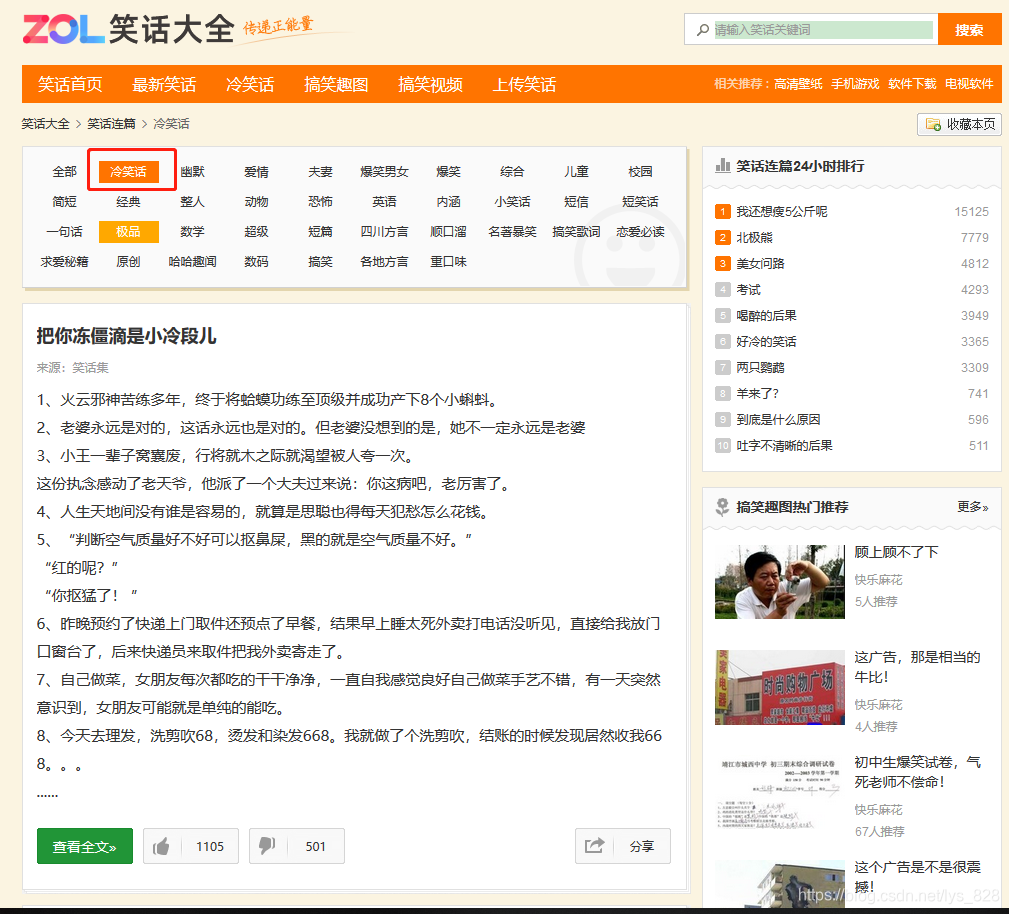
1. 打开笑话大全网
笑话大全网址,找到笑话分类,选择冷笑话
2. 窥探网页细节
2.1 观察翻页之后URL的变化
第一页的URL:http://xiaohua.zol.com.cn/lengxiaohua/
第二页的URL:http://xiaohua.zol.com.cn/lengxiaohua/2.html
第三页的URL:http://xiaohua.zol.com.cn/lengxiaohua/3.html
......
