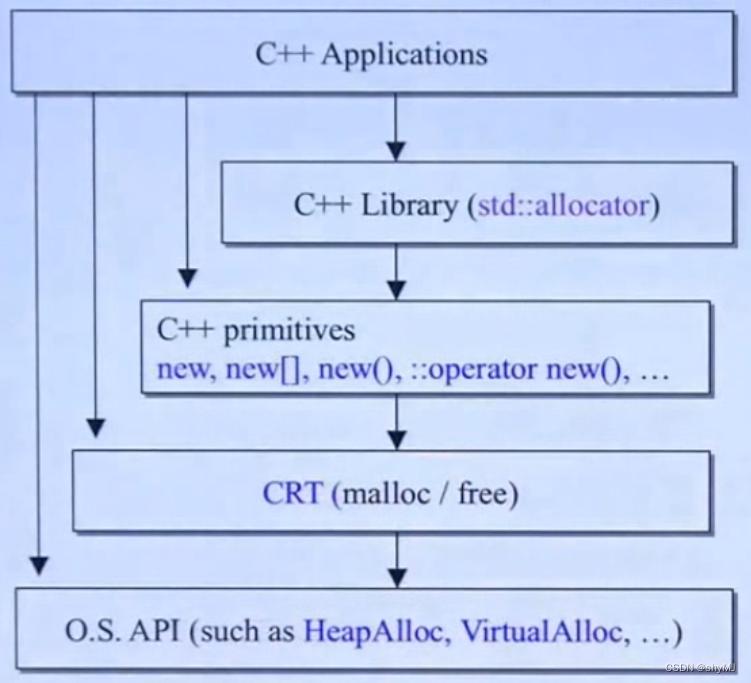
从::operateor new()开始,可以进行重载。同理,delete也可以进行重载。
new会调用operator new,然后operator new调用malloc进行内存分配
在第四个,你可以自己设计一个分配器搭配一个容器。

一、new()和delete()
1. new()
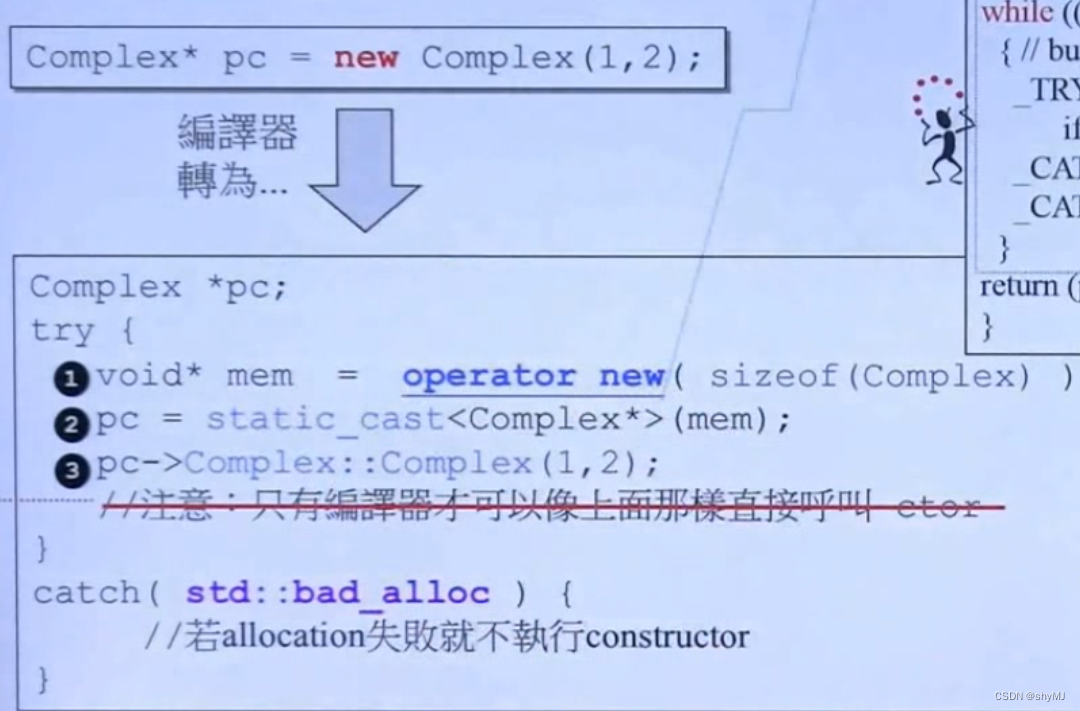
new关键词相当于进行两个步骤:
1.调用operator new,分配所创建对象需要的内存(其内部就是对malloc()的封装)
2.调用对象的构造函数
如果某个步骤发生错误,则抛出异常。
注意:在一些版本中,只有编译器可以直接调用构造函数,如果在程序中自己调用则会出错。
A* pA = new A(1);//正确pA->A::A(3);//错误A::A(5);//错误
2.delete()

