引言
传统知识库的痛点
传统知识库广泛应用于企业文档管理、客户支持等场景,但随着信息量和复杂度的增加,存在以下显著问题:
- 数据难整合: 结构化与非结构化数据分散,更新维护成本高。
- 检索不精准: 依赖关键词匹配,难以理解语义,导致检索结果不相关或无效。
- 用户体验差: 操作繁琐、学习曲线陡峭,缺乏智能和个性化支持。
AI时代对知识库需求
在信息爆炸和数字化转型背景下,企业需要更加智能的知识库。结合AI大模型的知识库具备以下优势:
- 语义级检索: 通过语义理解,提供精准的查询结果。
- 智能交互: 支持自然语言对话,用户体验更佳。
- 自动化维护: 实现数据的自动整合与更新,降低维护成本。
在大模型的加持下,让以上问题有了新的解法,今天我们来介绍FastGPT如何利用AI大模型重新定义传统知识库。
01.
FastGPT知识库工作原理
01 FastGPT简介
FastGPT是一个基于大语言模型(LLM)的智能化平台,擅长理解和处理自然语言。它通过深度学习技术,可以从各种数据源中自动提取和整合信息,生成语义丰富的知识库,并实现智能化的响应和检索。
02 FastGPT知识库工作原理
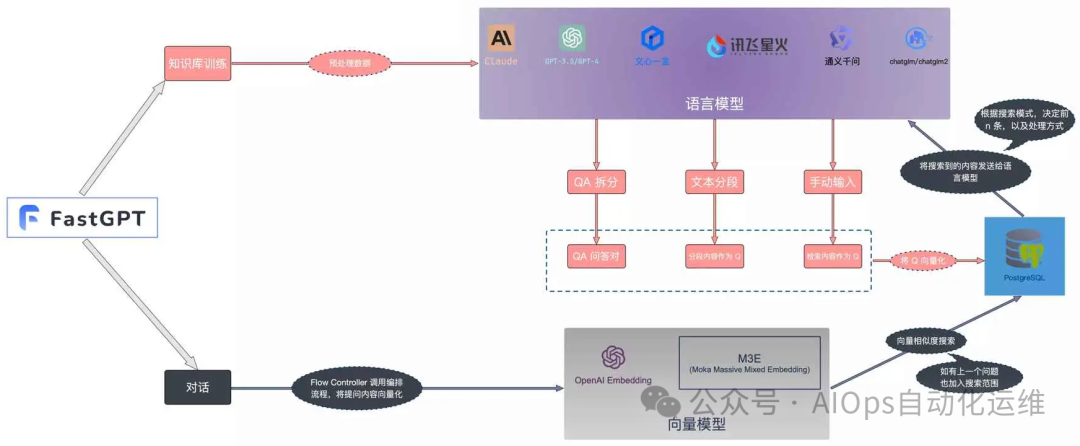
-
数据预处理:将文本拆分成更小的片段,比如:句子、段落。
-
文本向量化:利用大模型生成语义高维向量。
-
索引构建:将生成的语义向量构建成索引,通常包括向量索引和倒排索引。索引有助于快速检索相关片段,提高响应速度。
-
检索与匹配:当用户查询时,查询内容也会被向量化,并在索引中匹配相关的语义向量
-
