简介:gdao是一种创新的持久层解决方案。主要目的在于 减少编程量,提高生产力,提高性能,支持多数据源整合操作,支持数据读写分离,制定持久层编程规范。 灵活运用gdao,可以在持久层设计上,减少30%甚至50%以上的编程量,同时形成持久层的统一编程规范,减少持久层错误,同时易于维护和扩展。
gdao对于go语言,相当于 hibernate+ mybatis 对于java语言,gdao框架融合了Hibernate的抽象性和MyBatis的灵活性,并解决了它们各自在ORM框架上长久以来使用上的痛点。关于hibernate与mybatis在痛点问题,可以参考 jdao使用文档
gdao设计结构简洁且严谨,所有接口与函数均能见名知意。即使从未接触过gdao,看到gdao持久层代码,也能马上知道它的代码表达的意思和相关的数据行为。你可以在几分钟内,掌握它的用法,这是它的简洁性与设计规范性带来的优势。
- Github
- 使用文档
- Demo
- 官网
核心优势
- 融合精髓:Gdao融合了Hibernate的抽象性和MyBatis的灵活性,同时解决了两者在ORM框架使用中的长期痛点。
- 设计优雅:框架设计简洁严谨,接口与函数命名直观易懂,即便是初学者也能快速上手。
- 高效生成:内置代码生成工具,一键生成数据库表的标准化实体类,类似Thrift/Protobuf,提升开发效率。
- 性能卓越:支持高效序列化与反序列化,确保数据处理速度更快,体积更小。
- 读写分离:支持多数据源绑定及数据读写分离,满足复杂业务场景需求。
- 数据缓存:GDAO内置缓存机制,允许对缓存数据的有效期和回收策略进行精细控制。
- 广泛兼容:理论上支持所有实现Go数据库驱动接口的数据库,轻松对接多种数据源。
- 高级特性:支持事务、存储过程、批处理等高级数据库操作,满足各种复杂业务需求。
- SQL分离:类似MyBatis,支持SQL与程序分离,通过XML文件配置SQL映射,提升代码清晰度与维护性。
GDAO的设计理念
Gdao是Jdao的功能等价框架,设计模式来自Jdao。
- 标准化映射实体类,处理单表CRUD操作:90%以上的数据库单表操作,可用通过实体类操作完成。这些对单表的增删改查操作,一般不涉及复杂的SQL优化,由实体类封装生成,可以减少错误率,更易于维护。 利用缓存,读写分离等机制,在优化持久层上,更为高效和方便 标准化实体类的数据操作格式并非简单的对象函数拼接,而是更类似SQL操作的对象化,使得操作上更加易于理解。
- 复杂SQL的执行:在实践中发现,复杂SQL,特别是多表关联的SQL,通常需要优化,这需要对表结构,表索引性质等数据库属性有所了解。 而将复杂SQL使用对象进行拼接,通常会增加理解上的难度。甚至,开发者都不知道对象拼接后的最终执行SQL是什么,这无疑增加了风险和维护难度。 因此Gdao在复杂SQL问题上,建议调用Gdao的CURD接口执行,Gdao提供了灵活的数据转换和高效的对象映射实现,可以避免过渡使用反射等耗时的操作。
- Sql映射文件: 对于复杂的sql操作,Gdao提供了相应的crud接口。同时也支持通过xml配置sql进行接口映射调用,这点与java的mybatis Orm框架相似,区别在于mybatis需要映射所有SQL操作, 而Gdao虽然提供了完整的sql映射接口,但是建议只映射复杂SQL,或操作部分标准实体类无法完成的CURD操作。 Gdao的SQL配置文件参考java orm框架mybatis配置文件格式,并实现go语言的解析器,使得配置参数在类型的容忍度上更高,更灵活。
核心组件
- gdao:核心入口,负责数据源设置与SQL CRUD操作。
- gdaoCache:缓存管理,支持缓存绑定与移除,优化查询性能。
- gdaoSlave:读写分离控制,灵活管理数据源读写策略。
- gdaoMapper:SQL执行器,支持直接调用CRUD接口或通过XML映射文件执行复杂SQL。
快速入门
1. 安装
# gdao 导入
go get github.com/donnie4w/gdao2. 配置数据源
gdao.Init(mysqlDB,gdao.MYSQL)
// mysqlDB 为数据源
// gdao.MYSQL 为数据库类型3. 生成表实体类
- 使用 Gdao 代码生成工具生成数据库表的标准化实体类。
4. 实体类操作
// 数据源设置
gdao.init(mysqlDB,gdao.MYSQL)// 读取
hs := dao.NewHstest()
