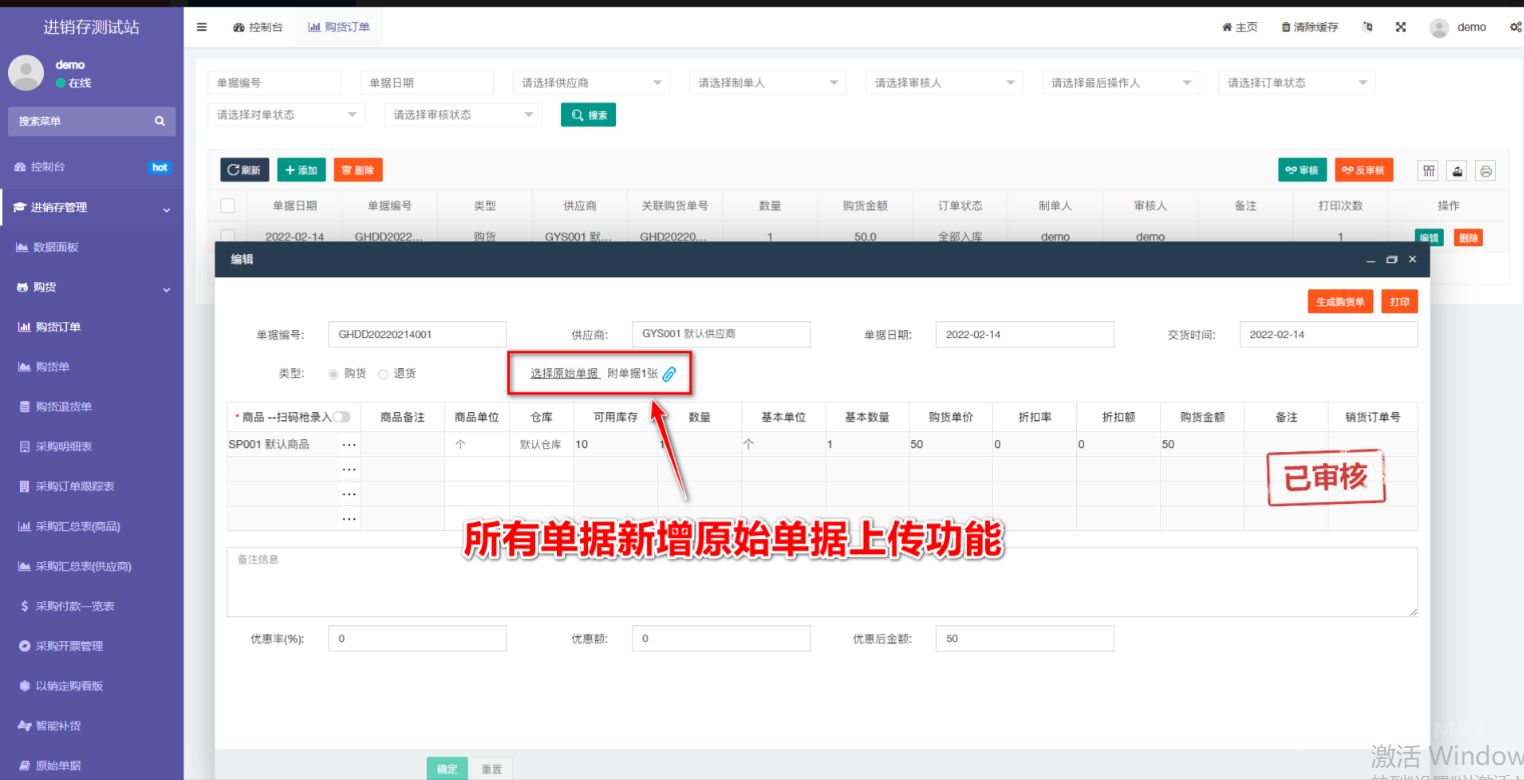
Mattermost 的 Jesús Espino 向 Natalie 讲述了他在阅读 Go 源代码时遇到的 10 个“顿悟时刻”(前六个)。第二部分(其余的顿悟时刻)即将推出!
本篇内容是根据2021年5月份#323 Aha moments reading Go’s source: Part 1 和
Aha moments reading Go’s source: Part 2 音频录制内容的整理与翻译
过程中为符合中文惯用表达有适当删改, 版权归原作者所有.
Natalie Pistunovich:大家好,欢迎收听新一期的 Go Time。我是 Natalie,今天和我们一起的是 Jesús Espino,来自 Mattermost。你今天将和我们聊聊你在阅读源码时的“顿悟”时刻。你用 Go 已经有一段时间了吧? (译者注: Mattermost是一个安全的协作平台,用于加速复杂环境中的关键任务工作。)
Jesús Espino:是的,我已经用了大约七年的 Go。算是挺长时间了,虽然也不是特别长……
Natalie Pistunovich:你是怎么开始使用 Go 的?为什么会选择 Go 呢?
Jesús Espino:嗯,其实一开始是因为我对 Go 语言本身产生了兴趣。我有个朋友---她当时在学习 Go,而且对这门语言非常兴奋,她向我介绍了 Go 中一些很酷的东西……于是我开始感兴趣,开始练习,后来还开始为一些开源项目做贡献。其中一个项目就是 Mattermost。大概六个月后,我就开始在 Mattermost 工作了,时机非常好。
Natalie Pistunovich:不错!你之前是从什么语言转过来的?
Jesús Espino:我之前主要用 Python,用了大概十年左右。
Natalie Pistunovich:你现在还用 Python 吗,还是已经完全转向 Go 了?
Jesús Espino:偶尔还会用到。Python 也是不错的语言,我更喜欢 Go,但 Python 也很棒。我有时在一些特定场景下还会用 Python。
Natalie Pistunovich:比如写 AI 模型?
Jesús Espino:是的,玩 AI 算是其中之一。另外可能还有一些小的脚本任务,或者非常小的 REST API,比如用 Bottle 或 Flask 写的小 API。所以基本上是一些小任务,没有大项目……不过我确实还会用 Python。
Natalie Pistunovich:不错。那我们开始聊聊你在阅读 Go 源码时的十个“顿悟”时刻吧。这是怎么开始的呢?
Jesús Espino:嗯,其实我一直喜欢深入了解我每天使用的工具。在之前使用 Python 时,我喜欢做演讲,深入探讨一些细节。当时我研究了 Python 中的对象在底层是如何工作的,比如内建对象的实现原理。我为此准备了一场演讲,并且真的在某个会议上做了这个演讲。当我转向 Go 之后,我从零开始学起,那个时候我对 Go 底层的东西还一无所知。我慢慢学习,逐渐对它有了信心。大概在 2020 或 2021 年,我觉得自己有足够的信心可以准备一个演讲了。我研究的其中一个内容就是 Go 中的一些内建对象是如何实现的,比如切片(slice)、映射(map)和通道(channel)。这些都是 Go 中的基础元素。所以我开始研究……
Natalie Pistunovich:是的,我看到的很多小测验通常都围绕着切片、数组这些主题。确实是个有趣的话题。
Jesús Espino:对,很有难度,理解它们的底层工作原理很有意思。这是我第一次开始有针对性地阅读 Go 源码。那时相对来说还比较简单。
我为 FOSDEM (自由及开源软件开发者欧洲会议) 准备了一个演讲,这是我第一次做这个演讲。这个过程给了我很多关于通道、切片和映射的洞见,甚至还对协程(goroutine)有了一些初步了解。所以这是一个有趣的实验,也让我开始了这段旅程。
之后我就一直在继续。我会利用参加会议和公开演讲的机会去学习我想学的东西。我准备演讲的时候,需要学到足够的知识,才能讲解并解答问题;有时候这真的很难。所以这就是我如何开始的。那些“顿悟”时刻就是在为不同的演讲做准备时不断发掘出来的。如果你想的话,我们可以继续聊聊这些。
Natalie Pistunovich:你要不要从第一个最大的“顿悟”开始?你会怎么介绍这些“顿悟”时刻?是按它们的影响力排序,还是按时间顺序?
