课程主页:Guoliang Li @ Tsinghua
继续补充DBMS概况:
DBMS概况
存储管理层

缓冲区管理
为了持久保存数据库里面的数据,必定要做持久化技术,也就是会用到磁盘,然而磁盘读取数据的速度是比较慢的,一般是毫秒级,所以就有了内存来配合数据的存储,也就是会做缓冲区管理。
磁盘读取的速度为什么慢?因为数据存储在磁盘的轨道里,轨道上方有一个磁头,可以从圆心移动到任一轨道,当要读取某个轨道的数据时,磁头需要转动到指定轨道,也叫做寻道。寻道的时间影响了数据读取的速度。
内存全称是随机存取存储器(RAM),为了提高读写速度,会在内存中划分出来一块区域即缓冲区也叫内存缓冲池(Buffer),用来缓存那些从磁盘读取的数据页,数据页是指数据库里存储数据的存储单元,类似于书页(一个容器)。当要找某一数据页中的数据时,会首先在缓冲池中寻找,如果找不到(缓存未命中),就会去磁盘里寻找,并把数据页存放到缓冲池中去,也方便了后续的操作;如果找到了(缓存命中)那就直接从内存读取而且当要写入数据时,不会直接写进磁盘里,而是先在缓冲池中寻找有没有对应的数据在缓冲池中进行数据的写入,如果缓冲命中直接修改数据,缓冲若未命中就会从磁盘中读取数据页到缓冲池,之后再更新到磁盘中去即延迟写入技术(异步去修),可以减少磁盘I/O操作的频率(I/O操作指输入输出操作,即硬件设备和内存之间的数据交换过程)即减少直接读取磁盘提高性能。
索引
类似于书籍的目录,用来检索数据,索引可以将检索的速度从O(n)的时间复杂度变成O(logn)甚至O(1),其中n是数据行数。使用B树或B+树结构的索引方法可以让O(n)的复杂度变成O(logn),这是因为数据被组织成了树状结构,这意味着可以通过逐级查找数据,而在理想情况下可以通过哈希算法(哈希函数)直接定位到数据所在的位置即O(1)的复杂度。
事务处理
是一系列对数据的操作,这些操作要么成功执行要么全都失败(比如银行转账,付款方账户和收款方的账户要同时发生变化,可以视为一个原子性变化,保证了数据的一致性)
故障恢复
日志是记录数据库操作历史的数据文件,当出现故障需要恢复时有利于找到问题,而且日志也让随机的数据读写变成追加性且记录是不可更改的。而且:当数据在内存中被修改时,数据库系统通常会将这些修改的记录先追加到内存中的日志缓冲区。然后,这些日志记录会被异步地写入到磁盘上的日志文件中。这个过程是为了确保即使在修改数据后但尚未写入磁盘之前发生系统崩溃(如电脑突然关机),这些更改也不会丢失。也就是说缓冲池和磁盘上都有日志文件,记录数据的更改历史。
讲完这些我们来看一张更为详细一点的图:
下方的“数据库”可以看作磁盘然后上方的“数据库管理系统”可以看作内存,可以看到内存和磁盘中都有索引和日志管理。
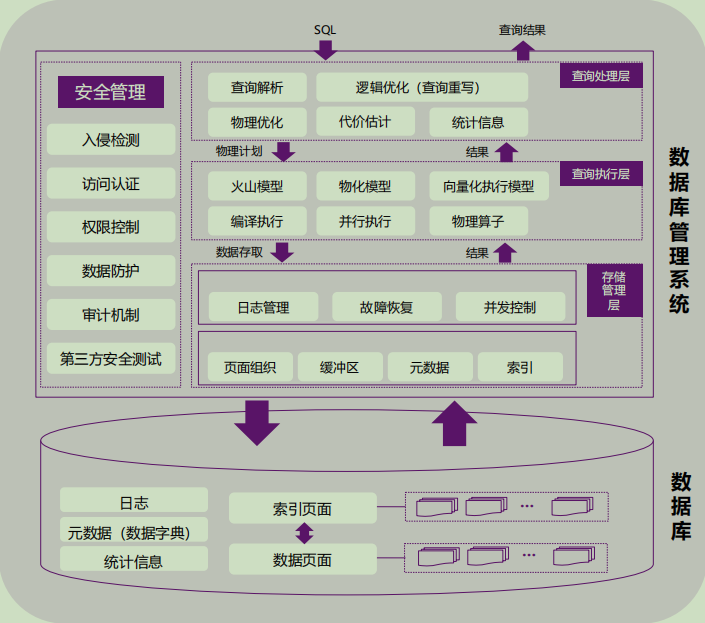
图中的元数据是指:
比如图书馆中有Books这么一个表:表里面有这些“元数据”
BookID:整数(用于唯一标识每本书)
Title:字符串(书籍的标题)
Author:字符串(书籍的作者)
ISBN:字符串(国际标准书号)
PublishDate:日期(书籍的出版日期)
Genre:字符串(书籍的类型,如小说、非小说、科技等)
ShelfLocation:字符串(书籍在图书馆的具体位置)后面我们就对DBMS进行深入讨论。





