1.Addressing Imbalance for Class Incremental Learning in Medical Image Classification

标题:解决医学图像分类中类增量学习的不平衡问题
作者: Xuze Hao, Wenqian Ni, Xuhao Jiang, Weimin Tan, Bo Yan
文章链接:https://arxiv.org/abs/2407.13768
摘要:
假设所有类别的训练样本同时可用,深度卷积神经网络在医学图像分类方面取得了重大突破。然而,在现实的医疗场景中,人们普遍需要不断学习新的疾病,从而催生了医学领域的新兴领域——类增量学习(CIL)。通常,CIL 在接受新课程训练时会遭受灾难性遗忘。这种现象主要是由新旧类别之间的不平衡引起的,并且随着不平衡的医疗数据集变得更加具有挑战性。在这项工作中,我们引入了两种简单而有效的插件方法来减轻不平衡的不利影响。首先,我们提出了 CIL 平衡分类损失,以通过 logit 调整来减轻分类器对多数类别的偏差。其次,我们提出了一种分布边际损失,它不仅可以减轻嵌入空间中的类间重叠,而且可以增强类内的紧凑性。我们通过在三个基准数据集(CCH5000、HAM10000 和 EyePACS)上进行大量实验来评估我们方法的有效性。结果表明我们的方法优于最先进的方法。
这篇论文试图解决什么问题?