Jesús Espino:我觉得按时间顺序来讲比较好,因为这样在我脑海中更容易理解,可能也能更好地解释为什么这是一个“顿悟”时刻。对我来说,第一个“顿悟”就是关于切片、映射和通道,特别是切片的实现。当我刚开始写 Go 时,别人告诉我“你可以使用切片,切片是不可变的,你可以往切片里添加元素,得到一个新切片。”但我觉得这看起来效率很低,这到底是怎么做到高效的?当我开始研究代码时,我意识到它们的实现非常聪明。切片其实只是指针和计数器,真正的数据是存储在底层的数组中的。这个数组会随着数据的增加自动扩展……而且数组的增长并不是简单地“加一个,加一个”,通常是将之前数组的大小翻倍来存储更多的数据。了解这些之后,你就明白为什么我们应该预先分配数组大小。这是我的第一个“顿悟”时刻,原来这就是它高效运行的原因。这个方法确实很聪明。
当然,这种实现方式也有一些陷阱。比如多个切片指向同一个数组,当其中一个切片修改数据后,其他切片仍然指向相同的底层数组,但突然之间它们就不再同步了。这种行为有些奇怪,如果你不理解底层实现的话会觉得很意外。但这确实是我的第一个“顿悟”,原来它是这样实现的,这就是它能够高效且流畅运行的原因。
Natalie Pistunovich:你当时是和其他语言对比着看的吗,还是这是你第一次关注数组底层是怎么实现的?
Jesús Espino:其实和 Python 比较相似,虽然不完全一样。在 Python 中,我不太确定,但好像不是直接向列表追加元素。你是在告诉 Python “我有一个元素列表,我要往里面加东西。”所以在语义上,你是理解为向列表中添加元素。在底层,如果我没记错,行为也是相似的。它也是在内存中有一个数组,当需要存储更多数据时会翻倍增长,类似的指针和计数器机制也存在。我记得这在 Python 中是差不多的实现,但我对 Python 实现的细节记得不是很清楚了。
Natalie Pistunovich:当然,我们现在也不是要讨论 Python 源码。我只是好奇你是否在其他语言中也关注过类似的主题,或者说你是在 Go 中才开始深入研究这些。
Jesús Espino:不,我以前在 Python 中也做过类似的研究,后来转到 Go 是因为我每天都在用 Go。所以重点是“我每天都在用这个工具,我想更好地理解它。”这就是我之前在 Python 中做这些研究的原因。我也想对我使用的所有工具都做类似的研究。我以前研究过 Git,未来我想研究 Postgres……但这需要时间,而有时候很难找到时间。不过这是我想做的事情。
Natalie Pistunovich:是的,这可以成为一个有趣的“深入代码的节日项目”。就像 Advent of Code 那样,但不是去解题,而是阅读别人的代码,学习其中的奥秘。
Jesús Espino:对。
Natalie Pistunovich:可以列入新年计划了。
Jesús Espino:嗯,这确实很有挑战性。我得说 Go 在这方面帮了很大的忙。Go 是一个非常适合阅读的语言,因为它的代码风格在各处都很一致。当然,不同项目的算法和复杂度会有所不同,读编译器源码是一件很难的事,因为编译器本身就很复杂。但同时,你会看到相同的代码风格,比如“if error then nil”这样的代码片段到处都是,所以不会感觉特别陌生。而在其他语言中,每个项目可能都有自己独特的编码风格。
Natalie Pistunovich:对,确实符合我们人类对模式识别的需求。我同意。你刚才提到的数组实现很容易理解,也符合你对模式的识别。
Jesús Espino:是的。我觉得最终很多实现,像切片和映射,其实并不是特别复杂或奇怪的实现。在其他语言中你也能找到非常类似的实现。比如在 Go 中,映射的键是无序的,而且这是有意设计的。实际上,每个映射的键顺序都是随机的。所以两个有相同键和值的映射,它们的顺序也会不同。
这是 Go 的设计,但大多数语言都有自己类似的实现,比如 HashMap 和切片等等。
Natalie Pistunovich:好的,那第二个“顿悟”是什么呢?
Jesús Espino: 接下来要说的是让我对 Go 语言感到好奇的一点,那就是协程(goroutine)。这是 Go 中的一个关键特性,大家都很喜欢用它……我也非常想更好地理解协程到底是什么,它是如何工作的。于是我开始深入源码,研究协程的底层工作原理,特别是协程的生命周期。我为此还准备了一个演讲,叫做《The secret life of a goroutine》 。在那次演讲中,我尝试跟踪一个协程从创建到销毁的整个过程,看看它如何从一个状态转变到另一个状态,以及它背后的逻辑是如何运作的。
在这个过程中,我发现了一件事---其实我之前已经有一些直觉或理解,那就是协程是合作式的(cooperative)。但当我深入代码时,这一点变得更加明显。
在操作系统线程中,操作系统决定何时中断某个任务并分配另一个线程来处理。而在 Go 中,协程本身负责说“嘿,我要暂停自己,调用调度器来选择另一个任务或协程”,然后另一个协程就会开始运行。协程并不仅仅是因为它在等待某件事而停止,唤醒它的通常是另一个协程。比如,当你向某个通道发送数据时,如果有另一个协程在等待,发送数据的协程会唤醒那个等待的协程。所以协程是互相协作来完成所有处理任务的。
当然,也有一些特殊的协程,比如系统监控协程,它负责监控某些事情,或者网络连接池,它也会监控一些任务的完成情况……但总体上,协程是互相唤醒的,或者它们会自行休眠,并调用调度器来选择另一个协程。这种协作式的特性让我觉得非常有趣,这也是我的一个“顿悟”时刻。对,就是这样。
Natalie Pistunovich: 你提到前面的那个“顿悟”---数组的实现让你觉得很合理。那么这个协程的实现让你觉得合理吗?如果是你设计,你会以不同的方式来处理吗?
Jesús Espino: 我觉得这是一种很自然的方式,特别是在你处理协程的时候。虽然 Go 的协程不完全是传统意义上的协程,但这种协作式的方式确实很适合。当你只有一个线程时,需要决定什么时候切换到另一个协程。如果你让协程之间进行协作,整个过程会简单得多,而不需要再加一个额外的进程来协调所有的协程。实际上,Go 的调度器并不是一个单独的进程,也不是另一个协程;它只是代码的一部分。挂起的协程会调用调度代码,调度器执行并选择另一个协程,然后把执行权交给那个协程。所以调度器其实只是一个代码块,用来在协程之间切换。这真的很酷,非常有趣。我不确定我是否回答了你的问题……
Natalie Pistunovich: 对对。接下来是一个有点哲学性的问题,作为背景---你看过《瑞克和莫蒂》吗?你知道里面有个叫“Mr. Meeseeks”的概念吗?