相应的,delete关键词也相当于两个步骤:
1.先对需要delete的对象进行析构,调用其析构函数
2.再释放该对象所使用的内存空间(内部是封装了free()函数)
3.new[ ]和delete[ ]

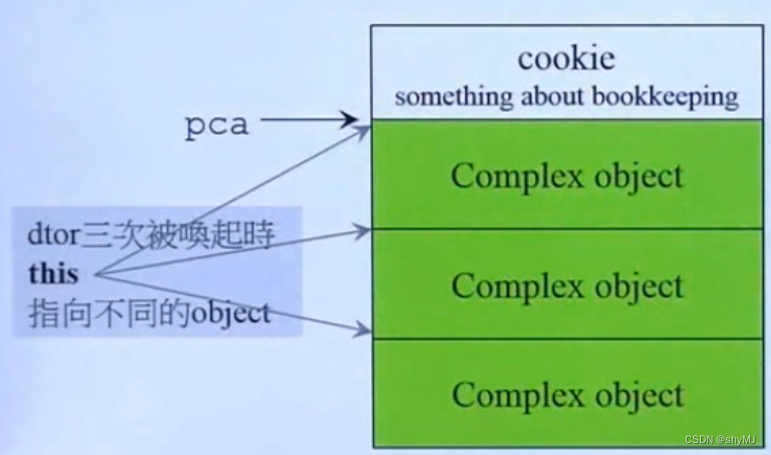
使用new[ ]时,顺序分配对象所需空间,指针指向第一个内存空间,但不调用构造函数进行初始化(如果对象内不包含指针成员则无影响,包含则有影响),后续可以通过指针对各个对象进行初始化。同时在空间开头会有一个cookie,记录了这个空间共有几个对象。
使用delete[ ]时会读取cookie,倒序析构对象,并释放对应的空间;如果直接使用delete则不会读取cookie,会导致空间错位,程序报错,所以new[ ]必须要跟delet[]对应。
4.placement new(定位new)
定位new(Placement new)是C++中的一个高级特性,它允许在已分配的内存上构造对象,而不会进行新的内存分配。以下是对定位new的详细解释:
一、定义与原理
- 定义:定位new就是在已分配好的内存空间中调用构造函数对象进行初始化。它不会申请新的内存空间,而是利用已经分配好的空间来构造对象。
- 原理:使用定位new时,程序员需要指定一个已经分配好的内存区域,然后在这个区域中调用对象的构造函数来构造对象。由于对象的空间是预先分配好的,因此定位new不会进行额外的内存分配操作。
二、使用方法
定位new的使用语法通常如下:
cpp复制代码new (placement_address) type (initializer_list);
placement_address:这是一个指向已分配内存的指针,表示对象将要被构造的位置。type:这是要构造的对象的类型。initializer_list:这是传递给对象构造函数的初始化列表(可选)。
例如,假设有一个已经分配好的内存区域mem,并且想要在这个区域中构造一个类型为A的对象,可以使用以下代码:
cpp复制代码A* p = new (mem) A;
此时,指针p和数组名mem指向同一片存储区,对象A将在mem指向的内存区域中被构造。
三、注意事项
- 内存管理:由于定位new不会进行内存分配,因此程序员需要手动管理内存。在对象不再需要时,需要显式地调用析构函数来释放对象占用的内存。
- 对象生命周期:使用定位new构造的对象,其生命周期由程序员负责管理。程序员需要确保在对象不再需要时正确地调用析构函数,以避免内存泄漏和悬空指针等问题。
- 使用场景:定位new通常用于内存池或自定义内存管理等场景,在这些场景中,程序员需要精确地控制内存的使用和对象的构造与析构。
四、示例
以下是一个使用定位new的示例代码:
#include <new> // 包含定位new所需的头文件
#include <iostream> class A {
public: A() { std::cout << "A's constructor called" << std::endl; } ~A() { std::cout << "A's destructor called" << std::endl; }
}; int main() { char mem[sizeof(A)]; // 分配一块足够大的内存区域来存储对象A A* p = new (mem) A; // 在指定的内存区域中构造对象A // ... 使用对象p ... p->~A(); // 显式地调用析构函数来释放对象占用的内存 return 0;
}
在这个示例中,我们首先分配了一块足够大的内存区域mem来存储对象A,然后使用定位new在mem指向的内存区域中构造了一个对象A。最后,我们显式地调用了析构函数来释放对象占用的内存。
综上所述,定位new是C++中的一个高级特性,它允许在已分配的内存上构造对象而不会进行新的内存分配。在使用时需要谨慎处理内存管理和对象生命周期的问题以确保程序的正确性和稳定性。
课程内:

