作者:胡志广(独鳌)
背景
Serverless 应用引擎 SAE 事件中心主要面向早期的 SAE 控制台只有针对于应用维度的事件,这个事件是 K8s 原生的事件,其实绝大多数的用户并不会关心,同时也可能看不懂。而事件中心,是希望能够成为一个更高维度入口,可以总览全局的事件(着重于异常事件),并且配置相关的通知与告警。
建设事件中心和监控最大的区别在于:
- 监控: 监控主要在关注异常指标的监控告警和可观测能力上。
- 事件中心: 主要是系统进行诊断抽象后面向用户更紧急和具体定位的事件可以让用户进行一键订阅和提前告警,面向智能运维的方向进行建设。
事件中心的核心意义在于通过显示、通知来将 SAE 上的应用与用户更紧密的连接起来。
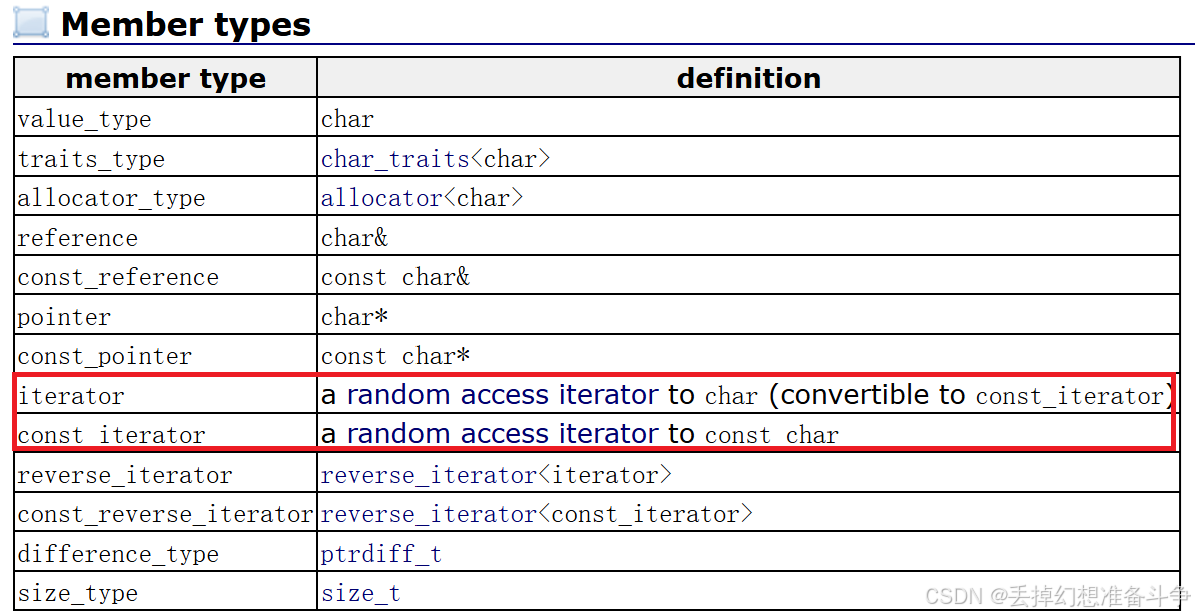
事件中心整体能力大图如下:
SAE Web 上线后对于用户的事件需求更加的敏感,因为 Web 支持百毫秒弹性,所以对于事件的实时性和可靠性的要求更高,对于用户的通知和告警消息感知也更重要,针对这些需求 SAE 针对 Web 进行开发了事件中心让用户可以更好的感知异常事件。
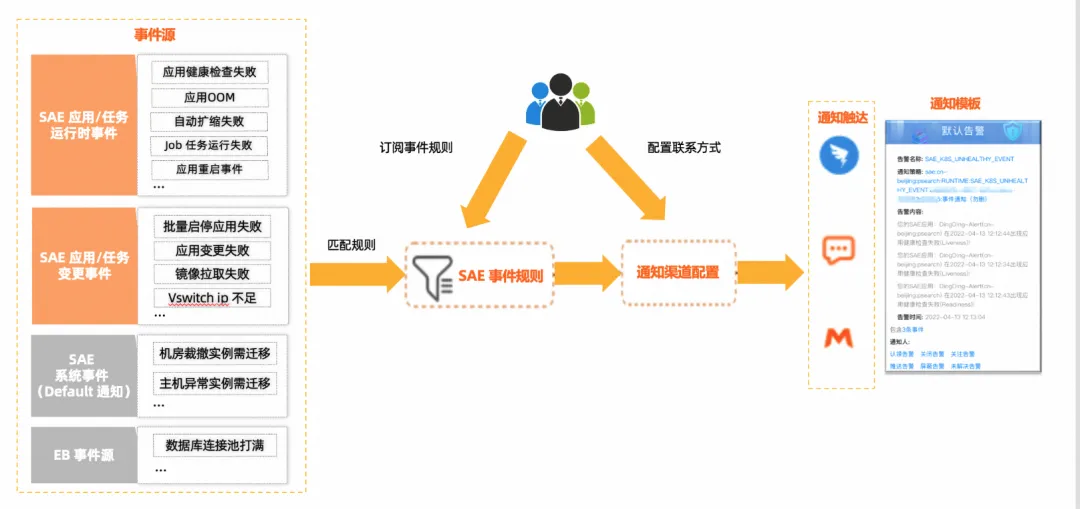
整体架构
-
资源服务
- K8s:针对 K8s 的原始事件等各种记录入库,包括 pod、workload、网络等。
- 极速系统:主要是针对 Web 的场景开发的百毫秒资源服务,实时性和弹性高,这里主要将实例信息、版本切换事件原始信息入库。
-
事件中心
- 事件消费:主要实时消费日志库中的原始数据进行监听。
