文章链接:https://arxiv.org/pdf/2409.12193
gitbub链接:https://github.com/florinshen/Vista3D
亮点直击
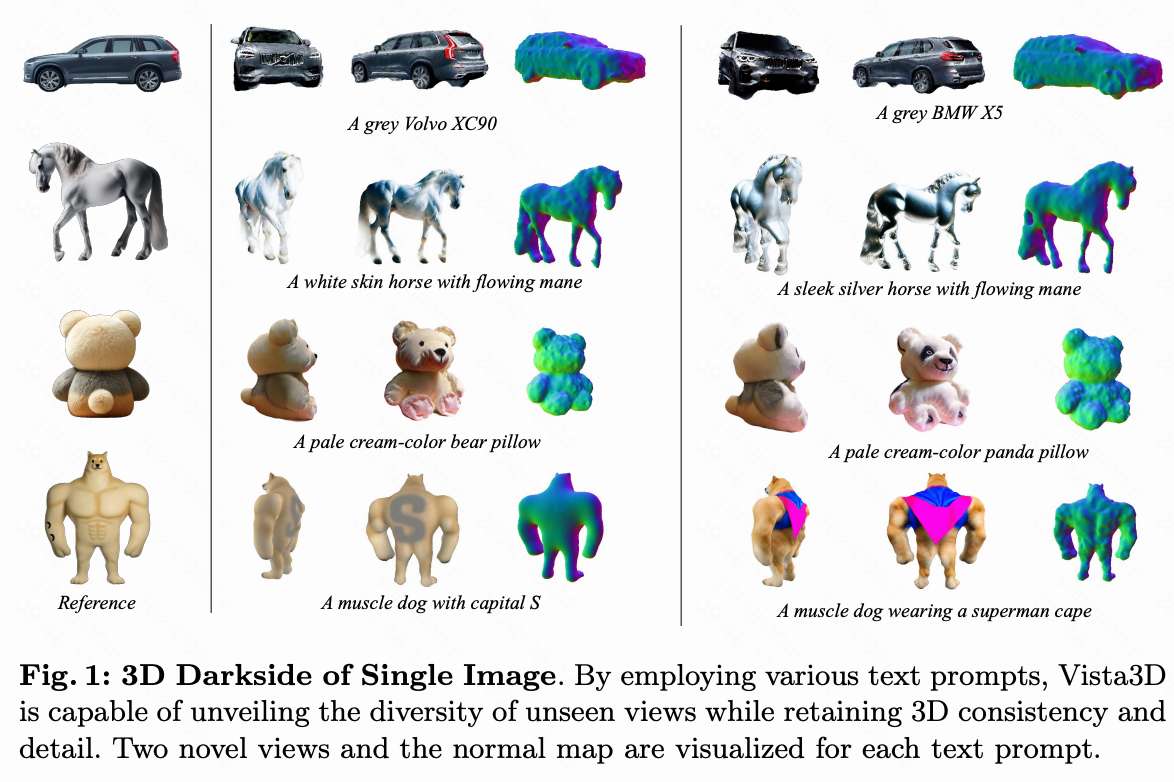
- 提出了Vista3D,一个用于揭示单张图像3D darkside 的框架,能够高效地利用2D先验生成多样的3D物体。
- 开发了一种从高斯投影到等值面3D表示的转换方法,通过可微等值面方法和解耦纹理来优化粗糙几何,实现纹理化网格的创建。
- 提出了一种角度组合方法用于扩散先验,通过约束其梯度幅度,在不牺牲3D一致性的情况下实现3D潜力的多样性。
总结速览
解决的问题
- 解决单张图像生成3D对象时多视图不一致的问题。
- 平衡3D生成中的一致性与多样性。
提出的方案
- Vista3D框架采用两阶段方法:粗略阶段通过高斯投影生成初始几何,精细阶段优化符号距离函数(SDF)。
- 使用角度组合方法进行扩散先验,通过约束梯度幅度实现多样性。
应用的技术
- 高斯投影和可微等值面方法。
- 解耦纹理技术。
- 使用两个独立隐函数捕捉物体的可见和隐藏方面。
达到的效果
- 在短短5分钟内实现快速且一致的3D生成。
- 提升生成质量,维持3D物体一致性和多样性之间的平衡。
方法
本节概述了利用2D扩散先验从单张图像生成详细3D对象的框架。如下图2所示,本文对单张图像3D darkside的探索始于通过3D高斯投影高效生成基础几何。在精细化阶段,本文设计了一种方法,将初步的3D高斯几何转换为符号距离场,随后引入可微分的等值面表示,以进一步增强几何和纹理。为了实现给定单张图像的多样化3D darkside,本文提出了一种新颖的方法来约束两个扩散先验,通过限制梯度幅度来创造多样而连贯的暗面纹理。通过这些方法,可以高效地从单张图像生成多样化且高保真的网格。
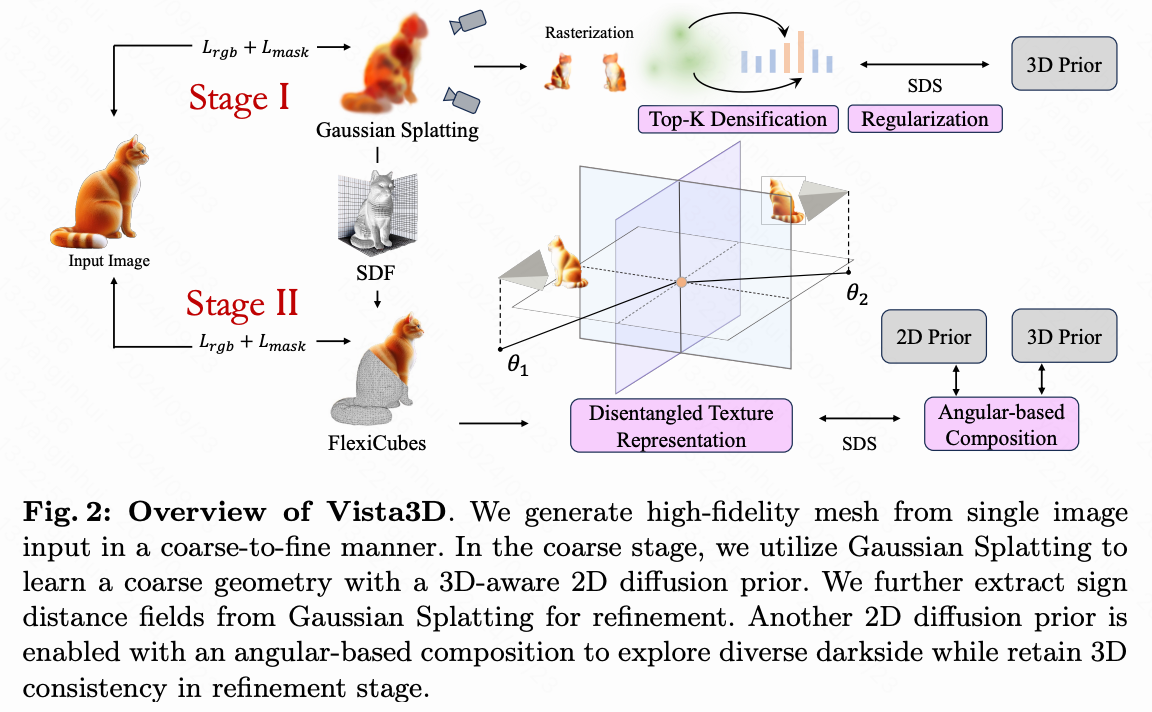
Gaussian Splatting 的粗略几何
在本文框架的粗略阶段,专注于使用Gaussian Splatting构建基础对象几何。该技术将3D场景表示为一组各向异性3D高斯。与其他神经逆渲染方法(如NeRF)相比,Gaussian Splatting在逆渲染任务中表现出显著更快的收敛速度。
一些研究,比如[3, 41, 49] 尝试将 Gaussian Splatting 引入3D生成模型。在这些方法中,发现直接使用 Gaussian Splatting 生成详细的3D对象需要优化大量的3D高斯,这需要大量时间进行优化和密集化,仍然耗时。然而, Gaussian Splatting 可以在一分钟内使用有限数量的3D高斯从单张图像快速创建粗略几何。因此,在本文的方法中,仅利用 Gaussian Splatting 进行初始粗略几何生成。
