今日指数项目项目集成RabbitMQ与CaffienCatch
一. 为什么要集成RabbitMQ
首先CaffeineCatch 是作为一个本地缓存工具 使用CaffeineCatch 能够大大较少I/O开销
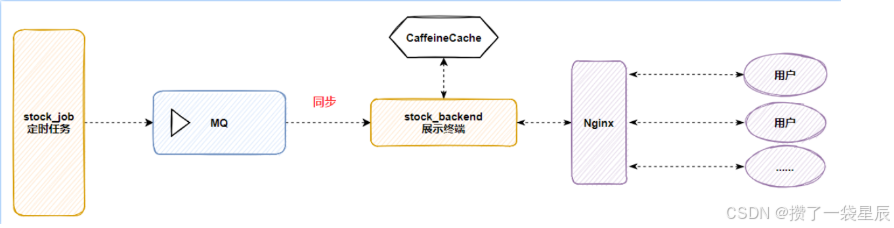
股票项目 主要分为两大工程 --> job工程(负责数据采集) , backend(负责业务处理)
由于股票的实时性也就是说 , 对于股票来说像大盘数据 , 个股数据等都是每分钟进行更新的
而使用传统的采集以及业务处理方式 , 也就是说 数据采集后将数据保存到数据库中 , 然后客户从数据库中反复获取数据
当用户数量增多 , 数据库的I/O开销也会随之增大 , 会导致时效性的降低
所以这里我采用MQ加CaffeineCatch , 在job工程中采集数据后 写入数据库 , 同时通过MQ发送消息给backend工程 重新加载缓存
将数据库中的数据读取到CaffeineCatch 中
二. job工程代码实现
1. 导入mq依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency>
2. 定义配置文件
spring:rabbitmq:host: 114.116.244.165 # rabbitMQ的ip地址port: 5672 # 端口username: jixupassword: 123321virtual-host: /
3. 编写服务端代码
package com.jixu.stock.config;import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class MqConfig {// 定义大盘消息序列化方式@Beanpublic MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}// 定义主题交换机@Beanpublic TopicExchange topicExchange(){return new TopicExchange("stockExchange",true,false);}// 定义大盘队列@Beanpublic Queue stockMarketQueue(){return new Queue("marketQueue",true);}@Bean// 绑定大盘信息public Binding bindingStockeMarket(){// with( Routingkey 参数 --> 匹配的队列名称 )return BindingBuilder.bind(stockMarketQueue()).to(topicExchange()).with("inner.market");}
}
4. 定义客户端
package com.jixu.stock.config;import lombok.extern.slf4j.Slf4j;
import org.joda.time.DateTime;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Date;@Configuration
@Slf4j
public class MqConfig {// 定义大盘消息序列化方式@Beanpublic MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}// 客户端接受信息@RabbitListener(queues = "marketQueue")public void stockMarketListener(Date date){long diffTime= DateTime.now().getMillis()-new DateTime(date).getMillis();//超过一分钟告警if (diffTime>60000) {log.error("采集国内大盘时间点:{},同步超时:{}ms",new DateTime(date).toString("yyyy-MM-dd HH:mm:ss"),diffTime);}}
}
3. 修改业务层代码
在数据插入成功后发送消息给MQ
log.info("当前时间点{} , 数据插入成功", DateTime.now().toString("yyyy-MM-dd HH-mm-ss"));
rabbitTemplate.convertAndSend("stockExchange","inner.market",new Date());
三. backend工程代码实现
首先在实现业务逻辑之前需要导入相关依赖 , 以及配置MQ和CaffineCache
1. 配置MQ配置类
package com.jixu.stock.config;import lombok.extern.slf4j.Slf4j;
import org.joda.time.DateTime;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Date;@Configuration
@Slf4j
public class MqConfig {// 定义大盘消息序列化方式@Beanpublic MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}}
2. 配置CaffineCache配置类
/*** 配置CaffienCatch*/@Beanpublic Cache<String,Object> caffeineCache(){Cache<String, Object> cache = Caffeine.newBuilder().maximumSize(200)//设置缓存数量上限
// .expireAfterAccess(1, TimeUnit.SECONDS)//访问1秒后删除
// .expireAfterWrite(1,TimeUnit.SECONDS)//写入1秒后删除.initialCapacity(100)// 初始的缓存空间大小.recordStats()//开启统计.build();return cache;}
3. 创建客户端类接收信息
package com.jixu.stock.mq;import com.jixu.stock.service.StockService;
import lombok.extern.slf4j.Slf4j;
import org.joda.time.DateTime;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.github.benmanes.caffeine.cache.Cache;
import java.util.Date;/*** @program: stock_parent* @description:* @author: jixu* @create: 2024-10-01 12:45**/
@Component
@Slf4j
public class StockMarketMQ {@Autowiredprivate Cache caffeineCache;@Autowiredprivate StockService service;// 客户端接受信息@RabbitListener(queues = "marketQueue")public void stockMarketListener(Date date){long diffTime= DateTime.now().getMillis()-new DateTime(date).getMillis();//超过一分钟告警if (diffTime>60000) {log.error("采集国内大盘时间点:{},同步超时:{}ms",new DateTime(date).toString("yyyy-MM-dd HH:mm:ss"),diffTime);}}
}在信息接受之后需要对业务层代码进行修改 --> 实现CaffineCache缓存
这里我们使用CaffineCache.get的方法 , 其中会传入两个参数 , 分别是要从CaffineCache中查询的数据的key ,以及如果key不存在使用的补救方法(从数据库中查询)
4. 完善业务代码
/*** 实现股票大盘数据查询* @return*/@Overridepublic R<ArrayList<InnerMarketDomain>> getInnerMarketDomain() {R<ArrayList<InnerMarketDomain>> msg = (R<ArrayList<InnerMarketDomain>>) caffeineCache.get("stockMarketMsg" , key -> {// 1. 获取最新时间数据Date curTime = DateTimeUtil.getLastDate4Stock(DateTime.now()).toDate();// 创建mock数据curTime = DateTime.parse("2022-01-02 09:32:00", DateTimeFormat.forPattern("yyyy-MM-dd HH:mm:ss")).toDate();// 2. 获取股票代码ArrayList<String> marketInfo = stockInfoConfig.getInner();// 3. dao层查询数据ArrayList<InnerMarketDomain> data = stockMarketIndexInfoMapper.getMarketInfo(curTime , marketInfo);return R.ok(data);});return msg;}
5. 完善StockMarketMQ类刷新数据
// 清除caffeineCache中的缓存
caffeineCache.invalidate("stockMarketMsg");
// 调用service重新获取
service.getInnerMarketDomain();






