目录
一、什么是缓存?
二、为什么要使用缓存
三、如何使用缓存
四、添加商户缓存
1. 缓存模型和思路
2. 代码如下
五、缓存更新策略
1. 内存淘汰
2. 超时剔除
3. 主动更新
七、缓存穿透问题的解决思路
1. 什么是缓存穿透
2. 如何解决缓存穿透
3. 编码解决商品查询的缓存穿透问题
4. 总结
八、缓存雪崩问题及解决思路
九、缓存击穿问题及解决思路
1. 什么是缓存击穿
2. 解决方案
方案一:使用锁来解决
方案二:逻辑过期方案
两种方案进行对比
3. 利用互斥锁解决缓存击穿问题
4. 利用逻辑过期解决缓存击穿问题
十、封装Redis工具类
十一、缓存问题归纳
1. 雪崩问题
2. 缓存击穿
3. 缓存穿透
4. 缓存雪崩
一、什么是缓存?
前言:什么是缓存?
就像自行车,越野车的避震器

举个例子:
越野车,山地自行车,都拥有"避震器",防止车体加速后因惯性,在酷似"U"字母的地形上飞跃,硬着陆导致的损害,像个弹
簧一样;同样,实际开发中,系统也需要"避震器",防止过高的数据访问猛冲系统,导致其操作线程无法及时处理信息而
瘫痪;这在实际开发中对企业讲,对产品口碑,用户评价都是致命的;所以企业非常重视缓存技术;
缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码
例如:
例1:Static final ConcurrentHashMap<K,V> map = new ConcurrentHashMap<>(); 本地用于高并发例2:static final Cache<K,V> USER_CACHE = CacheBuilder.newBuilder().build(); 用于redis等缓存例3:Static final Map<K,V> map = new HashMap(); 本地缓存由于其被Static修饰,所以随着类的加载而被加载到内存之中,作为本地缓存,由于其又被final修饰,
所以其引用(例3:map)和对象(例3:new HashMap())之间的关系是固定的,不能改变,因此不用担心赋值(=)导致缓存
失效;
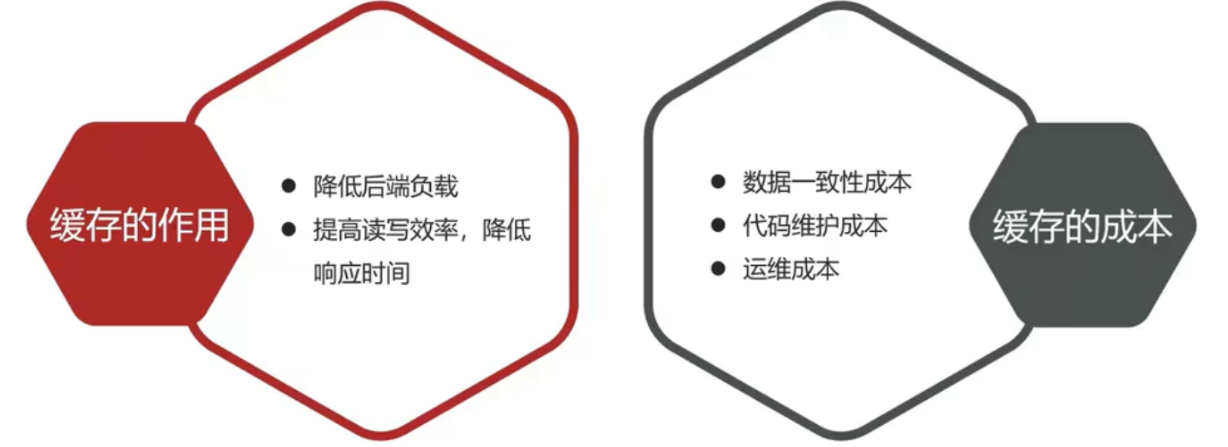
二、为什么要使用缓存
因为速度快,好用
缓存数据存储于代码中,而代码运行在内存中,内存的读写性能远高于磁盘,缓存可以大大降低用户访问并发量带来的
服务器读写压力
实际开发过程中,企业的数据量,少则几十万,多则几千万,这么大数据量,如果没有缓存来作为"避震器",
系统是几乎撑不住的,所以企业会大量运用到缓存技术;
但是缓存也会增加代码复杂度和运营的成本:
三、如何使用缓存
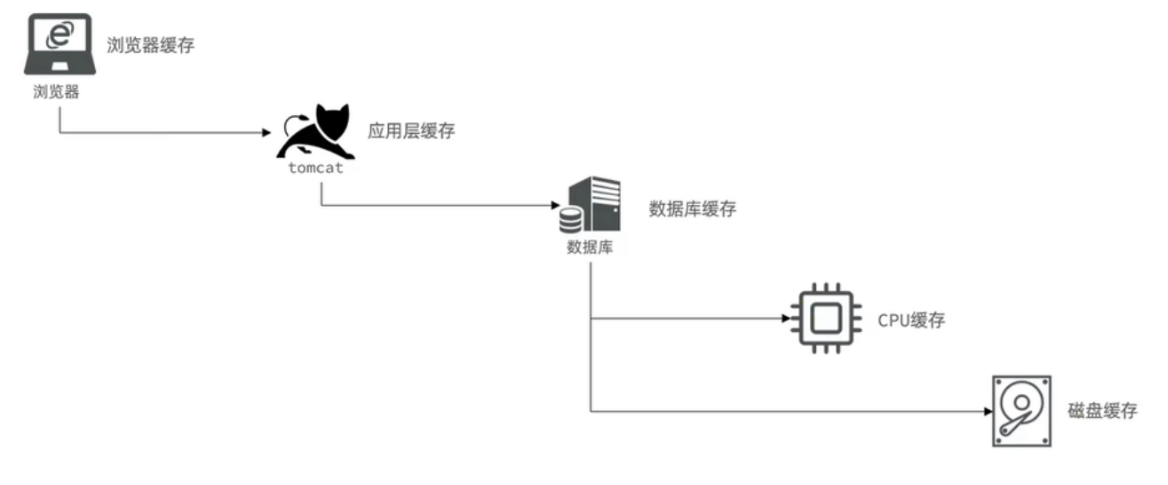
实际开发中,会构筑多级缓存来使系统运行速度进一步提升,例如:本地缓存与redis中的缓存并发使用
应用层缓存:可以分为tomcat本地缓存,比如之前提到的map,或者是使用redis作为缓存
数据库缓存:在数据库中有一片空间是 buffer pool,增改查数据都会先加载到mysql的缓存中
CPU缓存:当代计算机最大的问题是 cpu 性能提升了,但内存读写速度没有跟上,