AI对话:利用大模型的上下文理解能力,理解用户需求,生成自然回答。
02.
搭建FastGPT知识库步骤
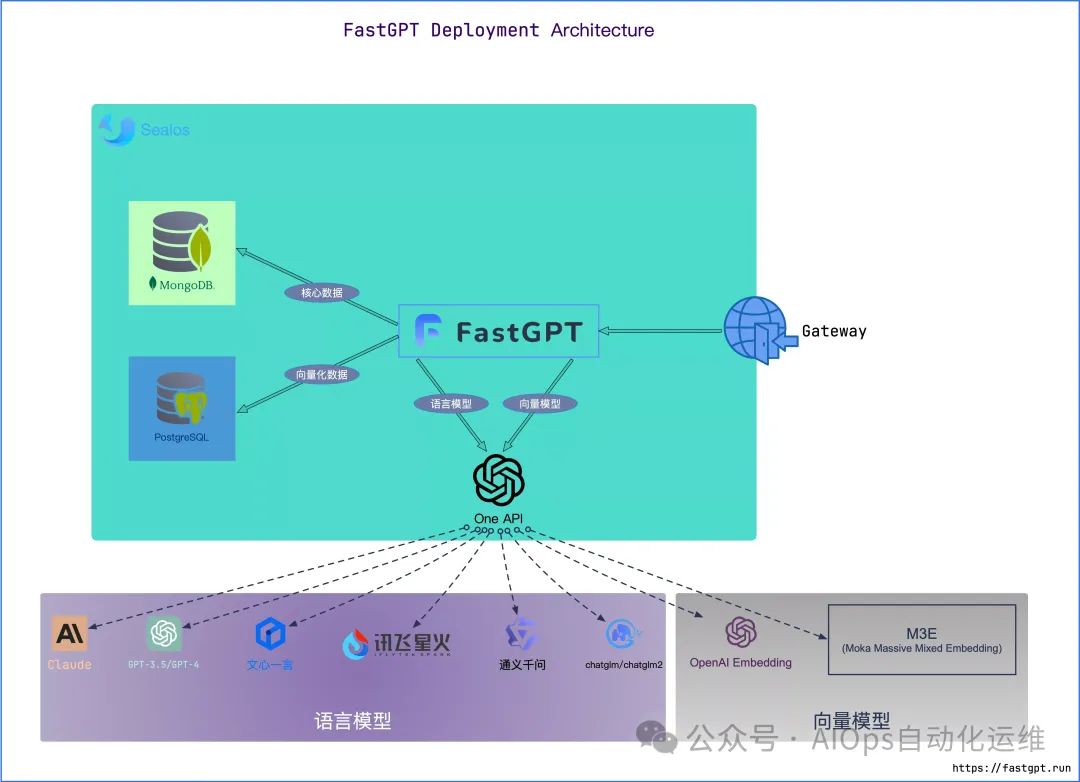
我们先来看一张FastGPT的部署架构图,主要包括FastGPT、MongoDB、PostgreSQL、OneAPI:
FastGPT有多个版本,分别为PgVector、Milvus、zilliz cloud,分别对应不同的配置要求,如下图:
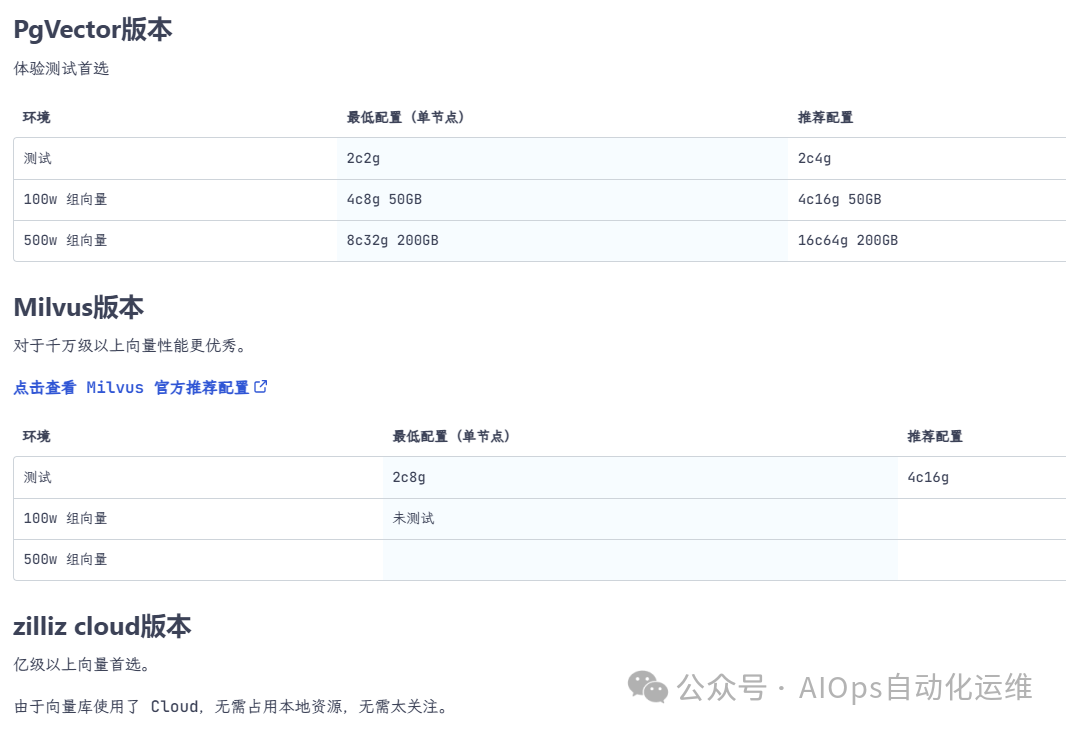
文本仅作演示,因此选择PgVector版本
前置工作
Step1 确保网络环境
如果使用OpenAI等国外模型接口,请确保可以正常访问,否则会报错:Connection error 等
Step2 准备 Docker 环境
# 安装 Docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
systemctl enable --now docker
# 安装 docker-compose
curl -L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
# 验证安装
docker -v
docker-compose -v
# 如失效,自行百度~
开始部署
Step1 下载 docker-compose.yml
所有 docker-compose.yml 配置文件中 MongoDB 为 5.x,需要用到AVX指令集,部分 CPU 不支持,需手动更改其镜像版本为 4.4.24(需要自己在docker hub下载,阿里云镜像没做备份)
