与 PDF 互动是很酷的。你可以与你的笔记、书籍和文档等进行聊天。
本文将帮助你构建一个基于 Multi RAG Streamlit 的 Web 应用程序,通过对话 AI 聊天机器人来读取、处理和互动PDF数据。

以下是该应用程序的工作步骤,用简单的语言进行说明。
RAG%20%E8%81%8A%E5%A4%A9%E6%9C%BA%E5%99%A8%E4%BA%BA&spm=1018.2226.3001.4187">配置必要的工具
该应用程序首先导入了各种强大的库:
- Streamlit:用于创建Web界面。
- PyPDF2:用于读取PDF文件的工具。
- Langchain:用于自然语言处理和创建对话AI的一套工具。
- FAISS:用于高效相似性搜索的向量库,在大数据集中快速查找信息非常有用。
import streamlit as st
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.embeddings.spacy_embeddings import SpacyEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.tools.retriever import create_retriever_tool
from dotenv import load_dotenv
from langchain_anthropic import ChatAnthropic
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.agents import AgentExecutor, create_tool_calling_agentimport os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"RAG%20%E8%81%8A%E5%A4%A9%E6%9C%BA%E5%99%A8%E4%BA%BA&spm=1018.2226.3001.4187">读取和处理PDF文件
应用程序的第一个主要功能是读取PDF文件:
- PDF阅读器:当用户上传一个或多个PDF文件时,应用程序读取这些文档的每一页并提取文本,将其合并为一个连续的字符串。
一旦提取文本,它将被分割成可管理的块:
- 文本分割器:使用Langchain库,将文本分割成每块1000个字符。这种分割有助于更高效地处理和分析文本。
def pdf_read(pdf_doc):text = ""for pdf in pdf_doc:pdf_reader = PdfReader(pdf)for page in pdf_reader.pages:text += page.extract_text()return textdef get_chunks(text):text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)chunks = text_splitter.split_text(text)return chunksRAG%20%E8%81%8A%E5%A4%A9%E6%9C%BA%E5%99%A8%E4%BA%BA&spm=1018.2226.3001.4187">创建可搜索的文本数据库和生成嵌入
为了使文本可搜索,应用程序将文本块转换为向量表示:
- 向量存储:应用程序使用FAISS库将文本块转换为向量,并将这些向量本地保存。这一转换至关重要,因为它允许系统在文本中执行快速高效的搜索。
embeddings = SpacyEmbeddings(model_name="en_core_web_sm")def vector_store(text_chunks):vector_store = FAISS.from_texts(text_chunks, embedding=embeddings)vector_store.save_local("faiss_db")RAG%20%E8%81%8A%E5%A4%A9%E6%9C%BA%E5%99%A8%E4%BA%BA&spm=1018.2226.3001.4187">设置对话AI
该应用程序的核心是对话AI,它使用OpenAI的强大模型:
- AI配置:应用程序使用OpenAI的GPT模型设置对话AI。这个AI设计用于回答基于已处理的PDF内容的问题。
- 对话链:AI使用一组提示来理解上下文并为用户查询提供准确的响应。如果文本中没有问题的答案,AI会回复“答案不在上下文中”,确保用户不会收到错误信息。
def get_conversational_chain(tools, ques):llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)prompt = ChatPromptTemplate.from_messages([("system", "You are a helpful assistant. Answer the question as detailed as possible from the provided context, make sure to provide all the details, if the answer is not in provided context just say, 'answer is not available in the context', don't provide the wrong answer"),("placeholder", "{chat_history}"),("human", "{input}"),("placeholder", "{agent_scratchpad}"),])tool = [tools]agent = create_tool_calling_agent(llm, tool, prompt)agent_executor = AgentExecutor(agent=agent, tools=tool, verbose=True)response = agent_executor.invoke({"input": ques})print(response)st.write("Reply: ", response['output'])def user_input(user_question):new_db = FAISS.load_local("faiss_db", embeddings, allow_dangerous_deserialization=True)retriever = new_db.as_retriever()retrieval_chain = create_retriever_tool(retriever, "pdf_extractor", "This tool is to give answer to queries from the pdf")get_conversational_chain(retrieval_chain, user_question)RAG%20%E8%81%8A%E5%A4%A9%E6%9C%BA%E5%99%A8%E4%BA%BA&spm=1018.2226.3001.4187">用户互动
在后端准备就绪后,应用程序使用Streamlit创建一个用户友好的界面:
- 用户界面:用户看到一个简单的文本输入框,他们可以在其中输入与PDF内容相关的问题。应用程序会直接在网页上显示AI的响应。
- 文件上传和处理:用户可以随时上传新的PDF文件。应用程序会即时处理这些文件,更新AI搜索的新文本数据库。
