找工作:笔试+面试
笔试:选择题+编程题(OJ onlin可能现场写一个算法


死磕代码+注意多画图和思考
理解了写不出代码就是没有完全理解。
多画图多思考多写代码
好的命名:让人一眼看出是啥,方便维护
做好备注
慢就是快
可以把有的报错进行注释
有时候实在找不出错误可以让AI帮你解读代码,然后找出错误。
建议代码写一点测试一点+调试
当程序输出结果不对时,可以用两种方式来检查代码
①结合测试样例,手动模拟你的程序
②打印一些关键的值
如果OJ执行结果:超出时间限制。可能有两种情况:
①代码有死循环
②超出时间限制O(n)

课后作业+总结博客+维护gitee
宁可累死自己,,也要卷死同学
刷题网站:牛客网+力扣leetcode
没有思路,多做题,学习别人的方法。
学习本来就是站在巨人的肩膀上,并且越学越聪明。
原理搞清楚了,代码就是不难的。
画出逻辑图了(跟图走和变量也很清晰),代码写不出来就是图没画到位。

链表要注意最后一个节点的next设置位NULL,表示链表的结束,这是链表的定义。
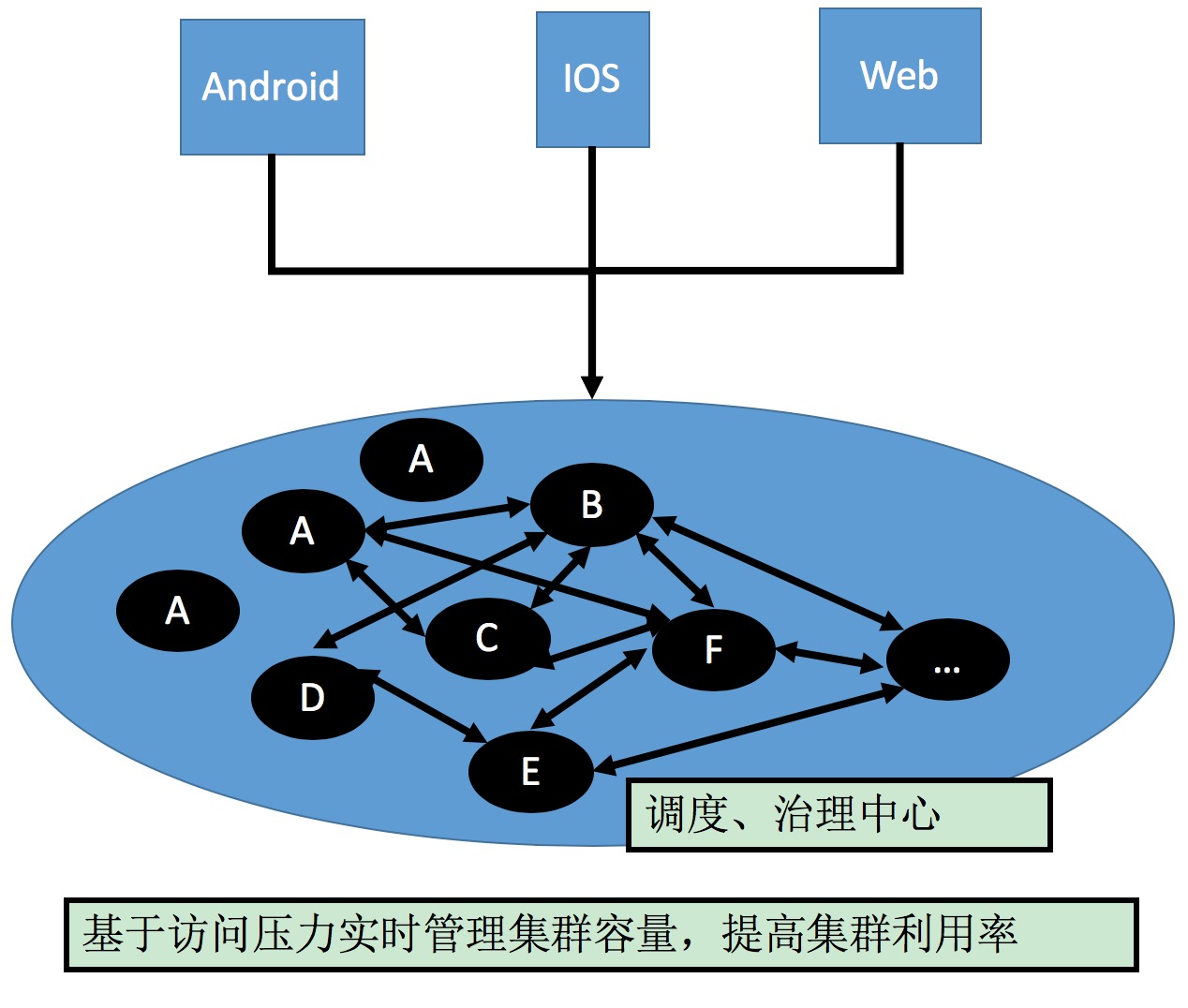
0 前言
数据结构?
实现一些项目,需要在内存中将数据存储起来。
例如:通讯录中,每个人的信息存储起来。可以用数组;链表;树...,用来干嘛
算法?
用一系列的计算步骤,将输入数据转换为输出结果。
排序、查找、去重...
推荐算法(抖音)
1 时间复杂度+空间复杂度
1.1算法效率
衡量算法好不好,从两个方面:时间(运行快慢)和空间(额外需要的空间)

1.2时间复杂度
算法的时间复杂度是一个函数(数学中的带有未知数的函数表达式)
不能计算具体的时间,它和你的机器有关。

所以计算基本操作的执行次数。

时间复杂度的函数式:F(N)=N*N+2*N+10
时间复杂度:O(N*N)
N=10,F(N)=130
N=100,F(N)=10210
N=1000,F(N)=1002010
N越大,后面的项对结果的影响是越小的。
实际中,我们只需要计算出大概执行次数,即大O渐进表示法。

O(N)是估算的方法,不是精确的方法。
O(N)=N,这里精确的是2N+10

F(N)=M+N
O(M+N),M和N的大小关系未知。
若M>>N ->O(M)
若N>>M ->O(N)
一般情况,时间复杂度计算时未知数都是用的N,但有时也可以用M、N等等。

O(1):并不是1次,而是运行常数次。
![]()
while(*str)
{
if(*str==character)
return str;
else
++str;
}
比如hello world

当一个算法随着输入不同,时间复杂度不同,时间复杂度做悲观预期,看最坏的情况。
一般不看平均,平均只是来看一下大概是什么样子。

计算冒泡排序的时间复杂度

精确计算:F(n)=n+(n-1)+(n-2)+...+1=n*(n-1)/2
时间复杂度:O(N^2) 只看对结构影响最大的。
计算二分查找的时间复杂度

算时间复杂度不能之去看是几层循环,还要去看它的思想。
时间复杂度:O(log N)
如何计算?
最好的情况:O(1)
最坏的情况:(找不到)O(log N)
1*2*2*2...=N2
2^X=N ->X=log N
找了多少次就除以2,除了多少次2就是找了多少次。

N个数中查找 大概查找次数
1000 10 (2^10=1024,3个0)
100w 20(2^20~100w,6个0)
10亿 30(9个0)
二分查找的缺陷就是排序,排序的消耗很大。
所以之后学树->二叉树->搜索树->平衡搜索二叉树->AVLTree->RBTree
哈希表,B树系列
实例6:递归算法次数=递归次数*每次递归调用的次数


时间复杂度:O(N)
实例8:斐波那契数列
递归算法次数=递归次数*每次递归调用的次数


 ,上面是计算递归次数。每次递归调用的次数是常数次。
,上面是计算递归次数。每次递归调用的次数是常数次。
x远小于2^N,x是指这里会缺一些递归调用,会提前递归结束
时间复杂度:O(2^N)
斐波那契数列的递归写法完全是一个实际中没用的算法,因为太慢了。写循环。
1.3空间复杂度
空间复杂度也是一个数学函数表达式,额外的空间
算的是变量的个数,
实例1:冒泡排序法的空间复杂度

定义变量:end,i,exchange
空间复杂度O(1),常数个
算额外的空间大小,自己定义的变量的个数

空间复杂度:O(N)
时间复杂度:O(N),比递归算法快了很多。
实例3:阶乘的时间复杂度
看递归的深度

额外的变量,没定义,但是有栈帧

空间复杂度:O(N)
实例8:斐波那契数列的空间复杂度


空间复杂度:O(N),注意并不是O(2^N)
空间是可重复利用,不累计的
时间是一去不复返,累计的
1.4 复杂度的OJ练习
1.消失的数字面试题 17.04. 消失的数字 - 力扣(LeetCode)

思路1:排序(看后一个数是不是前一个数加1)
快排时间复杂度O(n*logN),本题不满足
思路2:(0+1+2+3...+n)-(a[0]+a[1]+...a[n-1])
时间复杂度是O(n)
思路3:建立n+1的数组
数组中值是几就在第几个未知写这个值