每个3D高斯由其中心位置 x ∈ R 3 x \in \mathbb{R}^3 x∈R3、缩放 r ∈ R r \in \mathbb{R} r∈R、旋转四元数 q ∈ R 4 q \in \mathbb{R}^4 q∈R4、不透明度 α ∈ R \alpha \in \mathbb{R} α∈R 和球谐函数 c ∈ R 3 c \in \mathbb{R}^3 c∈R3 来表示颜色。为了生成粗略的3D对象,本文优化一组这些高斯参数 Ψ = { Φ i } \Psi = \{\Phi_i\} Ψ={Φi},其中 Φ i = { x i , r i , q i , α i , c i } \Phi_i = \{x_i, r_i, q_i, \alpha_i, c_i\} Φi={xi,ri,qi,αi,ci}。为了将3D高斯渲染为2D图像,使用了高度优化的基于栅格化的实现。
为了生成给定单张图像 I ref I_{\text{ref}} Iref 的粗略几何,采用 Zero1-to-3 XL作为预训练参数 ϕ \phi ϕ 的2D扩散先验 ϵ ϕ \epsilon_\phi ϵϕ。该先验能够基于给定图像 I ref I_{\text{ref}} Iref 和相对相机姿态 Δ π \Delta\pi Δπ 对新视图进行去噪。使用SDS优化3D高斯 Ψ \Psi Ψ。
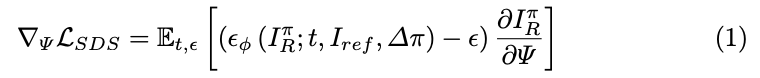
其中, π \pi π 表示围绕对象采样的相机姿态,具有固定的相机半径和视场角(FoV)。 I R π I^\pi_R IRπ 是从3D高斯集合 Ψ \Psi Ψ 中使用相机姿态 π \pi π 渲染的图像,时间步长 t t t 被退火以对添加到渲染图像中的高斯噪声 ϵ \epsilon ϵ 进行加权。除了这种基本方法之外,还引入了一种基于Top-K梯度的加密策略来加速收敛,并添加两个正则化项以增强重建的几何形状。
基于Top-K梯度的加密策略:在优化过程中,发现使用简单梯度阈值的周期性加密由于SDS的随机特性而难以调整。因此,本文采用了一种更稳健的加密策略。在每个间隔期间,仅对具有Top-K梯度的高斯点进行加密,这种简单的策略可以在各种给定图像中稳定训练。
尺度与透射率正则化:本文添加了两个正则化项,以鼓励 Gaussian Splatting在此阶段学习更详细的几何形状。引入了尺度正则化以避免过大的3D高斯,并采用另一种透射率正则化以鼓励几何学习从透明到实心。此阶段的总体损失函数可以写为:

其中, L rgb L_{\text{rgb}} Lrgb 和 L mask L_{\text{mask}} Lmask 是在渲染的参考视图和给定图像之间计算的两个均方误差(MSE)损失。 T k = ∑ i α i ∏ j = 1 i − 1 ( 1 − α j ) T_k = \sum_i \alpha_i \prod_{j=1}^{i-1} (1 - \alpha_j) Tk=∑iαi∏j=1i−1(1−αj) 表示在 $I_{R}^\pi $ 中第 k k k 个像素的透射值,其中 N f g N_{fg} Nfg 是前景像素的总数。 τ \tau τ 作为一个超参数,从0.4逐渐退火到0.9,有效地随着时间的推移对透射进行正则化。
网格细化和纹理解耦
在细化阶段,重点是将通过Gaussian Splatting生成的粗糙几何体转化为符号距离场(SDF),并使用混合表示来优化其参数。这个阶段对于克服粗糙阶段遇到的挑战至关重要,特别是Gaussian Splatting常常引入的表面伪影。由于Gaussian Splatting无法直接提供表面法线的估计,无法采用传统的平滑方法来减轻这些伪影。为了解决这个问题,本文引入了一种混合网格表示,即将3D对象的几何体建模为可微分的等值面,并使用两个不同、解耦的网络来学习纹理。这种双重方法不仅可以平滑表面不规则性,还能显著提高3D模型的逼真度和整体质量。