(译者注:
《瑞克和莫蒂》(Rick and Morty)是一部美国的动画科幻喜剧,由丹·哈蒙和贾斯汀·罗兰创作。该剧首次在2013年播出,讲述了疯狂科学家瑞克·桑切斯(Rick Sanchez)和他的孙子莫蒂·史密斯(Morty Smith)在多个宇宙和维度之间进行冒险的故事。
瑞克是一个天才但自私的科学家,常常因其冒险而导致各种麻烦;莫蒂则是一个普通的青少年,常常被卷入瑞克的疯狂计划中。该剧探讨了家庭关系、存在主义、道德困境等深刻主题,同时融合了幽默和讽刺。)
Jesús Espino: 哦,不,我没看过。抱歉。
Natalie Pistunovich: 在《瑞克和莫蒂》里有一个叫“Mr. Meeseeks”的小蓝色生物,我发现这个概念对理解协程非常有帮助。它的工作原理是生成一个任务,完成后就会消失。我觉得这个概念和协程很相似。我猜这部剧的创作者里可能有开发者,因为我发现了很多相似之处。后来当 AI 的概念出现后,特别是自主代理(autonomous agents)的概念,也有些相似之处。在 AI 世界里,这些代理会接收一个任务,然后分解成子任务,最终完成任务并返回结果。
我认为这三者之间有很多相似性,希望我刚才的简单介绍能让你理解这个逻辑……接下来在我们讨论这些“顿悟”时刻时,这会是我引导问题的思路之一,因为我喜欢在当前的软件开发和我所想象的基于 AI 的软件之间寻找很多对应关系。我知道你不熟悉《瑞克和莫蒂》,这没关系(笑)。你有没有尝试过 AI 代理?你对此有足够的经验可以发表意见吗,还是暂时还没有接触过?
Jesús Espino: 目前还没有接触过,我不太了解你所说的 AI 代理。
Natalie Pistunovich: 自主代理可能是更好的说法。
Jesús Espino: 嗯,我猜是类似的东西吧,比如你给它一个任务,它通过外部资源或外部操作来完成任务……大概是这样吧。
Natalie Pistunovich: 基本上,AI 接收一个目标,然后它自己决定如何分解成子任务,并生成小型 AI 去执行这些子任务。整个过程有点像协程的概念。
Jesús Espino: 是的……有可能。我不是很深入研究 AI,但我确实喜欢它,而且也用过一些 AI 工具。我认为它们之间确实有相似之处。最终,协程就是一种轻量级的进程。它们有一个任务要完成,并且在一定程度上与其他协程是独立的。
其实有一点让人觉得奇怪---协程之间没有父子关系。如果我没记错的话,协程是独立的。一个协程就是一个协程,它们之间没有层级关系。你可以运行成千上万个协程,它们彼此之间没有任何关联,甚至和启动它们的那个协程都没有关系。所以我有点跟不上你的问题了(笑)。
Natalie Pistunovich: 是的,这只是一个观点而非问题……不过再复杂一点,然后我们就可以聊第三个“顿悟”了(笑)。我还发现协程与处理器线程之间也有相似之处。我不知道你有没有机会深入研究操作系统是如何将任务分配给不同处理器的,但我发现这些概念之间有一些相似之处。这些领域虽然不同,但它们之间有着某种联系。我个人觉得这非常有趣。这只是一个观察,并不是问题。如果你对此有经验,我很乐意听听你的看法。如果没有的话,那我们可以进入第三个“顿悟”。
Jesús Espino: 是关于线程与协程的区别,还是其他什么?
Natalie Pistunovich: 对,你想聊这个话题吗?
Jesús Espino: 是的,其实 Go 在运行时是如何解决这个问题的非常有趣。基本上,它把操作系统线程抽象出来,称之为“处理器”。然后这些处理器会被分配给不同的协程。但协程和处理器之间并不是紧密耦合的。协程通常会倾向于在同一个处理器或操作系统线程上执行,但这并不是强制要求的。所以协程可以在不同的操作系统线程上执行。
Go 这种让 CPU 和协程、操作系统线程与协程解耦的方式非常聪明。它允许你使用这种架构充分利用处理器的性能。如果某个 CPU 负载过高,你可以将协程从另一个 CPU 拿过来,并在空闲的那个 CPU 上运行。这种方式非常酷,Go 通过这种方式把 CPU、操作系统线程和协程都抽象出来了,真的很棒。
Natalie Pistunovich: 是的,确实很高效。那么你的第三个“顿悟”是什么呢?
Jesús Espino: 好的,第三个“顿悟”。嗯,这个有点傻(笑)。我当时在研究编译器,具体来说是词法分析和语法分析的过程。当我开始阅读解析器时,我突然意识到---虽然这其实很显然---解析器中的内容就是你可以写在 Go 文件中的内容,除此之外没有其他东西。
所以当你查看 Go 的抽象语法树(AST)是如何生成的时,你会发现每个文件都有一个抽象语法树,它包含一个导入语句、一组声明和一组导入。声明可以是常量、变量、函数或类型。就这么多,文件里不会有其他东西。
对我来说,这是一种彻底理解某件事的感觉,就好像“哦,我明白了,所有的东西都在这些范围内,文件里不会有其他东西,我没有遗漏什么。”常量、变量、函数和类型,还有导入语句和包名。就是这些了。
虽然这听起来有点傻,但对我来说这是一个“顿悟”时刻,就是“哦,原来如此”。当然,函数体里面还有很多东西,但在一个文件中你只会看到这些元素。
Natalie Pistunovich: 这让我想到了 C 语言中的头文件和代码文件。它们有点类似于作用域的概念,给文件定义了一个小宇宙,而这里则是为 Go 文件定义了范围。知道这些内容是文件的全部,确实很有帮助。
Jesús Espino: 对,确实有点像。你对文件能包含哪些内容有了明确的定义。虽然和 C 的头文件不完全一样,头文件中声明的是函数的定义,也就是公共接口。但在某种程度上确实是这样,如果我理解头文件,我就应该能够使用它,并理解它的边界。所以确实有相似之处。
Natalie Pistunovich: 你提到的这种方式不仅仅是定义文件的范围,更是对整个 Go 语言工具箱的定义。它告诉你“这就是你所有的工具,不会有其他的意外”。这不仅仅是关键词,而是真正的工具箱。
Jesús Espino: 是的,就这些了。如果你问:“我能不能在主文件中,在函数之外执行一段代码?”答案是不行。要是声明变量呢?可以。声明常量呢?可以。但如果不是类型定义或函数,你就不能这么做。因为在 AST(抽象语法树)中没有这种结构的表示方法。你无法在 AST 中表示这样的代码。当然,这里有些像 pragma 之类的东西,[听不清 00:28:50.19],但它们其实是以智能方式处理的注释。但归根结底,AST 只包含这些内容。除此之外,你没法用它表示其他东西。
Natalie Pistunovich: 听起来这个“顿悟”还没有成为一个演讲内容。
Jesús Espino: 确实没有。这个“顿悟”其实来自于我在准备另一场演讲时的发现。当时我正在准备一场名为《理解 Go 编译器》的演讲。其实它原本叫《Hello World:从代码到屏幕》。我在 GopherCon US 上做过这个演讲,但后来为了 GopherCon UK,我根据最新版本的 Go 编译器更新了这场演讲,并重新命名为《理解 Go 编译器》,因为这个标题更清晰,更不会让观众误解我将要谈论的内容。这个“顿悟”就来自于那场演讲。
