
欢迎来到雲闪世界。在本文中,我将解决数据工程师在设计流数据管道时可能遇到的关键挑战。我们将探讨用例场景,提供 Python 代码示例,讨论使用流框架的窗口计算,并分享与这些主题相关的最佳实践。
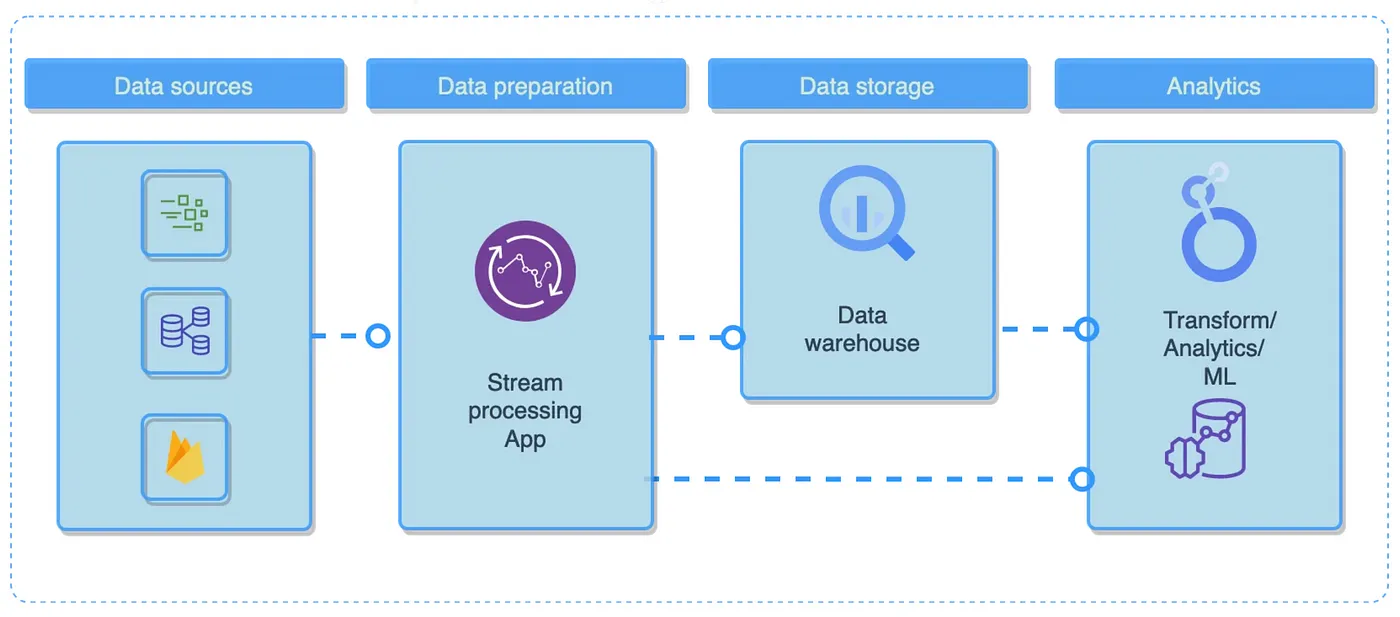
在许多应用中,访问实时且不断更新的数据至关重要。欺诈检测、客户流失预防和推荐是流式传输的最佳选择。这些数据管道实时处理来自各种来源的数据到多个目标目的地,在事件发生时捕获它们并实现其转换、丰富和分析。数据管道是一系列数据处理步骤,其中每个阶段的输出成为下一个阶段的输入,从而创建逻辑数据流。
只要在两点之间处理数据,就存在数据管道,例如从源到目标
数据管道的三个关键组成部分是源、处理步骤和目标。例如,从外部 API(源)提取的数据可以加载到数据仓库(目标)中,这说明了源和目标不同的常见情况。
在流式传输中,源通常是发布者服务,而目的地是处理数据的消费者(例如应用程序或其他端点)。这些数据通常使用窗口计算进行转换。一个很好的例子是会话窗口,由最后一个事件之后的非活动期定义(Google Analytics 4 等)。
添加图片注释,不超过 140 字(可选)
实际应用示例
考虑下面用 Python、Kafka 和 Faust 构建的简单流数据处理应用程序示例。高级应用程序逻辑如下:
-
API 服务app/app_main.py允许将有效的用户参与事件发布到 Kafkaproducer主题。这些事件可以从网站、移动应用程序收集,也可以由其他服务(例如某种数据发布者)发送。
{"event_type": "page_view","user_id": "e659e3e7-22e1-4a6b","action": "alternative_handset","timestamp": "2024-06-27T15:43:43.315342","metadata": {"session_id": "4b481fd1-9973-4498-89fb","page": "/search","item_id": "05efee91","user_agent": "Opera/8.81.(X11; Linux x86_64; hi-IN) Presto/2.9.181 Version/12.00"}
}事件验证可以由pydantic具有有效类型和操作的事件执行,并接受这些事件等。[2]
我们的应用程序不断使用来自consumer主题的已处理事件并将其发送到WebSocket,以便可以看到实时处理。
import os
import json
import logging
import asyncio
import uvicorn
from contextlib import asynccontextmanager
from fastapi import FastAPI, WebSocket, HTTPException
from fastapi.staticfiles import StaticFiles
from aiokafka import AIOKafkaConsumer, AIOKafkaProducer
from app.models import Eventfrom .http import events, users
from dotenv import load_dotenv
load_dotenv()logging.basicConfig(level=logging.INFO)# kafka_brokers = os.getenv("REDPANDA_BROKERS")
kafka_brokers = ("redpanda-0:9092"if os.getenv("RUNTIME_ENVIRONMENT") == "DOCKER"else "localhost:19092"
)
consumer_topic = os.getenv("CONSUMER_TOPIC")
producer_topic = os.getenv("PRODUCER_TOPIC")
error_topic = os.getenv("ERROR_TOPIC")def kafka_json_deserializer(serialized):return json.loads(serialized)@asynccontextmanager
async def startup(app):app.producer = AIOKafkaProducer(bootstrap_servers=[kafka_brokers],)await app.producer.start()app.consumer = AIOKafkaConsumer(consumer_topic,# "agg-events",# group_id="demo-group",# loop=loop,bootstrap_servers=[kafka_brokers],enable_auto_commit=True,auto_commit_interval_ms=1000, # commit every secondauto_offset_reset="earliest", # If committed offset not found, start from beginningvalue_deserializer=kafka_json_deserializer,)await app.consumer.start()yieldapp = FastAPI(lifespan=startup)