Linux 快速脚本
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json# pgvector 版本(测试推荐,简单快捷)
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
# milvus 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-milvus.yml
# zilliz 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-zilliz.yml
Step2 启动容器
在 docker-compose.yml 同级目录下执行。请确保docker-compose版本最好在2.17以上,否则可能无法执行自动化命令。
# 启动容器
docker-compose up -d
# 等待10s,OneAPI第一次总是要重启几次才能连上Mysql
sleep 10
# 重启一次oneapi(由于OneAPI的默认Key有点问题,不重启的话会提示找不到渠道,临时手动重启一次解决,等待作者修复)
docker restart oneapi
Step3 打开 OneAPI 添加模型
简单说明一下OneAPI的作用和原理,这里可以把OneAPI当作一个接口网关:
- 默认情况下,FastGPT 只配置了 GPT 的模型,如果你需要接入其他模型,需要进行一些额外配置。
- One API 是一个 OpenAI 接口管理 & 分发系统,可以通过标准的 OpenAI API 格式访问所有的大模型,开箱即用。
- FastGPT 可以通过接入 One API 来实现对不同大模型的支持
通过 ip:3001 访问OneAPI,默认账号为 root 密码为 123456。
在oneapi中添加合适的AI模型渠道,如果搭建服务器可以访问openai,则可以跳过此步骤.
如果想使用国内大模型或者本地部署的模型,*下文会涉及*。
Step4 访问 FastGPT
目前可以通过 ip:3000 直接访问(注意防火墙)。登录用户名为 root,密码为docker-compose.yml环境变量里设置的 DEFAULT_ROOT_PSW。
02.
接入国产大模型
如果无法科学上网,或者想接入国产大模型,甚至知识库可能设置一些敏感数据,想接入本地大模型的,可以参考本章节,这里以接入国产大模型为例,接入本地大模型类似。
FastGPT可以统一接入不同模型的核心原理,是借助了另一个开源项目的能力:oneapi
项目地址:https://github.com/songquanpeng/one-api
Step1 打开oneapi,添加渠道
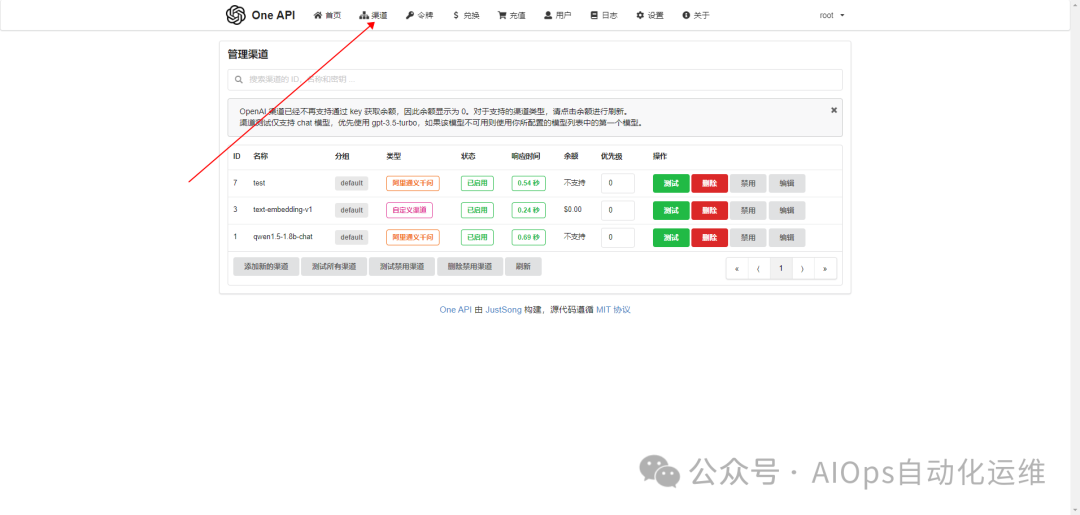
因为这里只是做演示用途,我们可以使用阿里灵积提供的免费开源大模型
模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
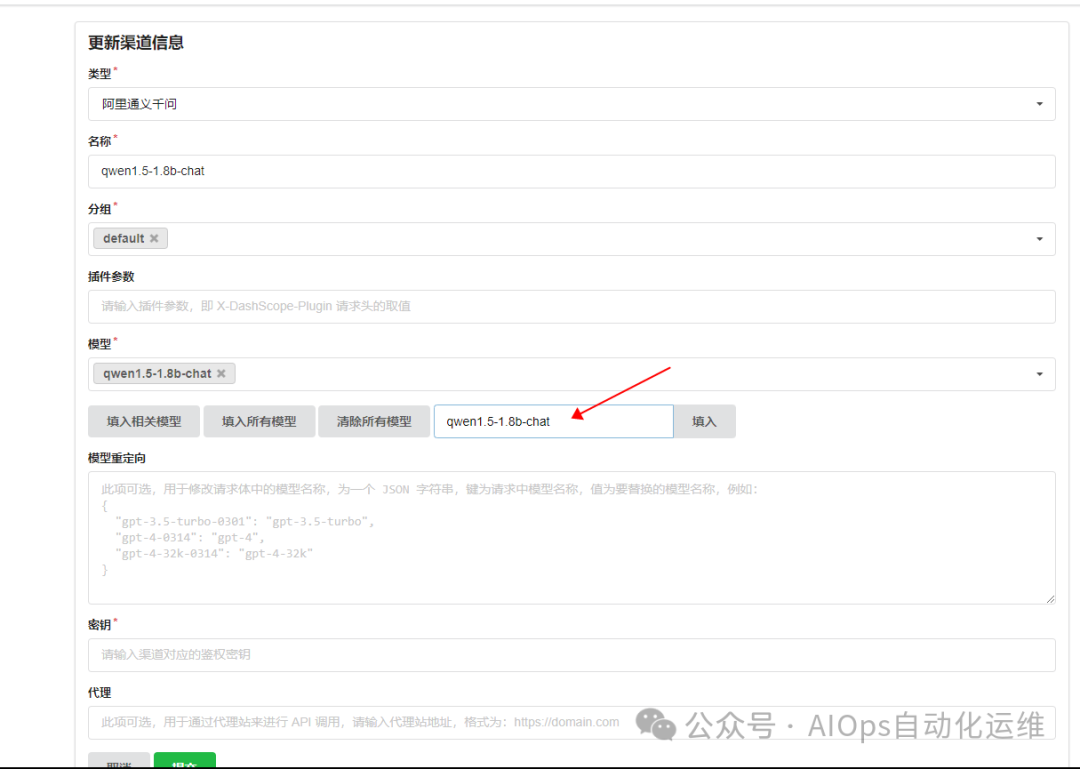
