batch normalization(批次标准化)
batch normalization--Tarining
- 直接改error surface的landscape,把山“铲平”
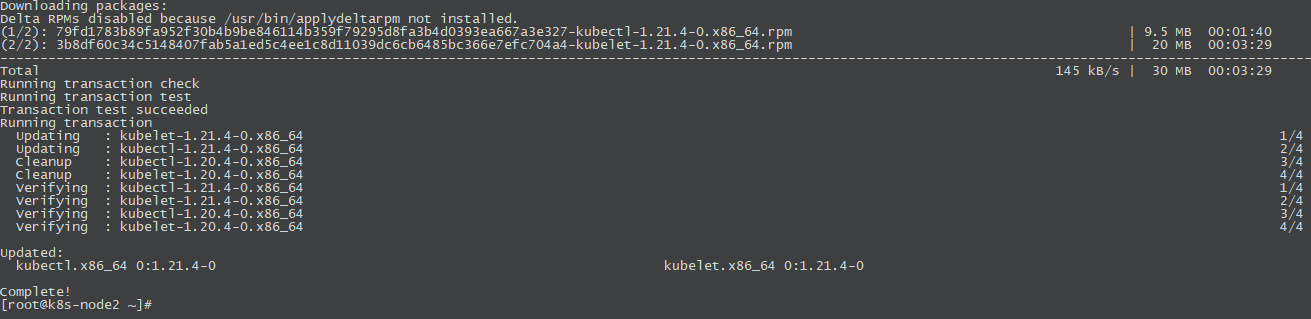
- 有时候尽管error surface是个“碗”,都不见得好train。如下图所示:
w1,w2对loss的斜率差别很大,w1方向上斜率变化很小,w2方向上斜率变化很大,直接用固定的learning rate很难train,所以需要自学习的learning rate,这种比较高阶的optimization或者是这个task的批次标准化,直接把“山铲平”
w1和w2斜率差很大的原因是:x1数值输入相较x2都很小,w1+w1产生的y+
y就会小,进而产生的
y就会小,最终产生的L就会小,表现出来就是w1方向上斜率变化很小;同理可以分析出来w1方向上斜率变化很大的原因:x2数值输入相较x1都很大,w2+
w2产生的y+
y就会大,进而产生的
y就会大,最终产生的L就会大,表现出来就是w1方向上斜率变化很大,所以,我们就给相同值的feature,让w1和w2对L的斜率影响一样大

这些让feature的输入值变得一样的方法统称为Feature Normalization
以下是Feature Normalization中的一种方法:
将所有的值都变成0~1

Feature Normalization会让你的train更快
为了让Feature Normalization的效果能同样延续到w2,那就需要对z,a进行正则化(2选一做即可)(因为x正则化之后得到的w1的值差异性可能很大,所以要继续正则化)(如果选择 sigmoid,比较推荐对 z 做特征归一化,因为 sigmoid 是一个 s 的形状,其在 0 附近斜率比较大,如果对 z 做特征归一化,把所有的值都挪到 0 附近,到时候算梯度的时候,算出来的值会比较大。如果使用别的激活函数,可能对 a 归一化也会有好的结果。)

举例来看,z的正则化:


在做批量归一化的时候,往往还会做如下操作:


由上述式子,我们就可以知道 之前的 x˜1, x˜2 x˜3 是独立分开处理的,但是在做特征归一化以后,这三个样本变得彼此关联了。所以有做特征归一化的时候,可以把整个过程当做是网络的一部分。即有一个比较大的网络,该网络吃一堆输入,用这堆输入在这个网络里面计算出 µ,σ,接下来产生一堆输出。
因为训练数据非常多,现在一个数据集可能有上百万笔数据,GPU 的显存无法把它整个数据集的数据都加载进去。因此,在实现的时候,我们不会让这一个网络考虑整个训练数据里面的所有样本,而是只会考虑一个批量里面的样本。这一招就叫做batch normalization。但是要求batch要足够大,也许批量大小里面的数据就足以表示整个数据集的分布。
batch normalization--Testing(Influence)
batch normalization--Testing(Influence)运作过程:批量归一化在测试的时候,并不需要做什么特别的处理,PyTorch 已经处理好了。在训练的时候,如果有在做批量归一化,每一个批量计算出来的 µ,σ,都会拿出来算移动平均(moving average)。假设现在有各个批量计算出来的 µ1, µ2, µ3, · · · · · · , µt,则可以计算移动平均