app.mount("/static", StaticFiles(directory="static"), name="static")app.include_router(events.router)
app.include_router(users.router)# WebSocket endpoint
@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):await websocket.accept()async def send_message_to_websocket(msg):text = str(msg.value)await websocket.send_text(text)async def consume_from_topic(topic, callback):print(f"Consuming from {topic}")async for msg in app.consumer:print(f"Received message: {msg.value}")await callback(msg)# Start consumingasyncio.create_task(consume_from_topic(consumer_topic, send_message_to_websocket))# Keep the connection openwhile True:await asyncio.sleep(3)@app.post("/track")
async def send_event_to_topic(event: Event):try:data = event.model_dump_json()data = data.encode()# # Validate the presence of required fields# We could do something like this but Pydantic will do# everything for us.# if "user_id" not in data or "action" not in data:# raise HTTPException(# status_code=422, detail="Incomplete data provided")user_id = event.user_id# Send filename to Redpandaawait app.producer.send(producer_topic, data)# Returning a confirmation messagereturn {"message": "User data submitted successfully!","user_data": {"user_id": user_id}}except HTTPException as e:# Re-raise HTTPException to return the specified# status code and detailprint(e)raise eexcept Exception as e:# Handle other unexpected exceptions and return a# 500 Internal Server Errorprint(e)raise HTTPException(status_code=500, detail=f"An error occurred: {str(e)}")if __name__ == "__main__":uvicorn.run("app.app_main:app", host="0.0.0.0", port=8000)# Run:
# uvicorn app.app_main:app --reload --host 0.0.0.0 --port 8000
# python -m app.app_main api -l info流处理服务的代码可以在下面找到。
Kafka、Kinesis、RabbitMQ 和其他流处理工具
让我们来看看过去几年中最有用的流行数据流平台和框架。
-
Apache Spark——用于大规模分析和复杂数据转换的分布式数据计算框架。
-
Apache Kafka — 一个实时数据管道工具,带有一个面向应用程序的分布式消息传递系统。它使用发布-订阅模型,生产者将数据发送到主题,消费者从这些主题中提取数据。每个主题被分成多个分区,这些分区复制到不同的服务器上,以提高可用性并平衡负载。此外,Kafka 具有内置容错功能,因此您可以设置复制因子以及每个主题所需的同步副本 (ISR) 数量。这意味着即使某些服务器发生故障,您的数据仍然可访问。
-
AWS Kinesis是一个用于分析和应用程序的实时流式传输平台。我之前在这里写过关于它的文章 [3]。
-