所以为了适应当下的情况,增加了cpu的L1,L2,L3级的缓存
四、添加商户缓存
在我们查询商户信息时,我们是直接操作从数据库中去进行查询的,大致逻辑是这样,
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {//这里是直接查询数据库return shopService.queryById(id);
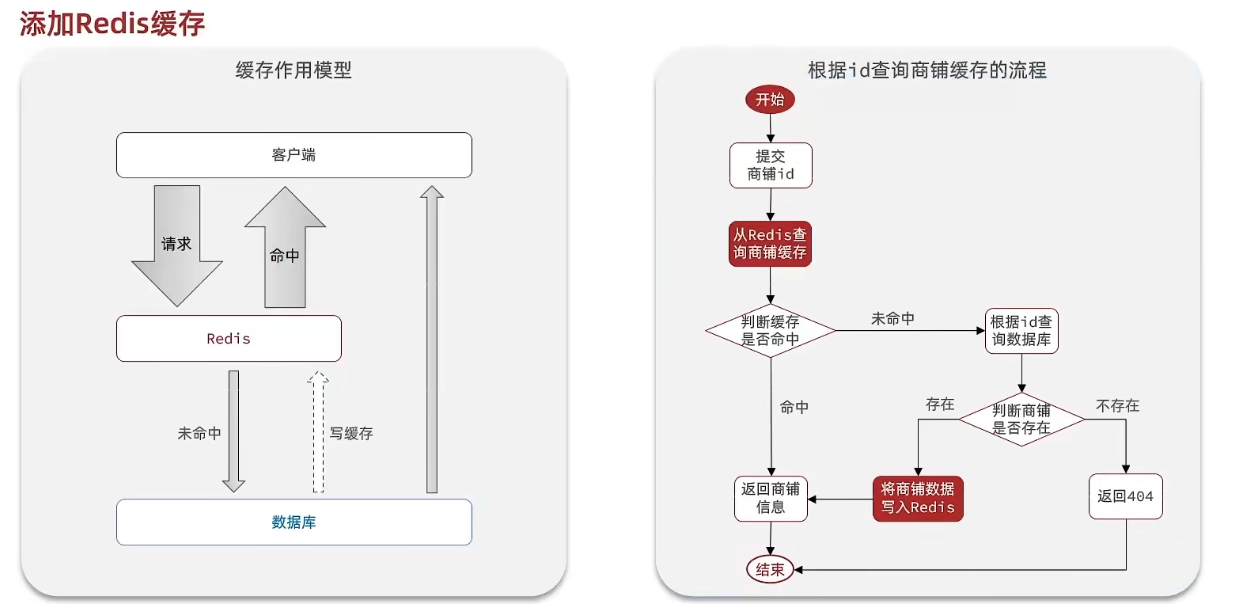
}1. 缓存模型和思路
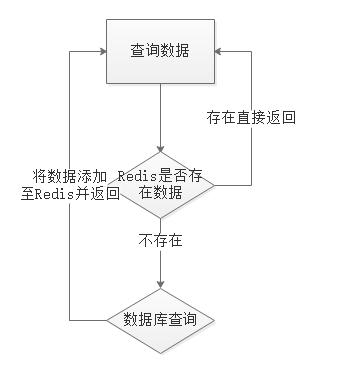
标准的操作方式就是查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,
如果缓存数据不存在,再查询数据库,然后将数据存入redis。

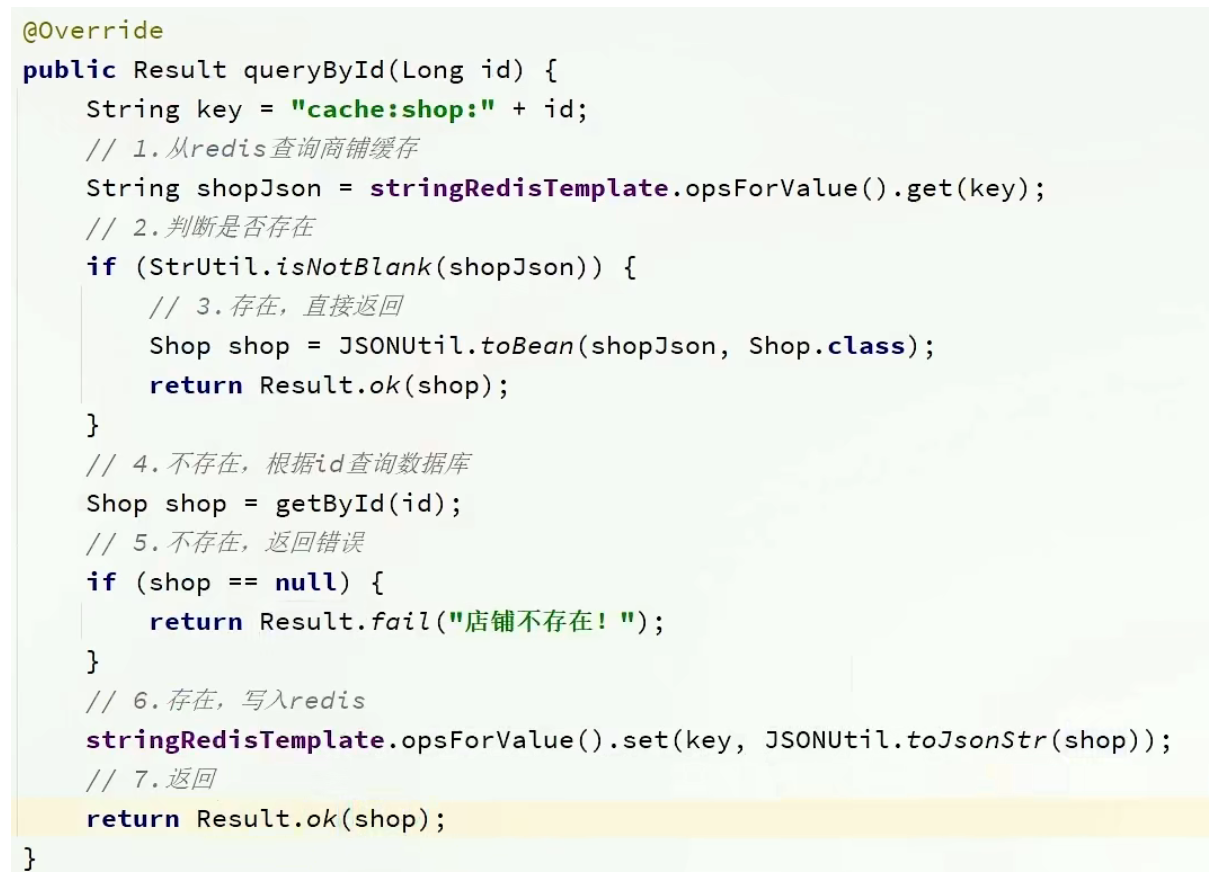
2. 代码如下
代码思路:如果缓存有,则直接返回,如果缓存不存在,则查询数据库,然后存入redis。
五、缓存更新策略
缓存更新是redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,
当我们向redis插入太多数据,此时就可能会导致缓存中的数据过多,
所以redis会对部分数据进行更新,或者把他叫为淘汰更合适。
1. 内存淘汰
内存淘汰:
redis自动进行,当redis内存达到咱们设定的max-memery的时候,会自动触发淘汰机制,
淘汰掉一些不重要的数据(可以自己设置策略方式)
2. 超时剔除
超时剔除:当我们给redis设置了过期时间ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存
3. 主动更新
主动更新:我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题

六、数据库缓存不一致解决方案
1. 数据库缓存不一致解决方案
由于我们的缓存的数据源来自于数据库,而数据库的数据是会发生变化的,
因此,如果当数据库中数据发生变化,而缓存却没有同步,此时就会有一致性问题存在,其后果是:
用户使用缓存中的过时数据,就会产生类似多线程数据安全问题,从而影响业务,产品口碑等;怎么解决呢?
有如下几种方案
Cache Aside Pattern人工编码方式:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案
Read/Write Through Pattern:由系统本身完成,数据库与缓存的问题交由系统本身去处理
Write Behind Caching Pattern :调用者只操作缓存,其他线程去异步处理数据库,实现最终一致

2. 数据库和缓存不一致采用什么方案
综合考虑使用方案一,但是方案一调用者如何处理呢?这里有几个问题
如果采用第一个方案,那么假设我们每次操作数据库后,都操作缓存,但是中间如果没有人查询,
那么这个更新动作实际上只有最后一次生效,中间的更新动作意义并不大,
3. 如何保证缓存与数据库的操作的同时成功或失败?