我们这里使用 qwen1.5-1.8b-chat 作为文本处理模型,text-embedding-v2 作为索引模型(文本向量)
密钥获取地址:https://dashscope.console.aliyun.com/apiKey
Step2 测试渠道
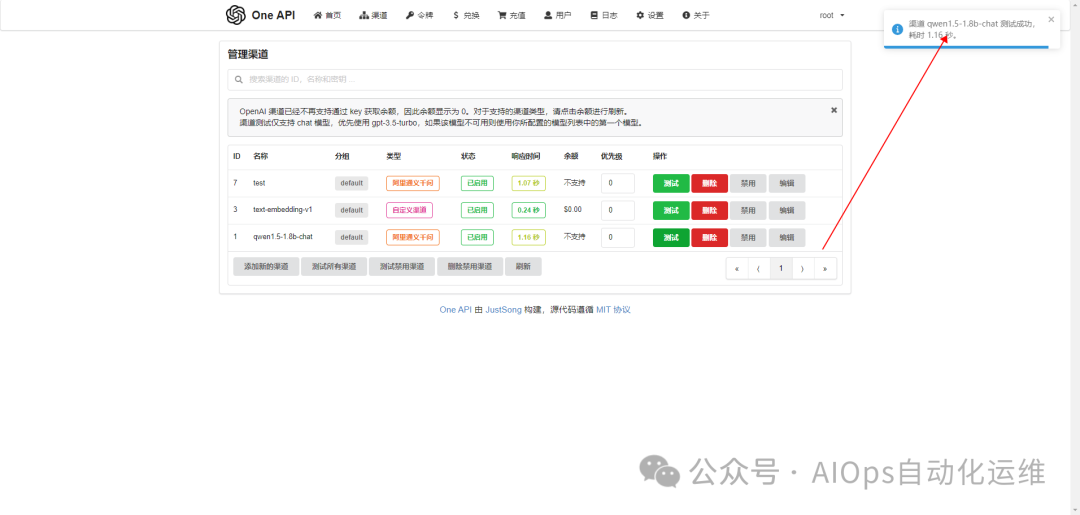
添加 text-embedding-v2 渠道方法同理
Step3 修改FastGPT配置文件
测试通过后,我们需要修改FastGPT的配置文件,然后重启FastGPT
打开 fastgpt/config.json,在llmModels下添加 qwen1.5-1.8b-chat 的配置,注意 datasetProcess 需要设置为 true,如下图所示:
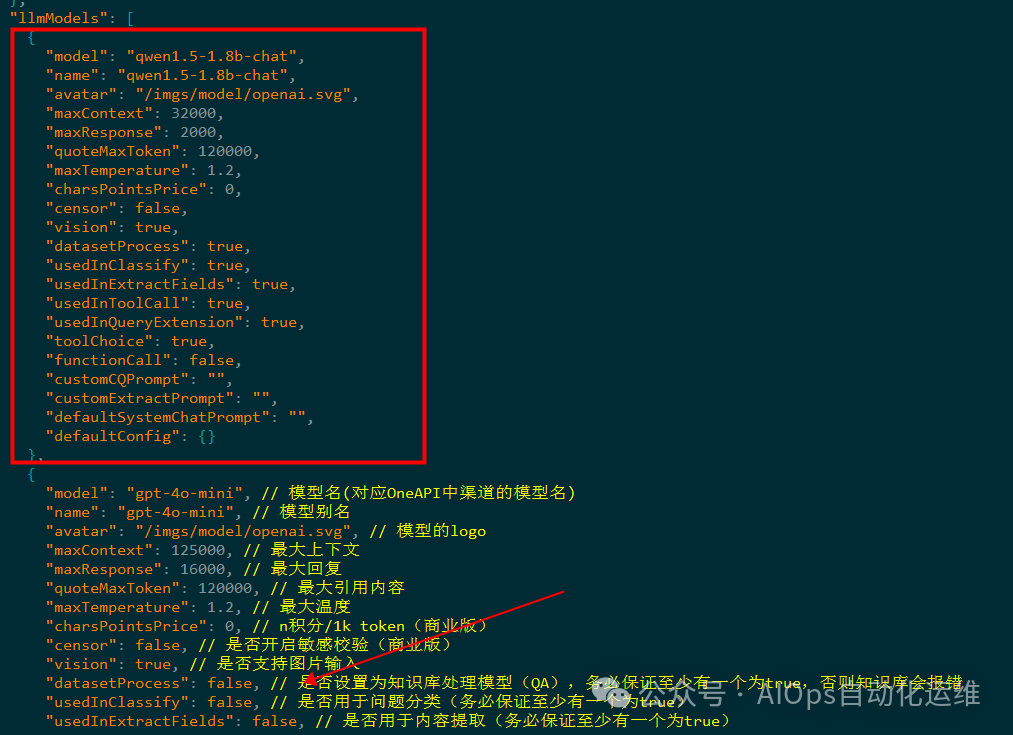

在 vectorModels 标签下添加 text-embedding-v2


重启FastGPT
docker-compose down
docker-compose up -d
Step4 创建知识库
打开FastGPT,点击左侧“知识库”,右上角点击 “创建”
选择“通用知识库”
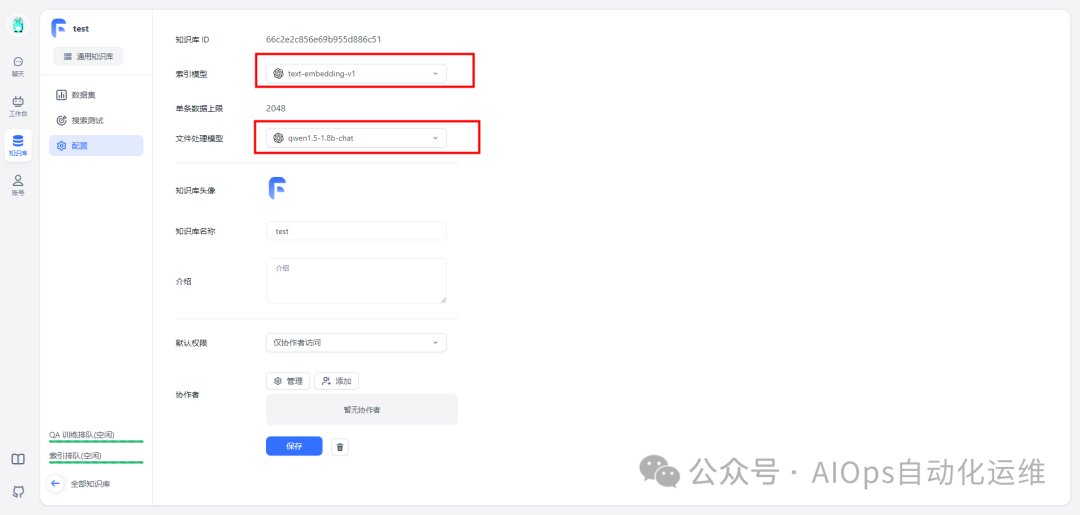
文本处理模型选择刚刚配置好的 qwen1.5-1.8b-chat,索引模型选择 text-embedding-v2
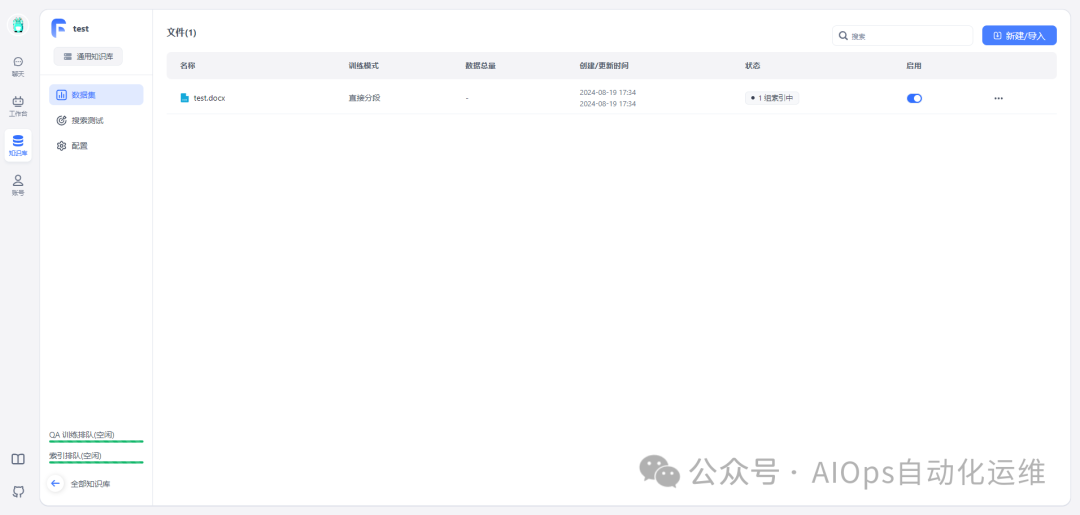
创建完成后,进入知识库,点击创建/导入,这里以导入文本数据集为例