看到这里就可以找出里面的规律, 第一页的话URL应该是http://xiaohua.zol.com.cn/lengxiaohua/1.html,不妨把这个网址输入,验证一下,结果正是对应了上面的规律
2.2 推荐使用浏览器为Chrome(谷歌)
主要是插件丰富,原生功能设计对爬虫开发者非常友好

2.3 获取页面内容
利用requests输出首页内容,要先安装requests库
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
安装成功后,运行代码如下
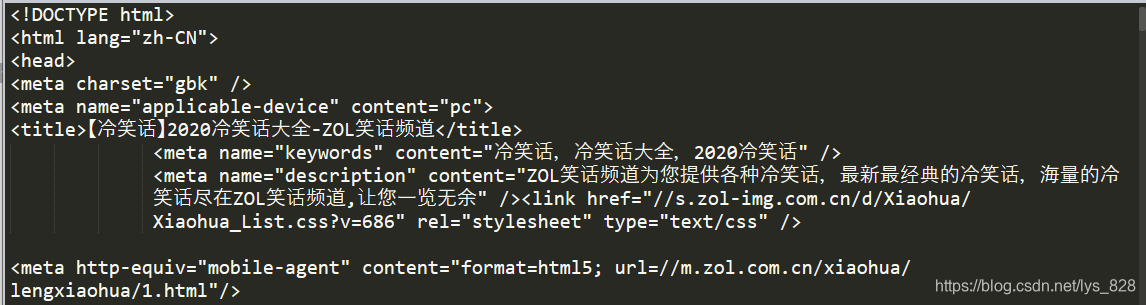
import requestsheaders = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}html = requests.get('http://xiaohua.zol.com.cn/lengxiaohua/1.html',headers = headers)print(html.text)
–> 输出结果为:
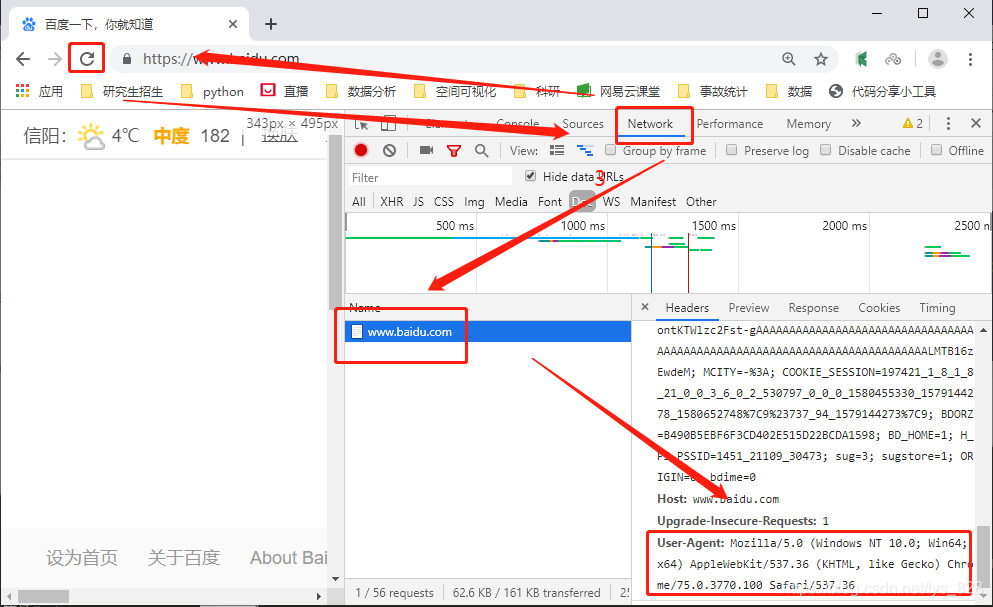
headers就是请求头,可以通过打开一个浏览器,然后网页空白处右键选择“检查”,点击Network,然后刷新一下页面,这时候选择右侧出现的第一条信息,往下拉就可以获得headers了,如下
如果要获取第二页的内容,直接将网址(URL)修改一下,将里面的数字1,变成数字2,因此要爬取多页的消化信息时,就可以构造一个url循环就可以了,比如获取前十页的笑话信息,代码如下
for i in range(10):html = requests.get('http://xiaohua.zol.com.cn/lengxiaohua/{}.html'.format(i+1),headers = headerprint(html.text)