在那次演讲中,我带领大家走过整个编译过程……其实有很多“顿悟”时刻来自于那场演讲,因为我深入研究了整个编译过程。我的演讲思路是,我有一个 Hello World,它将会是这场演讲的主角,它会经历从源代码到生成二进制文件的整个转变过程。我带领观众一步步理解这个过程。而这个“顿悟”就是在那时产生的。当然,还有其他一些“顿悟”也是来自于这次演讲。如果你愿意,我们可以继续谈下一个“顿悟”。
Natalie Pistunovich: 好的,好的。我们来聊第四个“顿悟”。
Jesús Espino: 我想是这样。当我在研究编译器时,有两项我特别关注的特性:逃逸分析(escape analysis)和内联(inlining)。对于不太了解逃逸分析的人来说,逃逸分析是编译器中的一个过程,它决定某个变量是需要存储在堆上,还是可以存储在栈上。这个决定是通过逃逸分析做出的,基本上就是判断“嘿,我能否将这个数据存储在函数的栈上,还是因为这个变量的作用范围超出了函数的范围,因此我需要将它存储在别的地方?”如果超出函数的范围,那么它就得存储在主内存,也就是堆上。这就是逃逸分析的工作原理。
另一方面是内联。内联是一个分析函数的过程,Go 编译器会分析函数,并决定这个函数是否足够简单,可以在调用的地方直接嵌入它的代码。也就是说,编译器不会调用这个函数,而是将函数的代码直接替换进调用点。这就是内联。它取决于函数的复杂度,这不仅是指函数的大小,还取决于函数内部使用的操作。
我学到的有趣之处在于:当你有逃逸分析时,它会决定函数的变量是存储在栈上还是堆上;而内联则允许你将函数嵌入到调用点。如果你的函数足够简单,它就会被内联,突然间,变量的作用范围变大了,更有可能存储在栈上而不是堆上。这非常酷,非常有趣。我觉得这是一个特别有意思的发现。
Natalie Pistunovich: 那么你有没有机会写一些与这种功能对应的代码?这些代码是否显得特别高效或有趣?或者你能想到什么用例让它变得特别有趣吗?因为你在描述的时候,我脑海里没有想到任何具体的例子。
Jesús Espino: 确实有一些用例……我认为这是一个有用的工具,有时你可能会说:“我这里有一个非常紧凑的函数,它生成了大量的内存分配。”然后你可以尝试调整它,直到它被内联。这是一个方法。但我觉得更有趣的部分在于,你可以根据这个知识做出更聪明的设计决策,比如在创建结构体时。如果你有一个用于创建新结构体的函数,并且这个函数中有初始化过程,那么这个新函数几乎肯定不会被内联,因为初始化过程会变得足够复杂而无法内联。
因此,当你执行 new 函数时,它会返回一个指向该变量的指针,而由于这个原因,变量总是会被存储到堆上。但如果函数足够小,比如说“嘿,这个 new 函数创建对象并返回指针”,那么这个 new 函数就总是会被内联,变量也总是存储在栈上---除非有其他原因导致逃逸。但你是在父函数的栈上存储这个变量……然后如果你调用一个初始化函数,这个初始化函数已经在栈上工作了。
所以保持构造函数足够小以便它们能够被内联,通常来说是一个好的实践。比如说,这就是一个不错的做法。它不会带来巨大的性能提升,但可以带来一些小的性能改进. 所以,是的,这是个好方法。
Natalie Pistunovich: 是的,这很有道理。而且如果能在这个基础上进行追踪(tracing),并进行对比,那将会非常有趣……
Jesús Espino: 是的。根据你应用程序的规模,你可能会创建成千上万个对象。如果这些对象被分配到堆上而不是栈上,那会产生大量的 待回收对象,还有很多其他可能不太重要的东西。
Natalie Pistunovich: 实际上,可能会发现很大的差异。我非常好奇,你会不会计划做一期追踪相关的节目?作为该话题的第二部分……我会记得标记一下,届时在那期节目中提到这个发现。这是一个很酷的观察。
Jesús Espino: 是的。其实我听说内联器现在正在被重写。我不确定这个工作是否已经完成……
Natalie Pistunovich: 我记得在 23 版本中应该会发布并更新。
Jesús Espino: 是的,还会有一个分析器,对吧?带有基于分析结果的优化。所以是的,这会非常酷,可能会有很大的影响。
Natalie Pistunovich: 关于第四个“顿悟”,你还有什么要补充的吗?
Jesús Espino: 我想没有了。我们还有很多内容要讨论……
Natalie Pistunovich: 好的,继续吧……现在我们来谈第五和第六个“顿悟”。
Jesús Espino: 是的,我还在继续研究 Go 编译器,经历了这个过程中不同的步骤……然后我到达了一个对我来说非常有趣的点,那是另一个“顿悟”时刻,就是当 Go 编译器变得与具体机器相关的时候。整个过程包括词法分析、语法分析,中间有一个中间表示(IR),然后它会转换为一个叫做 SSA(单一静态赋值)的东西,接着进行一系列优化……在将 SSA 转换或处理的过程中,有一个优化阶段叫做“lower”(下沉)。这个阶段是编译器开始处理与具体机器相关的部分。在这之前的所有步骤都是与机器无关的。无论你使用的是 ARM 还是 AMD-64,都没有区别,代码库是一样的。然后,当进入 SSA 的“lower”阶段时,编译器就会将它转换为与具体机器相关的 SSA。接着进行其他优化,最终生成二进制文件,进行链接,生成可执行文件。
最有趣的是,直到过程的很后面,编译器才开始处理与具体机器相关的部分。这本身就是一个“顿悟”时刻,对我来说非常有趣……但我也是 TinyGo 的超级粉丝。我喜欢微控制器,喜欢玩这些东西……虽然我不是很擅长,但我喜欢尝试。这让我对 TinyGo 的运作方式特别感兴趣。而 TinyGo 的做法非常聪明。它基本上是将一切处理到 SSA 阶段……直到那个点,它使用的都是相同的编译器,基本上是相同的代码库。在那个点上,它接过 SSA,而不是将 SSA 转换成机器码,而是将其转换为 LLVM 的中间表示(IR),或者 LLVM 的汇编代码。然后,LLVM 负责将其编译为与微控制器特定架构相关的代码。
除此之外,你还需要一个与微控制器兼容的运行时,因为微控制器没有像操作系统这样的东西,也没有同样的资源访问方式。但最终,编译过程是完全相同的,这就是为什么 TinyGo 使用的还是同样的语言。你可能在运行时上有一些差异,但在语言上没有差异,因为它们是相同的语言,利用了这个关键点。所以对我来说,这是一个“哇,这些人真的很聪明”的时刻。我非常喜欢这个“顿悟”,而且我也是 TinyGo 的大粉丝,所以……
Natalie Pistunovich: [笑] 为 TinyGo 的酷炫功能打个广告……尤其是 Ron Evans 和 Daniel Esteban 以及他们的团队,他们一直在做这些很酷的项目。
Jesús Espino: 哦,是的。
Natalie Pistunovich: 是的,确实很有趣。如果它可以轻松映射到不同的处理器上,也可以映射到小型嵌入式技术上,那么它如何在 GPU 上工作呢,例如?
