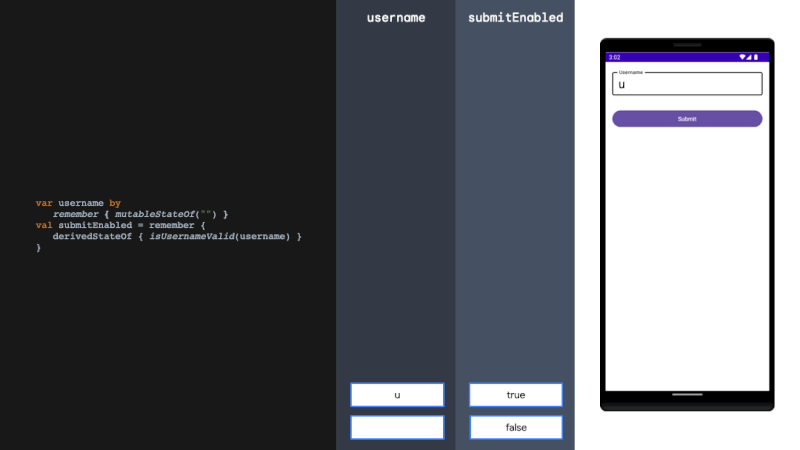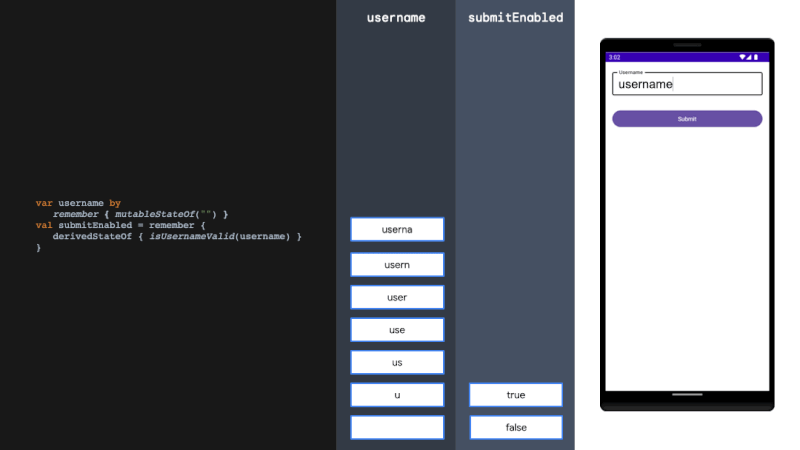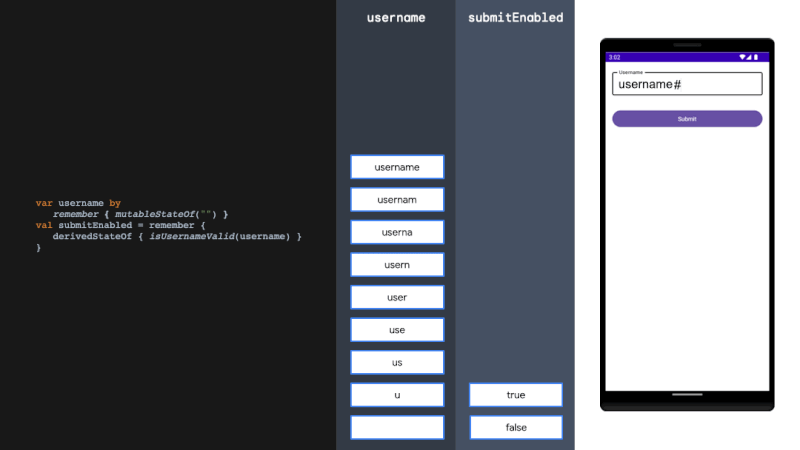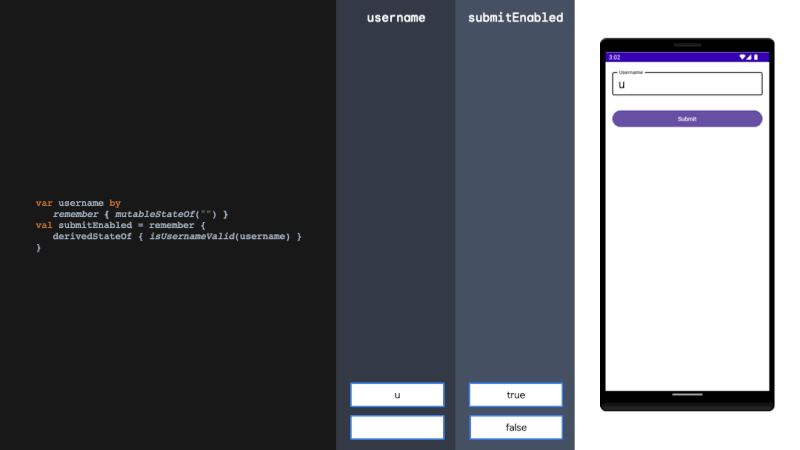
论文地址:https://arxiv.org/pdf/2408.17428
背景概述
-
研究问题:这篇文章要解决的问题是如何利用预训练的语言模型(LMs)来改进光学字符识别(OCR)的质量,特别是针对报纸和期刊等复杂布局的文档。
-
研究难点:该问题的研究难点包括:OCR技术在处理复杂布局的报纸和期刊时容易出现错误;现有的后OCR校正方法效果有限;如何有效利用语言模型的上下文自适应能力来提高OCR质量。
-
相关工作:该问题的研究相关工作有:基于众包校正的方法、在线安全测试、以及机器学习方法等。然而,2017年ICADAR后OCR校正竞赛发现,只有约一半的提交方法能够提高OCR质量。
研究方法
这篇论文提出了上下文利用OCR校正(CLOCR-C)的方法,用于解决OCR质量问题。具体来说,
-
CLOCR-C的定义:CLOCR-C利用基于Transformer的语言模型的填充和上下文自适应能力来改进OCR质量。其目标是识别损坏的文本并填充缺失的部分,以纠正文本到其原始状态。
-
方法论:研究方法分为三个部分:数据集和采样方法、语言模型和实验、评估方法。
-
数据集和采样方法:使用三个数字化的英国、澳大利亚和美国的报纸数据集,包括19世纪连载版(NCSE)和两个Overproof集合的数据集。对NCSE数据集进行分层随机抽样,确保样本的代表性。
-
语言模型和实验:比较了八种流行的LMs,包括GPT-4、GPT-3.5、Llama 3、Mixtral 8x7b、Claude 3 Opus和Claude 3 Haiku。使用字符错误率(CER)和错误减少百分比(ERP)作为评估指标。
-
评估方法:使用命名实体识别(NER)任务来评估后OCR校正的效果,采用余弦命名实体相似度(CoNES)作为评估指标。
-
实验设计
-
数据收集:使用了三个数据集:19世纪连载版(NCSE)、Overproof集合1和Overproof集合2。NCSE数据集包含6种期刊,Overproof集合包含高质量的对齐转录文本。