思路4:异或
给一个值x=0
x先跟[0,n]的所有值异或,x再跟数组中每个值异或,最后x就是缺的那个数字。
一道题有多种方法,线分析时间复杂度,选择最优的方式即可,这样就是复杂度在实际中的应用。
异或的性质
假设N为任意实数
性质1:0 ^ N = N
性质2:N ^ N = 0
性质3:异或运算满足交换律与结合律
重点:我们可以将异或运算理解为二进制的无进位相加!也就是说,当两个数异或的时候,如果某一位同为1,则该位为0并且不向前进位。
int missingNumber(int* nums,int numsSize){int x=0;//跟[0,n]异或for(int i=0;i<=numsSize;++i){x^=i;}//再跟数组中值异或for(int i=0;i<numsSize;++i){x^=nums[i];}return x;
}2.旋转数组OJ链接189. 轮转数组 - 力扣(LeetCode)



思路1:暴力求解,旋转k次
时间复杂度:O(N*K),每次挪动n次
空间复杂度:O(1),用的同一块空间,没有开辟多余的空间。
思路2:开辟额外的空间,以空间换时间

借助一个temp数组空间
时间复杂度:O(N)
空间复杂度:O(N)
思路3:非常神奇的算法,双赢的方法,时间空间都考虑(做题做多了能想到了 )

时间复杂度O(N),空间复杂度O(1)

要是写代码时想不清楚边界可以用具体的数字。
void Reverse(int *nums,int left,int right){//逆置小菜一碟,也可以直接用内置函数reversewhile(left<right)//left,right交换,一个加加一个减减{int temp=nums[left];nums[left]=nums[right];nums[right]=temp;++left;--right;}}void rotate(int* nums, int numsSize,int k) {//前k-1个数逆置Reverse(nums,0,numsSize-k-1);//后K个数逆置Reverse(nums,numsSize-k,numsSize-1);//全部进行逆置Reverse(nums,0,numsSize-1);}
#include<bits/stdc++.h>
2 顺序表_链表
线性表、顺序表、链表、顺序表和链表的区别和联系
常见的线性表:顺序表、链表、栈、队列、字符串
非线性:树
2.1 顺序表
顺序表就是可以动态增加的数组。
顺序表本质上就是数组,但它分静态和动态的,存储是连续的
数字是从头开始存储,并且是连续的

数据结构的定义
#pragma once //预处理指令,用于使当前头源文件在单次编译中只被包含一次
#define N 1000
typedef int SLDataType;//重命名,可以int,double,ContactInfo...
//静态顺序表
typedef struct SeqList
{SLDataType a[N];int size;//表示数组中存储了多少个有效的数组
}SL;//接口函数--命名风格是跟着STL走的,STL中有一些数据结构的取名规范
//静态的特点:如果满了就不让插入 缺点:给多少合适?这个很难确定
//n给小了不够用,n给大了浪费
void SeqListInit(SL* ps);//初始化
void SeqListPushBack(SL* ps,SLDataType x);//尾插
void SeqListPopBack(SL* ps);//尾删
void SeqListPushFront(SL* ps,SLDataType x);//头插
void SeqListPopFront(SL* ps);//头删我们实现动态的
typedef int SLDataType;//重命名,可以int,double,ContactInfo...
//动态顺序表
typedef struct SeqList
{SLDataType* a;int size;//表示数组中存储了多少个有效的数组int capacity;//数组实际能存数据的空间容量是多大的
}SL;//接口函数--命名风格是跟着STL走的,STL中有一些数据结构的取名规范
void SeqListInit(SL* ps);//初始化
void SeqListPushBack(SL* ps,SLDataType x);//尾插
void SeqListPopBack(SL* ps);//尾删
void SeqListPushFront(SL* ps,SLDataType x);//头插
void SeqListPopFront(SL* ps);//头删
函数传参,形参是实参的拷贝,形参的改变不会影响实参。传地址所以要传指针。
所以上面的接口函数传的都是指针SL* ps.
2.1.1接口实现
尾插法

可能的情况:
1.整个顺序表没有空间 空间不够 扩容
2.空间足够,直接插入数据即可
#pragma once //预处理指令,用于使当前头源文件在单次编译中只被包含一次
#define N 1000
typedef int SLDataType;//重命名,可以int,double,ContactInfo...
//动态顺序表
typedef struct SeqList
{SLDataType* a;int size;//表示数组中存储了多少个有效的数组int capacity;//表示实际能存数据的空间容量是多少
}SL;//打印,把顺序表中的东西打印一下
void SeqListPrint(SL* ps)
{for(int i=0;i<ps->size;++i){printf("%d",ps->a[i]);}printf("\n");
}//初始化
void SeqListInit(SL* ps)
{ps->a=NULL;ps->size=ps->capacity=0;
}//销毁
void SeqListDestory(SL* ps)
{free(ps->a);//free只是free指针指向的空间,把空间释放ps->a=NULL;//野指针ps->capacity=ps->size=0;
}//尾插
void SeqListPushBack(SL* ps,SLDataType x);
{//空间不够->扩容if(ps->size==ps->capacity)//空间满了,扩容,扩的少后面可能不够,扩多了用不完;取一个适中的值2倍{int newcapacity=ps->capacity==0?4:ps->capacity*2;//先判断capacity是否是0,如果是直接给4,否则给4倍SLDataType* temp=(SLDataType*)realloc(ps->a,newcapacity*sizeof(SLDataType));if(tmp==NULL){printf("realloc fail\n");exit(-1);}ps->a=tmp;ps->capacity=newcapacity;}//空间足够,直接插入数据即可ps->a[ps->size]=x;ps->size++;
}//尾删
void SeqListPopBack(SL* ps)
{/*//温柔的方式if(ps->size>0){ps->size--;//size标识了有几个数据}*///粗暴的方式assert(ps->size>0);//断言,如果当前满足就没事,否则在标准错误上像是错误消息,并终止程序执行。ps->size--;
}//接口函数
void SeqListPrint(SL* ps);//打印
void SeqListInit(SL* ps);//初始化
void SeqListDestory(SL* ps);//销毁
void SeqListPushBack(SL* ps,SLDataType x);//尾插
void SeqListPopBack(SL* ps);//尾删
void SeqListPushFront(SL* ps,SLDataType x);//头插
void SeqListPopFront(SL* ps);//头删尾删

头插法

把所有的往后挪,这里需要主要空间容量,是否满了

头删法:往前挪

//头删法
void SeqListPopFront(SL* ps)
{assert(ps->size>0);while(begin<ps->size){ps->a[begin-1]=ps->a[begin];begin++;}
}#pragma once //预处理指令,用于使当前头源文件在单次编译中只被包含一次
#define N 1000
typedef int SLDataType;//重命名,可以int,double,...
//动态顺序表
typedef struct SeqList
{SLDataType* a;int size;//表示数组中存储了多少个有效的数组int capacity;//表示实际能存数据的空间容量是多少
}SL;//打印,把顺序表中的东西打印一下
void SeqListPrint(SL* ps)
{for(int i=0;i<ps->size;++i){printf("%d",ps->a[i]);}printf("\n");
}//初始化
void SeqListInit(SL* ps)
{ps->a=NULL;ps->size=ps->capacity=0;
}//销毁
void SeqListDestory(SL* ps)
{free(ps->a);//free只是free指针指向的空间,把空间释放ps->a=NULL;//野指针ps->capacity=ps->size=0;
}//检查增容
void SeqListCheckCapacity(SL* ps)
{//空间不够->扩容if(ps->size==ps->capacity)//空间满了,扩容,扩的少后面可能不够,扩多了用不完;取一个适中的值2倍{int newcapacity=ps->capacity==0?4:ps->capacity*2;//先判断capacity是否是0,如果是直接给4,否则给4倍SLDataType* temp=(SLDataType*)realloc(ps->a,newcapacity*sizeof(SLDataType));if(tmp==NULL){printf("realloc fail\n");exit(-1);}ps->a=tmp;ps->capacity=newcapacity;}
}//尾插
void SeqListPushBack(SL* ps,SLDataType x);
{//空间不够,扩容SeqListCheckCapacity(ps);//空间足够,直接插入数据即可ps->a[ps->size]=x;ps->size++;
}//尾删
void SeqListPopBack(SL* ps)
{/*//温柔的方式if(ps->size>0){ps->size--;//size标识了有几个数据}*///粗暴的方式assert(ps->size>0);//断言,如果当前满足就没事,否则在标准错误上像是错误消息,并终止程序执行。ps->size--;
}//头插法
void SeqListPushFront(SL* ps,SLDataType x)
{SeqListCheckCapacity(ps);//检查增容//挪动数据int end=ps->size-1;while(end>=0)//括号中的是结束条件{ps->a[end+1]=ps->a[end];--end;}ps->a[0]=x;ps->size++;
}//头删法
void SeqListPopFront(SL* ps)
{assert(ps->size>0);//挪动数据int begin=0;while(begin<ps->size-1){ps->a[begin]=ps->a[begin+1];begin++;}
}//接口函数
void SeqListPrint(SL* ps);//打印
void SeqListInit(SL* ps);//初始化
void SeqListDestory(SL* ps);//销毁
void SeqListCheckCapacity(SL* ps);//空间检查增容
void SeqListPushBack(SL* ps,SLDataType x);//尾插
void SeqListPopBack(SL* ps);//尾删
void SeqListPushFront(SL* ps,SLDataType x);//头插
void SeqListPopFront(SL* ps);//头删
int SeqListFind(SL* ps,SLDataType x);//查找,找到返回x下标,否则返回-1
void SeqListInsert(SL* ps,int pos,SLDataType x);//指定下标pos处插入
void SeqListErase(SL* ps,int pos);//删除指定位置pos的数据在pos处插入,要检查位置是否合法