Batch Normalization能帮助Optimization的原因:
原始的批量归一化论文里面提出内部协变量偏移(internal covariate shift)概念。如下图所示,假设网络有很多层,-x 通过第一层后得到 a,a 通过第二层以后得到 b;计算出梯度以后,把 A 更新成 A′,把 B 这一层的参数更新成 B′。但是作者认为说,我们在计算 B 更新到 B′ 的梯度的时候,这个时候前一层的参数是 A,或者是前一层的输出是 a。那当前一层从 A 变成 A′ 的时候,其输出就从 a 变成 a′ 。但是我们计算这个梯度的时候,是根据 a 算出来,所以这个更新的方向也许它适合用在 a 上,但不适合用在 a′ 上面。因为我们每次都有做批量归一化,就会让 a 和a′ 的分布比较接近,也许这样就会对训练有帮助。

这篇论文从不同的角度来说明内部协变量偏移不一定是训练网络的时候的一个问题。批量归一化会比较好,可能不一定是因为它解决了内部协变量偏移。这篇论文里面做了很多实验,比如其比较了训练的时候 a 的分布的变化,发现不管有没有做批量归一化,其变化都不大。就算是变化很大,对训练也没有太大的伤害。不管是根据 a 算出来的梯度,还是根据 a′ 算出来的梯度,方向居然都差不多。内部协变量偏移可能不是训练网络的时候,最主要的问题,它可能也不是批量归一化会好的一个的关键。

Convolutional NeuralNetwork (CNN)卷积神经网络
版本一
- 是network的一个架构,(network的架构会让结果变得更好)。
- 专门用在影像上的。
- 这个task是以图像为例。
- 假设输入的图片的大小是相同的(目前的图像处理都是这样的假设,如果原始图片大小不一,就通过手段,让图片大小一致。
- 向量中的每一个数值代表颜色强度

如果把向量当做全连接网络的输入,输入的特征向量(feature vector)的长度就是 100 × 100 × 3。这是一个非常长的向量。由于每个神经元跟输入的向量中的每个数值都需要一个权重,所以当输入的向量长度是 100 × 100 × 3,且第 1 层有 1000 个神经元时,第 1 层的权重就需要 1000×100×100×3 = 3 ×107 个权重,这是一个非常巨大的数目。更多的参数为模型带来了更好的弹性和更强的能力,但也增加了过拟合的风险。模型的弹性越大,就越容易过拟合。为了避免过拟合,在做图像识别的时候,考虑到图像本身的特性,并不一定需要全连接,即不需要每个神经元跟输入的每个维度都有一个权重。

假设我们的任务是让网络识别出图像的动物。对一个图像识别的类神经网络里面的神经元而言,它要做的就是检测图像里面有没有出现一些特别重要的模式(pattern),这些模式是代表了某种物体的。比如有三个神经元分别看到鸟嘴、眼睛、鸟爪 3 个模式,这就代表类神经网络看到了一只鸟,人在判断一个物体的时候,往往也是抓最重要的特征。看到这些特征以后,就会直觉地看到了某种物体。对于机器,也许这是一个有效的判断图像中物体的方法。但假设用神经元来判断某种模式是否出现,也许并不需要每个神经元都去看一张完整的图像。因为并不需要看整张完整的图像才能判断重要的模式(比如鸟嘴、眼睛、鸟爪)是否出现,如下图所示,要知道图像有没有一个鸟嘴,只要看非常小的范围。这些神经元不需要把整张图像当作输入,只需要把图像的一小部分当作输入,就足以让它们检测某些特别关键的模式是否出现,

根据上图观察 可以做下图简化,卷积神经网络会设定一个区域,即感受野(receptivefield),每个神经元都只关心自己的感受野里面发生的事情,感受野是由我们自己决定的。比如在图 4.6 中,蓝色的神经元的守备范围就是红色正方体框的感受野。这个感受野里面有3 × 3 × 3 个数值。对蓝色的神经元,它只需要关心这个小范围,不需要在意整张图像里面有什么东西,只在意它自己的感受野里面发生的事情就好。

感受野(receptivefield)是由自己决定的,感受野(receptivefield)彼此之间是可以重叠的
 以下是最经典的receptivefield安排:
以下是最经典的receptivefield安排:
我们把左上角的感受野往右移一个步幅,就制造出一个新的守备范围,即新的感受野。移动的量称为步幅(stride),图中的这个例子里面,步幅就等于 2。步幅是一个超参数,需要人为调整。因为希望感受野跟感受野之间是有重叠的,所以步幅往往不会设太大,一般设为 1 或 2。
Q: 为什么希望感受野之间是有重叠的呢?A: 因为假设感受野完全没有重叠,如果有一个模式正好出现在两个感受野的交界上面,就没有任何神经元去检测它,这个模式可能会丢失,所以希望感受野彼此之间有高度的重叠。如令步幅 = 2,感受野就会重叠。
接下来需要考虑一个问题:感受野超出了图像的范围,怎么办呢?如果不在超过图像的范围“摆”感受野,就没有神经元去检测出现在边界的模式,这样就会漏掉图像边界的地方,所以一般边界的地方也会考虑的。
如图 所示,超出范围就做填充(padding),填充就是补值,一般使用零填充(zero padding),超出范围就补 0,如果感受野有一部分超出图像的范围之外,就当做那个里面的值都是 0。其实也有别的补值的方法,比如补整张图像里面所有值的平均值或者把边界的这些数字拿出来补没有值的地方。除了水平方向的移动,也会有垂直方向上的移动,垂直方向步幅也是设 2,如图 所示。我们就按照这个方式扫过整张图像,所以整张图像里面每一寸土地都是有被某一个感受野覆盖的。也就是图像里面每个位置都有一群神经元在检测那个地方,有没有出现某些模式。这个是第 1 个简化。