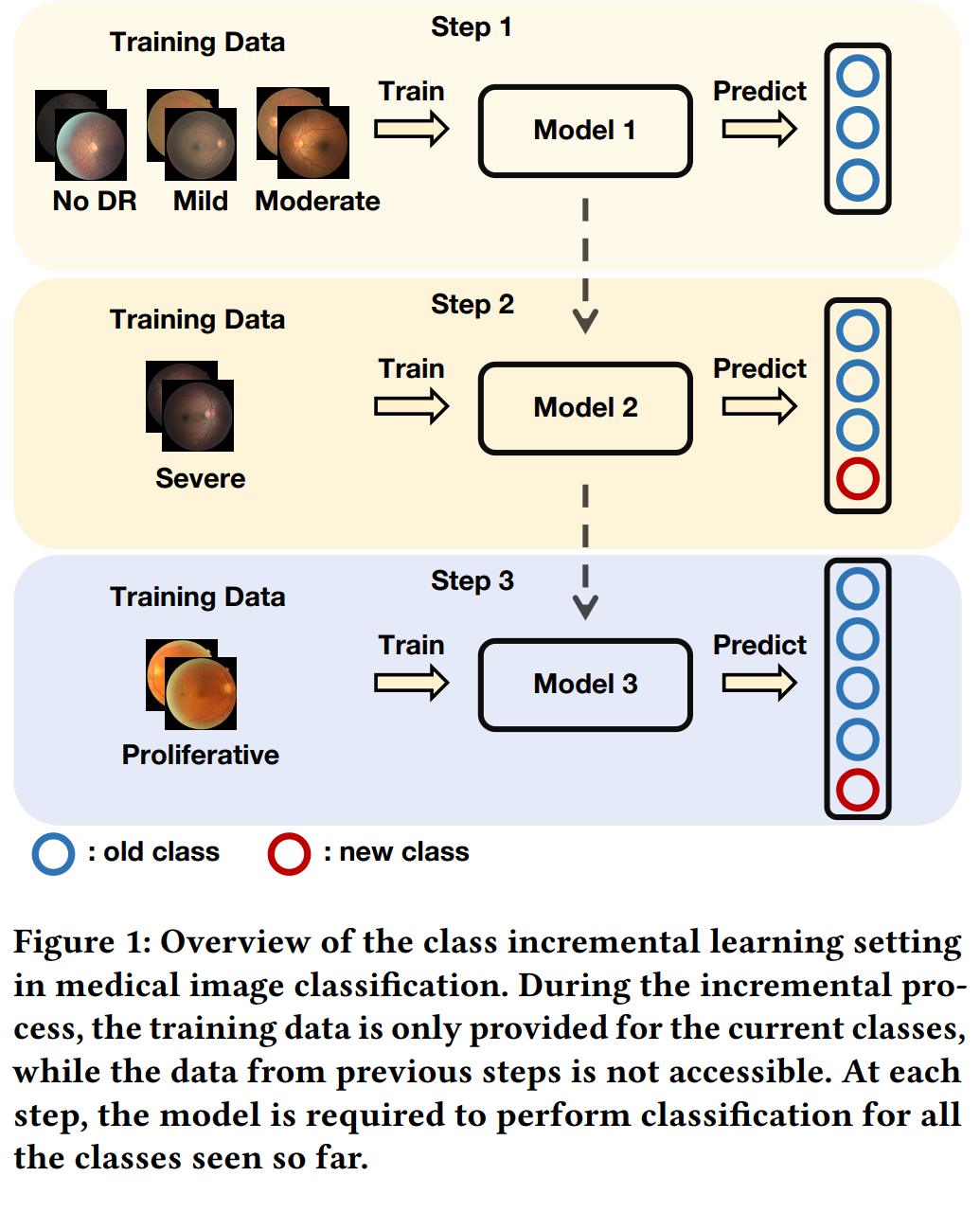
这篇论文试图解决医学图像分类中类别增量学习(Class Incremental Learning, CIL)面临的类别不平衡问题。在现实世界的医学场景中,随着新疾病的不断出现,需要模型能够持续学习新的类别,但传统的深度学习方法通常假设所有类别的训练样本同时可用,这在实际应用中往往不现实。类别增量学习在训练新类别时会遭受灾难性遗忘(catastrophic forgetting),即新数据的学习会抹去之前的知识。这种现象主要是由于旧类和新类之间的不平衡造成的,而在医学数据集中,这种不平衡问题尤为严重。
为了解决这一问题,论文提出了两种简单而有效的插件方法来减轻不平衡带来的不利影响:
-
CIL-balanced classification loss:通过logit调整减少分类器对多数类的偏见,强调少数类。
-
Distribution margin loss:不仅减轻了类别在嵌入空间中的重叠,还增强了类内紧凑性。
这些方法在CCH5000、HAM10000和EyePACS等三个基准数据集上的广泛实验表明,论文提出的方法优于现有的最先进方法。
论文如何解决这个问题?
论文通过提出两种新的损失函数来解决医学图像分类中的类别增量学习问题,这两种损失函数旨在解决类别不平衡问题:
-