位置合法,挪动,并且挪动时候也要考虑是否越界的问题。


//在pos位置插入一个数据x
void SeqListInsert(SL* ps,int pos,SLDataType x)
{//判断pos位置是否合法,是否越界//温柔的方式// if(pos>ps->size||pos<0)// {// printf("pos invalid\n");// return;//温柔的方式// }//暴力的方式:断言assert(pos<=ps->size && pos>=0);//扩容SeqListCheckCapacity(ps);int end=ps->size-1;//挪动数据while(end>=pos){ps->a[end+1]=ps->a[end];--end;}//把数放进来,size++ps->a[pos]=x;ps->size++;
}
接下来可以用指定位置pos处插入元素修改上面的头插法和尾插法
//头插法
void SeqListPushFront(SL* ps,SLDataType x)
{ /*方式1SeqListCheckCapacity(ps);//检查增容//挪动数据int end=ps->size-1;while(end>=0)//括号中的是结束条件{ps->a[end+1]=ps->a[end];--end;}ps->a[0]=x;ps->size++;*///方式2:直接调用上面的函数SeqListInsert(ps,0,x);
}//尾插
void SeqListPushBack(SL* ps,SLDataType x);
{/*方式1//空间不够,扩容SeqListCheckCapacity(ps);//空间足够,直接插入数据即可ps->a[ps->size]=x;ps->size++;*///方式2:直接调用上面的函数SeqListInsert(ps,ps->size,x);
}
移除pos处的元素

//移除pos处的元素
void SeqListErase(SL* ps,int pos)
{assert(ps>=0 && pos<ps->size);int begin=pos+1;while(begin<ps->size){ps->a[begin-1]=ps->a[begin];++begin;}
}根据删除pos处的元素可以修改头删法和尾插法
//头删法
void SeqListPopFront(SL* ps)
{/*方式1assert(ps->size>0);//挪动数据int begin=0;while(begin<ps->size-1){ps->a[begin]=ps->a[begin+1];begin++;}*///方式2 调用接口函数SeqListEraseSeqListErase(ps,0);}//尾删
void SeqListPopBack(SL* ps)
{/*----------方式1-----------// //温柔的方式// if(ps->size>0){// ps->size--;//size标识了有几个数据// }//粗暴的方式assert(ps->size>0);//断言,如果当前满足就没事,否则在标准错误上像是错误消息,并终止程序执行。ps->size--; *///方式2 调用接口函数SeqListEraseSeqListErase(ps,ps->size-1);
}
接口就是函数。(接口就是提供给别人用的)
全部的代码
#pragma once //预处理指令,用于使当前头源文件在单次编译中只被包含一次
#define N 1000
typedef int SLDataType;//重命名,可以int,double,...
//动态顺序表
typedef struct SeqList
{SLDataType* a;int size;//表示数组中存储了多少个有效的数组int capacity;//表示实际能存数据的空间容量是多少
}SL;//打印,把顺序表中的东西打印一下
void SeqListPrint(SL* ps)
{for(int i=0;i<ps->size;++i){printf("%d",ps->a[i]);}printf("\n");
}//初始化
void SeqListInit(SL* ps)
{ps->a=NULL;ps->size=ps->capacity=0;
}//销毁
void SeqListDestory(SL* ps)
{free(ps->a);//free只是free指针指向的空间,把空间释放ps->a=NULL;//野指针ps->capacity=ps->size=0;
}//检查增容
void SeqListCheckCapacity(SL* ps)
{//空间不够->扩容if(ps->size==ps->capacity)//空间满了,扩容,扩的少后面可能不够,扩多了用不完;取一个适中的值2倍{int newcapacity=ps->capacity==0?4:ps->capacity*2;//先判断capacity是否是0,如果是直接给4,否则给4倍SLDataType* temp=(SLDataType*)realloc(ps->a,newcapacity*sizeof(SLDataType));if(tmp==NULL){printf("realloc fail\n");exit(-1);}ps->a=tmp;ps->capacity=newcapacity;}
}//尾插
void SeqListPushBack(SL* ps,SLDataType x);
{//空间不够,扩容SeqListCheckCapacity(ps);//空间足够,直接插入数据即可ps->a[ps->size]=x;ps->size++;
}//尾删
void SeqListPopBack(SL* ps)
{/*----------方式1-----------// //温柔的方式// if(ps->size>0){// ps->size--;//size标识了有几个数据// }//粗暴的方式assert(ps->size>0);//断言,如果当前满足就没事,否则在标准错误上像是错误消息,并终止程序执行。ps->size--; *///方式2 调用接口函数SeqListEraseSeqListErase(ps,ps->size-1);
}//头插法
void SeqListPushFront(SL* ps,SLDataType x)
{SeqListCheckCapacity(ps);//检查增容//挪动数据int end=ps->size-1;while(end>=0)//括号中的是结束条件{ps->a[end+1]=ps->a[end];--end;}ps->a[0]=x;ps->size++;
}//头删法
void SeqListPopFront(SL* ps)
{/*方式1assert(ps->size>0);//挪动数据int begin=0;while(begin<ps->size-1){ps->a[begin]=ps->a[begin+1];begin++;}*///方式2 调用接口函数SeqListEraseSeqListErase(ps,0);}//查找
int SeqListFind(SL* ps,SLDataType x)
{//找到目标值,返回下标for(int i=0;i<ps->size;i++){if(ps->a[i]==x){return i;}}//没找到,返回-1return -1;
}//在pos位置插入一个数据x
void SeqListInsert(SL* ps,int pos,SLDataType x)
{//判断pos位置是否合法,是否越界//温柔的方式// if(pos>ps->size||pos<0)// {// printf("pos invalid\n");// return;//温柔的方式// }//暴力的方式:断言assert(pos<=ps->size && pos>=0);//扩容SeqListCheckCapacity(ps);int end=ps->size-1;//挪动数据while(end>=pos){ps->a[end+1]=ps->a[end];--end;}//把数放进来,size++ps->a[pos]=x;ps->size++;
}//移除pos处的元素
void SeqListErase(SL* ps,int pos)
{assert(ps>=0 && pos<ps->size);int begin=pos+1;while(begin<ps->size){ps->a[begin-1]=ps->a[begin];++begin;}
}//接口函数
void SeqListPrint(SL* ps);//打印
void SeqListInit(SL* ps);//初始化
void SeqListDestory(SL* ps);//销毁
void SeqListCheckCapacity(SL* ps);//空间检查增容
void SeqListPushBack(SL* ps,SLDataType x);//尾插
void SeqListPopBack(SL* ps);//尾删
void SeqListPushFront(SL* ps,SLDataType x);//头插
void SeqListPopFront(SL* ps);//头删
int SeqListFind(SL* ps,SLDataType x);//查找,找到返回x下标,否则返回-1
void SeqListInsert(SL* ps,int pos,SLDataType x);//指定下标pos处插入
void SeqListErase(SL* ps,int pos);//删除指定位置pos的数据2.1.2 面试OJ题目
OJ分类:
1.IO型:考试IO型居多
①我们要自己写头文件、main函数等等
②测试用例输入:要scanf获取
③测试结果:printf输出
2.接口型:给了你一个函数,你实现就可以
①不需要写头文件、主函数
②提交了以后,会跟OJ服务器上的其他代码进行合并,再编译运行
测试用例:通过参数过来
结果:一般是通过返回值拿的,也有可能是输出型参数
可能会有多组测试用例
【例2】数组中数字出现的数字

这里要return一个2个数的数组。
int* arr=(int*)malloc(sizeof(int)*2)
*returnSize=2;//要指出输出是多少
return arr;
练习
【练习1】移除元素(把数组中的元素3移除)

思路1:找多所有的val,依次挪动数据覆盖删除
时间复杂度:O(N^2),最坏的情况,数组中的值大部分甚至全部都是val。
如何优化时间复杂度到O(N)?
思路2:依次遍历nims数组,把不是val的数,放到tmp,再把tmp数组的值拷贝回去