- 事件诊断:原始数据量过大冗余信息也多,所以需要事件诊断进行数据清洗和把中间数据写入 cache 临时保存。
- 事件生成:数据诊断完成后,根据固定的事件模型写入到事件库保存。
- 事件消息规则订阅:根据用户订阅的规则将生成好的事件通过消息通知服务进行告警通知,包括:钉钉、短信、邮件等。
技术挑战
技术选型
-
全新实现一套 SAE Web 事件架构
- 优点:历史包袱小,实现更优雅。
- 缺点:研发周期长和之前的前后端需要兼容。
-
基于 SAE 微服务事件架构实现
- 优点:事件模型是现成的,实现简单和现有系统兼容。
- 缺点:无法处理 Web 的海量数据,存在数据瓶颈。
-
最终方案: 事件模型采用 SAE 微服务事件中心架构实现写入,但是 Web 的事件不直接写入事件而是通过一层数据清洗后写入事件库避免信息爆炸。
数据爆炸
资源数据架构现状
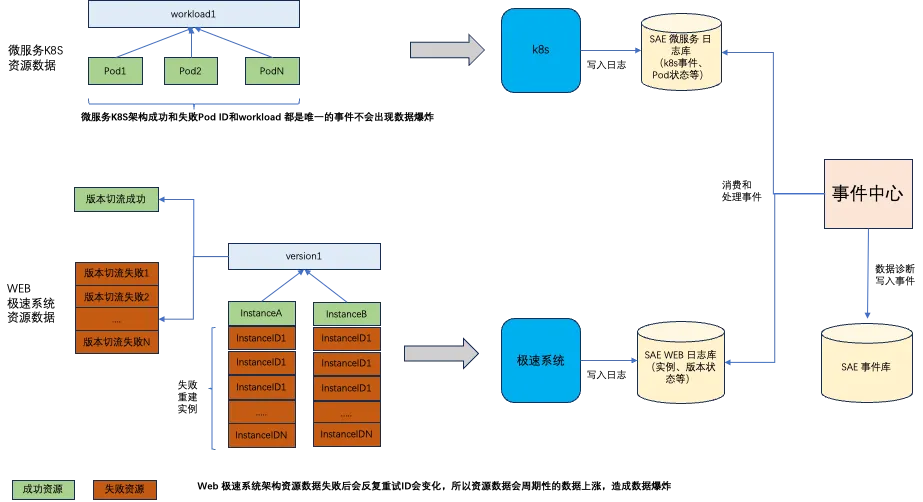
微服务 K8s 资源架构
微服务 K8s 资源架构基于 K8s 基础之上建设的,所以对于 workload 和 pod 当资源异常状态的时候会重试非重建,所以 workload 的 key 和 pod 的 key 是唯一的,这时是不会造成事件信息的数据爆炸的,所以最终通过组件将原始事件信息写入到日志库中最终通过事件中心进行消费。
Web 极速系统资源架构
Web 是自主研发的一套极速系统可以实现百毫秒弹性实例的资源系统,可以通过流量控制弹性,闲置时进行缩容。
-
实例资源: 实例主要通过预留和弹性扩容的方式进行创建,一般通过流量控制弹性扩容,没有流量访问时则动态缩容。