Jesús Espino: 是的,这很有趣……我认为 GPU 有一套不同的指令集,所以我觉得它不太适合这种情况。老实说,我不是这方面的专家,但我的感觉是,你处理的是一种面向通用 CPU 的 [听不清 00:40:52.01]。然后这个通用 CPU [听不清 00:40:58.09] 被转换为真正的通用 CPU,比如 ARM 或 AMD64 等等。所以将其应用于 GPU 的话---你可能可以应用相同的理念。你可以做 Rob Pike 做的事情,或者 Go 团队做的事情,也就是生成 [听不清 00:41:25.28] 的汇编代码,这是为 GPU 代码设计的,并将其构建到你拥有的中间语言的水平。然后,当你到达那个点时,你将其转换为不同 GPU 的汇编代码或指令的具体细节。但我不认为可以直接在 GPU 上执行 Go 二进制文件,因为它们有一套不同的指令。这与你处理的机器类型不同。
Natalie Pistunovich: 是的,这说得通。
Jesús Espino: 再说一次,我不是专家。也许我在这里错了。
Natalie Pistunovich: 是的,我猜这是一个突然的问题。不过这确实很有趣,我会去查一下。我现在也很好奇……你提到了嵌入式 TinyGo,虽然这种关联性已经存在很久了,但我现在才开始思考“它对于 FPGA 会有多么不同?”还有世界上所有的其他硬件。也许有一天我们可以做一期关于 Go 和不同处理单元的节目。
是的,我们只讨论了十个中的六个,但时间快到了,这意味着我们必须做第二部分,因为你带来了太多有趣的点,我有太多的问题/评论想说。最后一个问题是“你有什么不受欢迎的观点吗?”
Jesús Espino: 好的,我觉得我可能会因为这个观点受到一些反对……不过这就是不受欢迎的观点的意义所在。
Natalie Pistunovich: 是的。
Jesús Espino: 我认为机械键盘只是一种被过分美化的怀旧情怀。
Natalie Pistunovich: 大声地被美化了……
Jesús Espino: 是的,非常大声地被美化了。这就是问题所在---我用过机械键盘,但我不觉得它们更舒适,也不觉得它们更好。它们肯定不会让你成为更好的程序员,也不可能提高你的编程效率……这完全不可能。我能理解在某些情况下它们很酷,比如你自己组装键盘,或者使用那种分体式键盘,或者编程键盘,里面有微控制器和类似的东西---在这些情况下,我觉得很酷,因为你可以自己选择开关和其他组件,而且有很多配件可以用来做这些事情……但我不太能理解,为什么要花 10 倍的价格?你能从键盘上得到的 10 倍提升,可能只体现在价格上。
Natalie Pistunovich: 还有声音。噪音。
Jesús Espino: 哦,是的。确实。分贝数也增加了。你花 10 倍的价格买的东西……我不知道,这可能是一个不受欢迎的观点。我知道那些觉得这个观点不受欢迎的人会非常不赞同……所以我们拭目以待吧。
Natalie Pistunovich: 嗯,我不能说我不同意你,所以至少在我这里,你的观点是受欢迎的……我的不受欢迎的观点和这个话题类似……触控板比鼠标好用。
Jesús Espino: 我用的是鼠标,但是……是的,我觉得确实如此。
Natalie Pistunovich: 好吧,我猜我们都同意。既然我们达成了共识,我要感谢你今天的参与和分享的有趣见解,我期待第二期节目,也感谢所有参与的人。
Jesús Espino: 是的,谢谢你邀请我。
Aha moments reading Go’s source: Part 2
Natalie Pistunovich:好的,我叫 Natalie,今天再次和 Jesús 一起录制节目。我们现在正在录制的是第二部分,主题是 Jesús 在阅读 Go 代码库时的 10 个“顿悟”时刻……我们上次谈到第六个。你愿意在我们进入第七个之前做一个快速的回顾吗?
Jesús Espino:好的,没问题。大家好。
Natalie Pistunovich:是的,欢迎再次加入。我直接跳回正题,不过……[听不清 00:04:57.23]
Jesús Espino:没关系,让我们回顾一下。上一期我们讨论了一些来自我对 Go 源代码探索的“顿悟”时刻,这些发现来自于我做过的几次演讲。其中一个演讲是关于不同的构建对象,比如切片、映射和通道……另一个演讲则是关于 Go 编译器的。我还有一场关于理解 Go 编译器的演讲。我们探讨了这些不同的“顿悟”时刻。其中一个是关于切片在底层是如何工作的,这对我来说很惊讶。另一个是关于语法,Go 的语法在编译器内部是如何表现的,也就是抽象语法树(AST)……了解抽象语法树的结构对我来说是一个“顿悟”时刻,因为它让我明白了 Go 文件中可以包含什么,文件的边界在哪里,什么是不能存在的。
Natalie Pistunovich:构建块是什么。
Jesús Espino:对,构建块是什么,以及不存在其他我没见过的构建块。因为我已经读到了所有相关的内容。这是另一个很酷的“顿悟”时刻。另外一个是关于 goroutine 的协作性质,goroutine 之间如何彼此唤醒,如何自我停止等。这也非常有趣,是另一个非常有意思的发现。
还有一个是当我在研究编译器时,开始了解逃逸分析的概念,也就是编译器如何决定哪些数据放到堆上,哪些放到栈上……还有内联优化,编译器决定是否内联函数的代码。它们如何协同工作,以更好地利用内存。因为有时内联会让原本要放到堆上的东西,现在因为内联而被放到栈上。这会更快。所以这也是一个“顿悟”。
另一个对我来说也非常酷的发现是,理解编译器在哪个阶段开始处理与具体机器相关的代码。也就是在编译过程中,代码在哪一刻变得与具体机器相关。这发生在整个编译过程的很晚的阶段,是在静态单一赋值(SSA)表示的某个阶段。这非常酷,因为这意味着编译器的大部分内容与架构无关,这让人非常惊叹。
另一个与此相关的发现是 TinyGo 是如何利用这种思想的。它利用了 SSA 表示来构建 TinyGo 编译器。基本上,它使用 Go 的 SSA 表示来生成 SSA,使用现有的编译器机制生成 SSA。而不是将 SSA 编译成某个架构的二进制文件,而是截取这个过程,将 SSA 转换为 LLVM 的中间表示,或者 LLVM 汇编代码,然后由 LLVM 将代码转换为适合微控制器的特定架构。我觉得这非常聪明,也非常令人惊叹。这就是我们昨天讨论的六个“顿悟”时刻---也就是上一期节目讨论的内容。
Natalie Pistunovich:没关系,没关系。你可以说幕后发生了什么,一切都好。上一期节目变得比预期要长,所以我们把它拆分成了两部分。
Jesús Espino:好的,我想这就是我们昨天讨论的内容。
Natalie Pistunovich:好的,我准备好进入第七个了。
Jesús Espino:好的,第七个---这是我对理解 Go 编译器的演讲与理解 Go 运行时的演讲之间的交集。这是下一个显而易见的步骤。实际上,当你在探索这些内容时,最合理的下一步是停止继续深入,因为再深入下去可能没有意义……但我比较鲁莽,所以我继续深入研究,开始研究运行时。在这过程中我发现了一些有趣的东西,这让我感到惊讶……虽然不一定是出乎意料的,但还是让我觉得有趣……你仔细想想是有道理的,但我之前没有想到。当我看到它时,还是感到惊讶。这就是编译器通常会将代码编译为二进制代码。如果你有一个变量赋值,它将被编译为一些二进制代码,这些代码会进行寄存器更改、内存访问等操作。
但是,并不是所有的代码最终都会被编译成实际的二进制代码。有些你在 Go 源代码中看到的语法会被编译为对运行时的调用。也就是说,编译器不会生成一些汇编代码或 CPU 指令,而是将逻辑委托给一个始终存在的代码模块---也就是运行时。
例如,我们常用的语法之一是往通道中插入数据或从通道中读取数据。这种语法最终会转换为汇编中的一个函数调用,调用运行时模块中的特定函数,该函数负责向通道发送或接收数据。
这点非常酷,因为你可以看到设计的巧妙之处。运行时总是存在的,代码也相对容易理解……如果把所有这些转换为汇编来表示通道的概念,可能会让你的二进制文件变得更大。而且,这样的设计也更简单。你有一个始终存在的包,你的语法可以基于该包进行编译。所以我觉得这非常酷。
如果你使用 go build 的标志,你可以很容易地看到这一点。如果你传递 GC 标志,你可以在构建程序时看到生成的汇编代码,在汇编代码中你可以看到对运行时包的所有调用。所以这很容易看到,对我来说也非常酷。
Natalie Pistunovich:你认为为什么是这样设计的?有没有其他可能的设计方式,可能会适用于不同的场景?