时间复杂度2N:O(N)
空间复杂度:O(N)
用空间换时间
如何优化空间复杂度到O(1)?
思路3:不借助数组,而是直接放到原数组
src去找nums数组中不等于val的值,放到dst指向的位置去,再++src,++dst

int removeElement(int* nums, int numsSize, int val) {int src=0,dst=0;while(src<numsSize){if(nums[src]!=val)//不等于val{nums[dst]=nums[src];src++;dst++;}else{src++;}}return dst;
}【练习2】删除有序数组中的重复项26. 删除有序数组中的重复项 - 力扣(LeetCode)
不适用额外的数组空间。
思路1:双指针法
思路2:暴力双循环
【练习3】合并两个有序数组88. 合并两个有序数组 - 力扣(LeetCode)

学过的知识:归并排序(给一个更大的数组)谁小谁下来

思路2:归到新数组再拷回去,空间复杂度O(N)
①谁小放谁,数组中的元素可能被覆盖
②谁大放谁

2.2 链表
2.2.1 为什么用链表(针对顺序表的缺陷)
1 顺序表
a[i]等价于*(a+i)
优点:支持随机访问。
有些算法,需要结构支持随机访问。比如二分查找,比如优化的快排等。
顺序表存在两大缺陷:
1.空间不够了需要增容,需要付出代价
realloc有两种方法:原地扩容;异地扩容
2.避免频繁扩容,满了基本都是扩2倍,可能会导致一定的空间浪费
3.顺序表要求数据从开始位置连续存储
那么在头部或者中间位置插入数据,就需要挪动数据,效率不高
2 链表
针对顺序表的缺陷,就设计出链表。

链表也要付出一些代价,需要多余的存储一些指针。它不能随机访问。

按需申请空间,不用了就释放空间(更合理的使用空间)
优点:
头部中间插入数据,不需要挪动数据,不存在空间浪费。
缺点:
①每存一个数据,都要存一个指针去链接后面的数据节点
②不支持随机访问
顺序表和链表都存在,她两是互补的,各有优势。
2.2.2 链表分类及单链表
共有八种细分的结构。
尽管双链表完胜单链表,但题目一般出在单链表,也有价值。
 哨兵位的头节点,不存储有效数据。
哨兵位的头节点,不存储有效数据。


最优价值的两种链表

1.单链表

#prama once
#include <stdio.h>
typedef int SLTDataType;//动态申请
struct SListNode
{SLTDataType data;struct SListNode* next;
};
上面的是逻辑图,是想象出来的,实际上是没有箭头的。

物理中,phead存的是首元素的地址。
学链表要想清除逻辑地址和物理地址。

实际上是没有箭头的。
物理结构就是在内存中实在的如何存储。a
打印列表,列表的遍历。
void SListPrint(SLTNode*phead)
{SLTNode* cur=head;while(cur!=NULL){printf("%d->",cur->data);cur=cur->next;//next存的是地址}
}尾插SListPushBack()

二级指针传参的注意事项

形参的改变不会影响实参的改变。
实参是int,要改变实参,需要传int*。函数里面解引用(如函数中的*px=10)去改变。

传参:如果你要改变int,需要传int*的地址;如果要改变int*,需要传int**的地址。
改变的传二级指针。解引用 才能改变外面的int*.
//尾插 涉及到二级指针
void SListPushBack(SLTNode** pphead,SLTDataType x)
{//①申请新的节点//②插入,要找到尾tail//如果是空的列表,开始找tail的逻辑就有问题。//找到尾节点SLTNode* newnode=(*SLTNode)malloc(sizeof(SLTNode));newnode->data=x;newnode->next=NULL;if(*pphead==NULL)//链表中一个节点都没有{*pphead=newnode;}else{SLTNode *tail=*pphead;//指向第一个节点while(tail->next!=NULL){tail=tail->next;}//插入tail->next=newnode; }}测试

不带头节点的链表一般更适合于OJ的题目。更方便。
全部代码
#prama once
#include <stdio.h>
typedef int SLTDataType;//动态申请
//单链表
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;//打印
void SListPrint(SLTNode*phead)
{SLTNode* cur=head;while(cui!=NULL){printf("%d->",cur->data);cur=cur->next;}
}//尾插 涉及到二级指针
void SListPushBack(SLTNode** pphead,SLTDataType x)
{//①申请新的节点//②插入,要找到尾tail//如果是空的列表,开始找tail的逻辑就有问题。//找到尾节点SLTNode* newnode=(*SLTNode)malloc(sizeof(SLTNode));newnode->data=x;newnode->next=NULL;if(*pphead==NULL)//链表中一个节点都没有{*pphead=newnode;}else{SLTNode *tail=*pphead;//指向第一个节点while(tail->next!=NULL){tail=tail->next;}//插入tail->next=newnode; }
}void SListPrint(SLTNode*phead);
void SListPushBack(SLTNode* head,SLTDataType x);单链表的问题需要先找到尾。

注意传的二级指针。



还有其他的方式:引用、头节点、传指针的引用
while(tail->next!=NULL)
这里括号中我们想的是循环结束的条件,但是要写循环继续的条件。
2.接口函数
①打印
//打印
void SListPrint(SLTNode*phead)
{SLTNode* cur=head;while(cui!=NULL){printf("%d->",cur->data);cur=cur->next;}printf("NULL\n");
}②创建一个新节点
SLTNode* BuylistNode(SLTDataType x)
{SLTNode* newnode=(*SLTNode)malloc(sizeof(SLTNode));//检查生成是否成功,这里是从堆生成的,空间很大。所以一般会生成成功if(newnode==NULL){printf("malloc fail\n");//说明此时空间已经不打了,之后直接结束程序exit(-1);}newnode->data=x;newnode->next=NULL;return newnode;
}③头插
//头插法,非常简单,不用挪动数据
void SListPushFront(SLTNode** pphead,SLTDataType x)
{// SListNode* newnode=(SLTNode*)malloc(sizeof(SLTNode));// newnode->data=x;SListNode* newnode=BuylistNode(x);//生成节点newnode->next=*pphead;*pphead=newnode;
}④尾插(开一个哨兵位的头节点方便)
//尾插 涉及到二级指针
void SListPushBack(SLTNode** pphead,SLTDataType x)
{//①申请新的节点//②插入,要找到尾tail//如果是空的列表,开始找tail的逻辑就有问题。//找到尾节点// SLTNode* newnode=(*SLTNode)malloc(sizeof(SLTNode));// newnode->data=x;// newnode->next=NULL;//上面三行共同的操作直接弄成一个函数,然后调用SListNode* newnode=BuylistNode(x);if(*pphead==NULL)//链表中一个节点都没有{*pphead=newnode;}else{SLTNode *tail=*pphead;//指向第一个节点while(tail->next!=NULL){tail=tail->next;}//插入tail->next=newnode; }
}⑤尾删(借助画图来理解)

//尾删
//还要考虑删除后列表是不是就是空的
//单链表的缺陷,不好找到前一个节点
void SListPopBack(SLTNode** pphead)
{//温柔一点if(*pphead==NULL){return;}//粗暴一点// assert(*pphead!=NULL);SLTNode* tail=*pphead;//判断是否当前删除的是不是最后一个元素if((*pphead)->next==NULL){ free(*pphead);*pphead=NULL;}else{SLTNode* prev=NULL;while(tail->next!=NULL)//如果想少定义一个变量的话就用tail->next->next{ prev=tail;//尾节点的前一个节点tail=tail->next;}free(tail);//free是把节点还给系统tail=NULL;prev->next=NULL;}
}⑥头删

//头删
void SListPopFront(SLTNode** pphead)
{/*//方式1:分情况讨论if(*pphead=NULL)//没有节点{return ;}//assert((*pphead)!=NULL);if((*pphead)->next==NULL)//一个节点{free(*pphead);//*pphead<==>实参plist*pphead=NULL;}else{*pphead=(*pphead)->next;}*/assert((*pphead)!=NULL);//列表为空时暴力处理//上面的代码可以简化SListNode* next=(*pphead)->next;//保存它的下一个节点free(*pphead);//释放第一个节点空间*pphead=next;}⑦查找
SListNode* SListFind(SListNode* phead,SLTDataType x)
下面的是查找时可能有多个值

查找也可以进行修改

因为find返回的是节点的指针,所以修改就会比较方便。

这里pos=SListFind(),可以找到3所在的pos指针。但是存在一个问题,它前面的节点不知道,这就是单链表的局限。

⑧指定位置插入
在pos位置之前插入一个节点
单链表不适合前插,找前一个是需要代价的。
//在pos位置之前插入一个数据
void SListInsert(SLTNode**pphead,SLTNode* pos,SLTDataType x)
{SLTNode* newnode=BuylistNode(x);if(*pphead==pos)//pos位置是第一个元素节点{//头插法newnode->next=*phead;*phead=newnode;}else{//找到pos的前一个位置,但要考虑是否有前节点,即头插//也可以直接调用SLTNode* posPre=*pphead;while( posPre->next!=pos){posPre=posPre->next;}posPre->next=newnode;newnode->next=pos;}}单链表在pos位置之后插入一个节点
2.2.3 单链表的OJ题(增删查改的变形)
不用想着省几个变量,选择逻辑清晰的方式。
会解决错误。考试时候也不能用调试。
解决bug的tips
①走读代码。
②VS上进行调试。
如果还是找不出来,就出去VS上进行调试。【见下题1】
考试没有测试用例的话:链表一般是看头、尾、中间。
单链表的缺陷还是很多,单纯的单链表增删查改意义不大。
链表存储数据还要看双向链表。
为什么还要学习单链表?
①很多的OJ题考察的都是单链表
②单链更多的是去更复杂的数据结构的子结构,如哈希表、邻接表。
1.移除列表元素
203. 移除链表元素 - 力扣(LeetCode)
多定义多个变量也是常数个,空间复杂度也是O(1).