- 实例弹性扩容/缩容成功:扩容和资源闲置时进行缩容,除了预留资源是固定的 ID,其他的资源可能随时弹出和缩容,这里和微服务 K8s 架构固定实例的模式有很大差异,所以资源实例数据也会多很多。
- 实例弹性扩容失败:当实例出现异常的时候(包括镜像拉取失败、健康检查失败、其他创建失败等原因),那么将会不断的进行重试,所以实例的 ID 也会变化,这时将会有很多的失败实例信息。
-
版本切流: 微服务 K8s 架构是根据 workload 进行部署发布,Web 是基于版本流量进行发布。
- 版本切流成功:版本切流成功就是产生一条事件,这里主要会根据版本比例产生一些事件信息。
- 版本切流失败:版本切流失败因为和实例弹性有关系,所以也受弹性实例失败影响,当弹性失败的时候版本切流同样也是失败会进行重试,并且版本切流还会存在部分成功和部分失败的场景,这种当面临同版本失败过多时也会存在信息爆炸的风险。
-
数据爆炸风险: 基于上述内容 Web 架构的实例会动态的扩容和缩容,失败的时候不断的重建实例造成 ID 会重建,包括版本失败的信息也和实例扩缩容有关系,所以资源的事件数据量要远远大于微服务 K8s 架构的事件数据。
解决方案
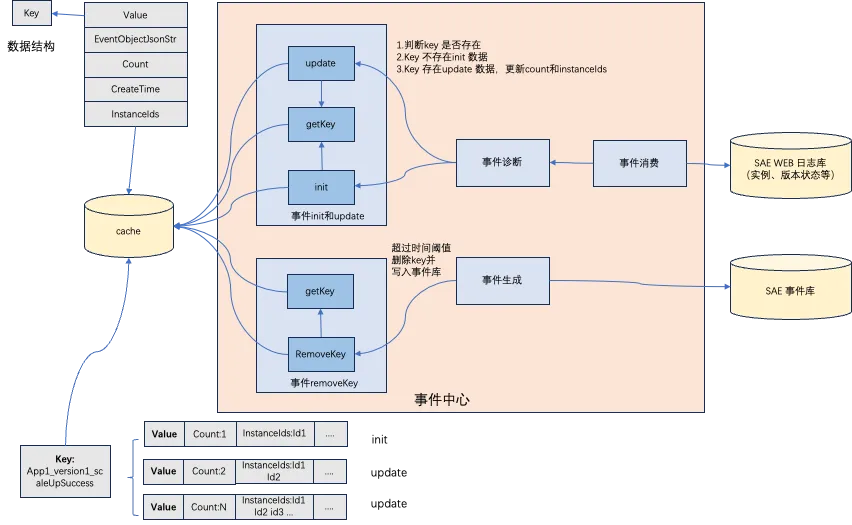
数据爆炸解决方案:通过分布式缓存进行数据聚合,根据时间阈值后进行事件生成,其实类似一种数据队列的模式。
- key:应用 ID+版本 ID+事件类型,如:app1_version1_scaleUpSuccess。