CIL-balanced classification loss(CIL平衡分类损失):
-
为了减少分类器对多数类的偏见,作者提出了一种基于类别频率调整logit的方法。这种方法首先根据类别频率调整logit,以强调少数类,然后引入一个比例因子(scale factor)来进一步平衡旧类和新类之间的关系。
-
-
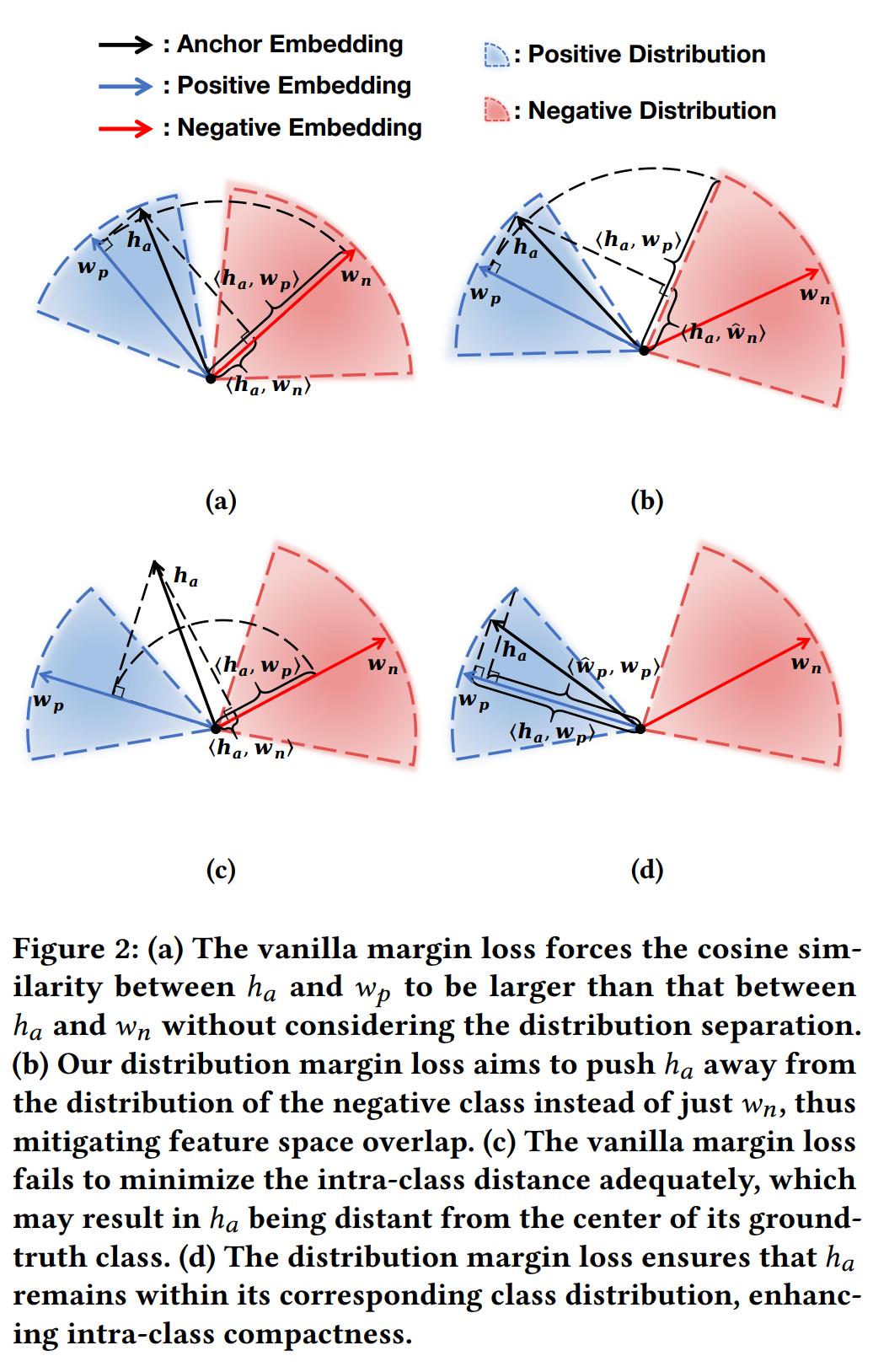
Distribution margin loss(分布边界损失):
-
为了缓解特征空间中类别的重叠问题,作者提出了一种新的边界损失,称为分布边界损失。这种损失不仅有助于推动旧类和新类在分布上的分离,而且还实现了类内紧凑性(intra-class compactness)的优化。
-
此外,论文还采用了以下策略:
-
记忆基方法(Memory-based approach):遵循记忆基方法,直接存储旧类别数据的一小部分用于排练(rehearsal)。
-
知识蒸馏损失(Knowledge Distillation Loss):为了防止遗忘并保持辨别能力,作者还应用了知识蒸馏损失来建立旧模型和当前模型之间的映射。
通过这些方法的综合应用,论文在CCH5000、HAM10000和EyePACS等医学图像数据集上进行了广泛的实验验证,并展示了其方法在处理类别不平衡问题方面的优越性。
论文做了哪些实验?