hs.Where(hs.Id.EQ(10))
h, _ := hs.Select(hs.Id, hs.Value, hs.Rowname)
logger.Debug(h)
//[DEBUG][SELETE ONE][ select id,value,rowname from hstest where id=?][10] // 更新
hs := dao.NewHstest()
hs.SetRowname("hello10")
hs.Where(hs.Id.EQ(10))
hs.Update()
//[DEBUG][UPDATE][update hstest set rowname=? where id=?][hello10 10]// 删除
hs := dao.NewHstest()
hs.Where(hs.Id.EQ(10))
t.delete()
//[DEBUG][UPDATE][delete from hstest where id=?][10]//新增
hs := dao.NewHstest()
hs.SetValue("hello123")
hs.SetLevel(12345)
hs.SetBody([]byte("hello"))
hs.SetRowname("hello1234")
hs.SetUpdatetime(time.Now())
hs.SetFloa(123456)
hs.SetAge(123)
hs.Insert()
//[DEBUG][INSERT][insert into hstest(floa,age,value,level,body,rowname,updatetime )values(?,?,?,?,?,?,?)][123456 123 hello123 12345 [104 101 108 108 111] hello1234 2024-07-17 19:36:44]5. gdao api
- CRUD操作
//查询,返回单条
bean, _ := gdao.ExecuteQueryBean("select id,value,rowname from hstest where id=?", 10)
logger.Debug(bean)//insert
int i = gdao.ExecuteUpdate("insert into hstest2(rowname,value) values(?,?)", "helloWorld", "123456789");//update
int i = gdao.ExecuteUpdate("update hstest set value=? where id=1", "hello");//delete
int i = gdao.ExecuteUpdate("delete from hstest where id = ?", 1);6. gdaoCache 缓存
- 配置缓存
//绑定Hstest 启用缓存, 缓存时效为 300秒
gdaoCache.BindClass[dao.Hstest]()//Hstest 第一次查询,并根据条件设置数据缓存
hs := dao.NewHstest()
hs.Where((hs.Id.Between(0, 2)).Or(hs.Id.Between(10, 15)))
hs.Limit(3)
hs.Selects()//相同条件,数据直接由缓存获取
hs = dao.NewHstest()
hs.Where((hs.Id.Between(0, 2)).Or(hs.Id.Between(10, 15)))
hs.Limit(3)
hs.Selects()执行结果
[DEBUG][SELETE LIST][ select id,age,rowname,value,updatetime,body,floa,level from hstest where id between ? and ? or (id between ? and ?) LIMIT ? ][0 2 10 15 3]
[DEBUG][SET CACHE][ select id,age,rowname,value,updatetime,body,floa,level from hstest where id between ? and ? or (id between ? and ?) LIMIT ? ][0 2 10 15 3]