Google Cloud Dataflow ——Google 用于实时事件处理和分析管道的流媒体平台。
-
Apache Flink——专为低延迟数据处理而设计的分布式流数据平台。
-
RabbitMQ是一个开源消息代理,可促进应用程序之间的通信。它使用基于高级消息队列协议 (AMQP) 的队列系统,让您能够高效地发送、接收和路由消息。RabbitMQ 有助于解耦应用程序组件,使它们能够独立工作并轻松扩展。
Kafka 是我最喜欢的分布式流媒体平台之一,它允许您发布和订阅数据流、实时处理数据流并可靠地存储数据流。它是为 Java 构建的,但现在也可供 Python 开发人员使用(kafka-python))。
我喜欢它的一点是它有内置的窗口方法,可以简化会话计算。
例如,使用faust-streaming框架可以轻松实现这一点。考虑下面的代码。它演示了我们的应用程序如何为每个用户计算窗口聚合:
import os
import random
from datetime import datetime, timedelta
import faust
SINK = os.getenv("CONSUMER_TOPIC")
TOPIC = os.getenv("PRODUCER_TOPIC")BROKER = ("redpanda-0:9092"if os.getenv("RUNTIME_ENVIRONMENT") == "DOCKER"else "localhost:19092"
)TABLE = "tumbling-events"
CLEANUP_INTERVAL = 1.0
WINDOW = 10 # 10 seconds window
WINDOW_EXPIRES = 10
PARTITIONS = 1app = faust.App("event-stream", broker=f"kafka://{BROKER}")app.conf.table_cleanup_interval = CLEANUP_INTERVAL
source = app.topic(TOPIC, value_type=Event)
sink = app.topic(SINK, value_type=UserStats)@app.timer(interval=3.0, on_leader=True)
async def generate_event_data():events_topic = app.topic(TOPIC, key_type=str, value_type=Event)allowed_events = [e.value for e in AllowedEvents]allowed_actions = [e.value for e in AllowedActions]# Create a loop to send data to the Redpanda topic# Send 20 messages every time the timer is triggered (every 5 seconds)for i in range(20):# Send the data to the Redpanda topicawait events_topic.send(key=random.choice(["User1", "User2", "User3", "User4", "User5"]),value=Event(event_type=random.choice(["page_view", "scroll"]),user_id=random.choice(["User1", "User2", "User3", "User4", "User5"]), # noqa: E501action=random.choice(["action_1", "action_2"]),timestamp=datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f"),),)print("Producer is sleeping for 3 seconds 😴")def window_processor(key, events):try:timestamp = key[1][0] # key[1] is the tuple (ts, ts + window)print(f'key:: {key}')users = [event.user_id for event in events]count = len(users)user_counter = Counter(event.user_id for event in events)for i, (user, count) in enumerate(user_counter.items()):print(f"{i}. {user}: {count}")aggregated_event = UserStats(timestamp=timestamp, user_id=user, count=count)print(f"Processing window: {len(users)} events, Aggreged results: {aggregated_event}" # noqa: E501)sink.send_soon(value=aggregated_event)except Exception as e:print(e)tumbling_table = (app.Table(TABLE,default=list,key_type=str,value_type=Event,partitions=PARTITIONS,on_window_close=window_processor,).tumbling(WINDOW, expires=timedelta(seconds=WINDOW_EXPIRES)).relative_to_field(Event.timestamp)