–> 输出结果为: 类似输出一页的结果样式,输出的是十页的结果
3. 页面源代码解析
我们print输出的正是html的内容,可以通过浏览器,在目标页面点击鼠标右键,选择“查看网页源代码(Ctrl + U)”,如下
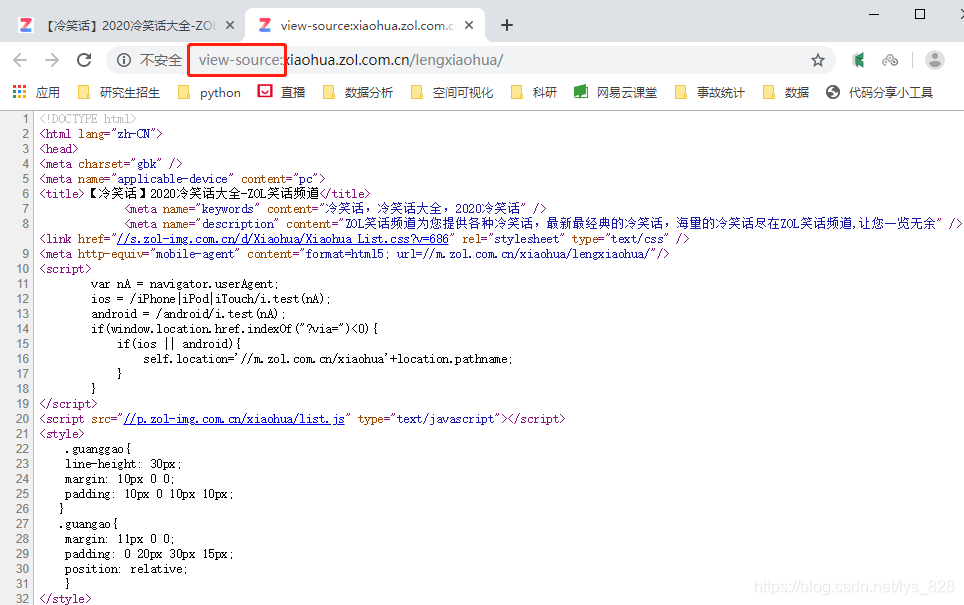
其中网址最前面的:view-source就是查看源代码的意思
3.1 分析网页源代码
就以刚刚获得的笑话大全中冷笑话页面的源代码为例

其中:
lang = “zh-CN” (lang就是language的缩写代表语言; “zh-CN”,其中zh就是中文的意思,CN代表着中国)
charset = “utf-8/gbk” 代表着字符集的编码形式,其中gbk编码里面已经包含了很多的汉字了
3.2 学会“一一对应”的观察技巧
我们日常可以看到的页面内容
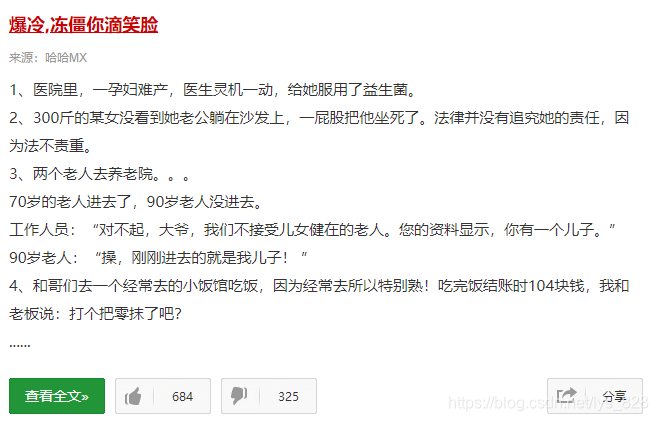
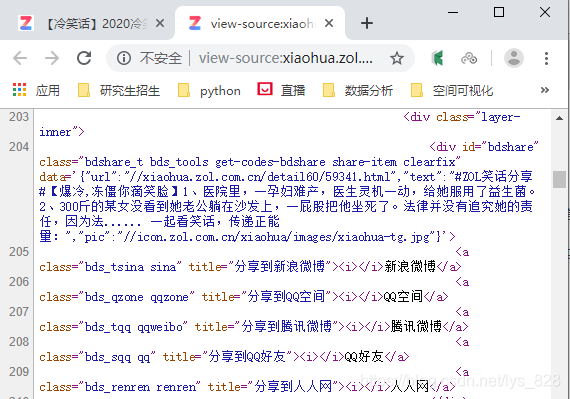
源代码中对应的内容(按住ctrl + f 进行相关字词的查找)
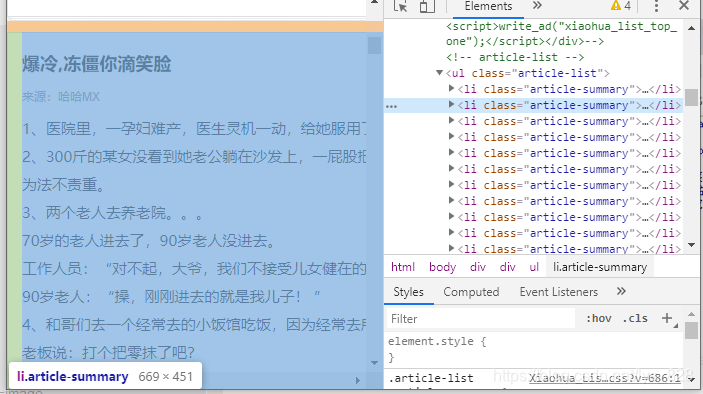
3.3 明确任务
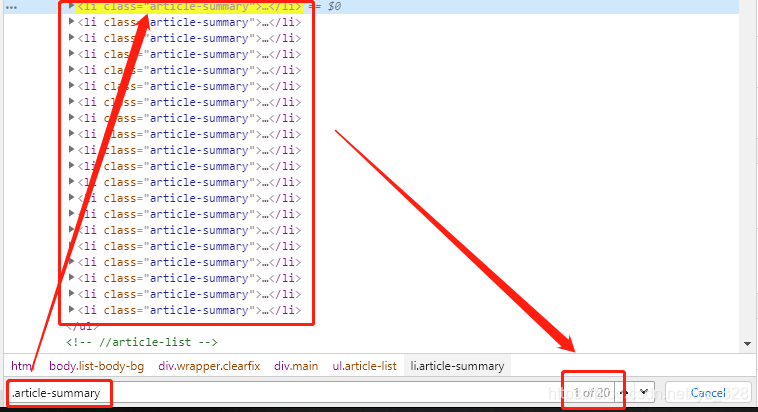
通过检查,可以发现每一个笑话都包含在<<li class="article-summary>>里面
3.4 BeautifulSoup工具
解析网页的强力工具,爬虫利器,安装(顺带把lxml库安装)和如何使用的代码如下,关于“lxml”的知识,我会在《爬虫专项》里面介绍这里就不再进行详细说明了
pip install bs4 lxml -i https://pypi.tuna.tsinghua.edu.cn/simple #安装代码
from bs4 import BeautifulSoup #库的使用
3.5 Tag标签介绍