几何表示:作者在方法中使用FlexiCubes来表示几何。FlexiCubes是一种可微分的等值面表示,允许对提取的网格几何和连接性进行局部灵活调整。对象的几何被描述为具有可学习权重的可变形体素网格。对于体素网格中的每个顶点 v i v_i vi,学习变形 δ i ∈ R 3 \delta_i \in \mathbb{R}^3 δi∈R3和符号距离场(SDF) s i ∈ R s_i \in \mathbb{R} si∈R。并为每个网格单元学习插值权重 β ∈ R 20 \beta \in \mathbb{R}^{20} β∈R20和分裂权重 γ ∈ R \gamma \in \mathbb{R} γ∈R,以定位双重顶点并控制四边形分裂。可以通过双重Marching Cubes算法以可微方式从中提取三角网格。为弥合学习到的粗糙几何与等值面表示之间的差距,本文首先使用局部密度查询从 Gaussian Splatting中提取密度场,然后应用Marching Cubes算法提取基网格 M coarse M_{\text{coarse}} Mcoarse。随后,本文在网格顶点 v i v_i vi处查询这个基网格以获得初始符号距离场(SDF) s ( v i ) s(v_i) s(vi)。为实现稳定优化,查询到的SDF按如下方式进行缩放:
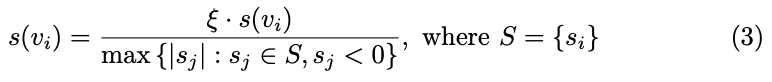
当 s j < 0 s_j < 0 sj<0 时,表示场在物体内部。缩放因子 ξ \xi ξ 在优化过程中线性增加,从 1 到 3。
解耦纹理表示。 在纹理学习中,采用哈希编码,后接一个 MLP 直接学习反照率。然而,与文本到3D任务不同,本文识别出该任务中的两个主要监督来源:提供的参考图像和来自2D扩散先验的SDS梯度。通常,为参考图像分配一个显著的损失权重 λ rgb \lambda_{\text{rgb}} λrgb。这种以参考图像为主的监督可能会减缓未见视角中纹理的收敛,特别是当未见视角与参考视角显著不同时。
为了解决这个问题,本文将纹理分为两个哈希编码,利用一个结合相对方位角 Δ θ = θ π − θ ref \Delta\theta = \theta_\pi - \theta_{\text{ref}} Δθ=θπ−θref 的比例,其中 θ π \theta_\pi θπ 表示采样相机姿态 π \pi π 的方位角, θ ref \theta_{\text{ref}} θref 是参考图像的方位角。给定查询点 κ \kappa κ 在光栅化三角网格中的哈希编码表示为:
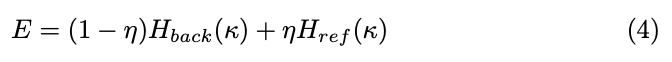
其中, H ref H_{\text{ref}} Href 和 H back H_{\text{back}} Hback 表示面向前方和后方的可学习哈希编码, η = ( cos ( Δ θ ) + 1 ) / 2 \eta = (\cos(\Delta\theta) + 1)/2 η=(cos(Δθ)+1)/2 是随采样的方位角变化的平衡因子。