-
样本选择:对NCSE数据集进行分层随机抽样,确保样本的代表性。Overproof数据集全部使用。
-
参数配置:比较了八种LMs的性能,使用字符错误率(CER)和错误减少百分比(ERP)作为评估指标。对每个模型进行多种提示格式的测试,选择表现最好的提示格式。
结果与分析
-
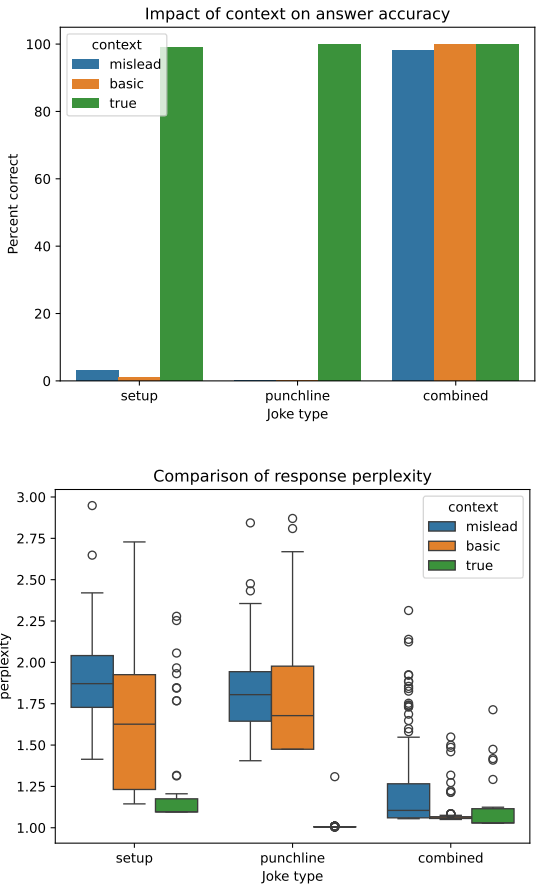
语言模型比较:在NCSE数据集上,GPT-4和Opus模型的CER减少了超过60%。在Sydney Morning Herald数据集上,CER从0.08减少到0.04,在Chronicling America数据集上,CER从0.1减少到0.05。
-
NER分析:所有LMs(除了Gemma)在所有数据集上的CoNES得分都有所提高,Opus模型在所有数据集上的CoNES得分超过了90%。
-
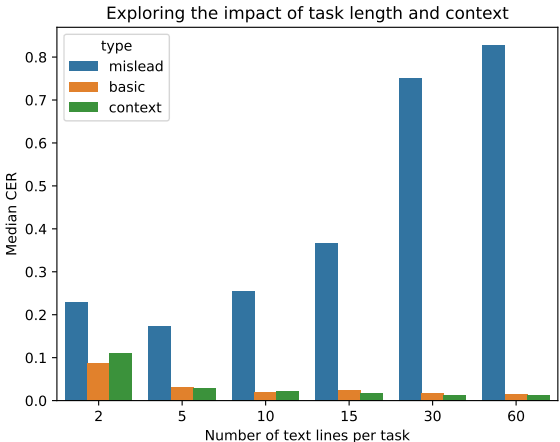
上下文信息的利用:提供真实上下文的提示显著提高了任务性能,甚至误导性提示在大多数情况下也能正确猜测答案。随着任务长度的增加,错误率显著降低。
总体结论
这篇论文展示了LMs可以用于后OCR校正,并且提供上下文信息可以显著提高校正性能。CLOCR-C方法利用了语言模型的上下文自适应能力和提示工程,能够有效改进OCR质量。然而,使用大型闭源模型进行校正成本较高,未来工作需要关注开源模型的训练和应用,以使CLOCR-C成为一种更具普及性的解决方案。
优点创新
-
创新方法:提出了CLOCR-C(Context Leveraging OCR Correction),利用基于Transformer的语言模型的填充和上下文自适应能力来提高OCR质量。
-
多语言模型比较:对比了八种流行的预训练语言模型,展示了它们在OCR后纠正任务中的表现。
-
数据集支持:发布了包含91篇文章的91千词的NCSE数据集,支持该领域的进一步研究。
-
下游任务分析:研究了OCR纠正对命名实体识别(NER)等下游任务的影响,发现纠正可以提高NER的Cosine命名实体相似度(CoNES)。
-
社会文化上下文的重要性:证明了在提示中提供社会文化上下文可以显著提高OCR纠正的性能,而误导性提示则会降低性能。