Tag就是HTML中的一个个标签,但是需要注意,这里只会返回第一个符合要求的标签(即使HTML中有多个符合要求的标签),用代码解释一下
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}r = requests.get("http://xiaohua.zol.com.cn/lengxiaohua/1.html", headers = headers)
html = r.text
soup = BeautifulSoup(html, "lxml")
#print(soup.prettify())
print('***title***')
print(soup.title)
print('\n***head***')
print(soup.head)
print("\n***a***")
print(soup.a)
print("\n***p***")
print(soup.p)
–> 输出结果为: 只会输出一个title、head、a和p标签
***title***
<title>【冷笑话】2020冷笑话大全-ZOL笑话频道</title>***head***
<head>
<meta charset="utf-8"/>
<meta content="pc" name="applicable-device"/>
<title>【冷笑话】2020冷笑话大全-ZOL笑话频道</title>
<meta content="冷笑话,冷笑话大全,2020冷笑话" name="keywords"/>
<meta content="ZOL笑话频道为您提供各种冷笑话,最新最经典的冷笑话,海量的冷笑话尽在ZOL笑话频道,让您一览无余" name="description"/><link href="//s.zol-img.com.cn/d/Xiaohua/Xiaohua_List.css?v=686" rel="stylesheet" type="text/css"/>