将编码特征 E E E 输入到一个 MLP 中以预测反照率值。通过这些几何和纹理表示,本文可以通过内存高效的光栅化结合朗伯反射对3D对象进行渲染。
上述可学习参数 Θ \Theta Θ 通过 ∇ Θ L refine \nabla_{\Theta}L_{\text{refine}} ∇ΘLrefine 进行优化。
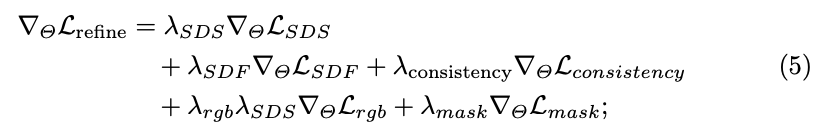
其中, L SDF L_{\text{SDF}} LSDF 是一个简单的SDF正则化项,避免浮动; L consistency L_{\text{consistency}} Lconsistency 是应用于表面法线的平滑损失; L rgb L_{\text{rgb}} Lrgb 和 L mask L_{\text{mask}} Lmask 是渲染的参考视图与给定图像之间的两个均方误差损失。
通过预先构图实现黑暗面多样性
在实现pipeline时,遇到了与未见视角缺乏多样性相关的关键挑战。这一问题主要源于依赖Zero-1-to-3 XL先验,该模型是在ObjaverseXL中的合成3D物体上训练的。虽然该先验在基于参考图像和相对相机姿态进行3D感知生成方面表现出色,但在未见视角中往往会产生过于简化或过于平滑的结果。当处理真实世界中捕获的物体时,这一限制尤为明显。
为了解决这个问题,研究者们引入了来自Stable-Diffusion的额外先验,以其合成多样化图像的能力而闻名。
使用2D扩散进行Darkside多样化 研究者们引入了第二个先验, ϵ ρ \epsilon_\rho ϵρ,其预训练参数为 ρ \rho ρ,从而导致两个Score Distillation Sampling (SDS)损失项 ∇ L SDS ϕ \nabla L^\phi_{\text{SDS}} ∇LSDSϕ和 ∇ L SDS ρ \nabla L^\rho_{\text{SDS}} ∇LSDSρ(公式1)进行优化。如何在这两个先验之间达到最佳平衡仍然相对未被探索。虽然Magic123 对后者项使用了1/40的经验损失权重,但这种方法可能无法充分利用2D先验的潜力。引入这个2D先验的关键目标是增加未见视角的多样性。一个较小的 ∇ L SDS ρ \nabla L^\rho_{\text{SDS}} ∇LSDSρ权重可能会大大限制其效果。
为了增强给定图像未见方面的多样性,本文采用梯度约束方法来合并这两个先验。将SDS损失重新表述为得分函数, ∇ Θ L SDS ( ϕ , x ) = − E t , z t ∣ x ∇ Θ log p ϕ ( z t ∣ y ) \nabla_\Theta L_{\text{SDS}}(\phi, x) = -E_{t,z_t|x}\nabla_\Theta \log p_\phi(z_t|y) ∇ΘLSDS(ϕ,x)=−Et,zt∣x∇Θlogpϕ(zt∣y),其中 t t t是时间步, z t z_t zt是噪声潜变量。