[DEBUG][SELETE LIST][ select id,age,rowname,value,updatetime,body,floa,level from hstest where id between ? and ? or (id between ? and ?) LIMIT ? ][0 2 10 15 3]
[DEBUG][GET CACHE][ select id,age,rowname,value,updatetime,body,floa,level from hstest where id between ? and ? or (id between ? and ?) LIMIT ? ][0 2 10 15 3]7. gdaoSlave 读写分离
- 读写分离
设置备库数据源:mysql
mysql, _ := getDataSource("mysql.json")
gdaoSlave.BindClass[dao.Hstest](mysql, gdao.MYSQL)
//这里主数据库为sqlite,备数据库为mysql,Hstest读取数据源为mysql
hs := dao.NewHstest()
hs.Where(hs.Id.Between(0, 5))
hs.OrderBy(hs.Id.Desc())
hs.Limit(3)
hs.Selects()8. gdaoMapper
- 使用 XML 映射 SQL
<!-- MyBatis 风格的 XML 配置文件 -->
<mapper namespace="user"><select id="selectHstest1" parameterType="int64" resultType="hstest1">SELECT * FROM hstest1 order by id desc limit #{limit}</select>
</mapper>//数据源设置
if db, err := getDataSource("sqlite.json"); err == nil {gdao.Init(db, gdao.SQLITE) gdao.SetLogger(true)
}//读取解析xml配置
hs1, _ := gdaoMapper.Select[dao.Hstest1]("user.selectHstest1", 1)
fmt.Println(hs1)id, _ := gdaoMapper.Select[int64]("user.selectHstest1", 1)
fmt.Println(*id)执行结果
[DEBUG][Mapper Id] user.selectHstest1
SELECTONE SQL[SELECT * FROM hstest1 order by id desc limit ?]ARGS[1]
Id:52,Rowname:rowname>>>123456789,Value:[104 101 108 108 111 32 103 100 97 111],Goto:[49 50 51 52 53]
[DEBUG][Mapper Id] user.selectHstest1
SELECTONE SQL[SELECT * FROM hstest1 order by id desc limit ?]ARGS[1]
52gdao的性能与运用
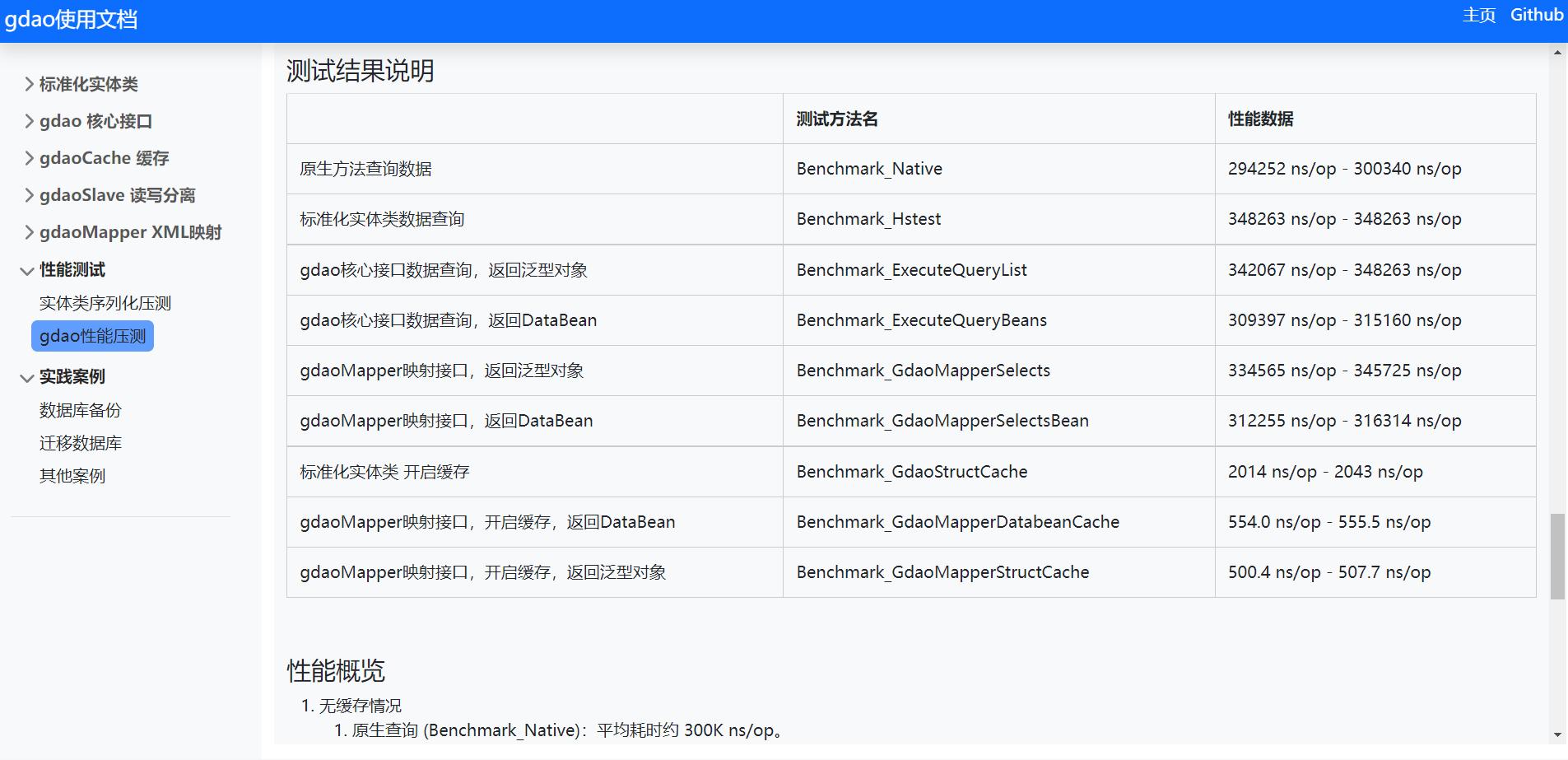
- 缓存的重要性:
- gdao 的性能表现:
- gdao 的性能已经非常接近原生的数据查询效率,这表明 gdao 的封装层引入的额外性能损耗非常小。
- 特别是在返回 DataBean 的情况下,gdao 的性能表现优异,这是由于 DataBean 的设计和处理机制高效性以及比泛型返回模式少了映射数据的流程,
- 性能损耗:
- 即使在没有开启缓存的情况下,gdao 的查询性能与原生查询相比也相差不大,这表明 gdao 的设计非常高效。
- 使用 gdao 的查询方法,无论是返回泛型对象还是 DataBean,性能都相当不错,说明 gdao 的封装层对性能的影响很小。
- 缓存与数据类型:
- 开启缓存后,使用标准化实体类的查询性能得到了极大的提升,这表明缓存对于此类查询特别有效。
- 使用 gdaoMapper 并开启缓存,无论是返回 DataBean 还是泛型对象,性能都有大幅提升,但返回 DataBean 的查询性能表现更优。
查看gdao使用文档,了解详细的性能测试数据与测试过程,和实践案例