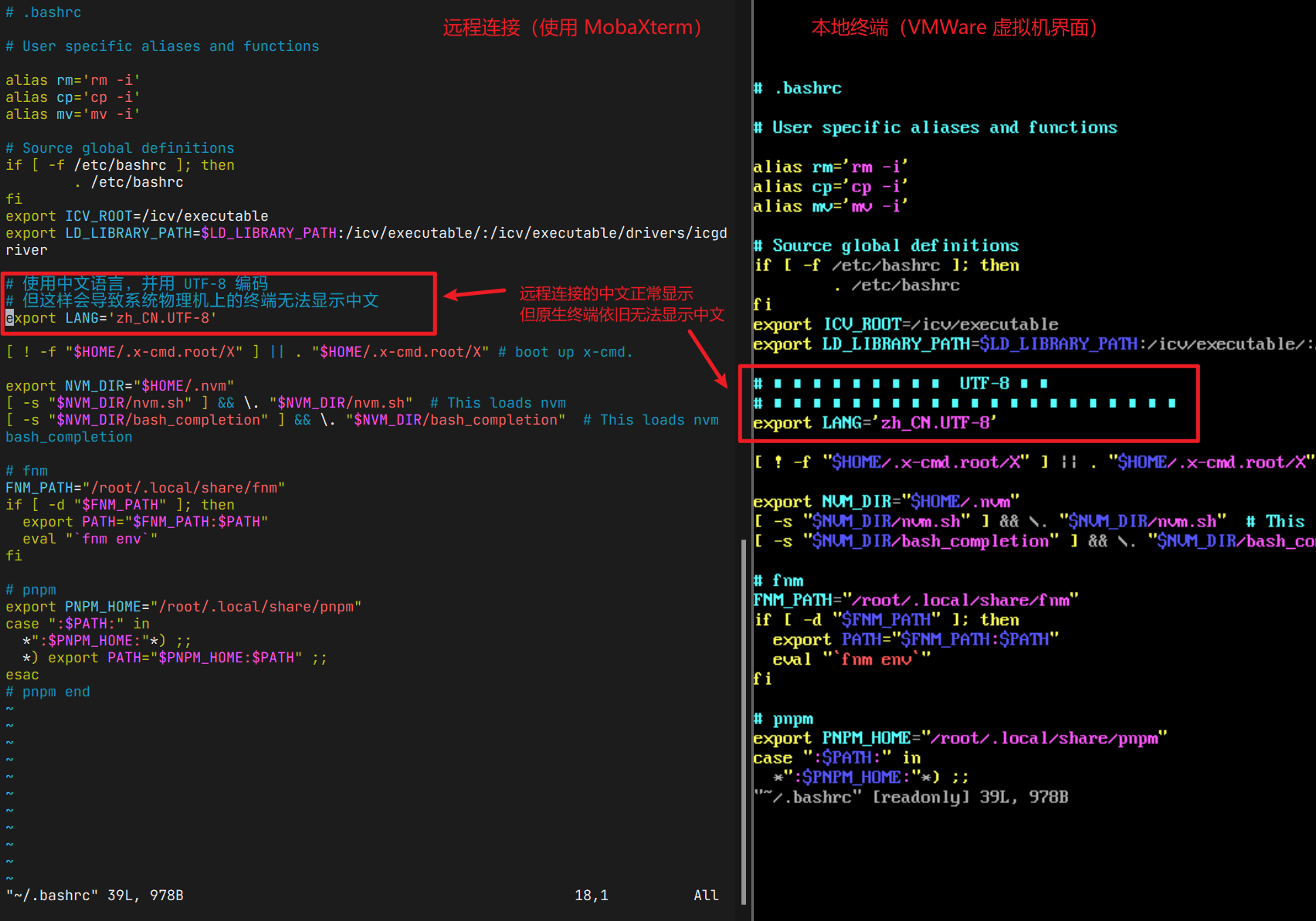
1 输入数据
VOS的数据集处理操作可见数据集操作,这里是进行数据集提取完毕后的操作。

图2:如图所示,使用datasets提取出数据之后,在模型训练阶段对数据做图中操作。即:将batch_size大小的ref_imgs、prev_imgs,和3batch_size大小的curr_imgs在通道维度上进行合并。如图例,batch_size为4时,得到203465465大小的合并图像和201465*465大小的合并mask。
2 AOTEngine
1) 初始化loss

