01.
业务背景
在智联招聘平台,求职者和招聘者之间的高效匹配至关重要。招聘者可以发布职位寻找合适的人才,求职者则通过上传简历寻找合适的工作。在这种复杂的场景中,我们的核心目标是为双方提供精准的匹配结果。在搜索推荐场景下,候选人或职位列表会经历召回、粗排、精排和重排等多个阶段,从亿级别的候选集中筛选出最匹配的简历或职位进行展示。在召回阶段我们除了使用传统的规则召回外,还引入了向量召回方式。本次我们主要介绍一种向量召回方式:通过职位召回简历(JD2CV)。为了便于讨论,文中将职位简写为JD,简历简写为CV。
02.
向量召回实现方式
1. 模型训练样本选择:
正样本来自系统日志中有正向交互的JD CV对。负样本由三部分组成:一部分是batch内负采样,第二部分来自全库的随机负采样,全库采样能够更好地模拟实际召回场景。第三部分,我们根据业务规则,选取了一些hard负样本,以提高模型的训练效果。
2. 模型结构:
我们采用了双塔模型结构,分别处理JD和CV的文本信息,将其映射为低维向量。通过计算向量间的相似度,并应用对比学习的损失函数进行优化,使得相关的JD和CV向量距离更近,而非相关的则距离更远。这种方式能有效提高匹配的精度。
3. 模型离线测评:
第一种评估方式是使用模型预测给定的正负样本对,进而计算AUC和JD维度的GAUC。然而,这种评估方式局限于有限样本集,难以全面反映召回模型的真实表现。为了获得更接近线上环境的评估结果,我们采用了一种新的评估方式,分为两个步骤:首先,进行实际的召回操作;其次,对召回结果进行详细评估。
为了支持这一流程,我们调研了多种向量数据库,最终选择了Milvus。主要原因有三点:
易用性:Milvus提供了简洁的API接口,文档丰富,开发者可以快速上手并集成。同时,它支持标量过滤与向量相似性搜索的结合,实现更灵活的混合搜索。
高性能:得益于优化的算法和索引结构,Milvus能够高效地处理大规模数据的向量检索任务,满足我们的性能需求。
社区支持:Milvus拥有活跃的社区和丰富的生态系统,提供了多语言支持和工具链资源,帮助开发者快速解决问题。
在评估召回结果时,我们采用了两种主要方法:
体感评估:对不同模型召回结果中各自独有的部分,使用大模型进行体感标注,统计标注结果看哪个模型体感表现更好。
量化指标:通过统计召回率和精准率等关键指标,评估模型在实际召回任务中的表现。
03.
Milvus使用及具体评估过程
1. Milvus的部署:我们使用Milvus官方提供的docker-compose方式进行部署,使用的是2.4.5版本。评估过程中,采样了百万级别的CV数据,单节点部署完全可以满足这一规模需求。同时还部署了管控平台Attu,便于加载和删除数据集合,修改索引类型,以及进行向量搜索等操作。
为便于数据的导入和召回测试,我们还开发了相应的数据导入和召回接口,使评估流程更加自动化和便捷。
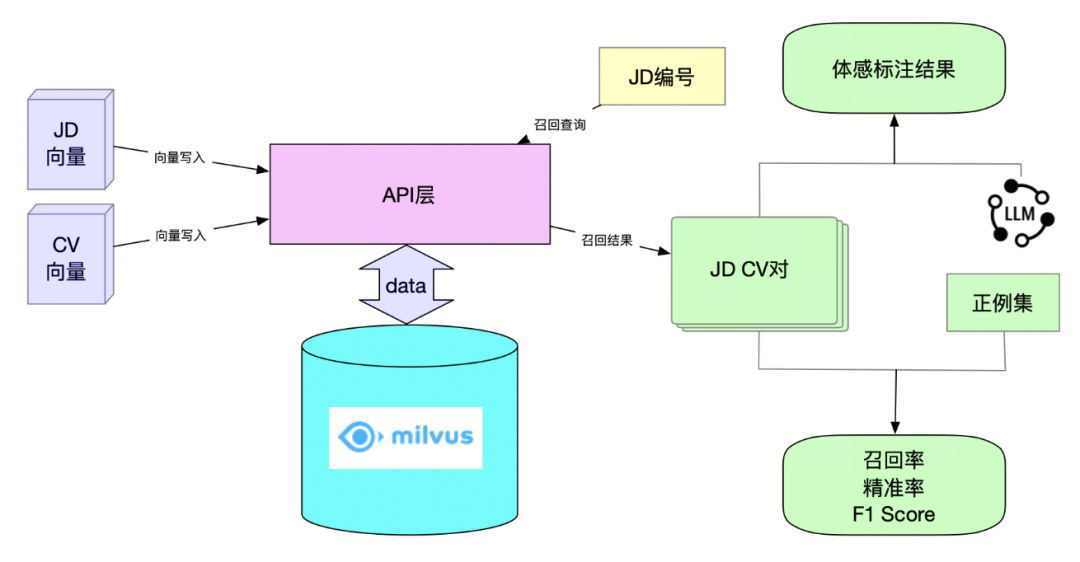
2. 数据准备:在Milvus和相关接口部署完成后,我们根据线上JD的流量分布情况,按照城市粒度采样了一些JD数据,并使用模型生成相应的JD向量。接着,我们对采样城市的全量CV进行向量生成,并通过写入接口将数据存储在Milvus中。为了确保评估的准确性,我们选择了FLAT类型索引,保证能够100%召回相关数据。
3. 召回过程:通过JD编号,我们从JD集合中查询出相应的JD向量,然后根据该向量从CV集合中召回最相似的topK CV。相似度计算采用内积作为度量标准,最终得到一组JD与CV的匹配对。
4. 召回结果评估:我们采用了两种方式对召回结果进行评估。首先,对不同模型各自召回集中独有的部分进行大模型的体感标注。其次,根据正向行为记录的JD-CV对构建正例集,并通过该正例集评估召回率和精准率等指标,最终对模型进行综合评估。
使用Milvus过程中遇到的一些问题:
1. 索引类型选择问题:在分析召回结果时,我们发现一些模型预测分数较高的记录并未被成功召回,而一些分数较低的记录却被召回了。经过排查,问题出在索引类型上。我们最初使用的是IVF_FLAT索引,该类型能够提高查询速度,但无法保证100%的召回率。通过查询官网文档,我们将索引类型更改为FLAT,成功解决了这一问题。
2. 条件查询问题:我们在使用Python SDK进行条件查询时,发现传入的filter参数无法生效。经过与社区的沟通和排查,最终将filter参数改为expr参数后,问题得以解决。
04.
总结
Milvus作为一款功能强大且易于部署的向量数据库,极大地帮助我们优化了召回评估流程,显著节省了时间成本,并为模型上线前提供了更加充分的评估依据。在未来,我们计划继续探索更多的应用场景,进一步发掘Milvus的潜力,并通过其丰富的功能进一步提升业务的召回效率和准确性。
本文作者:
张晓 算法工程师
李伟鹏 资深算法工程师
推荐阅读