这里, ∇ L SDS ϕ \nabla L^\phi_{\text{SDS}} ∇LSDSϕ是一个以 y = { Δ π , I ref } y = \{\Delta\pi, I_{\text{ref}}\} y={Δπ,Iref}为条件的3D感知项,而 ∇ L SDS ρ \nabla L^\rho_{\text{SDS}} ∇LSDSρ是一个以文本提示 y = P T y = P_T y=PT为条件的多样化文本到图像项。由于条件 y y y不同,这两个SDS项的得分函数也不同。为了保持未见视角的3D一致性, ∇ Θ log p ρ ( z t ∣ y ) \nabla_\Theta \log p_\rho(z_t|y) ∇Θlogpρ(zt∣y)的幅度需要相对于3D感知项 ∇ Θ log p ϕ ( z t ∣ y ) \nabla_\Theta \log p_\phi(z_t|y) ∇Θlogpϕ(zt∣y)进行约束。并且,为了避免纹理被3D感知扩散模型过度平滑, ∇ Θ log p ϕ ( z t ∣ y ) \nabla_\Theta \log p_\phi(z_t|y) ∇Θlogpϕ(zt∣y)的幅度确实需要与 ∇ Θ log p ρ ( z t ∣ y ) \nabla_\Theta \log p_\rho(z_t|y) ∇Θlogpρ(zt∣y)项进行约束。
基于角度的得分合成 由于两个先验中的噪声潜变量 z t z_t zt具有不同的编码空间,无法通过预测的噪声差异 ϵ ρ − ϵ \epsilon_\rho - \epsilon ϵρ−ϵ直接评估其幅度。相反,本文通过观察它们在渲染图像 x x x上的梯度,特别是 ∇ x L SDS \nabla_x L_{\text{SDS}} ∇xLSDS,来评估这些项的幅度。因此,本文为这两个SDS项的梯度幅度比建立了上下界,从而实现更准确和可行的评估方法:
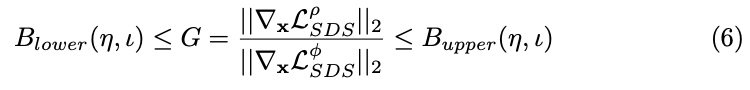
当这个比率超过 B upper B_{\text{upper}} Bupper 时,本文使用因子 B upper / G B_{\text{upper}}/G Bupper/G 调整 ∇ x L SDS ρ \nabla_x L^{\rho}_{\text{SDS}} ∇xLSDSρ 的幅度。相反,如果比率低于 B lower B_{\text{lower}} Blower,使用 G / B lower G/B_{\text{lower}} G/Blower 缩放 ∇ x L SDS ϕ \nabla_x L^{\phi}_{\text{SDS}} ∇xLSDSϕ 的幅度。这个 B upper B_{\text{upper}} Bupper 和 B lower B_{\text{lower}} Blower 由平衡因子 η \eta η 调节,受相机姿态和迭代次数 ι \iota ι 的影响,以促进多样性和3D一致性之间的平衡。
实验
实验细节