不同pattern的位置不同,receptivefield作用是一样的,就每个图片都重新设计一个神经元,是一个重复性工作,没有必要。如下图:

由上图的问题,我我们提出了以下的解决方法:
可以让不同感受野的神经元共享参数,也就是做参数共享(parameter sharing),如下图所示。所谓参数共享就是两个神经元的权重完全是一样的。

总的来说, 参数共享(parameter sharing)如下图:
 常见参数共享(parameter sharing)方法:
常见参数共享(parameter sharing)方法:

总结:

版本二
一个卷积层里面就是有一排的滤波器,每个滤波器都是一个 3 × 3 × 通道,其作用是要去图像里面检测某个模式。

滤波器在图像里面检测某个模式过程:
filter里的数值是未知的,是model里的parameter,需要通过gradient确认下来

假设这些滤波器里面的数值已经找出来了,如图所示。如图所示,这是一个 6 × 6 的大小的图像。先把滤波器放在图像的左上角,接着把滤波器里面所有的 9 个值跟左上角这个范围内的 9 个值对应相乘再相加,也就是做内积,结果是 3。接下来设置好步幅,然后把滤波器往右移或往下移,重复几次,可得到模式检测的结果,图中的步幅为 1。使用滤波器 1 检测模式时,如果出现图像 3 × 3 范围内对角线都是 1 这种模式的时候,输出的数值会最大。输出里面左上角和左下角的值最大,所以左上角和左下角有出现对角线都是 1 的模式,这是第 1 个滤波器。
 接下来把每个滤波器都做重复的过程。比如说有第 2 个滤波器,它用来检测图像 3 × 3 范围内中间一列都为 1 的模式。把第 2 个滤波器先从左上角开始扫起,得到一个数值,往右移一个步幅,再得到一个数值再往右移一个步幅,再得到一个数值。重复同样的操作,直到把整张图像都扫完,就得到另外一组数值。每个滤波器都会给我们一组数字,红色的滤波器给我们一组数字,蓝色的滤波器给我们另外一组数字。如果有 64 个滤波器,就可以得到 64 组的数字。这组数字称为特征映射(feature map)。当一张图像通过一个卷积层里面一堆滤波器的时候,就会产生一个特征映射。假设卷积层里面有 64 个滤波器,产生的特征映射就有 64 组数字。在上述例子中每一组是 4 × 4,即第 1 个滤波器产生 4 × 4 个数字,第2 个滤波器也产生 4 × 4 个数字,第 3 个也产生 4 × 4 个数字,64 个滤波器都产生 4 × 4 个数字。特征映射可以看成是另外一张新的图像,只是这个图像的通道不是 RGB 3 个通道,有64 个通道,每个通道就对应到一个滤波器。本来一张图像有 3 个通道,通过一个卷积变成一张新的有 64 个通道图像。
接下来把每个滤波器都做重复的过程。比如说有第 2 个滤波器,它用来检测图像 3 × 3 范围内中间一列都为 1 的模式。把第 2 个滤波器先从左上角开始扫起,得到一个数值,往右移一个步幅,再得到一个数值再往右移一个步幅,再得到一个数值。重复同样的操作,直到把整张图像都扫完,就得到另外一组数值。每个滤波器都会给我们一组数字,红色的滤波器给我们一组数字,蓝色的滤波器给我们另外一组数字。如果有 64 个滤波器,就可以得到 64 组的数字。这组数字称为特征映射(feature map)。当一张图像通过一个卷积层里面一堆滤波器的时候,就会产生一个特征映射。假设卷积层里面有 64 个滤波器,产生的特征映射就有 64 组数字。在上述例子中每一组是 4 × 4,即第 1 个滤波器产生 4 × 4 个数字,第2 个滤波器也产生 4 × 4 个数字,第 3 个也产生 4 × 4 个数字,64 个滤波器都产生 4 × 4 个数字。特征映射可以看成是另外一张新的图像,只是这个图像的通道不是 RGB 3 个通道,有64 个通道,每个通道就对应到一个滤波器。本来一张图像有 3 个通道,通过一个卷积变成一张新的有 64 个通道图像。 
卷积层是可以叠很多层的,如图 4.22 所示,第 2 层的卷积里面也有一堆的滤波器,每个滤波器的大小设成 3 × 3。其高度必须设为 64,因为滤波器的高度就是它要处理的图像的通道。如果输入的图像是黑白的,通道是 1,滤波器的高度就是 1。如果输入的图像是彩色的,通道为 3,滤波器的高度就是 3。对于第 2 个卷积层,它的输入也是一张图像,这个图像的通道是 64。这个 64 是前一个卷积层的滤波器数目,前一个卷积层的滤波器数目是 64,输出以后就是 64 个通道。所以如果第 2 层想要把这个图像当做输入,滤波器的高度必须是 64。所以第 2 层也有一组滤波器,只是这组滤波器的高度是 64。