Jesús Espino:我认为,例如,在 Rust 中有一个概念叫做“零开销抽象”(zero-cost abstractions)。也就是说,你有那样的语法,但编译器会处理所有这些,并为那个抽象生成最终的二进制文件,而不会有任何运行时开销。这是另一种做法。这会给编译器带来更大的压力,编译器需要花更多的时间来编译所有代码……这可能是原因之一。如果你有一个始终存在的运行时,并且它可以随时链接到你的二进制文件中,或者嵌入到你的二进制文件中,编译速度可能会更快。此外,我认为代码也会更简单。因为最终,你有这些转换,所有这些生成抽象语法树(AST)的过程,这些 AST 突然代表某些东西,然后转换为中间表示,再转换为指令……所有这些过程相对来说要比“当你看到一个通道发送时,只需添加一个函数调用”要复杂得多。这更简单。我想这就是背后的思路。我不确定,但这是我的猜测。编译速度更快,或者我猜测编译速度更快,而且从心智模型的角度来看也更简单。
Natalie Pistunovich:这是否与交叉编译标志有关,以支持这种设计?从你的猜测来看。我知道这个问题涉及多个话题的交叉。
Jesús Espino:是的……我觉得这不一定与交叉编译有关,因为交叉编译部分……确实有一些关系,因为如果你的运行时已经为另一个架构交叉编译过了,你就不需要一遍又一遍地重新编译那部分代码。所以运行时只需要交叉编译一次,剩下的代码才是需要重新编译的部分。但最终,运行时就像其他任何 Go 包一样……所以最终,交叉编译的影响可能不会那么大。因为你所做的就是“发送消息到通道时,它会是一组指令”。就这样。所以我不认为这会影响交叉编译。不过,正如你所说,这只是我的猜测。
Natalie Pistunovich:在编写代码时,有没有什么建议是可以考虑到这一层的?还是说这涉及太多层次,更多的是一种额外的知识?
Jesús Espino:是的,对我来说,我认为部分原因是,当你想了解某些东西是如何工作时,你可以去查看代码,然后说:“哦,原来它是直接调用运行时的。” 比如说,每当我向切片追加内容时,其实就是调用了运行时。因此,有些事情发生在运行时,基于此你可以说:“好吧,如果这是运行时的职责,我可以很容易地查看运行时的代码,搞清楚发生了什么。” 你可以理解追加到切片意味着什么,或者向映射中添加内容或向通道发送数据意味着什么。基于这些,你可以很容易地进行探索。我觉得这方面还是有一些价值的。
总的来说,我的演讲其实毫无用处。虽然这些知识很有趣,我觉得这些知识很有趣,但大体上它们是没什么实际用处的。因为它们主要讲的是事情的工作原理。而说实话,Go 编译器工作得非常好,所以你其实不需要了解编译器和运行时是如何工作的。这更多是出于好奇心,帮助你更好地理解某些东西。当然,偶尔你会发现这些知识派上用场,但总体来说,这更多的是一种对底层机制的理解的乐趣。
Natalie Pistunovich:是的。我猜总有那么一次,当内存突然被疯狂地消耗,没人能理解为什么,而那时有一个人知道某个非常小众但有趣的事实……这时这些知识就派上用场了。
Jesús Espino:是的……我在 GopherCon UK 上听了 Miki Tebeka 的一个关于脑筋急转弯的演讲。他还有一本关于这个主题的书……我大概能猜中 50%,剩下的 50% 我被难住了。不过有些其实很容易猜到……有些我会想:“哦,好的,我知道它会有奇怪的表现,因为我知道底层是如何工作的。” 但正如我所说的,这虽然很酷,但通常并没有太大的实际用途。
Natalie Pistunovich:基本上就是把它放在脑后,等到编译的某个时候出现问题时再想起来。
Jesús Espino:是的,没错。
Natalie Pistunovich:当编译表现得很奇怪的时候。
Jesús Espino:是的,没错。而且理解一些小细节也很有趣。
Natalie Pistunovich:好吧,我们进入第八个“顿悟”吧。
Jesús Espino:是的,这又是一个与理解知识有关的例子,有时你真的不知道发生了什么……这次是关于二进制文件的入口点。当你执行 Go 二进制文件时---当你学习 Go 时,大家都会说:“哦,程序的入口点是你定义的 main 函数,然后程序从那里开始执行。” 但实际上这并不完全正确,因为我们有一个运行时。实际上,二进制文件中首先执行的并不是 main 函数,而是一个与操作系统和架构相关的汇编函数。这个函数会初始化很多东西,比如内存分配器、垃圾回收器、CPU 标志、与安全相关的内容等等……在 main 函数被调用之前,已经有很多事情发生了。这真的很有趣,因为你可以看到在执行 main 函数之前已经有很多事情在进行,这非常令人惊叹。
另外,在这个过程中,发生的另一件事是你的 main 函数实际上是通过一个 goroutine 执行的。并不是主进程执行 main 函数,然后再生成 goroutine。实际上,第一个 goroutine 被创建后,就开始执行你的 main 函数。所以 main 函数并不是在 goroutine 之外执行的,在它执行之前,已经有其他 goroutine 在运行了,比如系统监视器等等。因此,在 main 函数执行之前,有一个非常有趣的过程。我觉得这非常酷。
Natalie Pistunovich:一方面,发生了很多事情;另一方面,这一切都很快完成,这让我想到了那个 XKCD 漫画,讲的是在编译时他们玩剑术,而在 Go 里这一切基本上就像这样发生了,只是速度更快。 (译者注: xkcd是兰道尔·门罗(Randall Munroe)的网名,又是他所创作的漫画的名称)
Jesús Espino:是的,确实非常快。实际上,如果你深入研究初始化过程,大部分任务都非常小。比如内存分配器只是初始化一些结构体,但并不涉及什么繁重的工作。垃圾回收器只是设置一些标志位,垃圾回收器就启动了。所有这些都是小任务、小规模的初始化……然后当程序开始运行时,你就开始使用这些东西。比如当你需要内存时,内存分配器就会开始工作;当你需要回收垃圾时,垃圾回收器就会启动。所以在启动二进制文件和调用 main 函数之间发生的事情很多,但它们都是小任务,目标非常明确。
Natalie Pistunovich:如果有人想研究这个过程,该怎么做呢?你是怎么做到的?