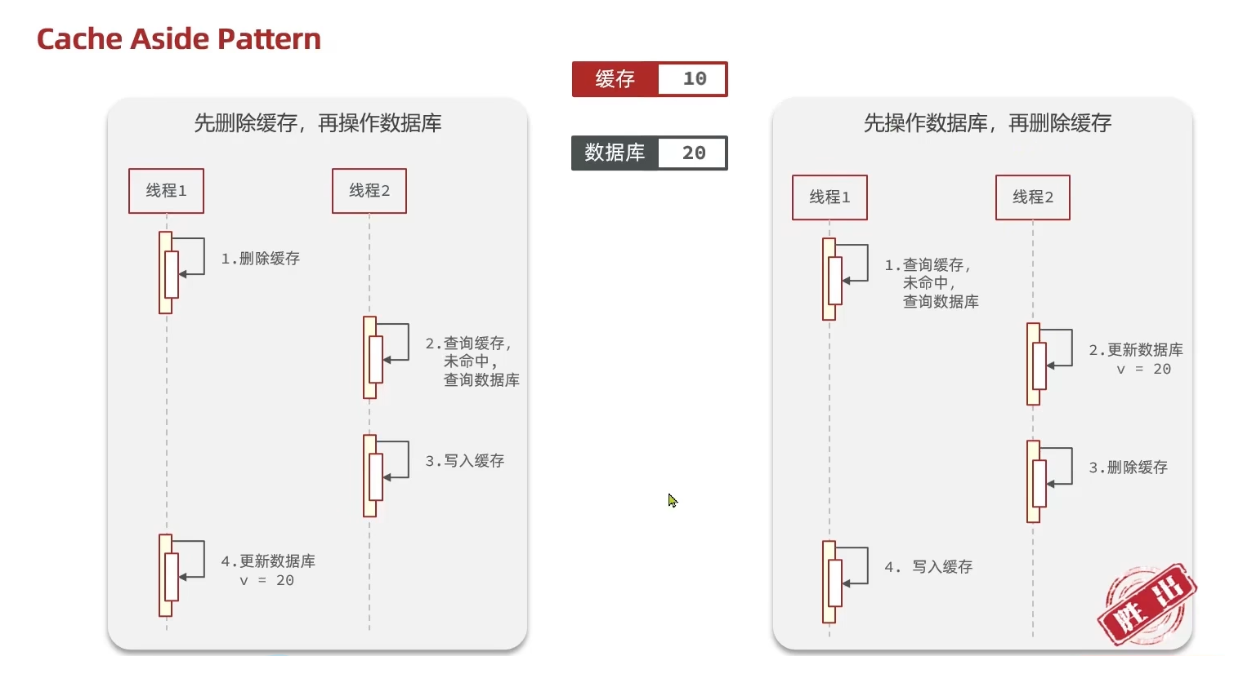
应该具体操作缓存还是操作数据库,我们应当是先操作数据库,再删除缓存,原因在于,如果你选择第
一种方案,在两个线程并发来访问时,假设线程1先来,他先把缓存删了,此时线程2过来,他查询缓存
数据并不存在,此时他写入缓存,当他写入缓存后,线程1再执行更新动作时,实际上写入的就是旧的数
据,新的数据被旧数据覆盖了。
4. 先操作缓存还是先操作数据库?
5. 实现商铺和缓存与数据库双写一致
核心思路如下:
修改ShopController中的业务逻辑,满足下面的需求:
根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
修改重点代码1:修改ShopServiceImpl的queryById方法
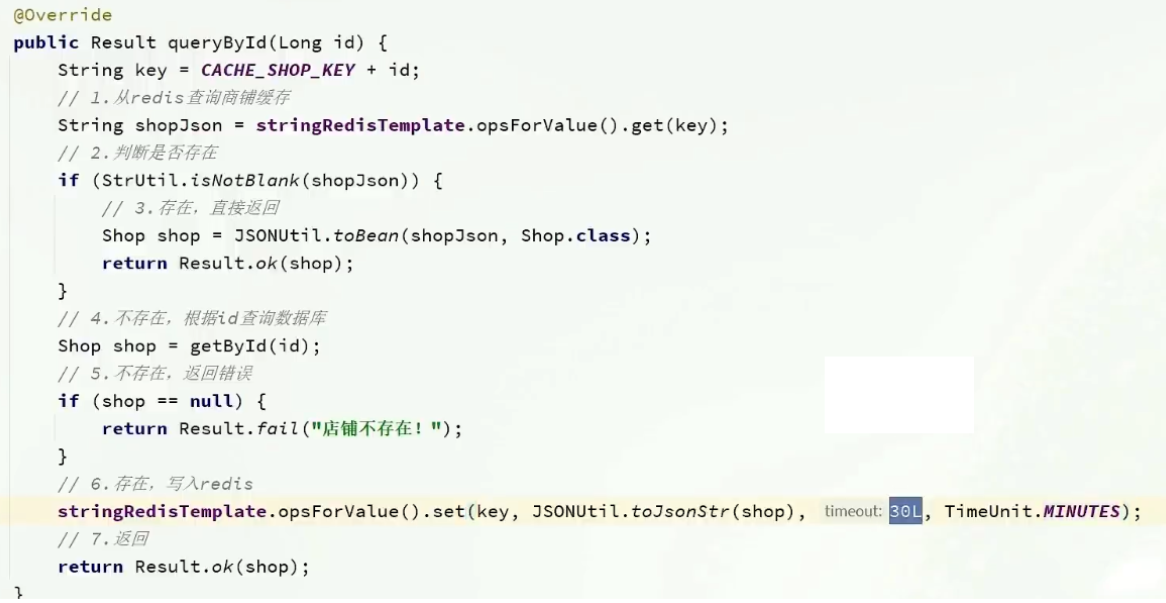
修改重点代码2
代码分析:
通过之前的淘汰,我们确定了采用删除策略,来解决双写问题,当我们修改了数据之后,然后把缓存中的数据进
行删除,查询时发现缓存中没有数据,则会从mysql中加载最新的数据,从而避免数据库和缓存不一致的问题

七、缓存穿透问题的解决思路
1. 什么是缓存穿透
缓存穿透:缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都
会打到数据库。
2. 如何解决缓存穿透
- 1. 缓存空对象优点:实现简单,维护方便缺点:额外的内存消耗、可能造成短期的不一致
- 2. 布隆过滤优点:内存占用较少,没有多余key缺点:实现复杂、存在误判可能
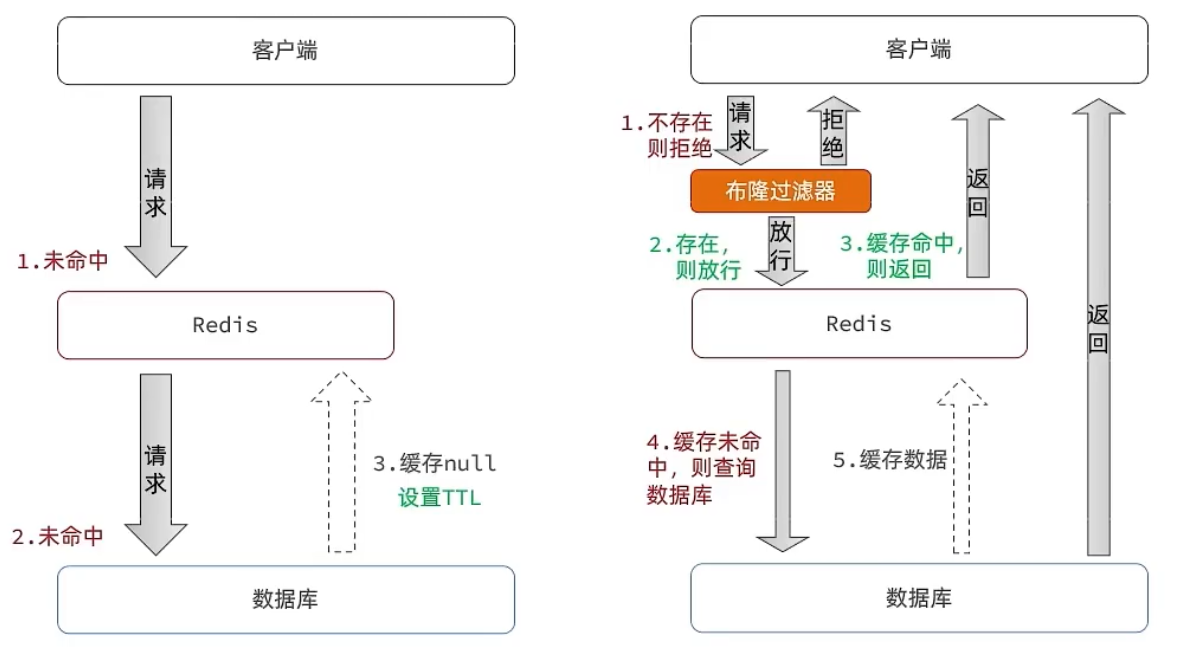
缓存空对象思路分析:
当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,
但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么
高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,
简单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去,
这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存了
布隆过滤:
布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要
查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据
过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,假设布隆过
滤器判断这个数据不存在,则直接返回这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器
走的是哈希思想,只要哈希思想,就可能存在哈希冲突
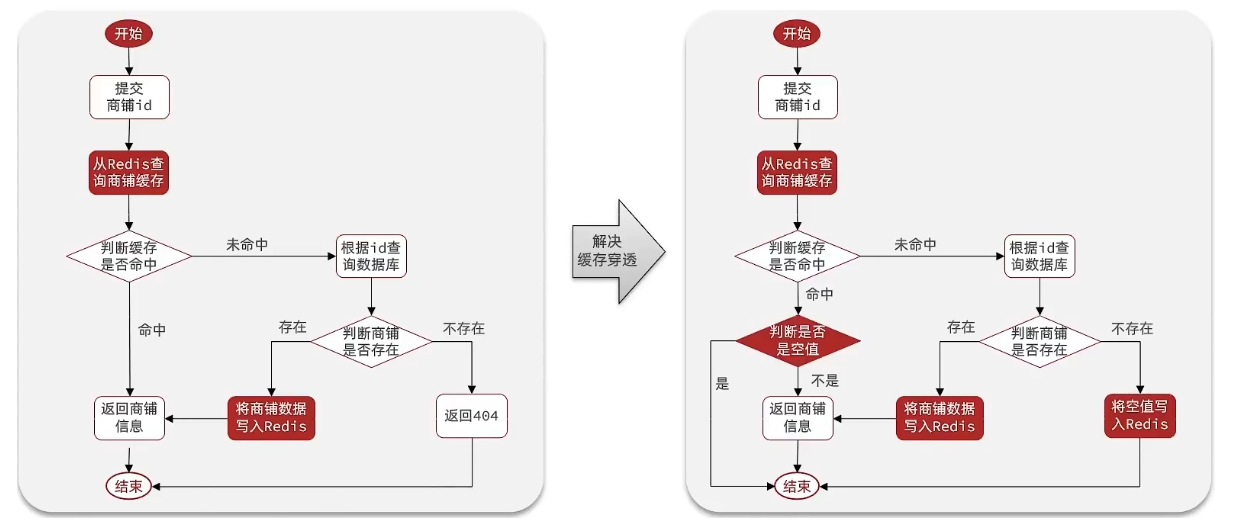
3. 编码解决商品查询的缓存穿透问题
核心思路
在原来的逻辑中,我们如果发现这个数据在mysql中不存在,直接就返回404了,
这样是会存在缓存穿透问题的现在的逻辑中:
如果这个数据不存在,我们不会返回404,还是会把这个数据写入到Redis中,并且将value设置为空,
当再次发起查询时,我们如果发现命中之后,判断这个value是否是null,
如果是null,则是之前写入的数据,证明是缓存穿透数据,如果不是,则直接返回数据。
4. 总结
- 缓存穿透产生的原因是什么?
- 缓存穿透的解决方案有哪些?
-
- 缓存null值
- 布隆过滤
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
八、缓存雪崩问题及解决思路
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,
带来巨大压力。
解决方案:

九、缓存击穿问题及解决思路
1. 什么是缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,
无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
- 互斥锁
- 逻辑过期
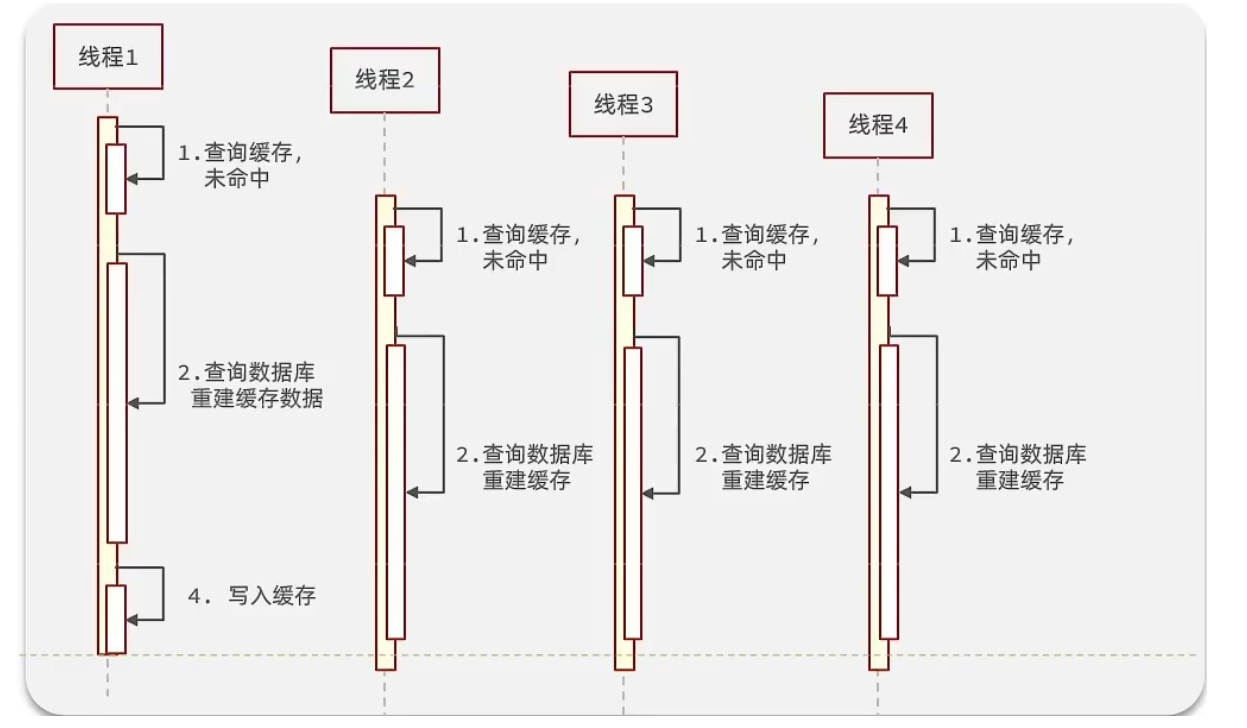
逻辑分析:
假设线程1在查询缓存之后,本来应该去查询数据库,然后把这个数据重新加载到缓存的,此时只要线程1走完这