粗略几何学习 在这个阶段,输入图像经过SAM的预处理,提取并重新中心化物体。本文将所有3D高斯体初始化为不透明度为0.1,颜色为灰色,限制在半径为0.5的球体内。渲染分辨率逐步从64增加到512。这个阶段总共涉及500个优化步骤,每100次迭代进行3D高斯体的稠密化和修剪。top-K稠密化从0.5的比例开始,逐渐退火到0.1,而修剪不透明度保持在0.1。第一次稠密化后,开启透射率正则化,并选择性地应用于3D高斯体不透明度最高的80%,以避免影响透明的高斯体。尺度正则化使用L1范数进行。 λ scale \lambda_{\text{scale}} λscale和 λ tr \lambda_{\text{tr}} λtr的权重在整个优化过程中保持在0.01和1,而 λ rgb \lambda_{\text{rgb}} λrgb和 λ mask \lambda_{\text{mask}} λmask则逐渐从0增加到10000和1000。SDS的时间步长从980线性退火到20。对于相机姿态采样,方位角在[-180, 180]范围内采样,仰角在[-45, 45]范围内,固定半径 r = 2 r = 2 r=2。优化粗略几何的这个阶段大约需要30秒。
网格细化 在细化阶段,本文将FlexiCubes的网格尺寸配置为 8 0 3 80^3 803,在空间 [ − 1 , 1 ] 3 [-1, 1]^3 [−1,1]3内。初始阶段获得的粗略几何重新中心化并重新缩放,以初始化该网格顶点的有符号距离场(SDF)。插值权重设置为1,所有变形从0开始。对于纹理,本文使用两个哈希编码和一个两层的多层感知机(MLP)。批量大小保持为4。变形和插值权重的学习率为0.005,SDF的学习率为0.001,纹理参数的学习率为0.01。渲染分辨率逐步从64增加到512。在方程5中,损失权重设置如下: λ rgb = 1500 \lambda_{\text{rgb}} = 1500 λrgb=1500, λ mask = 5000 \lambda_{\text{mask}} = 5000 λmask=5000, λ sdf = 1 \lambda_{\text{sdf}} = 1 λsdf=1, λ SDS = 1 \lambda_{\text{SDS}} = 1 λSDS=1。本文开发了两个版本的优化:Vista3D-S和Vista3D-L。Vista3D-S仅使用3D感知先验进行1000步优化,目标是在5分钟内生成3D网格。Vista3D-L进行2000步优化,使用两个扩散先验以创建更详细的3D对象。整个Vista3D的优化过程大约需要15到20分钟。在这个阶段,相机姿态使用3D感知高斯反采样策略来加速收敛。所有实验均在RTX3090 GPU上进行。
得分蒸馏采样 在SDS优化中,线性退火时间步长 t t t以调整噪声水平被证明对生成高质量3D对象有效。然而,在本文的实验中,本文观察到线性退火可能不是最佳策略。因此,本文实施了一种区间退火方法。在这种方法中,时间步长 t t t从退火区间中随机采样,而不是遵循固定的线性进程。该策略被发现能够有效缓解线性退火常见的伪影。
在本文的模型中,本文使用了两个扩散模型:Zero-1-to-3 XL 和 Stable-Diffusion 模型。对于 Stable-Diffusion 模型,时间步 t t t 被缩放因子 η \eta η 调整,以确保与参考视图的一致性。当使用两个扩散先验进行编辑时,本文从一个较大的初始上限 B upper = 100 B_{\text{upper}} = 100 Bupper=100 开始,并在优化迭代中线性退火至 10。