2)输入进encoder:offline_encoder
这一模块是对输入的图像数据和mask数据进行处理。
针对图像数据:
- 将图像输入进encoder中,获取四个不同比例大小的预测特征图。(具体步骤见图3)
- 对这四个预测特征图按batch大小进行分块,共分成5块,它们分别代表相关图像(ref_imgs)、前一帧图像(prev_imgs)、目前图像 * 3(curr_imgs * 3),这样总共获得20块预测特征图。
- 按照图像归属对这些预测特征图块进行分类,共获得五个列表,每个列表包含四个不同比例大小的预测特征图。(具体步骤见图4)
针对mask数据:
- 将mask图像进行one-hot-编码,分离出前后景的mask。源码中设置每张图像的最大目标数量为10,假设原始mask的张量大小为(1 * 465 * 465),那么经过编码后,得到的编码mask张量大小为(11 * 465 * 465).
- 将原始mask和编码后的mask按照batch大小进行分块,共得到五块特征图。每块特征图分别代表相关图像、前一帧图像和当前图像*3。具体步骤见图5.
2.1)提取backbone features
- 提取特征图
mobilenetv2共有19个block,分成四个阶段,如下面代码所示。提取不同阶段的特征图,分别得到下采样4倍、下采样8倍、下采样16倍和下采样32倍的特征图。最后的下采样32倍的特征图通过1*1的卷积(代码中命名为:encoder_projector)降维,由原来的1280维降到256维,如下图所示。
其中FrozenBatchNorm2d的相关解释见encoder和decoder代码讲解。
下图展示的是单张shape为3465465的图像经过mobilenetv2得到的变化。

图3:如图3所示,是mobilenet的整体结构,mobilenet共有19层,这19层被切分成4个阶段,每个阶段生成不同比例大小的特征图,并将这些特征图进行打包输入到程序的下一步。
# make it nn.Sequentialself.features = nn.Sequential(*features)self._initialize_weights()feature_4x = self.features[0:4]feautre_8x = self.features[4:7]feature_16x = self.features[7:14]feature_32x = self.features[14:]self.stages = [feature_4x, feautre_8x, feature_16x, feature_32x]self.freeze(freeze_at)def forward(self, x):xs = []for stage in self.stages:x = stage(x)xs.append(x)return xs
- 对特征图进行分块
程序中所有图像经过mobilenetv2的过程如下图所示,经历mobilenetv2之后,对features进行分割,按照batch的大小进行分割。

图4:是整体数据经过encoder(即mobilenetv2)时的步骤。在源码中,在得到4个不同比例的特征图后,程序会对特征图按照batch的大小进行分块,每一个小块所代表的图像特征如图所示,依次为:ref_imgs(参考图像)、prev_imgs(前一帧图像)、curr_imgs * 3 (现在的图像 * 3)

图5:是源码debug时的结果可视化
2.2)extract mask embeddings
- 对mask进行one-hot编码
下图是mask可视化的结果,它在程序中的存储形式如图5上方的矩形框所示,背景为用0填充,前景对象由1~10(源码中规定一张图可出现的最大对象数为10)的数字填充,同一前景对象的填充数字一致。源码使用one-hot-mask编码,将所有的前景对象提取出来,具体的代码和步骤如下所示:
def one_hot_mask(mask, cls_num):if len(mask.size()) == 3:mask = mask.unsqueeze(1)indices = torch.arange(0, cls_num + 1,device=mask.device).view(1, -1, 1, 1)return (mask == indices).float()
图5:对原始mask进行前后景分离。假如对形状为[1,465,465]的mask张量进行分割,会得到[11,465,465]的mask张量,里面代表的是11个目标对象的mask情况,可视化后的结果如图所示。
- 对编码后的mask进行分块
分块操作和上面特征图的分块操作一致。具体过程如图5下方所示:分块后共有五个list,同样的,每一个list所代表的图像特征和图4的表示一致,浅粉色代表ref_imgs、玫粉色代表prev_imgs、深红色代表curr_imgs*3。


![[vulnhub] LAMPSecurity: CTF4](/images/no-images.jpg)