个逻辑,其他线程就都能从缓存中加载这些数据了,但是假设在线程1没有走完的时候,后续的线程2,线程3,线
程4同时过来访问当前这个方法, 那么这些线程都不能从缓存中查询到数据,那么他们就会同一时刻来访问查询缓
存,都没查到,接着同一时间去访问数据库,同时的去执行数据库代码,对数据库访问压力过大
2. 解决方案
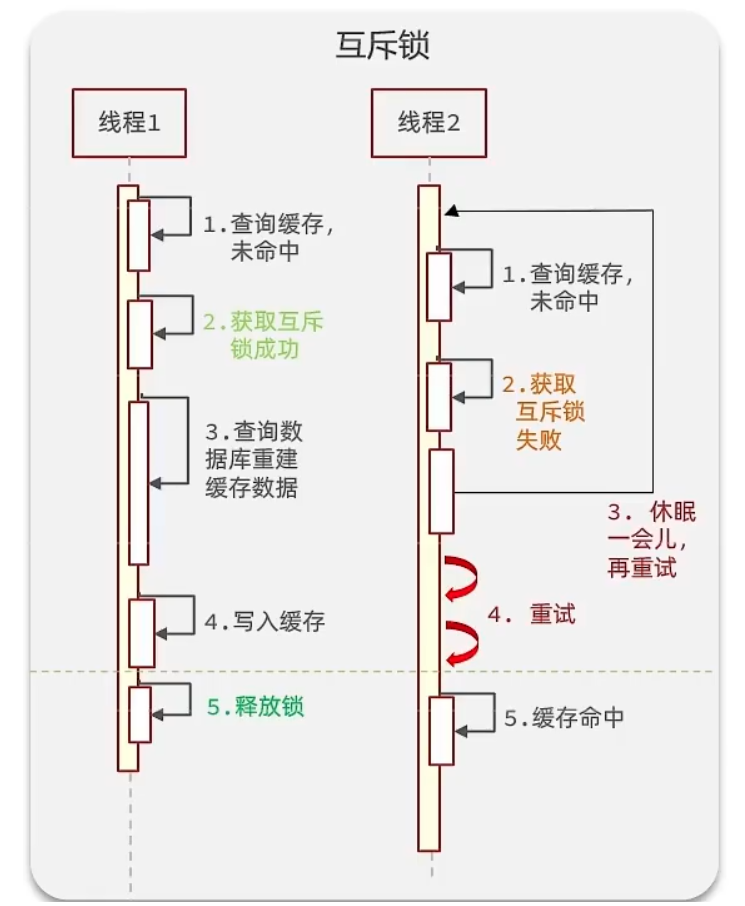
方案一:使用锁来解决
因为锁能实现互斥性。假设线程过来,只能一个人一个人的来访问数据库,从而避免对于数据库访问压力过大,
但这也会影响查询的性能,因为此时会让查询的性能从并行变成了串行,我们可以采用tryLock方法 + double
check来解决这样的问题。
假设现在线程1过来访问,他查询缓存没有命中,但是此时他获得到了锁的资源,那么线程1就会一个人去执行逻
辑,假设现在线程2过来,线程2在执行过程中,并没有获得到锁,那么线程2就可以进行到休眠,
直到线程1把锁释放后,线程2获得到锁,然后再来执行逻辑,此时就能够从缓存中拿到数据了。
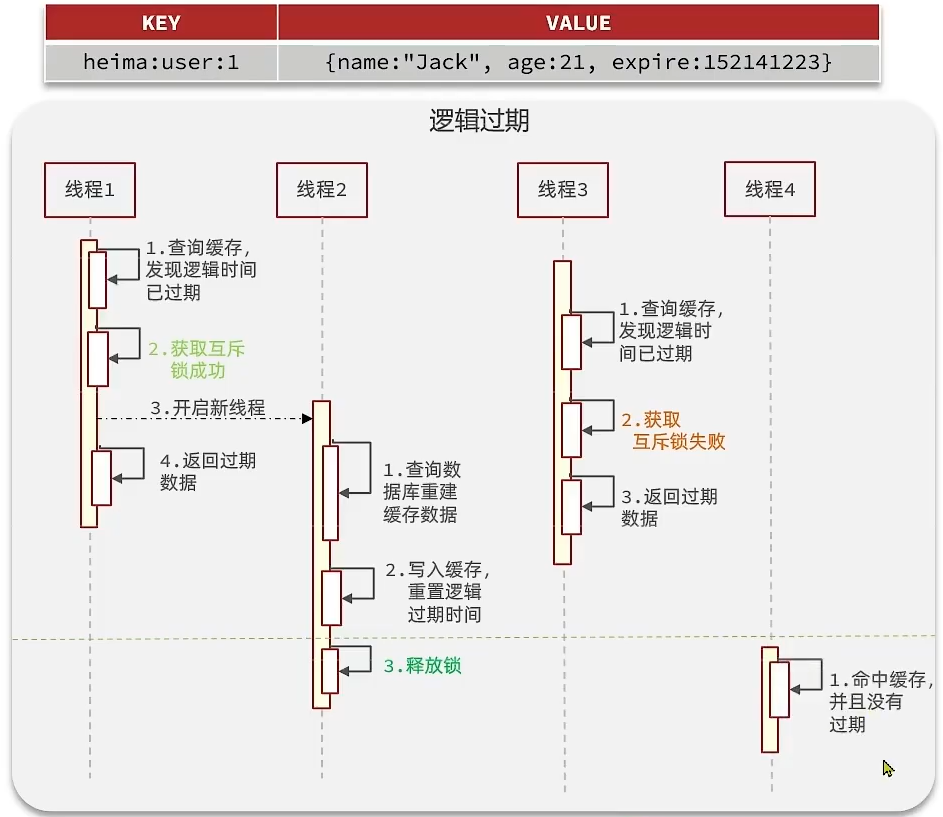
方案二:逻辑过期方案
方案分析:
我们之所以会出现这个缓存击穿问题,主要原因是在于我们对key设置了过期时间,假设我们不设置过期时间,其
实就不会有缓存击穿的问题,但是不设置过期时间,这样数据不就一直占用我们内存了吗,我们可以采用逻辑过
期方案。
我们把过期时间设置在 redis 的value中,
注意:
这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。
假设线程1去查询缓存,然后从value中判断出来当前的数据已经过期了,
此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的线程他会开启一个 线程去进行 以前的重构数据
的逻辑,直到新开的线程完成这个逻辑后,才释放锁, 而线程1直接进行返回,
假设现在线程3过来访问,由于线程线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据,
只有等到新开的线程2把重建数据构建完后,其他线程才能走返回正确的数据。
这种方案巧妙在于,异步的构建缓存,缺点在于在构建完缓存之前,返回的都是脏数据。
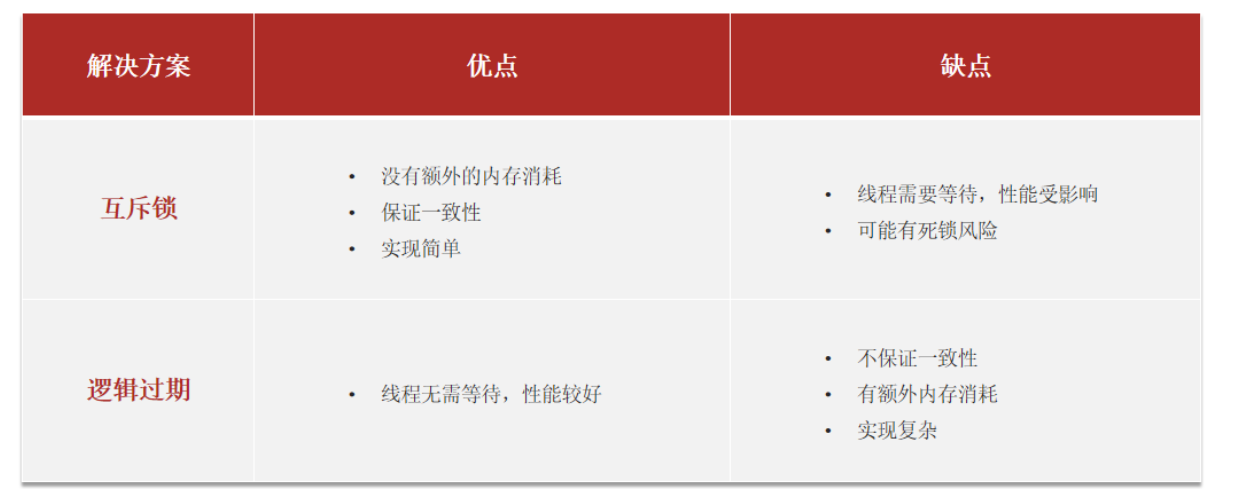
两种方案进行对比
- 互斥锁方案由于保证了互斥性,所以数据一致,且实现简单,因为仅仅只需要加一把锁而已,也没其他的事
情需要操心,所以没有额外的内存消耗,缺点在于有锁就有死锁问题的发生,且只能串行执行性能肯定受到
影响
- 逻辑过期方案:线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构数据,但是在重
构数据完成前,其他的线程只能返回之前的数据,且实现起来麻烦
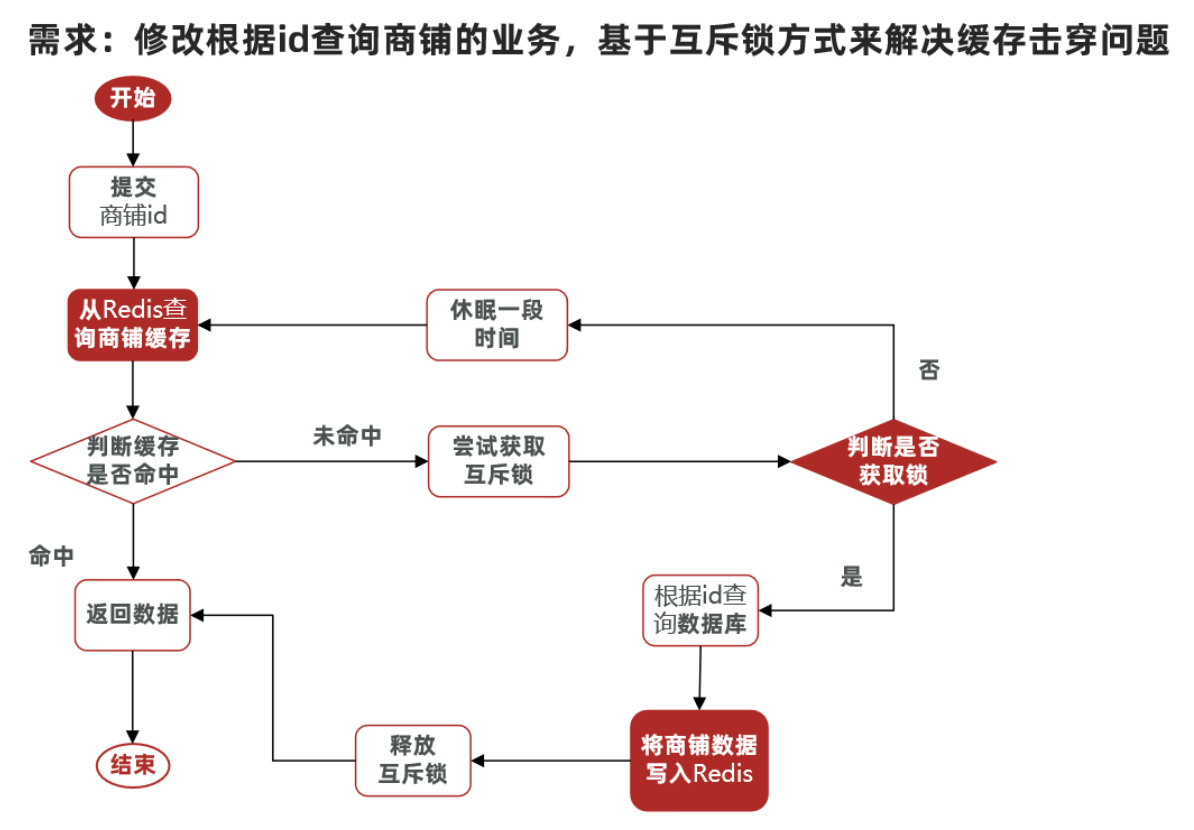
3. 利用互斥锁解决缓存击穿问题
核心思路:
相较于原来从缓存中查询不到数据后直接查询数据库而言,现在的方案是 进行查询之后,
如果从缓存没有查询到数据,则进行互斥锁的获取,获取互斥锁后,判断是否获得到了锁,如果没有获得到,则休眠,
过一会再进行尝试,直到获取到锁为止,才能进行查询
如果获取到了锁的线程,再去进行查询,查询后将数据写入redis,再释放锁,返回数据,
利用互斥锁就能保证只有一个线程去执行操作数据库的逻辑,防止缓存击穿
操作锁的代码:
核心思路就是利用redis的setnx方法来表示获取锁,
该方法含义是redis中如果没有这个key,则插入成功,返回1,
在stringRedisTemplate中返回true, 如果有这个key则插入失败,则返回0,
在stringRedisTemplate返回false,我们可以通过true,或者是false,来表示是否有线程成功插入key,
成功插入的key的线程我们认为他就是获得到锁的线程。
private boolean tryLock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);
}private void unlock(String key) {stringRedisTemplate.delete(key);
}操作代码:
public Shop queryWithMutex(Long id) {String key = CACHE_SHOP_KEY + id;// 1、从redis中查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get("key");// 2、判断是否存在if (StrUtil.isNotBlank(shopJson)) {// 存在,直接返回return JSONUtil.toBean(shopJson, Shop.class);}//判断命中的值是否是空值if (shopJson != null) {//返回一个错误信息return null;}// 4.实现缓存重构//4.1 获取互斥锁String lockKey = "lock:shop:" + id;Shop shop = null;try {boolean isLock = tryLock(lockKey);// 4.2 判断否获取成功if(!isLock){//4.3 失败,则休眠重试Thread.sleep(50);return queryWithMutex(id);}//4.4 成功,根据id查询数据库shop = getById(id);// 5.不存在,返回错误if(shop == null){//将空值写入redisstringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);//返回错误信息return null;}//6.写入redisstringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_NULL_TTL,TimeUnit.MINUTES);}catch (Exception e){throw new RuntimeException(e);}finally {//7.释放互斥锁unlock(lockKey);}return shop;}4. 利用逻辑过期解决缓存击穿问题
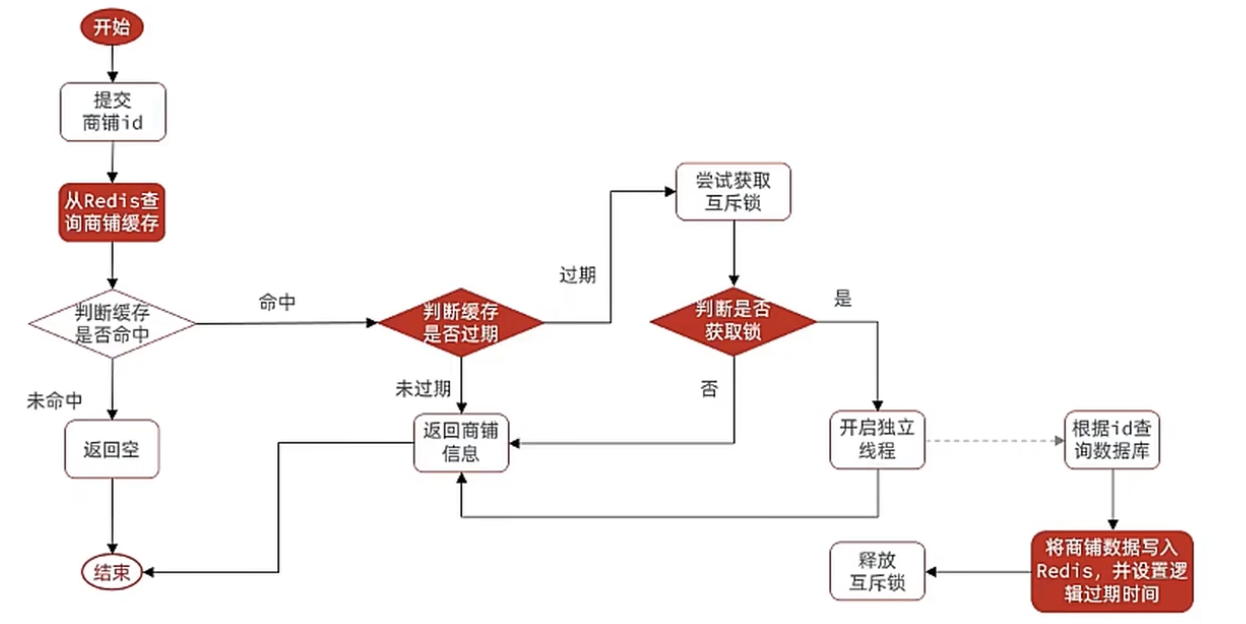
需求:修改根据id查询商铺的业务,基于逻辑过期方式来解决缓存击穿问题
思路分析:
当用户开始查询redis时,判断是否命中,如果没有命中则直接返回空数据,不查询数据库,而一旦命中后,将
value取出,
判断value中的过期时间是否满足,如果没有过期,则直接返回redis中的数据,
如果过期,则在开启独立线程后直接返回之前的数据,独立线程去重构数据,重构完成后释放互斥锁。
如果封装数据:因为现在redis中存储的数据的value需要带上过期时间,此时要么你去修改原来的实体类,要么你
步骤一:
新建一个实体类,我们采用第二个方案,这个方案,对原来代码没有侵入性。
@Data
public class RedisData {private LocalDateTime expireTime;private Object data;
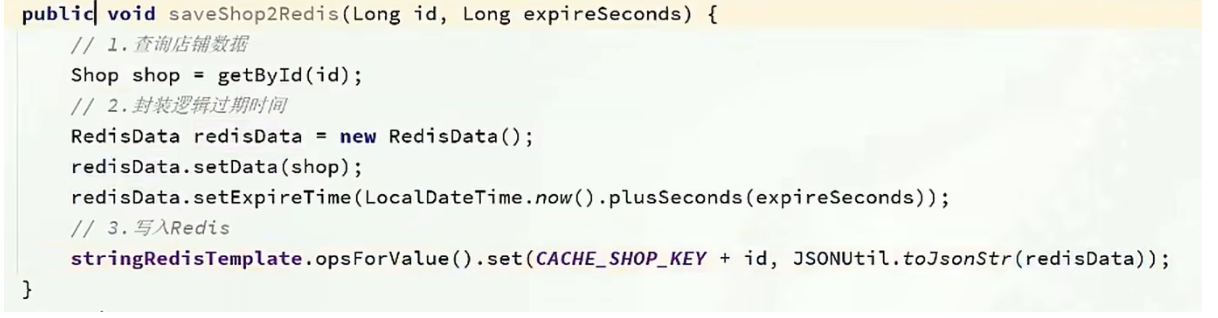
}步骤二:
在ShopServiceImpl 新增此方法,利用单元测试进行缓存预热
在测试类中
步骤三:正式代码
ShopServiceImpl
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public Shop queryWithLogicalExpire( Long id ) {String key = CACHE_SHOP_KEY + id;// 1.从redis查询商铺缓存String json = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isBlank(json)) {// 3.存在,直接返回return null;}// 4.命中,需要先把json反序列化为对象RedisData redisData = JSONUtil.toBean(json, RedisData.class);Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);LocalDateTime expireTime = redisData.getExpireTime();// 5.判断是否过期if(expireTime.isAfter(LocalDateTime.now())) {// 5.1.未过期,直接返回店铺信息return shop;}// 5.2.已过期,需要缓存重建// 6.缓存重建// 6.1.获取互斥锁String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);// 6.2.判断是否获取锁成功if (isLock){CACHE_REBUILD_EXECUTOR.submit( ()->{try{//重建缓存this.saveShop2Redis(id,20L);}catch (Exception e){throw new RuntimeException(e);}finally {unlock(lockKey);}});}// 6.4.返回过期的商铺信息return shop;