)@app.agent(app.topic(TOPIC, key_type=str, value_type=Event))
async def calculate_tumbling_events(events):async for event in events:value_list = tumbling_table["events"].value()value_list.append(event)tumbling_table["events"] = value_listif __name__ == "__main__":app.main()现在在命令行中输入此命令来启动我们的蒸汽模块:
faust -流光.event_stream worker -l info
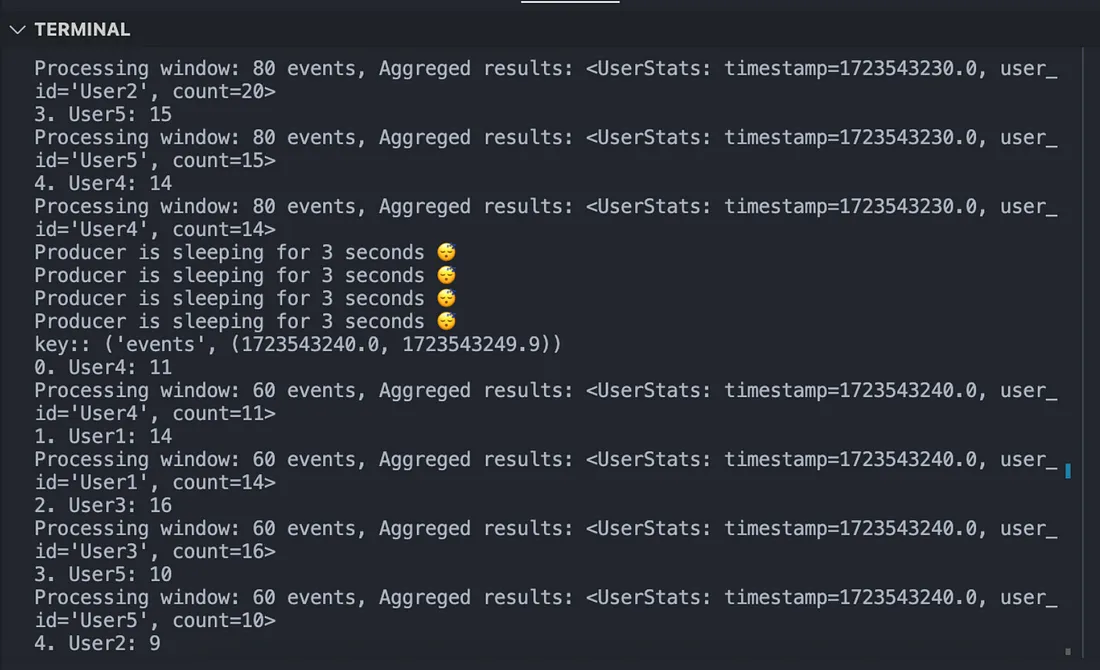
因此,我们应该看到实时发生的事件聚合:
添加图片注释,不超过 140 字(可选)
选择正确的 Python 客户端
一些流行的 Kafka Python 客户端包括confluent-kafka、pykafka和kafka-python。
confluent-kafka是高性能librdkafka C 库的 Python 包装器,提供完整的 Kafka 功能支持以及 AVRO 序列化和架构注册表集成等附加功能。它包括高级和低级 API,可提高 Kafka 应用程序的灵活性和控制力。
每个 Python 库都有其优点和缺点。
对于初级从业者来说,易用性非常重要。这包括文档、代码可读性、API 设计和错误处理。Pykafka通常被认为是最简单的,具有清晰的 API、良好的文档和用户友好的错误消息。相反,kafka-python和confluent-kafka-python往往不那么简单,具有更复杂的 API、不太全面的文档和不太清晰的错误消息。
另一方面,confluent-kafka-python和kafka-python提供最全面的Kafka 功能支持,涵盖所有 Kafka 功能,并提供高级和低级 API。相比之下,pykafka功能支持有限,仅提供高级 API。通常,由于基于优化的C 库,因此性能confluent-kafka-python最佳,而和性能较低,因为它们是纯 Python 实现,开销较大。librdkafkakafka-pythonpykafka
您可以kafka-python使用 pip 安装:pip install kafka-python我们的应用程序文件如下所示:
# app.pyfrom kafka import KafkaProducer, KafkaConsumerimport json
producer = KafkaProducer(bootstrap_servers=['brokerA:9092', 'brokerB:9092'],key_serializer=lambda k: json.dumps(k).encode(),value_serializer=lambda v: json.dumps(v).encode())# Send data to Kafka topic 'my_topic'
future = producer.send('my_topic', key='hello', value='world')
try:result = future.get(timeout=10)print(result)
except Exception as e:print(e)要使用主题中的数据,我们需要使用poll方法。它将返回包含 JSON 记录的主题分区列表:
import json
consumer = KafkaConsumer(bootstrap_servers=['brokerA:9092', 'brokerB:9092'],group_id='my-group',topics=['my_topic'],key_deserializer=lambda k: json.loads(k.decode()),value_deserializer=lambda v: json.loads(v.decode()),auto_offset_reset='earliest',enable_auto_commit=True,max_poll_records=10)for record in consumer:print(record.key, record.value)Kafka 最佳实践
那么我们如何提高 Kafka 应用程序的可靠性和性能?