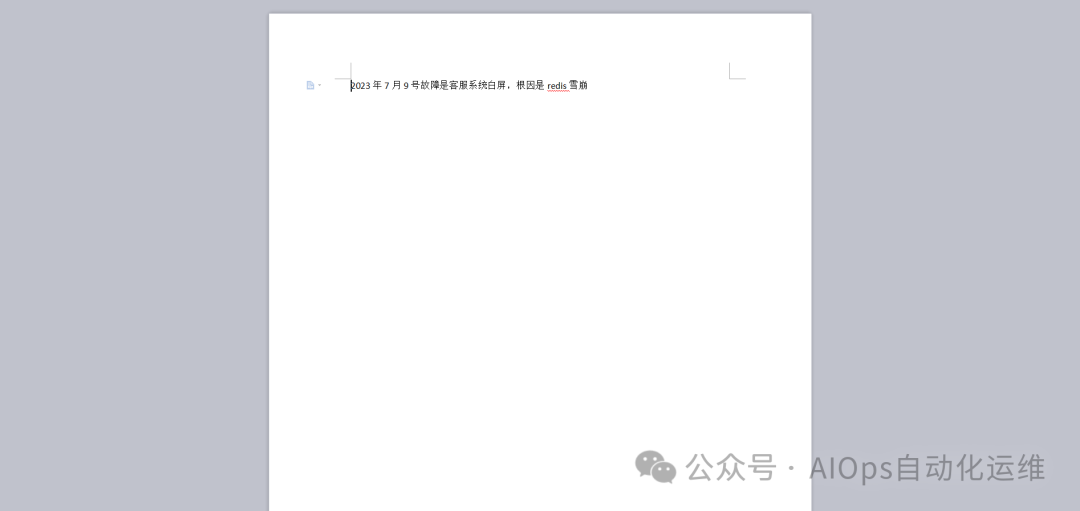
这里准备了一个docx文本数据,这里描述了发生故障的时间和根因。实际操作中,可以使用企业内部沉淀的学习资料,故障复盘等、操作手册等
导入时,选择“本地文件”
数据处理方式
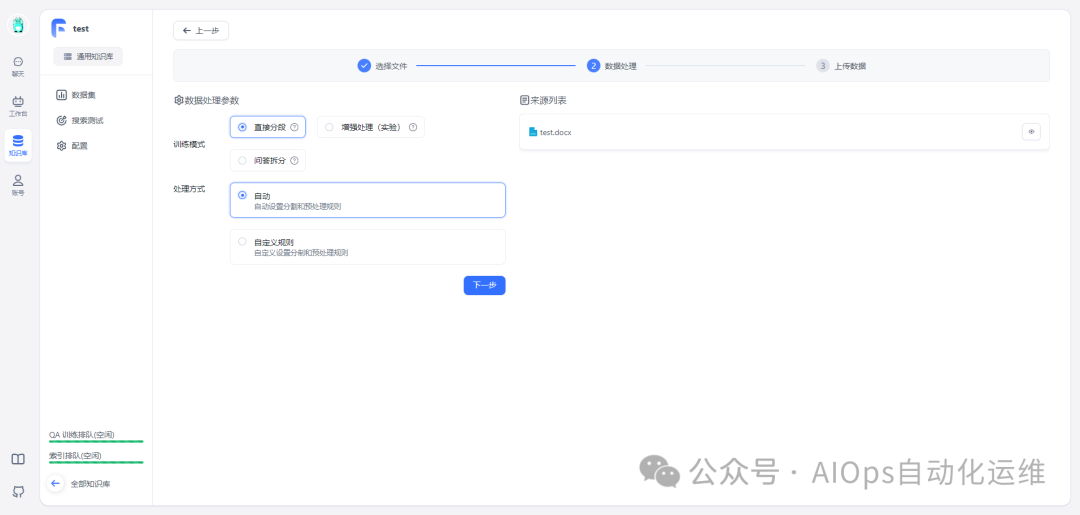
关于训练模式的选择:
- 直接分段:将文本按一定的规则进行分段处理后,转成可进行语义搜索的格式,适合绝大多数场景。不需要调用模型额外处理,成本低。
- 增强处理(实验):通过子索引以及调用模型生成相关问题与摘要,来增加数据块的语义丰富度,更利于检索。需要消耗更多的存储空间和增加 AI 调用次数。
- 问答拆分:根据一定规则,将文本拆成一段较大的段落,调用AI 为该段落生成问答对。有非常高的检索精度,但是会丢失很多内容细节。
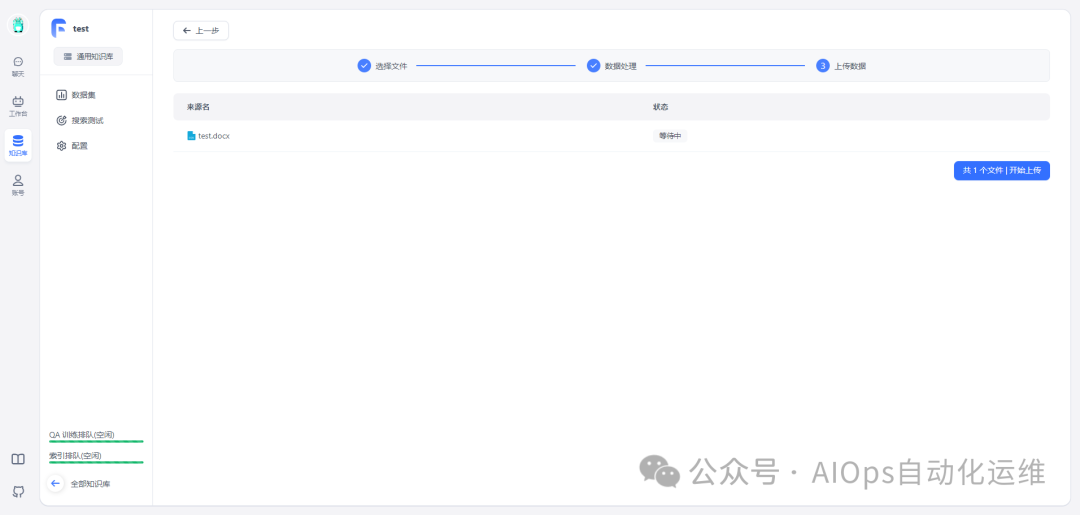
上传数据
创建应用
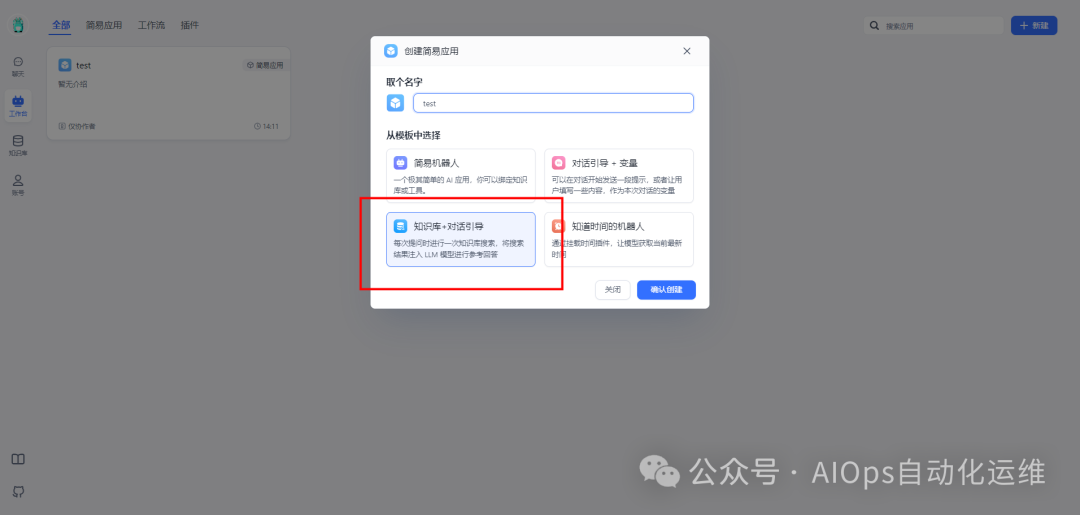
点击工作台,创建“简易应用”
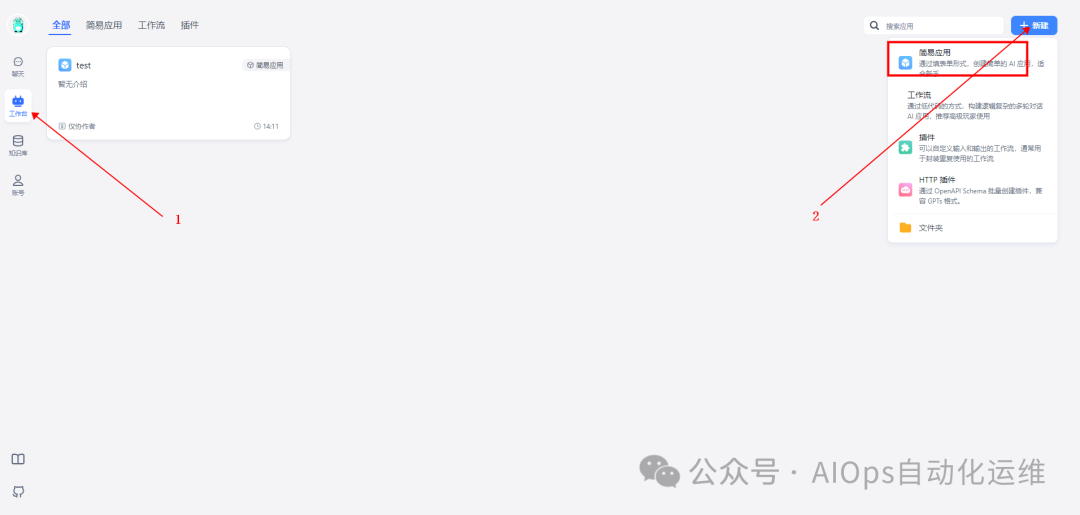
填写应用名字,选择“知识库+对话引导”
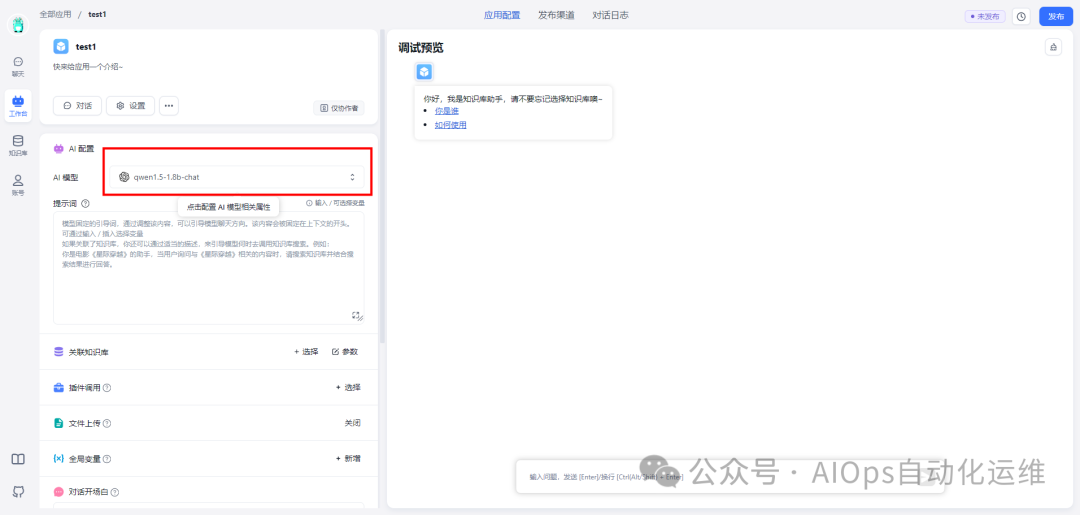
创建成功后,进入应用,修改AI模型:qwen1.5-1.8b-chat
选择AI模型
可以根据需要调整模型温度、回复上限、和聊天记录数量
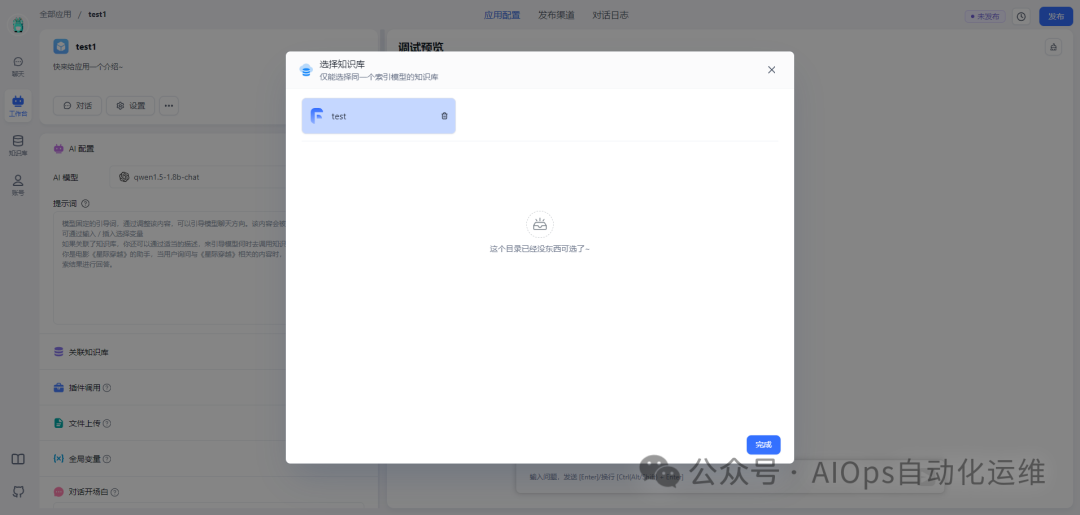