def main():st.set_page_config("Chat PDF")st.header("RAG based Chat with PDF")user_question = st.text_input("Ask a Question from the PDF Files")if user_question:user_input(user_question)with st.sidebar:pdf_doc = st.file_uploader("Upload your PDF Files and Click on the Submit & Process Button", accept_multiple_files=True)if st.button("Submit & Process"):with st.spinner("Processing..."):raw_text = pdf_read(pdf_doc)text_chunks = get_chunks(raw_text)vector_store(text_chunks)st.success("Done")RAG%20%E8%81%8A%E5%A4%A9%E6%9C%BA%E5%99%A8%E4%BA%BA&spm=1018.2226.3001.4187">结论
完整代码
import streamlit as st
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.embeddings.spacy_embeddings import SpacyEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.tools.retriever import create_retriever_tool
from dotenv import load_dotenv
from langchain_anthropic import ChatAnthropic
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.agents import AgentExecutor, create_tool_calling_agentimport os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"embeddings = SpacyEmbeddings(model_name="en_core_web_sm")
def pdf_read(pdf_doc):text = ""for pdf in pdf_doc:pdf_reader = PdfReader(pdf)for page in pdf_reader.pages:text += page.extract_text()return textdef get_chunks(text):text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)chunks = text_splitter.split_text(text)return chunksdef vector_store(text_chunks):vector_store = FAISS.from_texts(text_chunks, embedding=embeddings)vector_store.save_local("faiss_db")def get_conversational_chain(tools,ques):llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, apikey)prompt = ChatPromptTemplate.from_messages([("system","""You are a helpful assistant. Answer the question as detailed as possible from the provided context, make sure to provide all the details, if the answer is not inprovided context just say, "answer is not available in the context", don't provide the wrong answer""",),("placeholder", "{chat_history}"),("human", "{input}"),("placeholder", "{agent_scratchpad}"),]
)tool=[tools]agent = create_tool_calling_agent(llm, tool, prompt)agent_executor = AgentExecutor(agent=agent, tools=tool, verbose=True)response=agent_executor.invoke({"input": ques})print(response)st.write("Reply: ", response['output'])def user_input(user_question):new_db = FAISS.load_local("faiss_db", embeddings,allow_dangerous_deserialization=True)retriever=new_db.as_retriever()retrieval_chain= create_retriever_tool(retriever,"pdf_extractor","This tool is to give answer to queries from the pdf")get_conversational_chain(retrieval_chain,user_question)def main():st.set_page_config("Chat PDF")st.header("RAG based Chat with PDF")user_question = st.text_input("Ask a Question from the PDF Files")if user_question:user_input(user_question)with st.sidebar:st.title("Menu:")pdf_doc = st.file_uploader("Upload your PDF Files and Click on the Submit & Process Button", accept_multiple_files=True)if st.button("Submit & Process"):with st.spinner("Processing..."):raw_text = pdf_read(pdf_doc)text_chunks = get_chunks(raw_text)vector_store(text_chunks)st.success("Done")if __name__ == "__main__":main()通过将应用程序保存为 app.py,然后使用
streamlit run app.py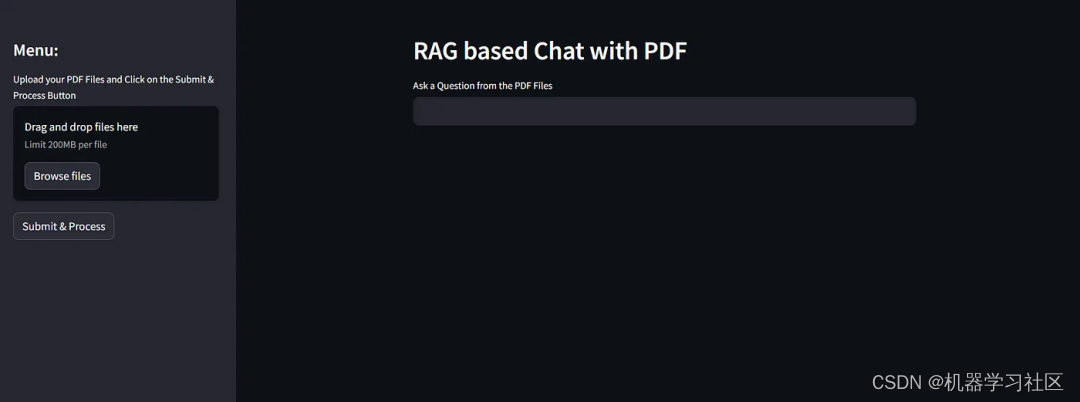
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。













![[Meachines] [Medium] SecNotes XSRF跨站请求伪造+SMB-Webshell上传+Linux子系统命令历史记录泄露权限提升](https://img-blog.csdnimg.cn/img_convert/fd12b9d0eb487f9f3b63a473b30a5f50.jpeg)