}十、封装Redis工具类
基于StringRedisTemplate封装一个缓存工具类,满足下列需求:
- 方法1:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
- 方法2:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓
存击穿问题
将逻辑进行封装
@Slf4j
@Component
public class CacheClient {private final StringRedisTemplate stringRedisTemplate;private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);public CacheClient(StringRedisTemplate stringRedisTemplate) {this.stringRedisTemplate = stringRedisTemplate;}public void set(String key, Object value, Long time, TimeUnit unit) {stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit);}public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit) {// 设置逻辑过期RedisData redisData = new RedisData();redisData.setData(value);redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));// 写入RedisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));}public <R,ID> R queryWithPassThrough(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit){String key = keyPrefix + id;// 1.从redis查询商铺缓存String json = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isNotBlank(json)) {// 3.存在,直接返回return JSONUtil.toBean(json, type);}// 判断命中的是否是空值if (json != null) {// 返回一个错误信息return null;}// 4.不存在,根据id查询数据库R r = dbFallback.apply(id);// 5.不存在,返回错误if (r == null) {// 将空值写入redisstringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);// 返回错误信息return null;}// 6.存在,写入redisthis.set(key, r, time, unit);return r;}public <R, ID> R queryWithLogicalExpire(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) {String key = keyPrefix + id;// 1.从redis查询商铺缓存String json = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isBlank(json)) {// 3.存在,直接返回return null;}// 4.命中,需要先把json反序列化为对象RedisData redisData = JSONUtil.toBean(json, RedisData.class);R r = JSONUtil.toBean((JSONObject) redisData.getData(), type);LocalDateTime expireTime = redisData.getExpireTime();// 5.判断是否过期if(expireTime.isAfter(LocalDateTime.now())) {// 5.1.未过期,直接返回店铺信息return r;}// 5.2.已过期,需要缓存重建// 6.缓存重建// 6.1.获取互斥锁String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);// 6.2.