-
实验设计:设计了详细的实验设置和评估方法,包括不同提示格式和下游任务的评估指标。
当前不足
-
模型成本:使用大型闭源模型进行OCR纠正的成本可能非常高,限制了其在更广泛应用中的可行性。
-
训练数据和方法:不清楚为什么某些语言模型在OCR后纠正任务中表现优异,而其他模型则表现不佳,可能与训练数据和方法的细微变化有关。
-
OCR过程的限制:OCR过程中的物理位置错误(如打印行混合、文章分割不良和列分离失败)可能会影响后纠正的效果,需要OCR过程至少在这方面相对准确。
-
未来工作:需要进一步研究开源模型的训练,以降低成本,使CLOCR-C成为更具成本效益的解决方案。此外,还需要研究CLOCR-C是否适用于文本损坏严重的场景。
关键问题及回答
问题1:CLOCR-C方法在实验中使用了哪些具体的评估指标?这些指标是如何定义和计算的?
CLOCR-C方法使用了两种主要的评估指标:字符错误率(CER)和错误减少百分比(ERP)。
(1)字符错误率(CER):这是最常用的OCR错误评估指标,计算公式为:
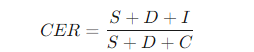
其中,S是替换错误数,D是删除错误数,I是插入错误数,C是正确文本的总字符数。CER越低,表示OCR识别的准确性越高。
(2)错误减少百分比(ERP):为了更好地衡量OCR校正的效果,论文定义了错误减少百分比,计算公式为:
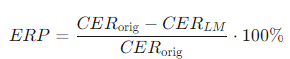
其中,CER-orig是原始OCR的字符错误率,CER-LM是经过语言模型校正后的字符错误率。ERP越高,表示语言模型校正的效果越好。
(3)此外,论文还使用了命名实体识别(NER)任务的**余弦命名实体相似度(CoNES)**作为下游任务的评估指标。CoNES通过计算两个文本中命名实体的相似度来评估校正效果,计算公式为:
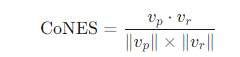
其中,v-p和v-r分别是预测文本和参考文本中命名实体的向量,∥v-p∥和∥v-r∥是向量的欧几里得范数。CoNES值越接近1,表示命名实体的一致性越高,校正效果越好。
问题2:在实验中,CLOCR-C方法使用了哪些数据集?这些数据集的选取和处理方法是什么?
