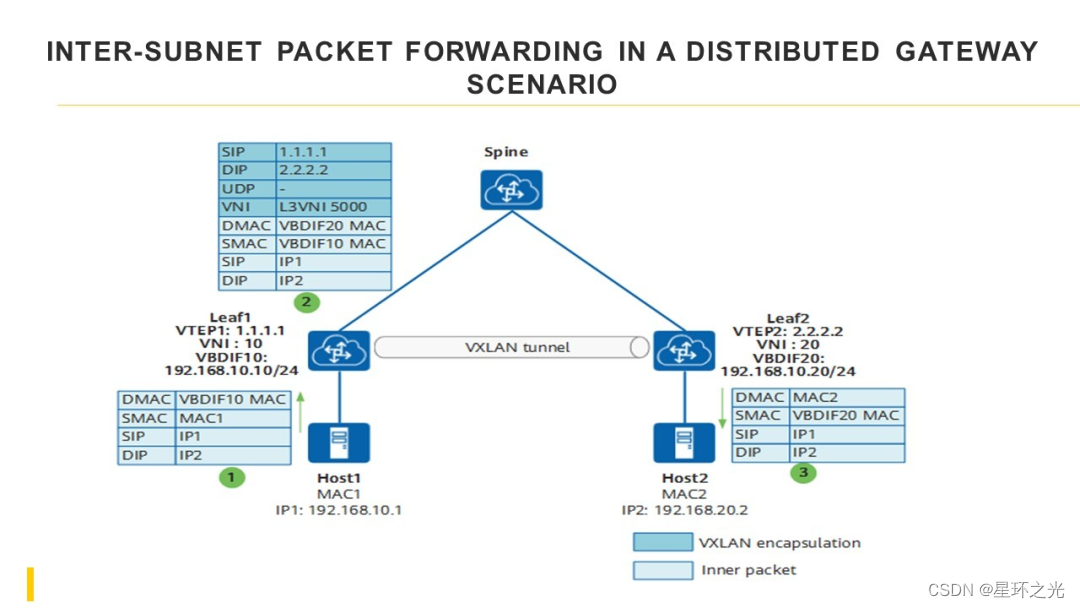
一.分区简述
1)分区的背景:当表中的数据量不断增大,查询数据的速度就会变慢(且加了索引 之后,仍然没有改观时),这时就可以考虑对表进行分区。 2)分区的粒度:某张表的大小超过2GB,直观点说,如果每个月(每年)某个表的 数据量都在百万以上,那就需要对该表以月(年)作为分区;即分区的粒度一般为 百万级数据量 3)分区表的结构:表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的 数据在物理上存放到多个表空间(物理文件上),这样查询数据时, 不至于每次都扫描整张表
二.分区步骤
1.创建文件组和文件右键单击要分区的数据库,单击属性,弹出如图下对话框,在此对话框中建立文件组和文件,以用于存储各分区表数据。如果以年作为分区界限,则以年为单位建立文件组和文件;若以月作为分区界限,则以月为单位建立文件组和文件。

2.文件组和文件建立好以后,开始对大数据量的表进行设计分区方案和分区函数

3.点击创建分区,弹出”创建分区向导”对话框。指定分区列

4.创建分区函数:分区函数会根据列中的值所对应的范围创建对应的文件

5.创建创建分区方案:分区方案会把分区函数创建的文件归类到指定的文件组中

6.设置分区表各个时间段的数据所对应的文件组,最好同一类数据表的不同分区文件对应不同 的文件组


7.可通过”立即运行”,直接创建表分区

三.分区结果确认
1)直接右键表,查看成功与否

2)通过SQL语句查看
a.查看分区依据列的指定值所在的分区 select $partition.bgPartitionFun(‘2017-09-21’) --返回值是2,表示此值存在第2个分区
b.查看分区表中,每个非空分区存在的行数 select $partition.bgPartitionFun(Business) as partitionNum,count(*) as recordCount from FoodBill group by $partition.bgPartitionFun(Business)
c.查看指定分区中的数据记录 select * from FoodBill where $partition.bgPartitionFun(Business)=2
四.分区注意事项
1)最好在部署完数据库就去做分区,这样可以避免产生很多不必要的冗余数据。如果是数据库运行一段时间后,再做的分区,分区后,原来的数据会在原有磁盘上和分区后的磁盘文件上分别存放。
2)做分区时,被分区的表不能有任何增删改查操作,否则分区时间会很长,而且增删改查也做不了,会相互抢占资源,形成死锁。
五.分区SQL
1)创建文件组 alter database kmcy_cloud_dz add filegroup G_kmcy_201706 alter database kmcy_cloud_dz add filegroup G_kmcy_201712 alter database kmcy_cloud_dz add filegroup G_kmcy_201806 alter database kmcy_cloud_dz add filegroup G_kmcy_201812 2)
创建文件 alter database kmcy_cloud_dz add file (name=N‘f_kmcy_201706',filename=N‘D:\DB\kmcy\f_kmcy_201706.ndf',size=5Mb,filegrowth=5mb) to filegroup G_kmcy_201706 alter database kmcy_cloud_dz add file (name=N‘f_kmcy_201712',filename=N‘D:\DB\kmcy\f_kmcy_201712.ndf',size=5Mb,filegrowth=5mb) to filegroup G_kmcy_201712 alter database kmcy_cloud_dz add file (name=N‘f_kmcy_201806',filename=N‘D:\DB\kmcy\f_kmcy_201806.ndf',size=5Mb,filegrowth=5mb) to filegroup G_kmcy_201806
3)创建分区函数 CREATE PARTITION FUNCTION [bgPartitionFun](DateTime) AS RANGE LEFT FOR VALUES (N‘2017-06-01', N‘2017-12-01', N‘2018-06-01', N‘2018-12-01', N‘Primary’) 4)创建分区方案 CREATE PARTITION SCHEME [bgPartitionSchema] AS PARTITION [bgPartitionFun] TO ([G_kmcy_201706], [G_kmcy_201712], [G_kmcy_201806], [G_kmcy_201812], [Primary])