- 事件消费+初始化缓存:消费原始日志后判断事件 key 是否在缓存中,如果不在缓存中则调用 init 函数初始化 cache 数据,初始化 count:1 和 instanceId:1,如果失败的则不存在 InstanceId。
- 事件消费+更新缓存:消费原始日志后如果事件 key 在缓存中则将缓存数据进行更新 count 和 instanceId 进行聚合,如:count2,instanceIds:id1,id2 这样(之前只有 id1),以此类推。
- 事件生成:根据时间阈值定时出队,比如 60s 后,如果 key 内的 createtime 超过 60s 则调用 remove 方法删除缓存事件生成到标准的 sae 事件库中按照格式。
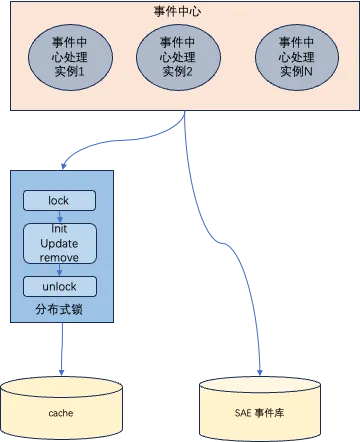
数据爆炸最初用的缓存方案,但是没有采用分布式锁,所以出现了事件中心管控多任务实例造成了同一个事件写入重复多份的问题,下面有问题和优化方案。
- 问题:最初只是在内存中保存,所以当多实例时每个实例都会写入到事件库就会存在数据冗余。
- 优化方案:队列采用分布式锁的方式处理,避免多实例重复写入事件的问题。
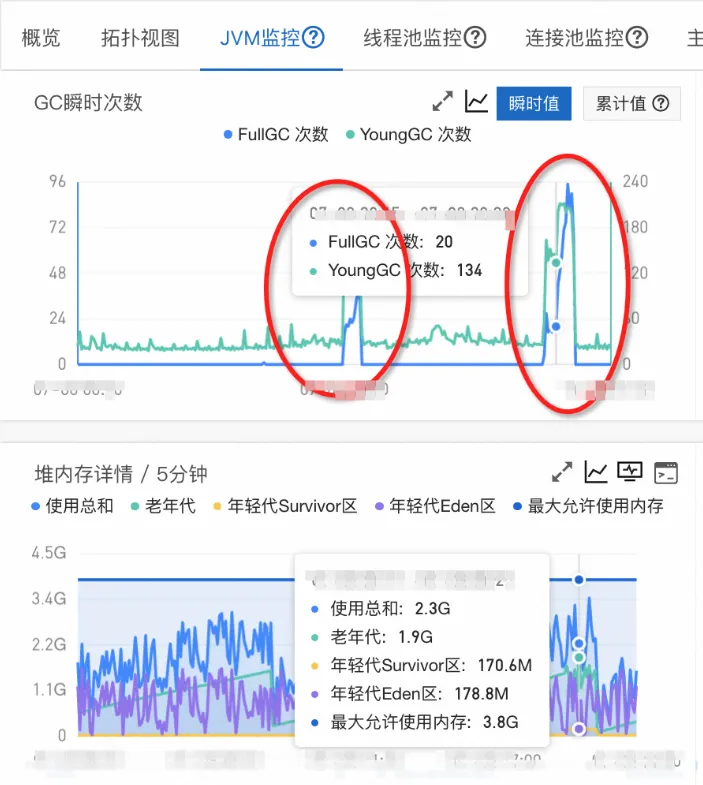
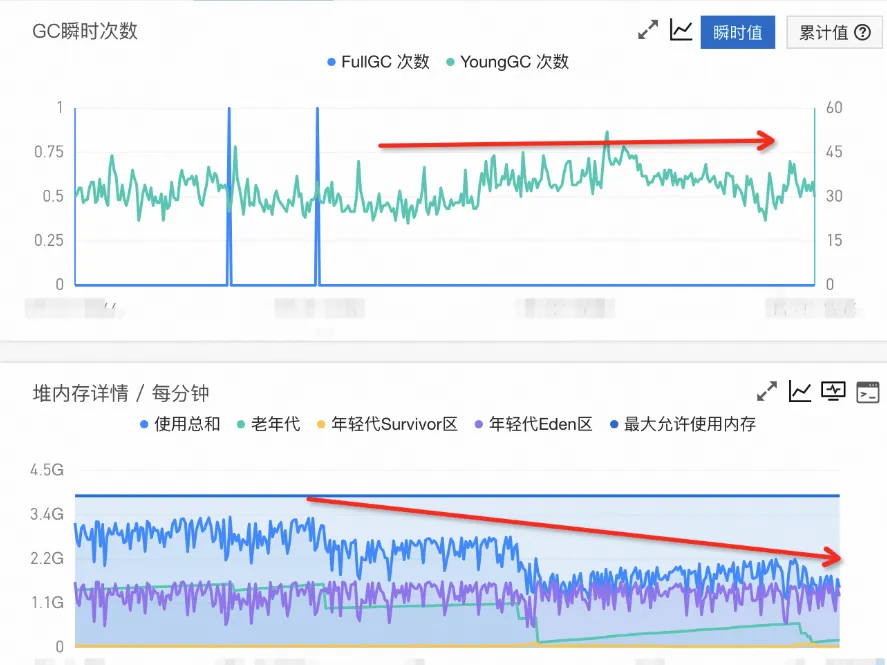
Full Gc
问题:因为基于微服务事件中心架构的模型是 java,最初是一次性获取缓存中所有的事件记录写到一个 Java 的 HashMap 中,而这一个 hashmap 有几百兆,如果在事件生成时比较慢会有多个线程都进行拉取就会造成上一个对象没回收下一个线程又获取了一个新的对象,这样就很容易 full gc 了,问题的监控图如下:
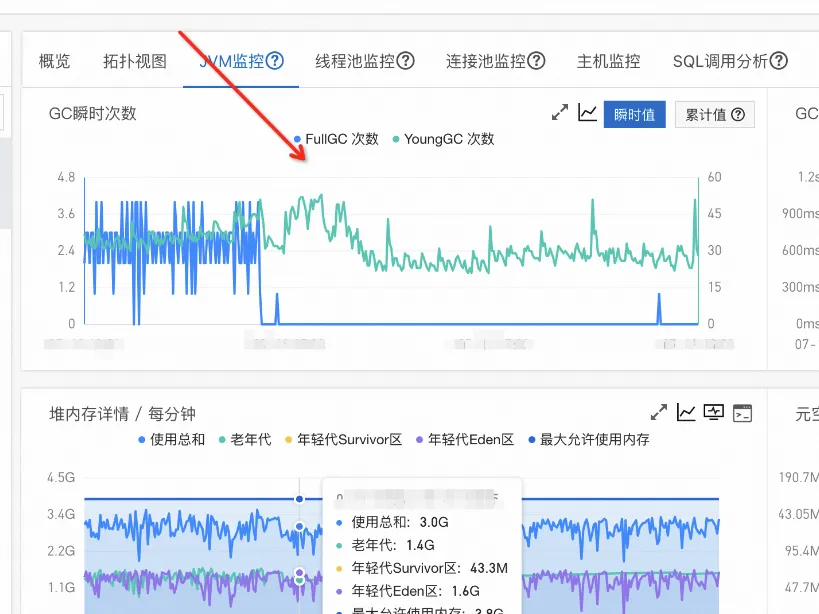
优化:
-
这个问题其实是有 2 个问题:
- 早期不是所有的事件类型都是类似队列的模式进行处理,就是入队和阈值出队的模式,所以某个事件异常后就会产生数据爆炸。
- 一次性拉取缓存所有的数据设置到 Java 的 hashmap,数据量过大如果处理慢则会造成变量一直在函数内没有释放容器造成内存泄露和触发 full gc。
-
优化内容:
- 优化一:所有的事件类型都采用入队和出队的模式进行处理,这样可以降低很多数据积压,到达阈值后都会进行事件写入和去重。
- 优化二:对于拉取缓存的数据进行分布式分片处理让整体的数据变小,比如 1/20 的数据量相对之前几百兆就缩小 20 倍,这样内存就直接下降了处理速度也快可以完美解决 full gc 问题。
- 优化后的效果图如下:
未来和展望
因为面向资源的原始事件相对于 SAE 的用户来讲太难理解了,所以事件中心的出现是更简单的帮助用户进行诊断和定位问题并且第一时间进行通知更加及时的定位问题根据事件,目前很多用户基于 SAE 的事件中心发现问题并诊断自闭环,比如南瓜电影、迅捷联动等用户。
事件中心不仅仅提供白屏化和可订阅通知能力,还可以和用户的运维系统进行定制化集成起来,如:南瓜电影将事件中心集成到了运维平台。
未来计划在事件中心上丰富更多的诊断和智能运维事件结合 AI 场景进行分析和定位让用户可以精确锁定问题和快速处理,实现真正一键定位和简单运维。