形式就相当于new ( p ) ,是将一块已经分配好了的内存用于构建对象,new则是当场分配一块内存用于构建对象,并没有特定的placement delete。
其中buf是已经分配好的内存
上面第二行这一行会被编译器解释为这三行

1.给一块已经分配好的内存,这一步其实什么都不会做,因为内存已经分配好了
2.转型
3.调用对象的构造函数
其实就相当于调用了一次构造函数
二、重载
1.new()和delete()
new()表达式本身不可重载,表示operator new(),但operator new()可以重载,分为全局和类内,通常重载类内的。
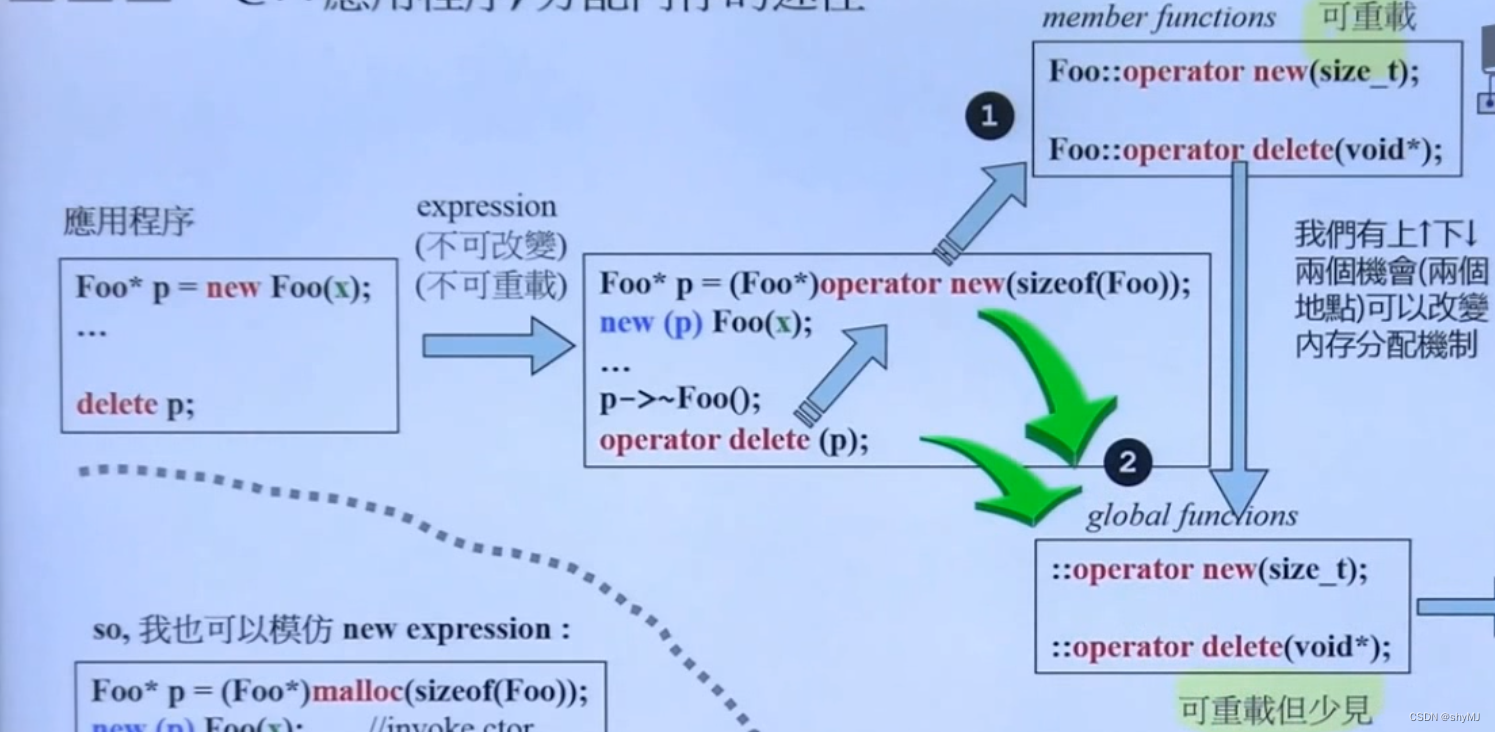
类内对operator new()和operator delete()进行重载,operator new()重载的第一参数必须是size_t,其大小足以保证存储内存中对象的大小,否则将抛出异常。