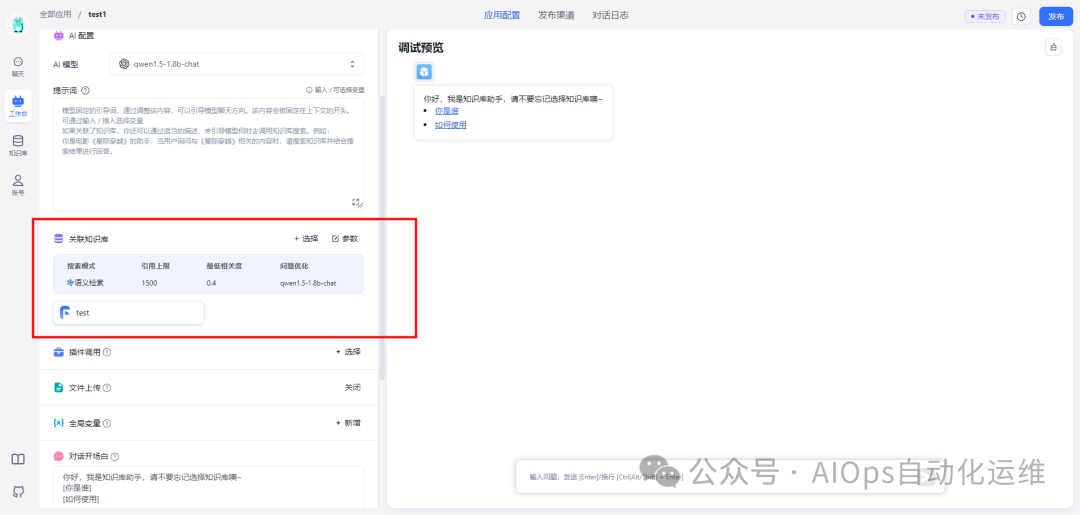
关联知识库
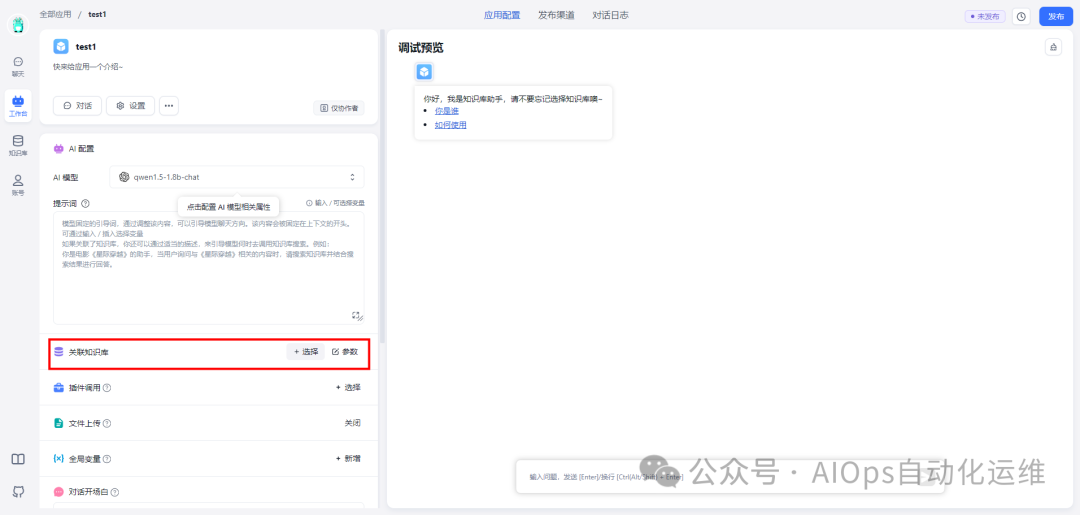
选择刚刚创建的知识库
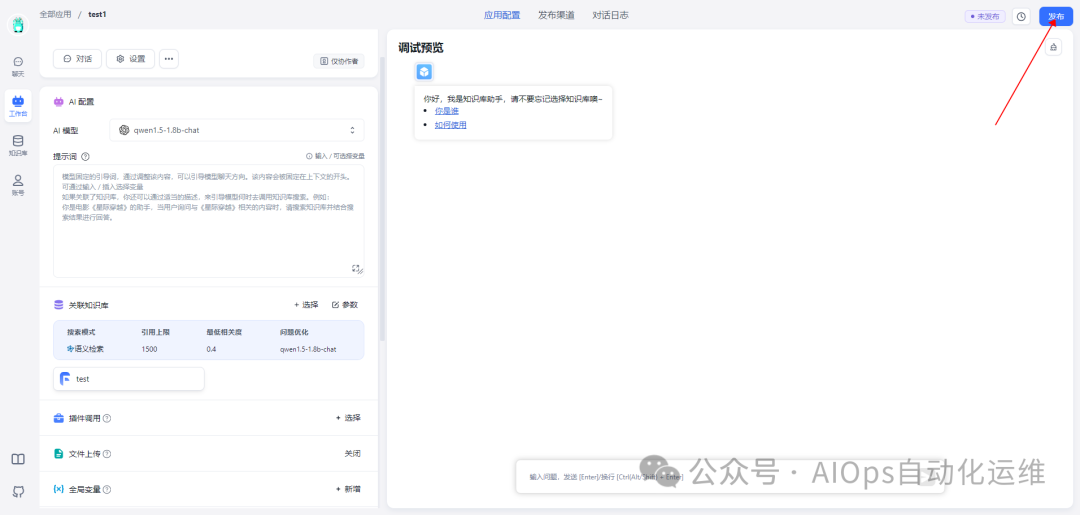
发布应用
问答测试
选择我们刚刚创建好的应用,就可以开始聊天了
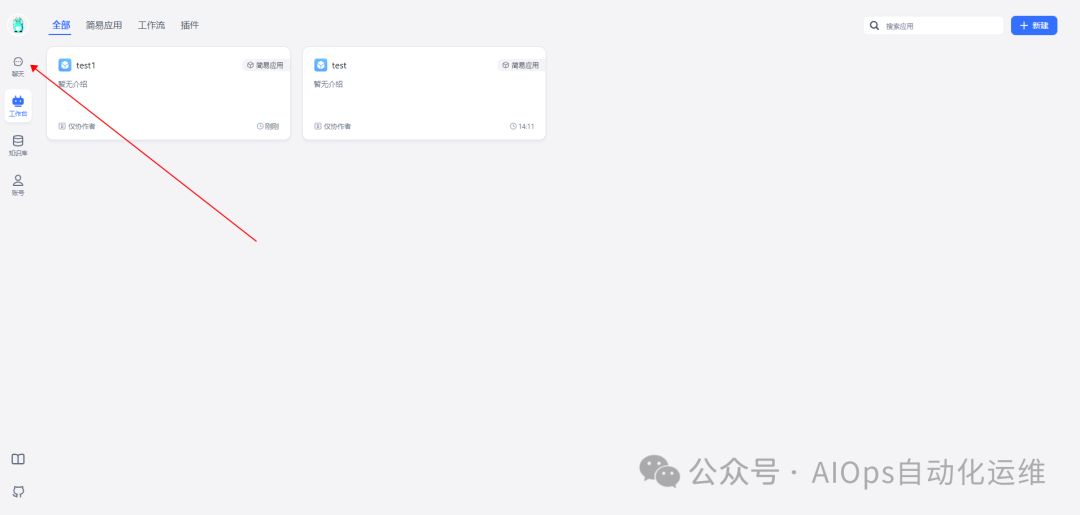
我们尝试提问某天发生了什么故障,以及根因是什么?
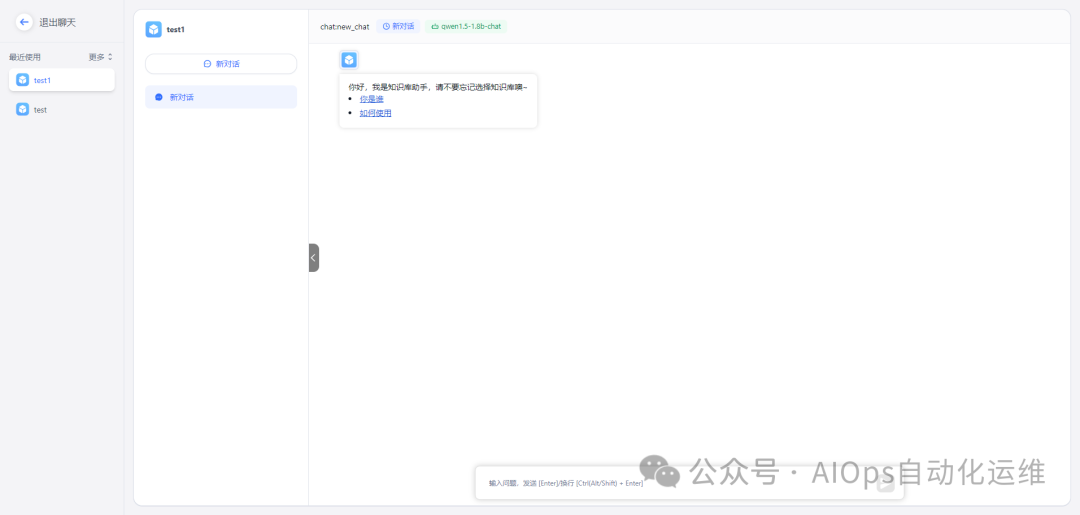
可以看出,FastGPT根据知识库给出了准确答案,根据AI进行了扩展,问答下方有标注答案应用的出处
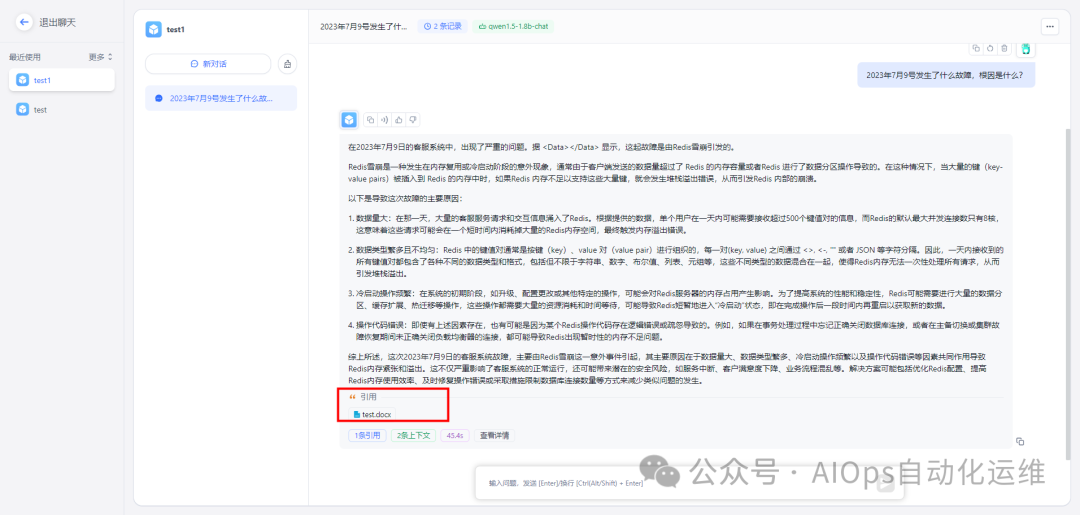
点击回答下方的查看详情,可以看到知识库的工作流程。
首先,FastGPT会根据将用户提问的问题交给向量模型做向量化,然后匹配本地知识库索引
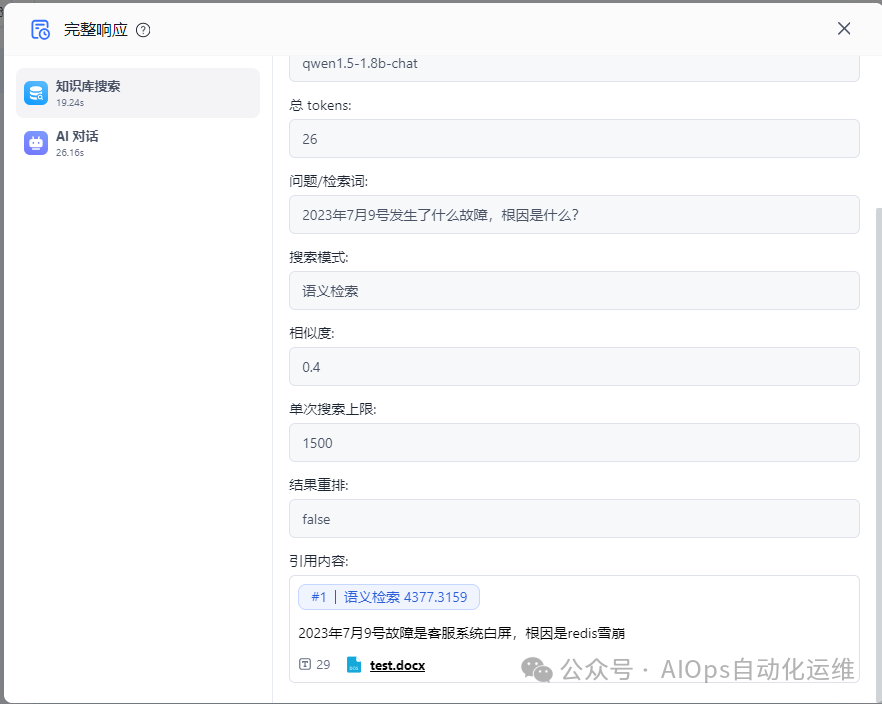
结合上下文发送给AI大模型,生成自然语言的回答。
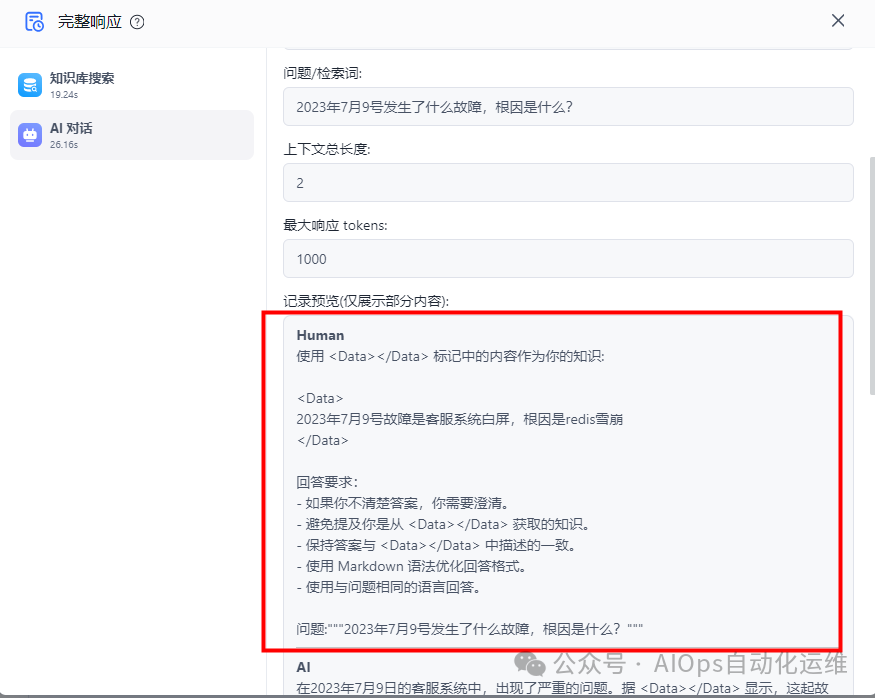
这里再简单说明下使用文本向量作为索引模型的原因:
文本向量的原理
- 什么是文本向量:可以把文本向量想象成一个由数字组成的“坐标”,用来表示一句话或一段文字。比如,假设我们把每句话都放在一张巨大的地图上,这些数字就是地图上表示它们的位置。