目前尚无通用的解决方案来优化 Kafka 应用程序
我们的 Kafka 应用程序的性能和可靠性可能受到各种因素的影响,其中包括:
-
生产者和消费者的配置和数量,
-
消息大小和频率,
-
网络带宽和延迟,
-
硬件和软件资源,
-
潜在的故障场景。
通常,这些是容错和性能设计的一般建议:
使用复制:复制会在代理之间创建多个数据副本,确保故障期间的可访问性并通过负载平衡提高性能。但是,这可能会导致磁盘使用率和网络流量增加。根据您的可用性和一致性要求设置复制因子和同步副本 (ISR) 的数量。
启用批处理:批处理将多条消息分组为单个请求,从而减少网络开销并提高吞吐量。它还可以提高压缩效率。在生产者和消费者上启用批处理,调整批处理大小和停留时间以满足您的延迟和吞吐量目标。
明智地进行分区:每个主题的分区数会影响可扩展性、并行性和性能。分区越多,生产者和消费者的容量就越大,从而有效地在代理之间分配负载。但是,分区过多会增加网络流量。因此,请根据预期的吞吐量和延迟来选择分区数。
启用压缩:压缩可减少消息大小。就这么简单。它可以减少磁盘空间使用量并发送数据传输。虽然处理时会产生一些 CPU 开销,但选择压缩算法和级别也被认为是最佳做法。
错误处理
Python Kafka 客户端提供了一系列用于管理错误和异常的方法和选项,包括:
-
错误处理策略:策略涉及重试、忽略或快速失败错误。数据工程师可以确定如何解决不同类型的错误,同时确保可靠性和数据一致性。例如,生产者可以使用诸如max_in_flight_requests_per_connectio和之类的参数。在消费者中,我们可以使用诸如、retries和之类的参数。retry_backoff_mskafka-pythonconfluent-kafka-pythonenable.auto.commitauto.commit.interval.msenable.auto.offset.store
-
异常处理:、和块可用于处理各种异常类型并执行清理或恢复程序。标准 Python 异常处理try。例如,和客户端中有一个类。在客户端中我们有类。exceptfinallyKafkaErrorkafka-pythonconfluent-kafka-pythonpykafkaPyKafkaException
-
错误回调:当我们需要记录错误、引发异常或实施恢复操作时,回调非常有用。回调函数可以分配给生产者和消费者的构造函数,每当客户端级别发生错误或异常时都会触发。例如,参数error_cb可用于kafka-python和confluent-kafka-python客户端,而on_error参数用于pykafka客户端。
例如,最常见的错误处理模式之一是死信队列。来自源主题的事件可以分为两个不同的路径:
-
如果一切正常,应用程序将成功处理源主题中的每个事件并将其发布到目标主题(接收器)。
-
无法处理的事件(例如缺少预期格式或缺少必需属性的事件)将被定向到错误主题。
另一种有用的错误处理模式是实现重试队列。例如,如果项目的参数当时不可用,事件可以路由到重试主题。例如,如果此功能正在由另一项服务处理,并且在请求时不可用,则可能会发生这种情况。
这种可恢复的情况不应归类为错误
相反,应该定期重试,直到满足所需条件。引入重试主题可以立即处理大多数事件,同时推迟处理某些事件,直到满足必要条件。
结论
流式传输技术(滚动和跳跃窗口、会话等)与 Python 相结合是一种多功能解决方案。Kafka 等工具可帮助数据工程师创建流式传输应用程序,以支持实时分析、消息传递和事件驱动系统。例如,Kafka 的主要优势包括高吞吐量和可扩展性,这使其功能极其强大。Kafka通过使用批量写入和读取、减少磁盘 I/O 和网络开销以及利用数据压缩,每秒处理数百万条消息,延迟低。它可以通过添加代理进行水平扩展,也可以通过增加分区和副本进行垂直扩展。它支持消费者群体有效地分配工作负载。Kafka 通过领导者-追随者模型(追随者复制数据)确保即使在发生故障时也能提供数据可用性。如果领导者发生故障,追随者将接管,并且 Kafka 的提交日志允许持久且可重放的数据存储。
选择正确的 Python 库是第一步。如果性能指标(如吞吐量、延迟、CPU 使用率和内存消耗)对您来说最重要,那么就选择confluent-kafka-python。如果您追求简单,那么pykafka或kafka-python将是更好的解决方案。
充分的错误处理和以最大化延迟、吞吐量和可用性的方式设计我们的流式应用程序是另一件需要考虑的事情。我希望遵循本文中的提示可以帮助您正确配置 Kafka 集群并启用复制、分区、批处理和压缩的最佳设置。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
订阅频道(https://t.me/awsgoogvps_Host) TG交流群(t.me/awsgoogvpsHost)