对于正面视图,当 η > 0.75 \eta > 0.75 η>0.75 时,本文使用因子 ( 1 − η ) (1-\eta) (1−η) 调整上限。下限专门用于 η < 0.5 \eta < 0.5 η<0.5 的未见视图,其范围在优化过程中逐渐从 10 减少到 1。对于使用扩散先验的增强,本文应用更严格的约束,将 B upper B_{\text{upper}} Bupper 从 2 减少到 0.5。用于 Stable-Diffusion 模型的文本提示来自 GPT-4 生成的图像标题。
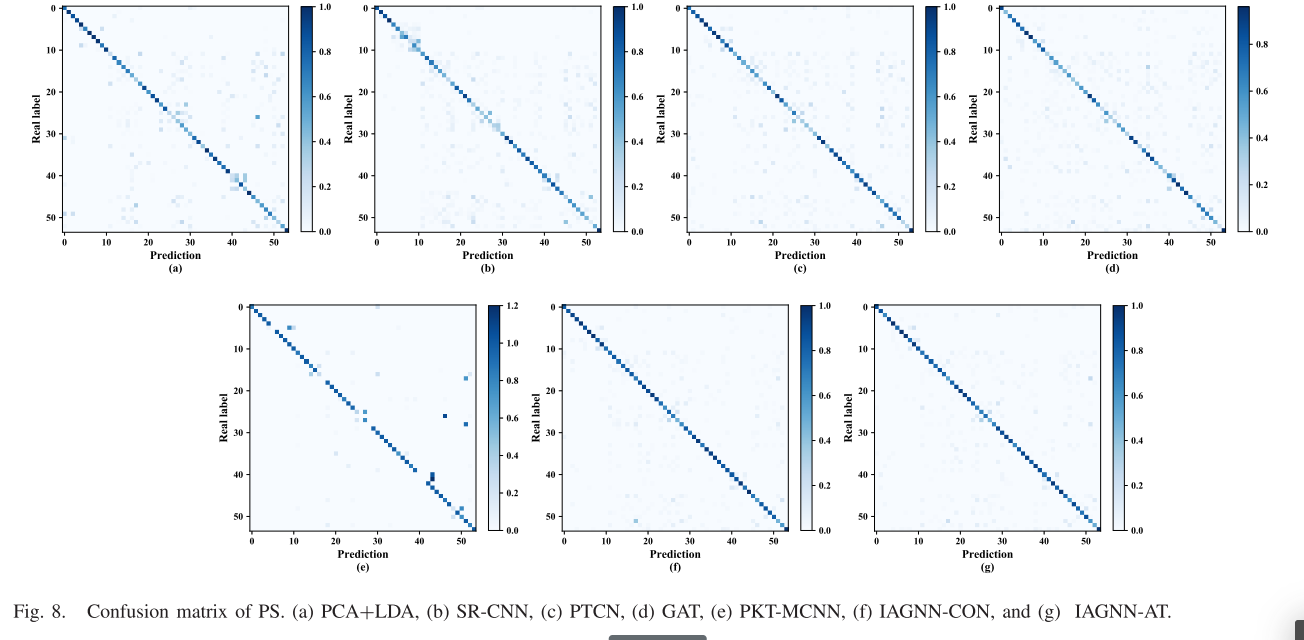
定性比较
在下图3中,本文展示了高效的Vista3D-S能够以比现有粗到细方法快20倍的速度生成具有竞争力的3D对象。对于Vista3D-L,如上图1和下图4所示,本文强调了本文的角度梯度约束,这使得本文的框架区别于以往的图像到3D方法,因为它可以在不牺牲3D一致性的情况下探索单幅图像背面的多样性。在下图3中,本文主要将Vista3D-S与两个基准方法Magic123和DreamGaussian进行比较,用于从单一参考视图生成3D对象。在生成的3D对象质量方面,本文的方法在几何和纹理上都优于这两种方法。关于Vista3D-L,本文将其与两个仅推理的单视图重建模型进行比较,具体来说是One-2-3-45和Wonder3D。如下图4所示,One-2-3-45往往会产生模糊的纹理,并可能导致复杂对象的几何不完整,而本文的Vista3D-L通过用户指定的文本提示实现了更精细的纹理,特别是在3D对象的背面。Wonder3D由于主要在合成数据集上训练,通常采用更简单的纹理,这偶尔会导致某些对象的分布外问题。相比之下,Vista3D-L通过控制两个扩散先验提供零样本3D对象重建,从而实现更详细和一致的纹理。此外,鉴于仅提供对象的单一参考视图,本文认为对象在优化过程中应该可以通过用户指定的提示进行编辑。为了说明这一点,本文在图1中展示了几个强调编辑潜力的结果。


定量比较
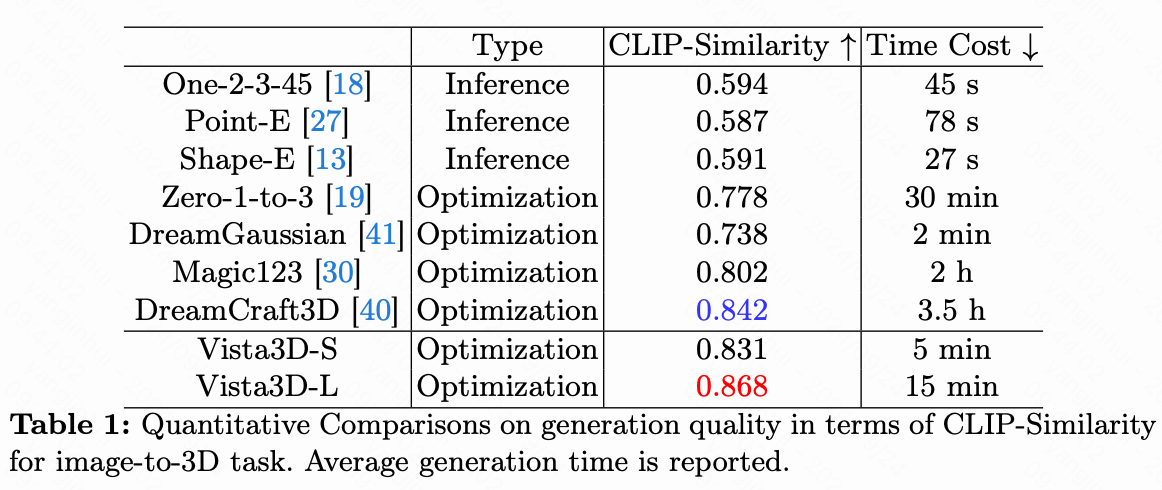
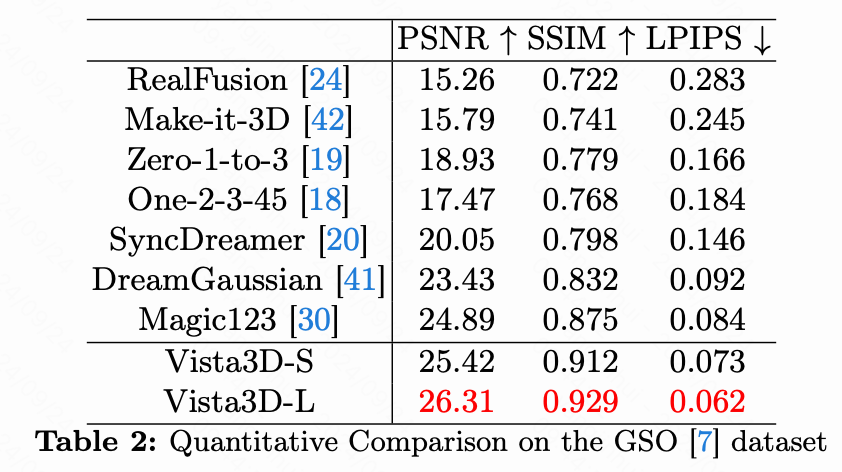
在本文的评估中,本文使用CLIP相似度指标来评估本文的方法在使用RealFusion数据集进行3D重建时的性能,该数据集包含15张不同的图像。与以往研究中使用的设置一致,本文在每个对象的方位角范围为[-180, 180]度的零仰角处均匀采样8个视图。然后使用这些渲染视图和参考视图的CLIP特征计算余弦相似度。下表1显示,Vista3D-S获得了0.831的CLIP相似度分数,平均生成时间仅为5分钟,从而超越了Magic123的性能。此外,与另一种基于优化的方法DreamGaussian相比,尽管Vista3D-S可能需要5分钟的时间,但它显著提高了一致性,这从更高的CLIP相似度分数中得到了证明。对于Vista3D-L,本文应用了仅增强设置。通过使用角度扩散先验组合,本文的方法实现了更高的0.868 CLIP相似度。Vista3D-L的能力,特别是在通过先验组合生成具有更详细和逼真纹理的对象方面,在图4中得到了展示。此外,本文在Google Scanned Object (GSO)数据集上进行了定量实验,遵循SyncDreamer的设置。本文使用30个对象评估每种方法,并计算3D对象的渲染视图与16个真值anchor视图之间的PSNR、SSIM和LPIPS。结果如下表2所示,显示本文的Vista3D-L在这些方法中以较大优势实现了SOTA性能。尽管Vista3D-S只有单一扩散先验,但也展示了具有竞争力的性能。