在VS中进行调试
Test.c
//VS中进行调试
//Definition for singly-linked list
struct ListNode {int val;struct ListNode *next;
};struct ListNode* removeElements(struct ListNode* head, int val) { struct ListNode* prev=NULL,*cur=head;while(cur){if(cur->val==val){//删除(但是需要考虑删的就是第一个数据元素,即头删)if(cur==head)//头删{head=cur->next;cur=head;}else//中间删{prev->next=cur->next;free(cur);//释放空间free,还剩一个指针.释放了cur所指指针的节点cur=prev->next;}}else{//迭代往后走prev=cur;cur=cur->next;}}return head;
}//快速调试OJ代码
int main()
{//直接手动构建一个链表struct ListNode* n1=(struct ListNode*)malloc(sizeof(struct ListNode));struct ListNode* n2=(struct ListNode*)malloc(sizeof(struct ListNode));struct ListNode* n3=(struct ListNode*)malloc(sizeof(struct ListNode));struct ListNode* n4=(struct ListNode*)malloc(sizeof(struct ListNode));n1->val=7;n2->val=7;n3->val=7;n4->val=7;n1->next=n2;n2->next=n3;n3->next=n4;n4->next=NULL;removeElements(n1,7);return 0;
}2.反转链表(※)
206. 反转链表 - 力扣(LeetCode)

能用循环就不用递归,因为递归的缺陷是栈不够,程序也过不了。
这里创建一个新的列表,过不了
思路1:原地翻转(把箭头方向换一下,本质就是存地址)
思路2: 头插法

3.链表的中间节点
876. 链表的中间结点 - 力扣(LeetCode)
思路1:计数,遍历列表两次
思路2:要是只能遍历链表一次----->用快慢指针
快指针一次走两步,慢指针一次走一步

struct ListNode* middleNode(struct ListNode* head)
{struct ListNode* slow,*fast;slow=fast=head;while(fast&&fast->next){slow=slow->next;fast=fast->next;}
}4.链表的倒数第K个节点
面试题 02.02. 返回倒数第 k 个节点 - 力扣(LeetCode)
快慢指针
5.合并两个有序列表(※)
21. 合并两个有序链表 - 力扣(LeetCode)
思路:依次取小的元素,尾插到新的链表。
(这里取元素不是很清晰)。用尾插法
开始我的思路:用一个节点存值,把list1中的元素插入到list2中。(被指针弄晕了,搞了太多指针,list指向谁,谁就是第一个节点)
思路:是不是可以简化一下,每次尾插都要判断是不是一个
所以增加一个哨兵。

//哨兵位的头节点mallochead=tail=(struct ListNode*)malloc(sizeof(struct ListNode));6.链表的分割(※)
面试题 02.04. 分割链表 - 力扣(LeetCode)
这里是不保留原来的位置。

开始的思路:把大于等于的记录下来和小于的进行交换,但是逻辑不是很清晰,没做出来
思路2:小于x的尾插到链表small,大于等于的尾插到链表large,最后把large尾插到small链表

注意单链表最后要把尾节点的next域置为NULL,表明链表结束。(在程序中可以看到,如果没有程序通过不了)

如果不要求相对位置的话,可以小于的数前插前newHead,大于的数尾插到新链表newHead中。


7.链表的回文结构(※)
面试题 02.06. 回文链表 - 力扣(LeetCode)
开始思路:如果反转后的列表和原来的链表是一样的说明是;否则不是
我写的代码智能通过一部分的测试用例,有的测试用例的链表长度巨长,所以我定义的数组长度很长,如何进行改进?

8.链表相交(※)
面试题 02.07. 链表相交 - 力扣(LeetCode)
面试题 02.07. 链表相交 - 力扣(LeetCode)

这里有个小白问题:{5,0,1,8,4,5}和{4,1,8,4,5}中相交节点不是1而是8?
你说的是值相等,题目描述的是两个链表指向的是同一个地址,才算相交。
思路1:暴力求解-穷举O(N^2)
判断链表是否相交,如果相交求交点
依次取A链表中的每个节点跟B链表中所有节点比较,如果有地址相同的节点,就是相交,第一个相同的交点
思路2:要求优化到O(N)
不断地找规律,找规则
①尾节点相同就是相交,否则不相交
②求交点:长的链表先走(长度差)布,再同时走,第一个相同就是交点。
学习下面的谁长谁短如何处理(这样写又方便代码也简化,开始我用了if-else代码写了一大堆)

这里新定义了两个longList和shortList比较方便,不用headA和HeadB动来动去。多定义两个变量空间复杂度还是O(1),但是代码的逻辑清晰了很多,所以不要害怕多定义变量。

思路3:将两个链表逆置,再比较,可以?
不能进行逆置,因为节点8逆置的话next要指向两个地址,但它只有一个next域,只能保存一个地址。
9.环形链表(非常经典的问题,面试常考)
141. 环形链表 - 力扣(LeetCode)
哈希表和快慢指针
(这里不难但是涉及很多证明)

难点:带环不能遍历
思路:slow和fast开始都指向head,slow走一步,fast走两步
如果fast和slow相遇的话,有环;不带环,fast为空。

哈希表的方法
(开始自己一点思路也没有)
延伸问题:
这题代码比较简单,面试官会让提新问题
1.为什么slow走一步和fast走两步一定会在环中相遇?会不会在环里面错过,永远遇不上?请证明
结论:他们一定会相遇。
分析证明:
第一步:slow和fast,fast一定先进环,这是slow走了入环前距离的一半。
第二步:随着slow进环,fast已经在环里走了一段距离(这段距离和环的大小有关系)
假设slow进环的时候,slow和fast的距离是N;fast开始追slow
slow每次往前走1步,fast往前走2步,,每追一次,判断一下相遇
每追一次,fast和slow的距离变化:
N N-1 N-2 N-3 N-4 N-5 ....1 0 每追一次,他们之间的距离减少1,当距离是0,就是相遇点。



2.为什么slow走一步,fast走两步?能不能fast走3、4、5...n步?请证明一下
结论:fast一次走n(n>2)步不会相遇。
这里没有给环的大小和入环之前的距离大小,所以不好具体证明。
假设slow走一步,fast走三步
slow进环以后,fast跟slow之间的距离为N,fast开始追slow
他们之间的距离变化如下:(距离变为-1意味着他们之间的距离变为C-1,C是环的长度)
如果下一趟追不上就永远追不上。
如果C-1是奇数,就永远追不上;如果C-1是偶数,就可以追上。
重点分析三步的情况,其他的就可以想明白了。



142. 环形链表 II - 力扣(LeetCode)
1.证明法
有环还要返回入环的点;无环返回NULL;
思路:先判断是否有环;有环求入口点
求环的入口点是一个证明的问题。
slow走1步,fast走两步,一定会相遇,求入口点?
结论:一个指针从相遇点开始走,一个指针从链表头开始走,他们会在环的入口点相遇。
可以推出一个公式
追上相遇的过程中
慢指针走的距离:L+X,快指针走的距离是L+X+nC(n>=1 是slow进环之前,快指针在环里走的圈数)
快指针走的路程是慢指针的2倍
2(L+X)=L+X+nC
L+X=nC
=>L=nC-X
<=>L=(n-1)*C+C-X

2.另外一种方法
思路简单实现复杂一些。
把问题转换,让相遇点指向空,弄一个新链表。求入口点,就是求两个链表的交点。

代码实现?
10. 随机链表的复制(※※)
要求深拷贝

138. 随机链表的复制 - 力扣(LeetCode)
思路1:
(建立原节点和拷贝节点之间的关系)
①复制节点,插入到原节点和下一个节点之间

②根据原节点random,处理复制节点的random。
原节点7的random为NULL,于是原节点的拷贝(7的下一个节点)也是NULL。

③把拷贝的节点剪下来链接成新链表;恢复原链表的链接关系。

2.3.4 带头节点的双向循环链表
![]()