- 为什么要这样做:当两句话的意思很相似时,它们的“坐标”会在地图上靠得很近;如果意思差很多,坐标就会离得远。这种方式能帮助计算机理解哪些句子在说同一件事。
- 如何生成这种“坐标”:生成这些坐标的方法有很多,比如通过机器学习,让计算机“读”大量的文本,学会用数字来表达语义信息。这样一来,计算机就能理解一些复杂的语言含义,而不仅仅是词语的表面意思。
FastGPT知识库使用文本向量的原因
- 更聪明的搜索:传统的搜索只能匹配关键词,如果用户的提问和知识库中的表达方式不完全一样,可能找不到正确的答案。而用文本向量,系统可以理解提问的真正意思,即使用词不同,也能找到相关的答案。
- 应对不同的说法:人们表达同一个意思的方式可能千差万别。文本向量能让系统识别这些不同的表达,从而更好地理解用户的问题。
- 更灵活:随着知识库中的信息增加,文本向量可以帮助系统更容易地找到新知识,保持回答的准确性,而不需要频繁更新或手动调整。
总的来说,FastGPT之所以用文本向量作为索引方式,是因为它可以更智能、更灵活地理解和处理用户的提问,让系统在搜索和回答问题时更加精准。
总结
本篇文章详细介绍了如何使用FastGPT搭建向量知识库。FastGPT充分利用了大模型的自然语言处理和对话能力,大幅提高了知识搜索的精确度,同时优化了用户的使用体验。
此外,文章还阐述了FastGPT知识库的工作原理。通过将文本转换为向量来建立索引,并借助大模型的上下文理解能力,系统能够为用户生成准确且符合语境的回答。
这种方法不仅提升了信息检索的效率,还显著改善了用户与知识库的交互方式。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。