Jesús Espino:是的。我建议你去看我的演讲,这是一个相对简单的途径。但如果你想自己研究,这也是完全可以的。我所做的是使用 GDB 调试器,找到程序的入口点;在我的情况下,它在 src/runtime/rt0_linux_amd64.s 文件中。那是个汇编代码文件。我开始跟踪它的不同调用,看看这些调用在做什么,正在初始化什么等等。基本上,我手动跟踪了整个执行过程。
这个过程相对来说有点难度;并不是特别容易,因为你需要理解一些汇编代码。你不需要精通汇编,但需要了解一点点。然后你就可以开始跟踪这些小步骤。你会看到调度器的初始化,但调度器的初始化还包括内存分配器和垃圾回收器的初始化……所以调度器的初始化是一个大块内容,但它内部实际上在初始化很多东西。跟踪这些花费了我一些时间,但并不是特别难,更多的是耗时而不是复杂。
Natalie Pistunovich:所有的链接都会放在节目笔记里。
Jesús Espino:哦,是的。我可以分享一些链接。实际上,在我的演讲中我通常会在幻灯片的右下角列出源代码的链接。这种做法更像是给观众布置的“作业”,如果他们想去看源码中发生了什么。你可以去看我的演讲幻灯片,并查看不同步骤,在右下角你会看到链接到源文件,以及 Go 运行时或编译器的特定版本。是的,你可以去那里查看。我不知道有多少人会去看,但我把它放在那里了。
Natalie Pistunovich:是的,很好,肯定是有参考资料的,这总是好的。好的,第九个。
Jesús Espino:好的,这与我们之前讨论的内容有关……这是关于内存分配器的。可能这是我的疏忽,但我从来没有考虑过 Go 中内存分配器的概念。每当谈到 Go 中的内存管理,通常我们会谈到垃圾回收器。但我从未想过内存分配器。而内存分配器是一个非常有趣的软件模块,我之前并不知道。
内存分配器负责与操作系统对接,申请和释放内存页。这是 Go 内存管理中的一个非常有趣的部分。实际上,它的工作原理是将数据按特定方式组织,即将一组内存页称为 mspans,这些 mspans 中的变量始终具有相同的大小。所以一个 mspan 可能有 30 页,但无论它有多少页,它总是存储相同大小的变量。
这意味着,如果你有一个 8 字节的 mspan,所有 8 字节大小的变量都会存储在里面。如果你有一个 32 字节的 mspan,32 字节的变量会存储在里面。mspans 的大小是预定义的,跨度越大,变量之间的间隔也越大。比如你有 8、16、24、32 字节的 mspan,然后可能会跳到 48 字节,再跳到 60 字节,依此类推。我不记得确切的数字,但变量之间的间隔会越来越大。这一点很重要,因为如果你有一个 30 字节的变量,它会被存储在 32 字节的 mspan 中,占用 32 字节的空间,无论结构体的实际大小是多少。
因此,所有介于 24 到 32 字节之间的变量都会存储在 32 字节的 mspan 中,并占用 32 字节的空间。这样做的好处是减少了内存碎片,存储和检索变量的效率也更高。此外,释放和申请内存页也变得更容易……这是一个非常有趣的内存管理方法。这就是内存分配器的工作原理。
除了 mspans,每个 CPU 还有一个 mspan,然后所有 CPU 的 mspans 会集中管理。还有一个 mheap 管理所有东西。最大 mspan 的大小是 32 KB,我记得是这样。所以超过 32 KB 的数据会直接由 mheap 处理,并申请独立的内存页。
因此,较大的数据块会被独立处理,不在 mspans 中,而是直接使用内存页。所有小于这个大小的数据都会存储在 mspans 中,由内存页处理。所以内存分配器负责从操作系统申请和释放内存页。垃圾回收器决定哪些内存可以回收,而内存分配器负责申请和释放内存。以前我完全不知道有这个东西的存在,因为我基本上是一名 Web 开发者……所以我的关注点一直在别的地方。
Natalie Pistunovich:是的。我想看一场关于这个主题的演讲。我觉得我需要再听一遍。
Jesús Espino:是的。我记得在上一次 EuroPython 大会上,Diana Shevchenko 做了一场演讲---
Natalie Pistunovich:来自 Datadog?
Jesús Espino:是的,来自 Datadog。她做了一场关于内存分配器的演讲,讲述了他们如何通过了解内存分配器的工作原理,极大地提高了性能,减少了内存使用,降低了垃圾回收压力等等。所以这很有趣……实际上,了解垃圾回收器的工作原理,了解结构体的字段顺序对内存使用的影响,如何通过改变字段顺序来减少内存使用……如果刚好能利用 mspans 的合适大小,你就能节省大量内存。所以当录音发布后,大家可以去看看 Diana 的演讲。
Natalie Pistunovich:有推荐的实践方法吗?有人能从中学到什么并应用到实际代码中吗?