最实用的两种列表结构

List.h
//双链表定义
typedef struct ListNode
{LTDataType data;struct ListNode*next;struct ListNode*prev;
}LTNode;//void ListInit(LTNode** phead);//初始化.(这里需要二级指针,因为需要改变phead指针本身)
LTNode* ListInit(LTNode* phead);//初始化
void ListPrint(LTNode* head);//打印列表
void ListPushBack(LTNode* phead,LTDataType x);//尾插
void ListPopBack(LTNode* phead);//尾删
void ListPushFront(LTNode* phead,LTDataType x);//头插
void ListPopFront(LTNode* phead);//头删
LTNode* ListFind(LTNode *phead,LTDataType x);//查找
LTNode* ListInsert(LTNode *pos,LTDataType x);//在pos位置之前插入
LTNode* ListErase(LTNode *pos,LTDataType x);//在pos处删除//函数复用,修改下面的函数
void ListPushBack(LTNode* phead,LTDataType x);//尾插
void ListPopBack(LTNode* phead);//尾删
void ListPushFront(LTNode* phead,LTDataType x);//头插
void ListPopFront(LTNode* phead);//头删void ListDestroy(LTNode** pphead);//销毁链表 二级指针初始化

尾插

pos之前插入 ListInsert,(包含了前面的头插尾插),可以修改前面写的函数

删除pos位置(包含了前面的头删尾删),可以修改前面写的函数
List.c
#include "List.h"//链表初始化
/* 法1 void方法需要用二级指针, 参考前面的法2 用返回值的方法LTNode*
*/
LTNode* ListInit(LTNode* phead)
{//哨兵位的头节点phead=(LTNode*)malloc(sizeof(LTNode));phead->next=phead;phead->prev=phead;return phead;
}//打印链表
void ListPrint(LTNode* phead)
{asseert(phead);LTNode* cur=phead->next;//phead指针哨兵位的头节点,存的不是有效数据while(cur!=phead){printf("%d->",cur->data);cur=cur->next;}printf("\n");
}//尾插
void ListPushBack(LTNode* phead,LTDataType x)
{//这里不是要改变这个phead,所以不需要二级指针assert(phead);LTNode* tail=phead->prev;LTNode* newnode=(LTNode*)malloc(sizeof(LTNode));//phead tail newnodetail->next=newnode;newnode->prev=tail;newnode->next=phead;phead->prev=newnode;tail=newnode;
}//尾删 带头节点的双向链表
void ListPopBack(LTNode* phead)
{assert(phead);assert(phead->next!=phead);//链表为空//找尾 和尾巴的前一个节点 多定义两个指针,思路和代码就会很清晰,不然next和prev一多不好找错误LTNode* tail=phead->prev;LTNode* tailPrev=tail->prev;free(tail); //释放空间//改变指针链接方式tailPrev->next=phead;phead->prev=tailPrev;
}//头插
void ListPushFront(LTNode* phead,LTDataType x)
{assetrt(phead);//创建新节点LTNode* newnode=(LTNode*)malloc(sizeof(LTNode));newnode->next=NULL;newnode->prev=NULL;//好习惯,虽然后面还要进行修改//修改指针LTNode* next=phead->next;newnode->prev=phead;newnode->next=next;next->prev=newnode;phead->next=newnode;
}//头删
void ListPopFront(LTNode* phead)
{assert(phead);assert(phead->next!=phead);//链表为空,不能再删了LTNode* pheadNext=phead->next;phead->next=pheadNext->next;pheadNext->next->prev=phead;free(pheadNext);
}//查找
LTNode* ListFind(LTNode *phead,LTDataType x)
{asseert(phead);LTNode* cur=phead->next;//phead指针哨兵位的头节点,存的不是有效数据while(cur!=phead){if(x==cur->data) return cur;cur=cur->next;}//没找到return NULL;
}//在pos之前插入
LTNode* ListInsert(LTNode *pos,LTDataType x)
{assert(pos);LTNode *posPrev=pos->prev;//创建新节点LTNode *newnode=(LTNode *)mallloc(sizeof(LTNode));newnode->prev=newnode->next=NULL;//修改链接 posPrev newnode pos//左边连上posPrev->next=newnode;newnode->prev=posPrev;//右边连上newnode->next=pos;pos->prev=newnode;
}//修改尾插 调用ListInsert
void ListPushBack(LTNode* phead,LTDataType x)
{ListInsert(phead,x);
}//修改头插 调用ListInsert
void ListPushFront(LTNode* phead,LTDataType x)
{ListInsert(phead->next,x);
}//在pos位置删除
LTNode* ListErase(LTNode *pos)
{assert(pos);//特殊情况:头删、尾删、只有一个一个节点,删了后为空LTNode * posPrev=pos->prev;LTNode * posNext=pos->next;//posPrev pos posNext 连线posPrev->next=posNext;posNext->prev=posPrev;//释放空间free(pos);pos=NULL;//置不置空都可以
}//修改尾删 调用ListErase
void ListPopBack(LTNode* phead)
{assert(phead);assert(phead->next!=head);//链表为空ListErase(phead->prev);
}//修改头删 调用ListErase
void ListPopFront(LTNode* phead)
{ assert(phead);assert(phead->next!=head);//链表为空ListErase(phead->next);//带哨兵位的头节点
}//销毁链表 二级指针
void ListDestroy(LTNode** pphead)//也可以用一级指针,然后再外面phead=NULL置空
{assert(&pphead);LTNode* cur=&pphead->next;while(cur!=&pphead){LTNode* next=cur->next;//保存它的下一个,因为要freefree(cur);cur=next;}free(&pphead);&pphead=NULL;//二级指针,需要解引用
}如何要改变传的指针,就需要二级指针。
带头节点就不需要传二级指针,因为就不用改变他了。
STL 模板结构类
2.3 顺序表和链表的区别(优缺)
这两个结构各有优势,很难区分谁更优秀
严格来说,他们两是相辅相成的两种结构。
2.3.1 顺序表
优点:(用下标访问)
①支持随机访问。需要随机访问结构支持算法可以很好的适用。
②CPU告诉缓存利用率更高
缺点:
①头部中部插入时间效率低。O(N)
②连续的物理空间,空间不够了以后增容。(增容有一定程度的消耗;为了避免频繁增容,一般都按倍数去增,用不完可能存在一定的空间浪费)
2.3.2链表(带头双向循环链表)
优点:
①任意位置插入删除效率高。O(1)
②按需申请释放空间
缺点:
①不支持随机访问。(不用下标访问)意味着:一些排序,二分查找等在这种结构上不适用。
②链表存储一个值,同时也要存储链接指针,也有一定消耗。(但问题不是很大,一般空间都够用,指针占不了多少,一亿用几块无关大雅)
③CPU告诉缓存利用率更低
CPU
对于高速缓存可以借助下图进行理解。
·
与程序员相关的CPU缓存知识 与程序员相关的CPU缓存知识 | 酷 壳 - CoolShell
多读读这个大佬的文章,这是他自己搭建的网站,写的文章。酷壳 – CoolShell.cn
3 栈_队列(线性结构)
3.1 栈
3.1.1 栈表示
在之前学的基础上加了新要求,后进先出(Last In First Out)
如:弹夹、排队、喝醉

3.1.2 栈实现(数组栈 or 链式栈)

数组栈和链式栈都可以,非要选一种
推荐选择数组栈 。
写完顺序表来写栈,就跟玩一样,轻松松。
stack.h
//Stack.h
#pragma once //保证头文件只被编译一次,防止头文件被重复引用#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>//栈的定义
typedef int STDataType;
typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;//栈接口函数
void StackInit(ST* ps);//栈初始化
void StackDestroy(ST* ps);//销毁
void StackPush(ST* ps,STDataType x);//入栈
void StackPop(ST* ps);//出栈
STDataType StackTop(ST* ps);//取栈顶元素
int StackSize(ST* ps);//栈中有多少数据
bool StackEmpty(ST* ps);//栈空Stack.c
初始化时top==0 or top=1

//Stack.c
#include "Stack.h"//栈初始化
void StackInit(ST* ps)
{assert(ps);ps->a=NULL;//这是什么意思,存栈中的数据元素ps->top=0;//top给0 意味着top指向栈顶数据的下一个位置;也可以-1,代表top指向栈顶数据(先++,再放数据)ps->capacity=0;
}//销毁
void StackDestroy(ST* ps)
{assert(ps);free(ps->a);ps->a=NULL;ps->capacity=ps->top=0;
}//入栈
void StackPush(ST* ps,STDataType x)
{assert(ps);if(ps->capacity==ps->top)//容量不够,增容{int newCapacity=ps->capacity==0?4:ps->capacity*2;//增容的方法STDataType *tmp=realloc(ps->a,sizeof(STDataType)*newCapacity);if(tmp==NULL){printf("realloc failed!\n");exit(-1);}ps->a=tmp;//把新的空间给它psps->capacity=newCapacity;//注意:这里由于开始多了一个等号,后面程序一直报错,最后才发现错误,是让AI对话帮我解决的}ps->a[ps->top]=x;//指向栈顶数据的下一个位置ps->top++;}//出栈
void StackPop(ST* ps)
{assert(ps);assert(ps->top>0);//说明还有数据ps->top--;
}//栈中有多少数据
int StackSize((ST* ps)
{assert(ps);assert(ps->top>0);return ps->top;
}//取栈顶的数据
STDataType StackTop(ST* ps)
{assert(ps);assert(ps->top>0);//说明还有数据;==0为空return ps->a[ps->top-1];
}//栈空
bool StackEmpty(ST* ps)
{assert(ps);return ps->top==0;
}