如果在创建对象时,直接调用new()和delete(),则调用的是类内重载的new()和delete(),是编译器调用的,并且重载的new和delete这两个函数一定得是静态的,因为调用的时候还没有实例对象

如果调用::new()和::delete(),则调用的是全局的new()和delete()

注意:
这里说的是placement operator delete不是operator delete
前者是下图说的抛异常的时候用,后者是和operator new配对的

很好的例子:
这是我们平常用的string,它的new会多出来一个extra,所以要重载
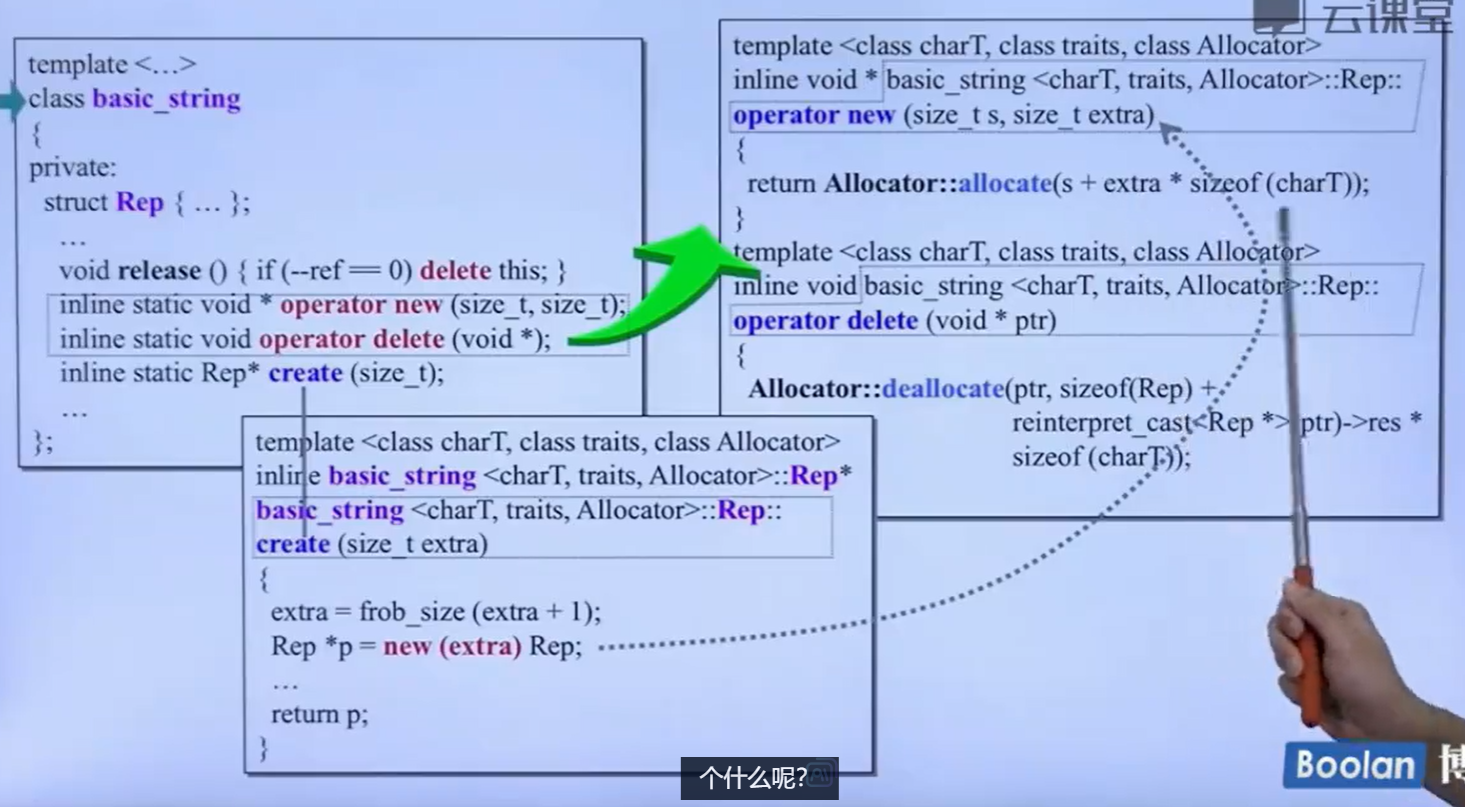
重载全局的operator new和operator delete的接口的格式
new一定要写参数size,delete写ptr指针,而size可写可不写是一个选项

2.allocator()和deallocator()
进行类内operator new()和operator delete()的重载,主要是为了减少::operator new()和::operator delete()的调用。因为::operator new()是对malloc()适配,每调用一次malloc(),就会产生头尾两个cookie共8个字节,既造成了空间浪费,速度上也更慢。
但对每一个不同的类进行重载,并且每次重载的内容都差不多,会造成大量重复劳动,会有很多的重复代码,所以设计一个概念把之前重载中共同的部分抽象出来,作为一个类来使用,即为allocator()和deallocator()。
设计一个allocator的类,在类里面定义allocator()和deallocator()。allocator()使用内存池模式,每次申请一大块内存,然后将这块内存切割小块,大小等同于对象的大小,并串成一个链表。这样只有在申请一大块内存的时候会调用malloc(),生成两个cookie,创建对象时不使用malloc(),而是从链表中取出一块分给对象,调用deallocator()也不将释放的内存free()给系统,而且将这块内存重新插入链表顶端。
重载operator new和delete的版本

测试结果会有cookie的空间占用
现在这样就不需要上面又是struct又是union的

static allocator(用allocator的版本)
对象需要重载new和delete时,直接在类内创建一个allocator对象,调用allocator的类方法,即上面那张图。
使用static使得每个类有一个自己的内存池,进行内存管理,而不是一个对象一个内存池
测试结果没有cookie的空间占用

application class的所有内存分配的细节都让allocator去操心,我们的工作是让application class正常工作
使用宏把重复的代码定义一下来使用的版本