论文中进行了广泛的实验来验证所提出方法的有效性。以下是实验的主要设置和结果:
实验设置
-
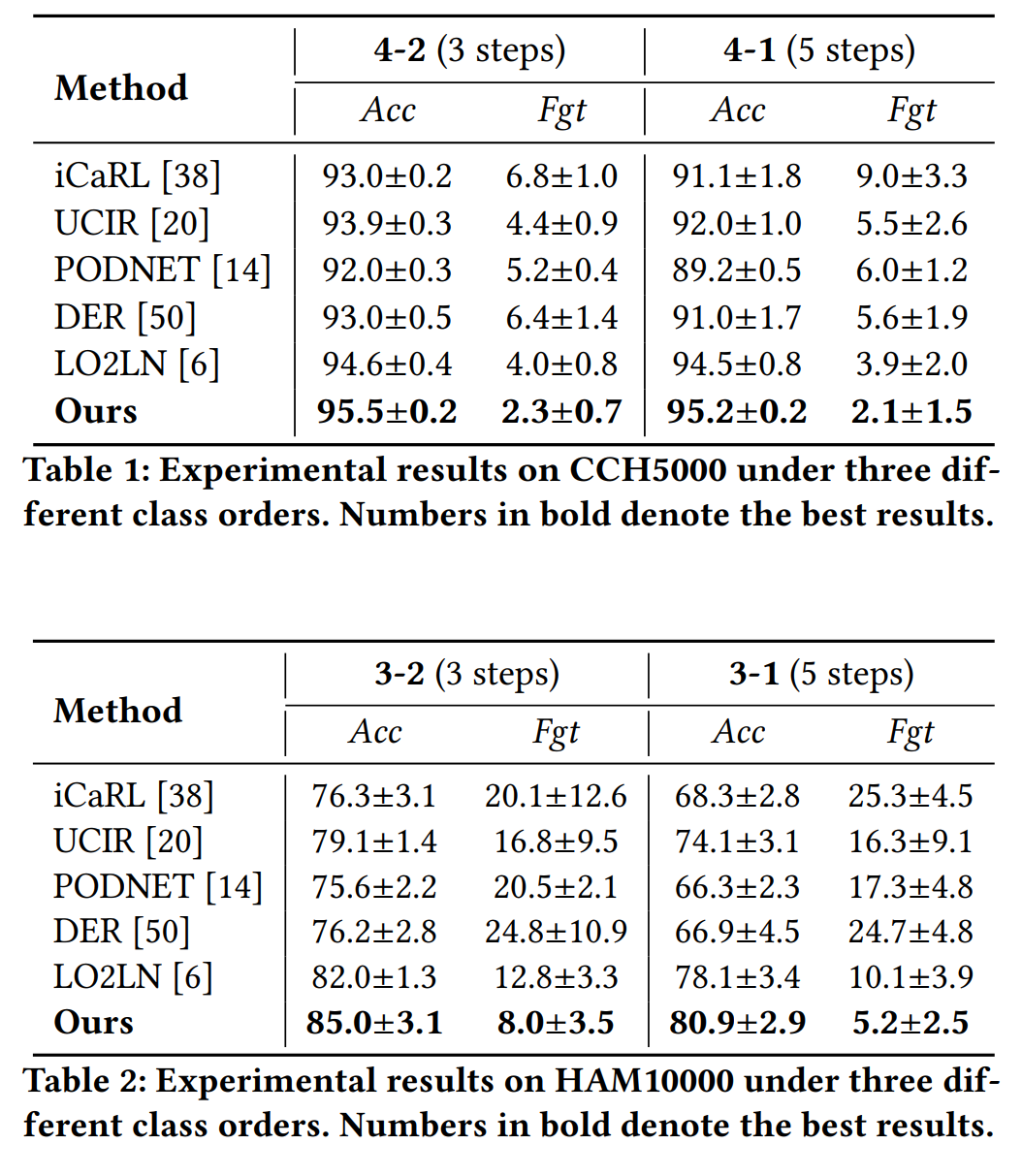
数据集:使用了三个医学图像数据集进行评估,分别是CCH5000、HAM10000和EyePACS。
-
评估协议:遵循先前工作的实验协议,评估了不同的场景,例如4-1、4-2、3-1等,这些数字表示基类和新类的数量。
-
评估指标:使用了平均准确率(Average Accuracy, Acc)和平均遗忘率(Average Forgetting, Fgt)两个标准指标来评估模型性能。
-
比较方法:与多种现有的增量学习方法进行了比较,包括iCaRL、UCIR、PODNet、DER和LO2LN等。
实验结果
-
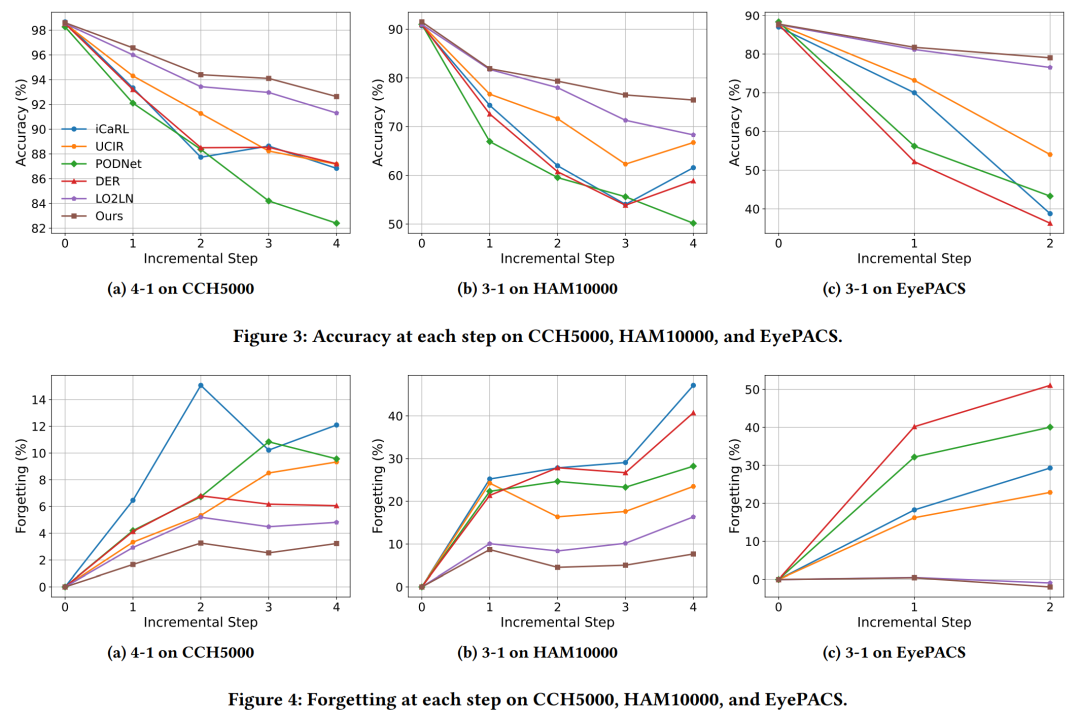