3.2 队列的表示和实现
1.队列的表示
先进先出 First In First Out

2. 队列的实现
考虑顺序表(数组)和链表(更适合)

Queue.h
//Queue.h
#pragma once#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int QDataType;typedef struct QueueNode
{struct QueueNode* next;QDataType data;
}QueueNode;typedef struct Queue//控制多个值一般用结构体
{QueueNode* head;QueueNode* tail;
}Queue;//核心接口函数
void QueueInit(Queue* pq);//队列的初始化
void QueueDestroy(Queue* pq);//队列的销毁
void QueuePush(Queue* pq,QDataType x);//一定是队尾入
void QueuePop(Queue* pq);//一定是队头出
QDataType QueueFront(Queue* pq);//取队头数据
QDataType QueueBack(Queue* pq);//取队尾数据
int QueueSize(Queue* pq);//有多少个数据
bool QueueEmpty(Queue* pq);//队空Queue.c
//Queue.c//队列的初始化
void QueueInit(Queue* pq)
{assert(pq);pq->head=NULL;pq->tail=NULL;
}//队列的销毁 释放空间,指针置空
void QueueDestroy(Queue* pq)
{assert(pq);QueueNode* cur=pq->head;while(cur)//释放空间{//删除当前位置,需要先保存他的下一个QueueNode* next=cur->next;free(cur);cur=next;}pq->head=pq->tail=NULL;//指针置空
}//一定是队尾入,尾插
void QueuePush(Queue* pq,QDataType x)
{//尾插分两种情况:直接插;一开始就是空的assert(pq);//先创建好新节点QueueNode* newnode=(QueueNode*)malloc(sizeof(QueueNode));newnode->data=x;newnode->next=NULL;if(pq->head==NULL)//表示链表是空的{pq->head=pq->tail=newnode;}else//不为空,直接插到链尾 tail {pq->tail->next=newnode;pq->tail=newnode;}
}//一定是队头出,头删
void QueuePop(Queue* pq)
{assert(pq);//判断结构体不为空assert(!QueueEmpty(pq));//判断队列是否是空QueueNode* next=pq->head->next;free(pq->head);//free是free指针指向的空间,不是指针本身,于是指针就是野指针pq->head=next;//注意是否是最后一个节点if(pq->head==NULL) pq->tail=NULL;
}//取队头数据
QDataType QueueFront(Queue* pq)
{assert(pq);//判断结构体不为空assert(!QueueEmpty(pq));//判断队列是否是空return pq->head->data;
}//取队尾数据
QDataType QueueBack(Queue* pq)
{assert(pq);//判断结构体不为空assert(!QueueEmpty(pq));//判断队列是否是空return pq->tail->data;
}//有多少个数据
int QueueSize(Queue* pq)//pq是个结构体
{assert(pq);int n=0;QueueNode* cur=pq->head;while(cur){++n;cur=cur->next;}return n;
}//队空
bool QueueEmpty(Queue* pq)
{assert(pq);return pq->head==NULL;//头指针为空说明列表为空
}队列的典型作用
医院、营业厅、银行 抽号机 :保证公平性,先来先被服务
os中互斥和同步
3.3 OJ
1.括号的匹配
20. 有效的括号 - 力扣(LeetCode)
注意细节,之后还会C++的方法,方便一些

2.用队列实现栈
225. 用队列实现栈 - 力扣(LeetCode)
//用已经实现的队列来实现栈
//不能去改变队列的结构(如 反转),只能去调用队列提供的接口函数
//核心思路:
// 1.入数据,往不为空的队列,永远保持一个队列为空
// 2.出数据:依次出对头的数据,转移到另一个队列,直至还剩下最后一个数据,然后进行Pop

注意free的时候,要先销毁队列

这个题思维不难,主要是代码的实现细节问题。
3.用栈实现队列
232. 用栈实现队列 - 力扣(LeetCode)

栈中只能调用已经定义好的函数,不能更改栈的原来结构。
//一个栈专门用来入数据pushST,一个栈用来出数据popST;出数据的栈空了再把另一个的数据导进来
typedef struct {ST pushST;ST popST;
} MyQueue;4.设计循环队列-环形缓冲器
622. 设计循环队列 - 力扣(LeetCode)
可以认为是大小固定的队列 满足:
① 先进先出
②空间大小固定
用数组或者循环链表实现。
重点:无论用数组实现还是链表实现,都要多开一个空间,也就意味着,要存一个k个数据的循环队列,要开k+1个空间,否则,无法实现判空和判满。


空:front==tail
满:tail->next=front

空:front=tail
满:(tail+1)%(k+1)==front
返回尾部元素 小tips很方便,不用单独处理特殊位置
return data[(rear-1+capacity)%capacity];
class MyCircularQueue {//用数组实现//开k+1个空间
private:int front,rear;//rear指向最后一个元素的下一个位置int capacity;//容量vector<int> data;//数据元素 向量 ==动态数组public://构造器,设置队列长度为 kMyCircularQueue(int k) {front=rear=0;this->capacity=k+1;this->data=vector<int>(capacity);//为什么要用这个??? 设置容量的大小,因为是固定的空间,所以需要设置}//检查循环队列是否为空bool isEmpty()//判空条件front=rear{// if(front==rear)return true;// return false;//可以简化为下面的return rear==front;}//检查循环队列是否已满bool isFull() //判满(rear+1)%capacity==front{// if((rear+1)%capacity==front) return true;// return false;return (rear+1)%capacity==front;}//向循环队列插入一个元素。如果成功插入则返回真(不满才可以插)bool enQueue(int value) {//满了直接返回falseif(isFull())return false;data[rear]=value;rear=(rear+1)%capacity;return true;}//从循环队列中删除一个元素。如果成功删除则返回真(不空才可以删)bool deQueue() {if(isEmpty())return false;front=(front+1)%capacity;return true;}//从队首获取元素。如果队列为空,返回 -1int Front() {if(isEmpty())return -1;return data[front];}//获取队尾元素。如果队列为空,返回 -1 int Rear() {if(isEmpty())return -1;if(rear==0)//特殊位置的讨论 ???这里写的越界了 因为特殊位置是rear指向的位置是下标为0的位置{return data[capacity-1];}return data[rear-1];//特殊位置是rear指向的位置是下标为0的位置 rear-1的话就会变成-1 就会越界//return data[(rear-1+capacity)%capacity];//注意这里的使用}};/*** Your MyCircularQueue object will be instantiated and called as such:* MyCircularQueue* obj = new MyCircularQueue(k);* bool param_1 = obj->enQueue(value);* bool param_2 = obj->deQueue();* int param_3 = obj->Front();* int param_4 = obj->Rear();* bool param_5 = obj->isEmpty();* bool param_6 = obj->isFull();*/4 二叉树 (非线性结构)
1.树
概念
节点的度:一个节点含有的子树的个数
树的度:max(节点的度)
节点的层次:根为第1层,依次类推
树的高度/深度:max(节点的层数)
叶节点==终端节点:度为0的节点
父节点==双亲节点:有子节点
兄弟节点:相同父节点(亲兄弟)
节点的祖先:Q的祖先有J、E、A

森林:m>0棵互不相交的树的集合
(日常很少碰到森林,并查集就是一个森林。)
树的表示:
左孩子右兄弟

双亲表示法:存双亲的下标
解决最小生成树,用并查集,用双亲表示法的多棵树。

树在实际中的应用(表示文件系统的目录树结构)

2.二叉树的定义和性质
二叉树特点:度为2的树



1.任何一棵二叉树由三部分组成:
①根节点
②左子树
③右子树
2.分治算法
分而治之,把大问题分为类似子问题,子问题再分为子问题,直到子问题不可再分。
3.二叉树的分类--满二叉树、完全二叉树


假设一棵满二叉树的高度是h,总结点的个数:
2^0+2^1+...+2^(h-1)=2^h -1=N
h=log(N+1)
完全二叉树:
①前h-1层是满的
②最后一层不满,但是最后一层都是连续的