测试结果没有cookie的空间占用,和static版本相同
技术的演进
new delete针对一个对象->static alloctor针对一个类->globa allocator针对一个标准库,里面有16个链表(static alloctor只有一个链表)
3.new_handler
在调用内存失败,抛出异常之前,会调用一个由自己设计的一个补救函数,即new_handler()。若new_handler()中没有abort()或者exit(),或者没有让更多内存可用,则会一直调用new_handler()直至满足内存需求。
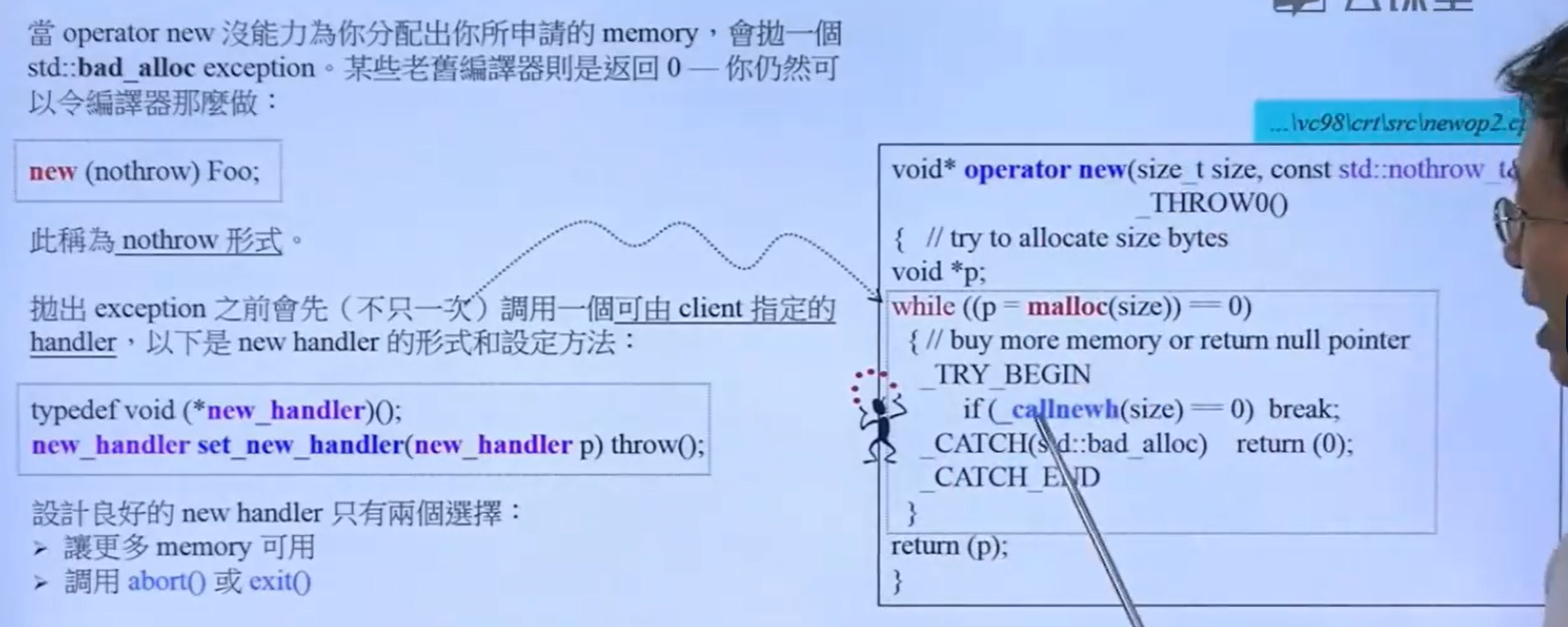
//调用:
//在main中写
set_new_handler(自己写的补救函数名);
注:
new delete的重载不可以是=default的,但可以是=delete的