<meta content="format=html5; url=//m.zol.com.cn/xiaohua/lengxiaohua/1.html" http-equiv="mobile-agent"/>
<script>var nA = navigator.userAgent;ios = /iPhone|iPod|iTouch/i.test(nA);android = /android/i.test(nA);if(window.location.href.indexOf("?via=")<0){if(ios || android){self.location='//m.zol.com.cn/xiaohua'+location.pathname;}}
</script>
<script src="//p.zol-img.com.cn/xiaohua/list.js" type="text/javascript"></script>
<style>.guanggao{line-height: 30px;margin: 10px 0 0;padding: 10px 0 10px 10px;} .guangao{margin: 11px 0 0;padding: 0 20px 30px 15px;position: relative;}
</style>
</head>***a***
<a class="logo" href="/">
<img alt="ZOL笑话大全" height="32" src="//icon.zol-img.com.cn/mainpage/2019logo/logo-xiaohua.png" width="214"/>
</a>***p***
<p>1、火云邪神苦练多年,终于将蛤蟆功练至顶级并成功产下8个小蝌蚪。</p>
[Finished in 0.6s]
| soup.prettify() | 标准打印输出 |
|---|---|
| soup.title | 输出第一个满足的title标签 |
| soup.head | 输出第一个满足的head标签 |
| soup.a | 输出第一个满足的a标签 |
| soup.p | 输出第一个满足的p标签 |
3.6 查找全部的标签
如果想找到全部的Tag(标签),需要使用.find_all方法,就刻意获得当前Tag的所有子节点,并判断是否符合过滤器的条件,举个栗子,获取所有的p标签
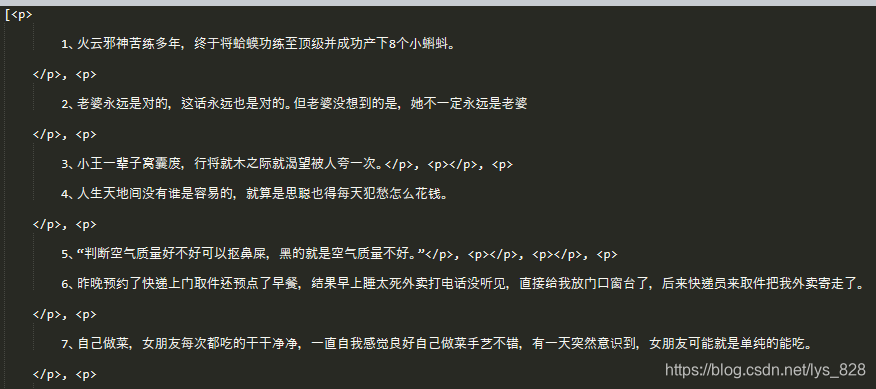
print(soup.find_all("p"))
–> 输出结果为: 只截取部分输出
3.7 keyward参数
这个参数不是该函数内置的函数名,而是对应的想要搜索的关键字的名字,比如
<a accesskey="I" href="genindex.html" title="General Index">insex</a>
print(soup.find_all(accesskey="I"))
4. CSS选择器
★★★★★ soup.select()和soup.find_all()方式是等价的,两者返回的都是列表,举例如下
soup.select('title')
soup.find_all('title')soup.select('a')
soup.find_all('a')soup.select('.footer')
soup.find_all(True, class_ = 'footer')soup.select('p #link')
soup.find_all('p', id = 'link')soup.select('head > title')
soup.head.find_all('title')soup.select('a[href="www.baidu.com"]')
soup.find_all('a', href='www.baidu.com')
4.1 CSS选择器的语法规则
四大标签名不需要加任何修饰 [title、head、a、p]
class名前要加点