CLOCR-C方法使用了三个数据集:
(1)19世纪连载版(NCSE):这是一个新发布的开源数据集,包含6种期刊:《Monthly Repository and Unitarian Chronicle》、《Northern Star》、《Leader》、《English Woman's Journal》、《Tomahawk》和《Publishers' Circular》。数据集经过数字化扫描并进行OCR处理。
(2)Overproof集合1和Overproof集合2:这两个数据集来自Evershed和Fitch(2014a)的研究,主要用于测试OCR后校正的效果。Overproof集合1是从TROVE Holley(2009)集合中收集的,但存在质量问题,如行边界改变、内容添加和单词更改。为了解决这些问题,Evershed和Fitch创建了Overproof集合2和Overproof集合3,后者来自一个人文数据存档。论文选择了Overproof集合2和Overproof集合3进行实验。
数据处理方法:
(1)NCSE数据集:进行了分层随机抽样,以确保样本的代表性。由于文章长度差异较大,选择了整个页面进行转录,而不是随机抽样文章。转录后的文本与原始OCR文本匹配,确保转录文本包含标题和句子边界信息。
(2)Overproof数据集:全部使用,因为这些数据集已经进行了高质量的对齐转录。数据集包括159篇文章,总字数约为70932字。
问题3:实验结果表明,不同语言模型在CLOCR-C任务中的表现有何差异?哪些模型表现最好,为什么?
实验结果表明,不同语言模型在CLOCR-C任务中的表现存在显著差异。以下是表现最好的模型及其原因:
-
GPT-4和Opus模型:在这两个模型中,Opus模型在NCSE数据集上的字符错误率(CER)减少了超过60%,在Sydney Morning Herald数据集上的CER从0.08减少到0.04,在Chronicling America数据集上的CER从0.1减少到0.05。GPT-4的表现也非常好,显示出强大的后OCR校正能力。
-
其他模型:Gemma 7B、Llama 3、Mixtral 8x7B、Claude 3 Haiku和Claude 3 Opus模型在某些数据集上也有改进,但总体表现不如GPT-4和Opus模型。特别是Gemma 7B和Mixtral 8x7B在所有数据集上都没有表现出明显的改进。
原因分析:
-
模型规模:较大的模型通常具有更多的参数,能够捕捉更多的上下文信息,从而在OCR校正任务中表现更好。GPT-4和Opus模型都是当前最大的语言模型之一,具有数十亿个参数。
-
提示工程:实验中使用的提示格式对模型性能有显著影响。选择合适的提示能够引导模型更好地理解任务需求,从而提高校正效果。例如,“expert recover publication text”和“full context”提示在大多数模型中表现最佳。
-
数据集特性:不同的数据集具有不同的文本特性和布局复杂性,模型在这些数据集上的表现也会有所不同。NCSE数据集包含复杂的期刊布局,而Overproof数据集则是对齐的高质量转录文本。
推荐阅读
《三年面试五年模拟》版本更新白皮书,迎接AIGC时代
AI多模态核心架构五部曲:
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
AI多模态模型架构之LLM主干(1):ChatGLM系列
AI多模态模型架构之LLM主干(2):Qwen系列
AI多模态模型架构之LLM主干(3):Llama系列
AI多模态模型架构之输出映射器:Output Projector
AI多模态模型架构之模态生成器:Modality Generator
AI多模态实战教程:
AI多模态教程:从0到1搭建VisualGLM图文大模型案例
AI多模态教程:Mini-InternVL1.5多模态大模型实践指南
AI多模态教程:Qwen-VL多模态大模型实践指南
AI多模态实战教程:面壁智能MiniCPM-V多模态大模型问答交互、llama.cpp模型量化和推理
智谱推出创新AI模型GLM-4-9B:国家队开源生态的新里程碑