Jesús Espino: 是的,我会说,了解 mspan 的大小以及结构体的字段排列可以帮助你节省内存---这是我建议大家去了解的,特别是如果你有大量实例的情况。比如在 Datadog,他们有一些结构体会被重复使用数百万次。如果你每个结构体节省 30 字节,乘以数百万次,你就能节省大量内存。同时也减少了操作系统的内存申请和释放次数。所以我觉得如果你有数百万个对象实例的话,这肯定是值得研究的。
Natalie Pistunovich:好的,我还在努力想把这些信息和某个实际场景联系起来,这样更容易记住……不过好吧,接下来是第十个,也是最后一个“顿悟”。
Jesús Espino:是的。第十个“顿悟”是相关的。我经常会说:“哦,垃圾回收器运行时会在内存达到某个阈值时触发,但它也可能在没有达到内存阈值时运行,或者你可以手动触发它……” 但垃圾回收器运行的时机其实只有三种情况。我意识到这一点时感到很有趣。第一种是你显式调用垃圾回收器,启动一个垃圾回收周期。这就是手动调用垃圾回收器的情况,称为 GC 触发周期。第二种与时间有关。Go 中有一个每 10 毫秒运行一次的 goroutine,叫做系统监视器。如果垃圾回收器在一段时间内没被调用,系统监视器会触发垃圾回收器运行。这叫做 GC 时间触发,由系统监视器检测并调用垃圾回收器。
然后第三种是我觉得最有趣的,就是 GC 堆触发。这与 Go 的环境变量 GOGC 有关,这个变量定义了垃圾回收器应该在何时运行,基于上一次垃圾回收后堆的大小。默认值是 100%,这意味着每次垃圾回收后,堆的大小会减小到某个值,比如 16 MB。下一次垃圾回收会在堆增长到两倍,也就是 32 MB 时触发。如果垃圾回收后堆的大小变为 20 MB,那么下一次垃圾回收会在 40 MB 时触发。这个过程会不断重复。
那么代码中到底是什么时候触发垃圾回收的呢?因为你一直在请求新的变量、新的结构体等。那么它是何时检查内存是否超出阈值的呢?当你了解内存分配器的工作原理后,答案变得相对简单。
当你请求新的内存页时,GC 堆触发检查会被执行。每当你请求新的内存块来存储变量时,系统会检查是否超出了内存阈值。如果超出阈值,垃圾回收器就会被触发。所以这是检查是否超出阈值的确切时机。总结一下,垃圾回收器会在以下三种情况下运行:当你从操作系统请求新的内存页时,如果超出阈值,垃圾回收器会运行;系统监视器基于时间间隔触发垃圾回收;以及手动调用垃圾回收器。除此之外,没有其他触发垃圾回收的时机。
Natalie Pistunovich:这里有什么实际的启示吗?
Jesús Espino: 嗯,我认为特别是理解堆内存的部分,会让你更好地理解什么时候会给垃圾回收器带来压力。举个例子,如果你不断地创建变量、释放它们、再创建它们、再释放它们,而且是在相同大小的变量范围内,你可能并不需要回收更多的页面,因为你可能会重复使用内存中的相同的 mspan 和页面。所以我不敢说这是否百分之百准确……但大致如此。
Natalie Pistunovich: 听起来好像如果我想要,不是说“破解”,但如果我想在某人的代码里探究一下……我在想,如果你在玩“夺旗赛”,你有这么一个程序片段,你试图找到它崩溃的地方……也许这是一个可以尝试的方向。虽然这不算是日常使用的实际场景,但……嗯,我还在试着把这个和别的东西联系起来。
Jesús Espino: 是的,这对我来说有点难,因为正如我所说,我在大多数情况下并没有发现这些知识有很多实际用途。对我来说,这更多是关于知识,理解它是如何运作的,并对类似的事情有更好的理解。
了解垃圾回收器什么时候会运行是有用的;可能在某些非常特定的实时应用中你需要知道这一点。但如果你是在做实时应用,几乎可以肯定你不会使用一个带有垃圾回收机制的语言。无论如何,对于这种情况,如果你需要知道“嘿,垃圾回收器在这段时间不会运行”,你可以先运行垃圾回收器,这样可以减少计时器自动运行的可能性。然后你可以控制堆的大小,确保在那段时间内堆不会翻倍。我不确定这是不是我会做的事情,可能我会试着禁用垃圾回收器,然后稍后再启用它……我不知道这在 Go 语言中是否可行。总之……
Natalie Pistunovich: 嗯,不,确实很有趣。
Jesús Espino: 是的,这有点……[听不清 00:41:34.02] 嗯,试着在这些问题上探究……我不知道你该怎么探究这个。我不知道……
Natalie Pistunovich: 就是一直用大量数组,直到发生点什么……
Jesús Espino: 是的,确实你可以生成大量数据,然后让垃圾回收器频繁运行。实际上,你可以尝试这种概念:“嘿,每当你翻倍内存,我就会触发一次垃圾回收器的运行。我可以轻松地翻倍内存,然后释放内存,再翻倍内存,再释放内存,重复这个过程。”这样会引发大量的垃圾回收循环。但是你需要玩弄这个技巧……是的,你可以玩弄这个,然后会稍微影响性能,因为你做了很多垃圾回收的工作,而不是实际的工作。
Natalie Pistunovich: 好的,酷。
Jesús Espino: 你甚至可以通过减少垃圾回收器所需的内存量来做得更好。你可以调整 Go 的 GC 参数,比如将它从 100 降到 10,这样每次达到 10% 或 1% 时,就会触发垃圾回收阶段运行,这会导致垃圾回收器一直在运行。这不是我推荐的做法,但……
Natalie Pistunovich: 是的,你给我提供了一个很好的过渡点,接下来我会提一个不太受欢迎的观点。但在此之前,我可以请你回顾一下这两集的内容,并快速总结一下你讲到的 10 个点吗?听到这些真的很有趣。
Jesús Espino: 好的,我可以做一个总结。其中一个是关于切片的内部工作原理,另一个是协程的合作性,协程之间的协作机制。再一个是语法的概念,抽象语法树(AST)以及它如何定义 Go 文件中的所有可能内容。还有一个是逃逸分析和内联优化,了解它们如何协作来优化内存使用。还有一个是 SSA 降级过程,这是将程序从与机器无关的 SSA 表示转化为与机器相关的表示的过程。TinyGo 如何利用 SSA 和 LLVM 技术,用相同的 Go 语言生成微控制器的二进制文件。然后是编译器和运行时如何协作,提供你在 Go 中使用的很多语法,比如向通道发送数据或者向 map 追加数据。还有就是程序的入口点,它不只是 main 函数,而是更复杂的一个过程。然后是内存分配器,它如何管理你的内存并从操作系统中回收页面。最后一个是垃圾回收器何时运行,垃圾回收器可以在哪三个地方运行,以及为什么会这样。我想就这些了。
Natalie Pistunovich: 嗯,我很想听听大家对这一系列节目的看法,无论是在 Go Time 播客的 Slack 频道,还是在 Twitter 上,大家觉得哪点让你感到震撼,或者哪一点对你有帮助,又或者哪一点让你产生了“啊哈”时刻。真的很酷。大家可以去看 Jesús 的所有演讲,所有链接都会列在节目说明里。非常感谢你加入我们。今天你有什么不太受欢迎的观点吗?
Jesús Espino: 嗯,这个问题有点难……我花了一些时间才想到一个……所以今天我没有不太受欢迎的观点。我还是坚持我不喜欢机械键盘的观点吧。
Natalie Pistunovich: 一个小小的不太受欢迎的观点是,两集在连续两天录制的节目中可以共享一个不太受欢迎的观点。
Jesús Espino: 是的。
Natalie Pistunovich: 太棒了,感谢你分享你的见解,祝你接下来的演讲一切顺利。
Jesús Espino: 是的,谢谢你。谢谢你邀请我。我在这里过得很愉快。所以,谢谢你。我真的很想知道更多人如何获取这些知识,并找到使用它们的方法。因为说实话,正如我所说,我是一名 Web 开发者,我的主要工作是开发 API。所以在更多系统层面的领域里,这种知识可能会有很大的用处。但对于构建 API 来说,Go 语言的表现已经非常顺畅了,你并不需要深入了解这些。
Natalie Pistunovich: 所有听众都可以分享你的想法。
Jesús Espino: 是的,让我们看看大家有什么反馈。
Natalie Pistunovich: 好的,谢谢大家收听。感谢 Jesús。再见。
Jesús Espino: 谢谢。再见。