4.二叉树的性质

对于性质3的记忆:度为0的节点比度为2的多一个
完全二叉树中:度为1的要么有一个,要么一个也没有。
题目:2.A 3.B


5.前中后序 遍历
前序(先根):根 左子树 右子树 ( A B D NULL NULL E NULL NULL C NULL NULL )
中序(中根):左子树 根 右子树 ( NULL D NULL B NULL E NULL A NULL C NULL )
后序(后根):左子树 右子树 根 ( NULL NULL D NULL NULL E B NULL NULL C A )
代码实现
递归实现
typedef char BTDataType;//二叉链
typedef struct BinaryTreeNode
{struct BinaryTreeNode* left;//指当前节点的左孩子struct BinaryTreeNode* right;//指当前节点的右孩子BTDataType data;//当前节点值域
}BTNode;//前序 根 左子树 右子树
void PrevOrder(BTNode* root)
{if(root=NULL)return;printf("%c ",root->data);//根PrevOrder(root->left);//左子树PrevOrder(root->right);//右子树
}//中序 左子树 根 右子树
void InOrder(BTNode* root)
{if(root=NULL)return;InOrder(root->left);//左子树printf("%c ",root->data);//根InOrder(root->right);//右子树
}//后序 左子树 右子树 根
void PostOrder(BTNode* root)
{if(root=NULL)return;PostOrder(root->left);//左子树PostOrder(root->right);//右子树printf("%c ",root->data);//根
}Test.c
//Test.cint main()
{BTNode* A=(BTNode*)malloc(sizeof(BTNode));A->data='A';A->left=NULL;A->right=NULL;BTNode* B=(BTNode*)malloc(sizeof(BTNode));B->data='B';B->left=NULL;B->right=NULL;BTNode* C=(BTNode*)malloc(sizeof(BTNode));C->data='C';C->left=NULL;C->right=NULL;BTNode* D=(BTNode*)malloc(sizeof(BTNode));D->data='D';D->left=NULL;D->right=NULL;BTNode* E=(BTNode*)malloc(sizeof(BTNode));E->data='E';E->left=NULL;E->right=NULL;A->left=B;A->right=C;B->left=D;B->right=E;PrevOrder(A);printf("\n");return 0;
}代码的理解


二叉树的层序遍历
前中后序遍历(一般用递归)-------深度优先遍历
层序遍历(一般用队列实现)------广度优先遍历
二叉树的层序遍历----非递归实现-----借助队列的先进先出
核心思路:上一层带下一层
队列不为空,出对头,带入下一层


//层序遍历--需要用队列(法1:之前的代码,拷贝过来;法2)
//核心思路:上一层带下一层
void LevelOrder(BTNode* root)
{Queue q;QueueInit(&q);if(root){QueuePush(&q,root);}while(!QueueEmpty(&q)){BTNode* front=QueueFront(&q);QueuePop(&q);printf("%c ",front->data);if(front->left) QueuePush(&q,front->left);if(front->right) QueuePush(&q,front->right);}printf("\n");QueueDestroy(&q);
}3.二叉树的表示和实现
数组和链表。
普通二叉树,不讲增删查改,在实际中普通二叉树增删查改没有意义。实际中常用搜索二叉树。
为什么要学?
🐟为后面学复杂的二叉树做基础
🐟OJ题考
不讲线索化和哈夫曼树

数组表示

链表表示和实现--二叉 三叉(RBT)

typedef char BTDataType;//二叉链
typedef struct BinaryTreeNode
{struct BinaryTreeNode* left;//指当前节点的左孩子struct BinaryTreeNode* right;//指当前节点的右孩子BTDataType data;//当前节点值域
}BinaryTreeNode;//三叉链
typedef struct ThreeTreeNode
{struct BinaryTreeNode* parent;//指当前节点的双亲struct BinaryTreeNode* left;//指当前节点的左孩子struct BinaryTreeNode* right;//指当前节点的右孩子BTDataType data;//当前节点值域
}ThreeTreeNode;求节点个数
方法3:分而治之--后序递归

typedef char BTDataType;//二叉链
typedef struct BinaryTreeNode
{struct BinaryTreeNode* left;//指当前节点的左孩子struct BinaryTreeNode* right;//指当前节点的右孩子BTDataType data;//当前节点值域
}BTNode;// 方法1
//求二叉树节点的个数 --前序遍历 计数
int size=0;//这种方法不是很好。可以用传参的方法
int TreeSize(BTNode* root)
{if(root==NULL)return 0;//int size=0;//局部,不能累积,要对同一个size进行++:法①可以定义全局size++size;TreeSize(root->left);TreeSize(root->right);return size;}//方法2 传参 第二个参数要传什么呀
int TreeSize(BTNode* root,int* psize)//在内部需要改变size的值,所以要传地址
{if(root==NULL)return 0;//int size=0;//局部,不能累积,要对同一个size进行++:法①可以定义全局size++(*psize);TreeSize(root->left,psize);TreeSize(root->right,psize);return size;}//方法3 分而治之 后序遍历 左子树的个数+右子树的个数+1
int TreeSize(BTNode* root)
{return root==NULL?0:TreeSize(root->left)+TreeSize(root->right)+1;
}求叶子节点个数

//叶节点的个数
//分治法: 后序遍历递归---递归要去画递归调用的图
int TreeLeafSize(BTNode* root)
{//左子树且右子树都为0 返回1if(root==NULL)return 0;if(root->left==NULL && root->right==NULL){return 1;}return TreeLeafSize(root->left)+TreeLeafSize(root->right);
}4 销毁二叉树
后序销毁
左子树 右子树 根(它)
void DestroyTree(struct TreeNode* root)//c++中 TreeNode*& root,这里是引用,调用Destroy(t),root就是t的别名(外号)
{if(root==NULL){return;}DestroyTree(root->left);DestroyTree(root->right);free(root);root=NULL;//这个置空其实不起作用,要用二级指针
}5 搜索二叉树

任何一棵树:左子树<根<右子树
搜索:最多查找高度次
时间复杂度:O(N)
==>左右两边节点数据比较均匀 平衡二叉树(AVL树 红黑树)
多叉搜索树--B树 数据库原理
6.哈夫曼树()
无损压缩的一部分
贪心算法(每次选最小的两个节点,)


哈夫曼编码:哈夫曼树左0右1
7.OJ
①二叉树的前序遍历
144. 二叉树的前序遍历 - 力扣(LeetCode)
多画递归调用的图
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
/*** Note: The returned array must be malloced, assume caller calls free().*/int TreeSize(struct TreeNode* root)
{if(root==NULL)return 0;return TreeSize(root->left)+TreeSize(root->right)+1;
}//子函数
void _prevOrder(struct TreeNode* root,int* a,int* pi)
{if(root==NULL)return;a[(*pi)++]=root->val;_prevOrder(root->left,a,pi);_prevOrder(root->right,a,pi);
}//前序遍历,然后返回到一个数组,并且返回数组的长度
int* preorderTraversal(struct TreeNode* root, int* returnSize) {//输出型参数 int* returnSizeint size=TreeSize(root);int* a=(int*)malloc(size*sizeof(int));int i=0;_prevOrder(root,a,&i);//要改变i的值,需要传i的地址*returnSize=size;return a;
}//注意:本题用了一个全局变量的i,但是不能AC,出现内存问题,越界;是因为它有多个测试用例,i的值累加了,所以要每次i=0②二叉树的中序遍历
③二叉树的后序遍历
④二叉树的最大深度
104. 二叉树的最大深度 - 力扣(LeetCode)
//分治
//1、空 高度 0
//2、非空 分解子问题
// 先求左右子树的深度,我的深度等于左右子树的最大值
⑤平衡二叉树
110. 平衡二叉树 - 力扣(LeetCode)

//左右子树的每个节点都满足高度差
要求每一棵树都满足
当前树不满足,就不检查之后的树了
⑥二叉树的层序遍历
102. 二叉树的层序遍历 - 力扣(LeetCode)
这里不建议用C来,比较恶心。后面用c++或者java来实现。
层序遍历,返回节点个数,并以二维数组返回(放映层次)。
⑦二叉树遍历(常考)--清华大学复试--IO型
二叉树遍历_牛客题霸_牛客网 (nowcoder.com)
根据给出的先序遍历创建二叉树,再给出中序遍历。
之前都是需要一个中序,才能重建,但是这里给出了空树。这里需要递归的创建树。
#include <cstdio>
#include <cstdlib>
#include <iostream>
using namespace std;typedef struct TreeNode
{char data;struct TreeNode* left;struct TreeNode* right;}TNode;TNode* CreateTree(char* a,int* pi)
{if(a[*pi]=='#'){++(*pi);return NULL;}TNode* root=(TNode*)malloc(sizeof(TNode));if(root==NULL){printf("malloc fail\n");exit(-1);}root->data=a[*pi];++(*pi);root->left=CreateTree(a,pi);root->right=CreateTree(a,pi);return root;
}void InOrder(TNode* root)
{//左子树 根 右子树if(root==NULL) return;InOrder(root->left);printf("%c ",root->data);InOrder(root->right);}int main() {char str[100];scanf("%s",str);int i=0;TNode* root=CreateTree(str,&i);//递归里上一层不会影响下一层,所以要传地址InOrder(root);}
5 排序
1.排序的概念和意义
应用场景很多:购物网站,筛选价格排序,销量排序