判断是否获取锁成功if (isLock){// 6.3.成功,开启独立线程,实现缓存重建CACHE_REBUILD_EXECUTOR.submit(() -> {try {// 查询数据库R newR = dbFallback.apply(id);// 重建缓存this.setWithLogicalExpire(key, newR, time, unit);} catch (Exception e) {throw new RuntimeException(e);}finally {// 释放锁unlock(lockKey);}});}// 6.4.返回过期的商铺信息return r;}public <R, ID> R queryWithMutex(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) {String key = keyPrefix + id;// 1.从redis查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isNotBlank(shopJson)) {// 3.存在,直接返回return JSONUtil.toBean(shopJson, type);}// 判断命中的是否是空值if (shopJson != null) {// 返回一个错误信息return null;}// 4.实现缓存重建// 4.1.获取互斥锁String lockKey = LOCK_SHOP_KEY + id;R r = null;try {boolean isLock = tryLock(lockKey);// 4.2.判断是否获取成功if (!isLock) {// 4.3.获取锁失败,休眠并重试Thread.sleep(50);return queryWithMutex(keyPrefix, id, type, dbFallback, time, unit);}// 4.4.获取锁成功,根据id查询数据库r = dbFallback.apply(id);// 5.不存在,返回错误if (r == null) {// 将空值写入redisstringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);// 返回错误信息return null;}// 6.存在,写入redisthis.set(key, r, time, unit);} catch (InterruptedException e) {throw new RuntimeException(e);}finally {// 7.释放锁unlock(lockKey);}// 8.返回return r;}private boolean tryLock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);}private void unlock(String key) {stringRedisTemplate.delete(key);}
}在ShopServiceImpl中
@Resource
private CacheClient cacheClient;@Overridepublic Result queryById(Long id) {// 解决缓存穿透Shop shop = cacheClient.queryWithPassThrough(CACHE_SHOP_KEY, id, Shop.class, this::getById, CACHE_SHOP_TTL, TimeUnit.MINUTES);// 互斥锁解决缓存击穿// Shop shop = cacheClient// .queryWithMutex(CACHE_SHOP_KEY, id, Shop.class, this::getById, CACHE_SHOP_TTL, TimeUnit.MINUTES);// 逻辑过期解决缓存击穿// Shop shop = cacheClient// .queryWithLogicalExpire(CACHE_SHOP_KEY, id, Shop.class, this::getById, 20L, TimeUnit.SECONDS);if (shop == null) {return Result.fail("店铺不存在!");}// 7.返回return Result.ok(shop);}十一、缓存问题归纳
1. 雪崩问题
1. Key的过期淘汰机制
Redis 可以对存储在Redis中的缓存数据设置过期时间,比如我们获取的短信验证码一般十分钟过期,