俩个版本的对比:
第 1 个版本的故事里面说到了有一些神经元,这些神经元会共用参数,这些共用的参数就是第 2 个版本的故事里面的滤波器。如上图所示,这组参数有 3 × 3 × 3 个,即滤波器里面有 3 × 3 × 3 个数字,这边特别还用颜色把这些数字圈起来,权重就是这些数字。为了简化,这边去掉了偏置。神经元是有偏置的,滤波器也是有偏置的。在一般的实践上,卷积神经网络的滤波器都是有偏置的。如图上所示,在第 1 个版本的故事里面,不同的神经元可以共享权重,去守备不同的范围。而共享权重其实就是用滤波器扫过一张图像,这个过程就是卷积。这就是卷积层名字的由来。把滤波器扫过图像就相当于不同的感受野神经元可以共用参数,这组共用的参数就叫做一个滤波器。如上图示,在第 1 个版本的故事里面,不同的神经元可以共享权重,去守备不同的范围。而共享权重其实就是用滤波器扫过一张图像,这个过程就是卷积。这就是卷积层名字的由来。把滤波器扫过图像就相当于不同的感受野神经元可以共用参数,这组共用的参数就叫做一个滤波器。

下采样不影响模式检测
把一张比较大的图像做下采样(downsampling),把图像偶数的列都拿掉,奇数的行都拿掉,图像变成为原来的 1/4,但是不会影响里面是什么东西。如图 4.26 所示,把一张大的鸟的图像缩小,这张小的图像还是一只鸟。
根据第 3 个观察,汇聚被用到了图像识别中。汇聚没有参数,所以它不是一个层,它里面没有权重,它没有要学习的东西,汇聚比较像 Sigmoid、ReLU 等激活函数。因为它里面是没有要学习的参数的,它就是一个操作符(operator),其行为都是固定好的,不需要根据数据学任何东西。每个滤波器都产生一组数字,要做汇聚的时候,把这些数字分组,可以 2 × 2 个一组,3 × 3、4 × 4 也可以,这个是我们自己决定的,图 4.27 中的例子是 2 × 2 个一组。汇聚有很多不同的版本,以最大汇聚(max pooling)为例。最大汇聚在每一组里面选一个代表,选的代表就是最大的一个,如图 4.28 所示。除了最大汇聚,还有平均汇聚(mean pooling),平均汇聚是取每一组的平均值。做完卷积以后,往往后面还会搭配汇聚。汇聚就是把图像变小。做完卷积以后会得到一张图像,这张图像里面有很多的通道。做完汇聚以后,这张图像的通道不变。如图 4.29 所示


在刚才的例子里面,本来 4 × 4 的图像,如果把这个输出的数值 2 × 2 个一组,4 × 4 的图像就会变成 2 × 2 的图像,这就是汇聚所做的事情。一般在实践上,往往就是卷积跟汇聚交替使用,可能做几次卷积,做一次汇聚。比如两次卷积,一次汇聚。不过汇聚对于模型的性能(performance)可能会带来一点伤害。假设要检测的是非常微细的东西,随便做下采样,性能可能会稍微差一点。所以近年来图像的网络的设计往往也开始把汇聚丢掉,它会做这种全卷积的神经网络,整个网络里面都是卷积,完全都不用汇聚。汇聚最主要的作用是减少运算量,通过下采样把图像变小,从而减少运算量。随着近年来运算能力越来越强,如果运算资源足够支撑不做汇聚,很多网络的架构的设计往往就不做汇聚,而是使用全卷积,卷积从头到尾,看看做不做得起来,看看能不能做得更好。一般架构就是卷积加汇聚,汇聚是可有可无的,很多人可能会选择不用汇聚。如图 4.30所示,如果做完几次卷积和汇聚以后,把汇聚的输出做扁平化(flatten),再把这个向量丢进全连接层里面,最终还要过个 softmax 来得到图像识别的结果。这就是一个经典的图像识别的网络,里面有卷积、汇聚和扁平化,最后再通过几个全连接层或 softmax 来得到图像识别的结果。