用户研究
在本文的用户研究中,本文评估了参考视图一致性和整体3D模型质量。评估涵盖了四种方法:DreamGaussian 、Magic123,以及本文自己的Vista3D-S和Vista3D-L。本文招募了10名参与者进行这项用户研究。每位参与者被要求根据视图一致性和整体质量分别对不同方法生成的3D对象进行排序。因此,每个指标的得分范围为1到4。下表3中的结果显示,本文的Vista3D-S在视图一致性和整体质量上均优于之前的方法。此外,Vista3D-L中采用的角度先验组合进一步提高了生成3D对象的一致性和质量。

消融研究
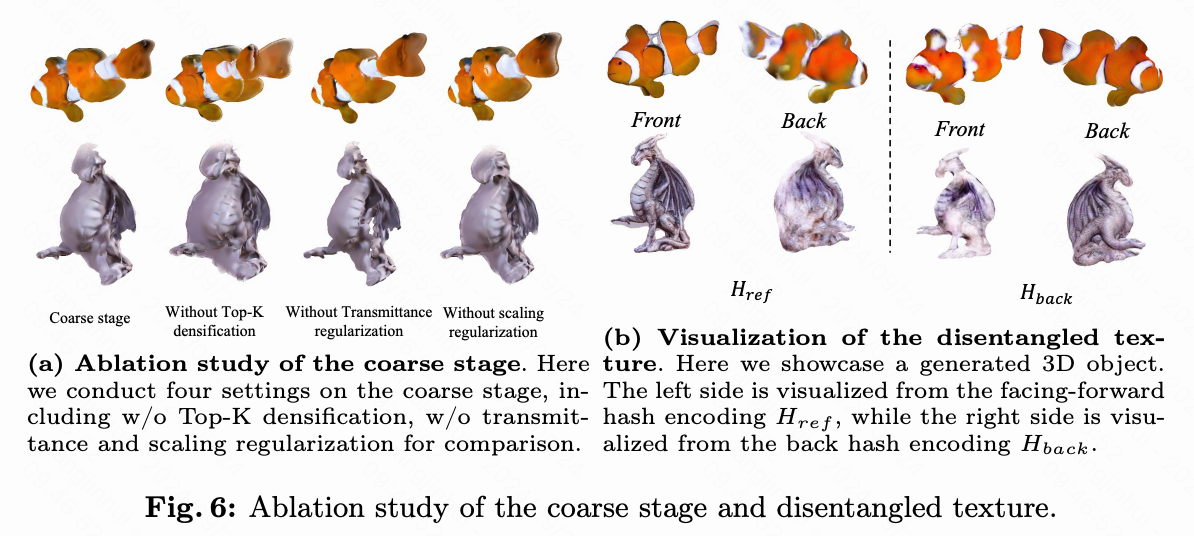
粗到细框架。 本文的框架集成了一个粗略阶段以学习初始几何形状,然后是一个细化阶段以优化几何形状和着色纹理。本文在下图5(a)中验证了这种粗到细流程的必要性。本文首先使用等值面表示直接学习几何形状,发现如果没有初步的几何初始化,几何优化容易崩溃。因此,粗略初始化变得至关重要。此外,本文展示了从粗略阶段的3DGS中提取的粗糙网格的法线贴图。可以观察到,粗略阶段往往会生成粗糙甚至不闭合的几何形状,且难以缓解。这些发现表明,结合这两个阶段对于Vista3D的最佳性能是至关重要的。

纹理解耦。 为了验证解耦纹理的有效性,本文在上图5(b)中比较了同时采用双哈希编码与单哈希编码的效果。使用双哈希编码时,重建的机器人上的伪影显著减少,尤其是在背面。此外,本文在下图6(b)中可视化了解耦的纹理。具体来说,当可视化 H ref H_{\text{ref}} Href时, H back H_{\text{back}} Hback在公式4中被设为0,反之亦然。从展示的可视化中,本文可以清楚地发现,面向前的哈希编码 H ref H_{\text{ref}} Href主要编码与给定参考视图一致的细节特征。而背面哈希编码 H back H_{\text{back}} Hback主要编码未见视图中的特征。面向前视图和背面视图的纹理被解耦并在两个独立的哈希编码中学习,这有助于在参考视图附近和未见视图中学习更好的纹理。
结论
本文提出了一种从粗到细的框架 Vista3D,以探索单张输入图像的3D暗面。该框架通过文本提示实现用户驱动的编辑,或通过图像字幕提高生成质量。生成过程从通过高斯喷射获得的粗略几何开始,随后使用等值面表示进行细化,并辅以解耦的纹理。这些3D表示的设计能够在短短5分钟内生成纹理网格。此外,扩散先验的角度组合使本文的框架能够揭示未见视角的多样性,同时保持3D一致性。本文的方法在现实感和细节方面超越了以往的方法,在生成时间和纹理网格质量之间达到了最佳平衡。本文希望本文的贡献能够激励未来的进步,并促进对单张图像3D暗面的进一步探索。
参考文献
[1] Vista3D: Unravel the 3D Darkside of a Single Image