我们这时候就需要在验证码存进Redis时添加一个key的过期时间,但是这里有一个需要格外注意的问题就是:
并非key过期时间到 了就一定会被Redis给删除。
2. 定期删除
Redis 默认是每隔 100ms 就随机抽取一些设置了过期时间的 Key,检查其是否过期,如果过期就删除。
为什么是随机抽取而不是检查所有key?
因为你如果设置的key成千上万,每100毫秒都将所有存在的key检查一遍,会给CPU带来比较大的压力。
3. 惰性删除
定期删除由于是随机抽取可能会导致很多过期 Key 到了过期时间并没有被删除。
所以用户在从缓存获取数据的时 候,redis会检查这个key是否过期了,如果过期就删除这个key。
这时候就会在查询的时候将过期key从缓存中清除。
4. 内存淘汰机制
仅仅使用定期删除 + 惰性删除机制还是会留下一个严重的隐患:
如果定期删除留下了很多已经过期的key,而且用户长时间都没有使用过这些过期key,导致过期key无法被惰性删除,
而导致过期key一直堆积在内存里,最终造成Redis内存块被消耗殆尽。
那这个问题如何解决呢?
这个时候Redis内存淘汰机制应运而生了。
Redis内存淘汰机制提供了6种数据淘汰策略
① volatile-lru :从已设置过期时间的数据集中挑选最近最少使用的数据淘汰。
② volatile-ttl :从已设置过期时间的数据集中挑选将要过期的数据淘汰。
③ volatile-random :从已设置过期时间的数据集中任意选择数据淘汰。
④ allkeys-lru :当内存不足以容纳新写入数据时移除最近最少使用的key。
⑤ allkeys-random :从数据集中任意选择数据淘汰。
⑥ no-enviction(默认) :当内存不足以容纳新写入数据时,新写入操作会报错。
一般情况下,推荐使用 volatile-lru 策略,对于配置信息等重要数据,不应该设置过期时间,
这样Redis就永远不会淘汰这些重要数据。
对于一般数据可以添加一个缓存时间,当数据失效则请求会从DB中获取并重新存入Redis中。

2. 缓存击穿
首先我们来看下请求是如何取到数据的:当接收到用户请求,首先先尝试从Redis缓存中获取到数据,如果缓存中
能取到数据则直接返回果,当缓存中不存在数据时从DB获取数据,如果数据库成功取到数据,则更新Redis,然后
返回数据

定义:高并发的情况下,某个热门key突然过期,导致大量请求在Redis未找到缓存数据,
进而全部去访问DB请求 数据,引起DB压力瞬间增大。
解决方案:缓存击穿的情况下一般不容易造成DB的宕机,只是会造成对DB的周期性压力。
对缓存击穿的解决方案 一般可以这样:
① Redis中的数据不设置过期时间,然后在缓存的对象上添加一个属性标识过期时间,每次获取到数据时,校验对
象中的过期时间属性,如果数据即将过期,则异步发起一个线程主动更新缓存中的数据。但是这种方案可能会导
致有些请求会拿到过期的值,就得看业务能否可以接受。
② 如果要求数据必须是新数据,则最好的方案则为热点数据设置为永不过期,然后加一个互斥锁保证缓存的单线
程写。
3. 缓存穿透
比如通过id查询商品信息,id一般大于0,攻击者会故意传id为-1去查询,由于缓存是不命中则从DB中获取数据,
这将会导致每次缓存都不命中数据导致每个请求都访问DB, 造成缓存穿透。
解决方案:
① 利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
② 采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异
步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
③ 提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅
速 判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
④ 如果从数据库查询的对象为空,也放入缓存,只是设定的缓存过期时间较短,比如设置为60秒。
4. 缓存雪崩
定义:缓存中如果大量缓存在一段时间内集中过期了,这时候会发生大量的缓存击穿现象,所有的请求都落在了
DB上,由于查询数据量巨大,引起DB压力过大甚至导致DB宕机。
解决方案:
① 给缓存的失效时间,加上一个随机值,避免集体失效。如果Redis是集群部署,将热点数据均匀分布在不同的
Redis库中也能避免全部失效的问题。
② 使用互斥锁,但是该方案吞吐量明显下降了。 设置热点数据永远不过期。
③ 双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预
热操作。
然后细分以下几个小点。