id名前要加#
举个栗子如下,在浏览器检查页面按住ctrl + f进入查找界面,输入“.article-summary”,就可以找到笑话对应的标签了
4.2 如果p标签里面有class
<p class="para">这是一个p标签</p>
如果标签内容如上所述,CSS选择器的搜索方式就是:p.class(p可以省略)
<p class="para tag">这是第二个p标签</p>
如果标签内容如上所述,CSS选择器的搜索方式就是:p.para.class(p可以省略)
<p class="para tag"><p>这是第二个p标签</p>
</p>
如果标签内容如上所述,CSS选择器的搜索方式就是:
①若是里面的p标签下还有标签,也就是里面还有子孙辈的p标签,要获取里面所有的标签(子孙)可以使用p.para.tag p
②若是里面的p标签下还有标签,也就是里面还有子孙辈的p标签,只获得第一层里面的标签(子)可以使用p.para.tag>p
4.3 如果p标签里面有id
因为id是唯一的,所以当要选择id对应的标签时候,就可以省略一切都不看,直接#xx就可以了,举个例子如下
<p class="para">这是一个p标签</p>
<p class="para tag"><p id='only_tag'>这是第二个p标签</p>
</p>
要想获得里面的id所在的标签内容,直接使用:#only_tag
4.4 在div中标签可以省略,直接通过class和id进行定位
<div class="test"><p class="para tag"><p id='only_tag'>这是第二个p标签</p></p>
</div>
比如选择最里层的标签:.test.para p(这种方式在实战解析里面也有用到)
5. 实战解析
5.1 建立for循环爬取前10页的内容
for i in range(10):html = requests.get('http://xiaohua.zol.com.cn/lengxiaohua/{}.html'.format(i+1),headers = headers)print(html.text)
这里的输出结果和上面的一样
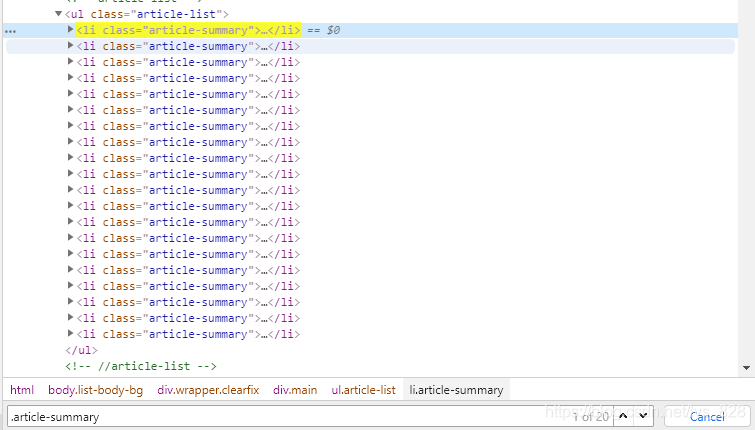
5.2 通过CSS选择器找到每条内容
这一步,上面有详细介绍,下面给图就行了
5.3 找到每条标签里面的内容并输出
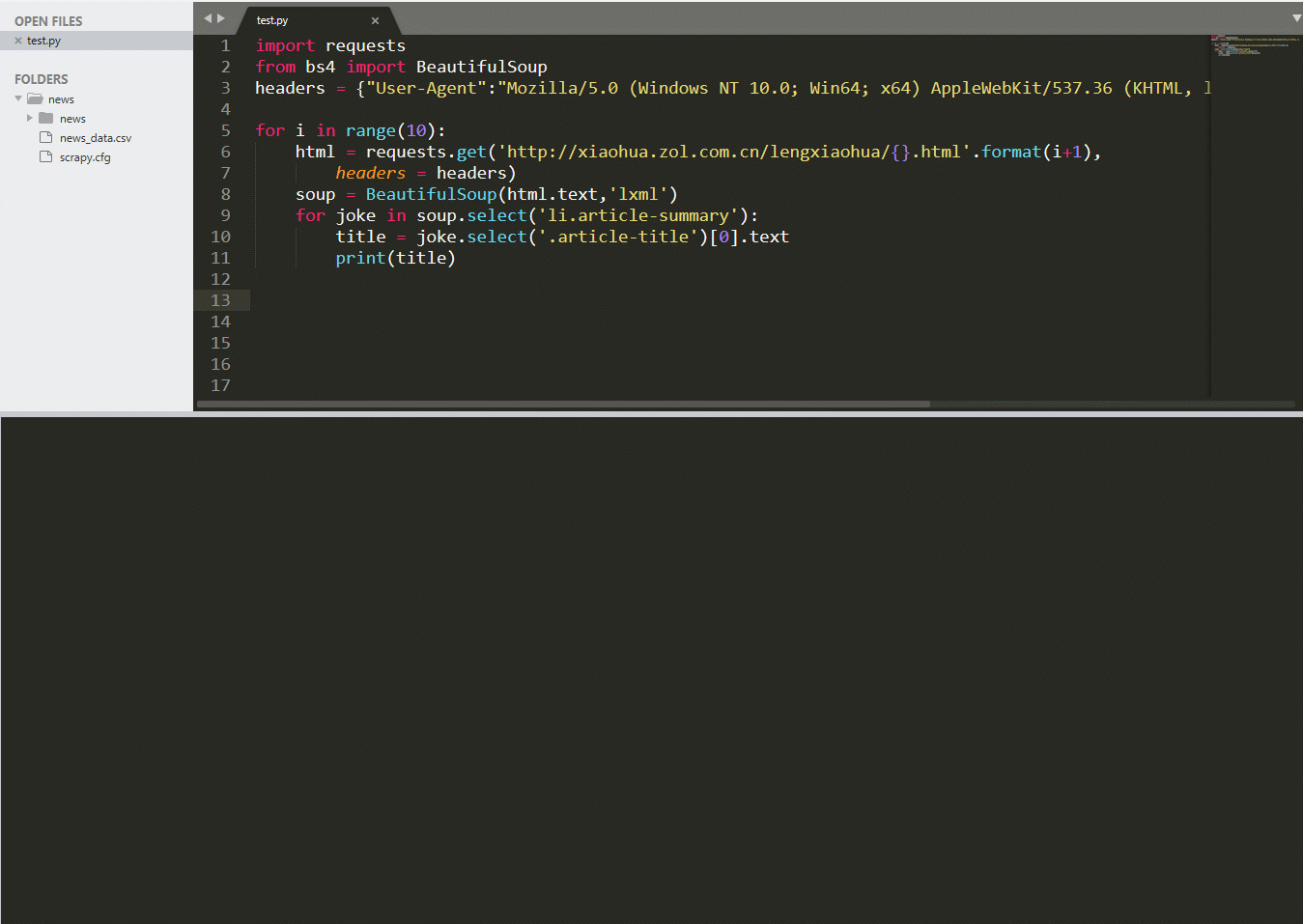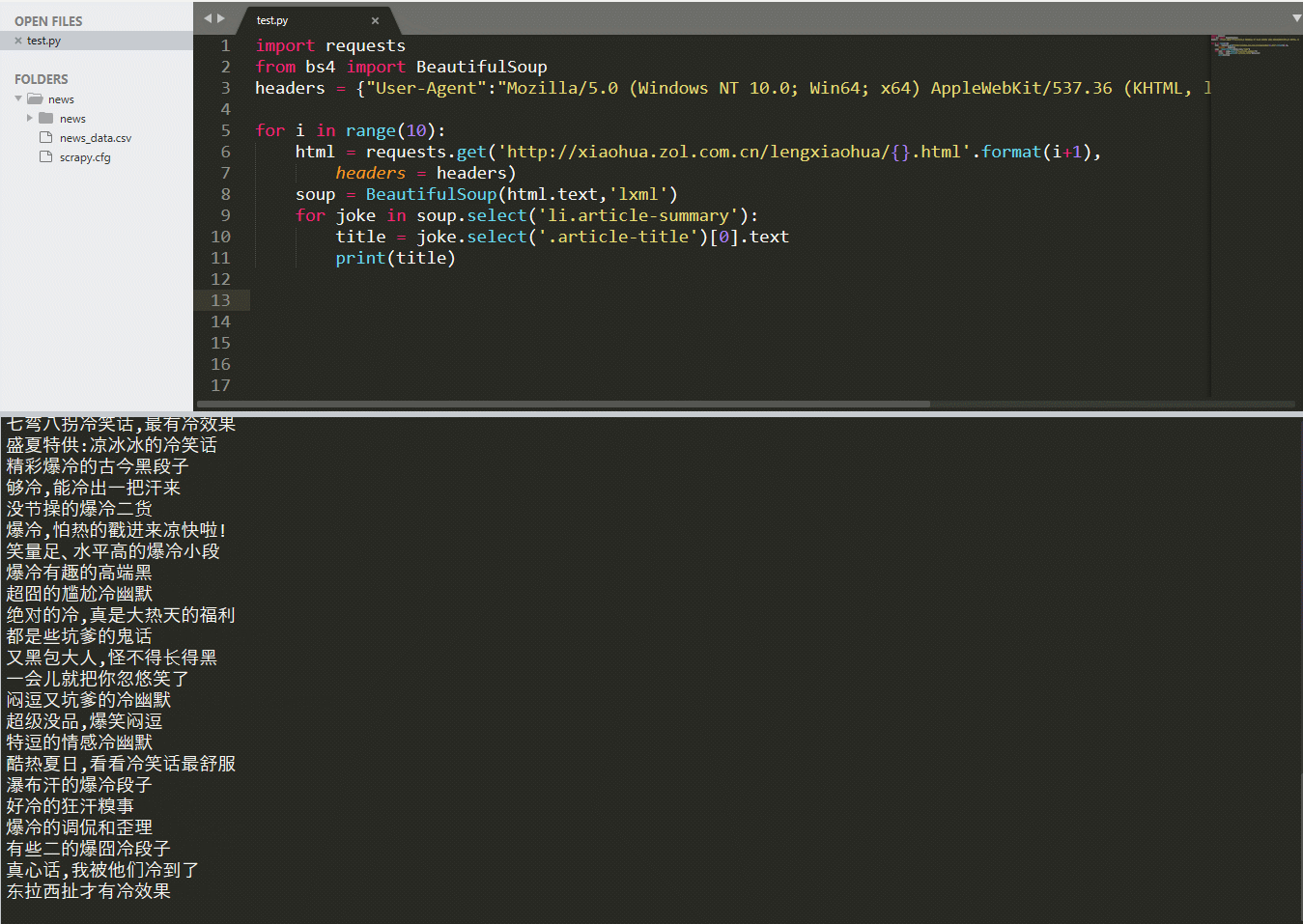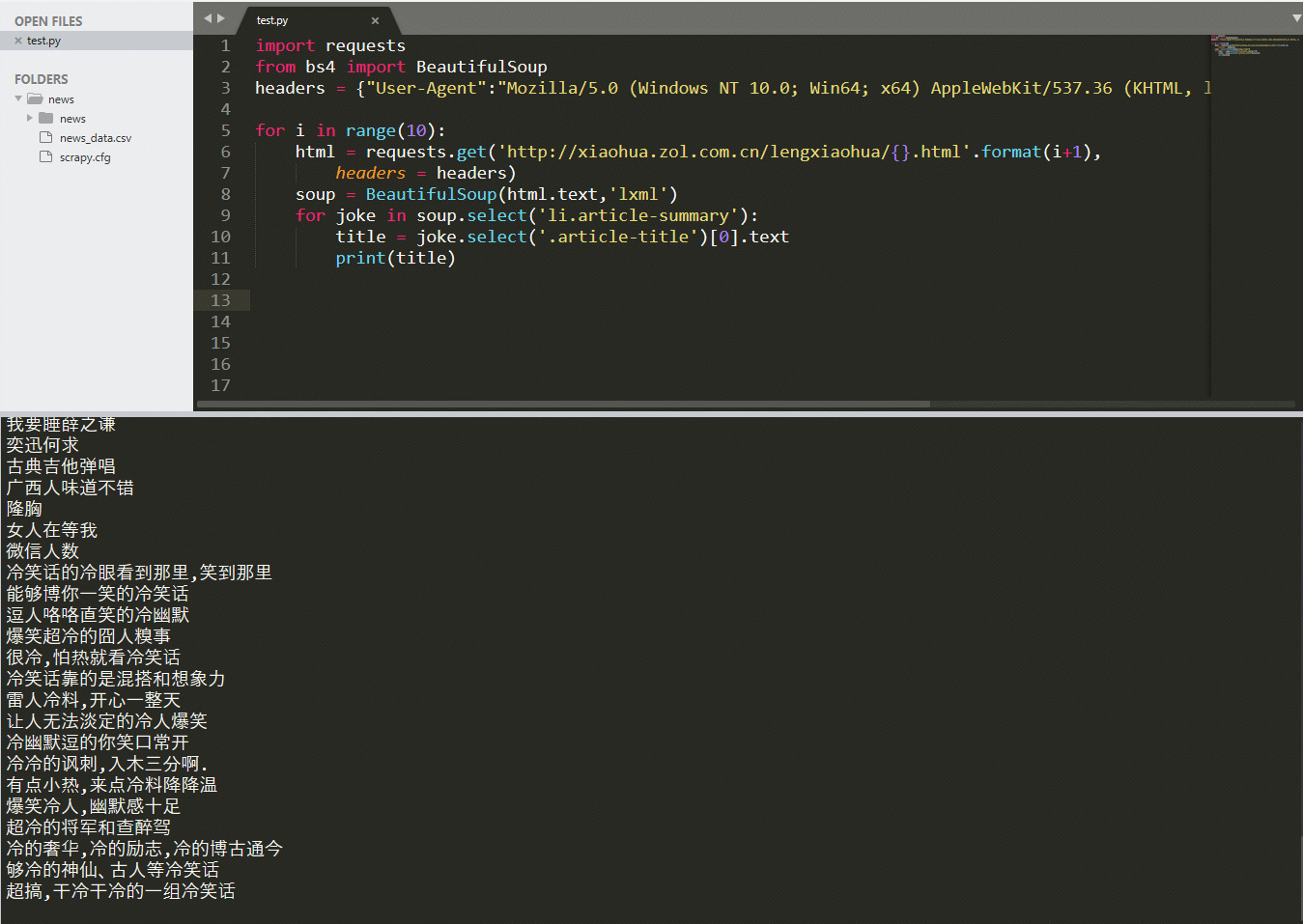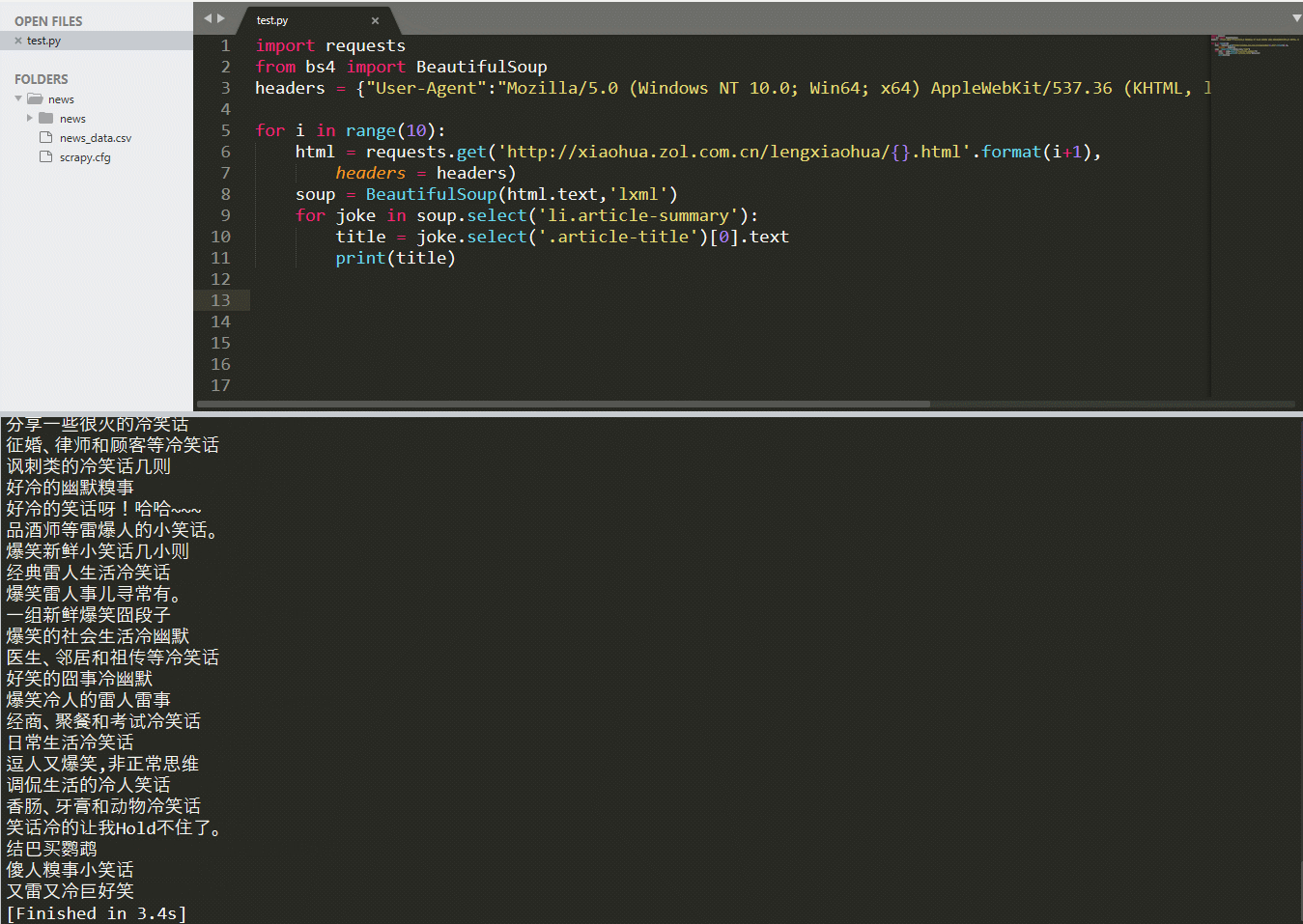
每个笑话的标题都是在.article-summary标签下的.article-title标签下面
soup = BeautifulSoup(html.text,'lxml')for joke in soup.select('li.article-summary'):title = joke.select('.article-title')[0].textprint(title)
–> 输出结果为:
6. 全部代码
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}for i in range(10):html = requests.get('http://xiaohua.zol.com.cn/lengxiaohua/{}.html'.format(i+1),headers = headers)soup = BeautifulSoup(html.text,'lxml')for joke in soup.select('li.article-summary'):title = joke.select('.article-title')[0].textprint(title)