在CCH5000数据集上,提出的方法在4-2和4-1的设置下均取得了最佳性能,特别是在遗忘率(Fgt)上,相较于LO2LN方法有显著提升。
-
在HAM10000数据集上,提出的方法在处理高度不平衡的数据集时表现尤为出色,与现有最佳方法相比,在3-2和3-1的设置下均有显著的性能提升。
-
在EyePACS数据集上,提出的方法不仅展示了显著更高的平均准确率,而且在遗忘率上也低于其他基线方法。
增量性能分析
-
准确性:随着学习步骤的增加,基线方法的性能显著下降,而提出的方法能够有效减缓这种下降,显示出随着时间推移与基线方法之间的性能差距逐渐增大。
-
遗忘率:大多数方法在新类别到来时遗忘率迅速上升,而提出的方法在每个增量步骤上始终优于现有最佳方法,表明了对灾难性遗忘的改善。
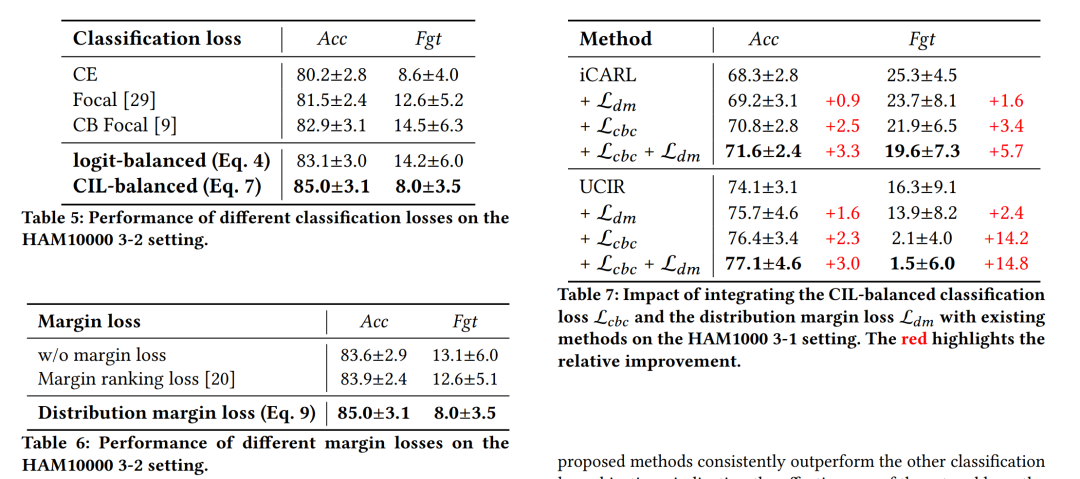
消融研究
-
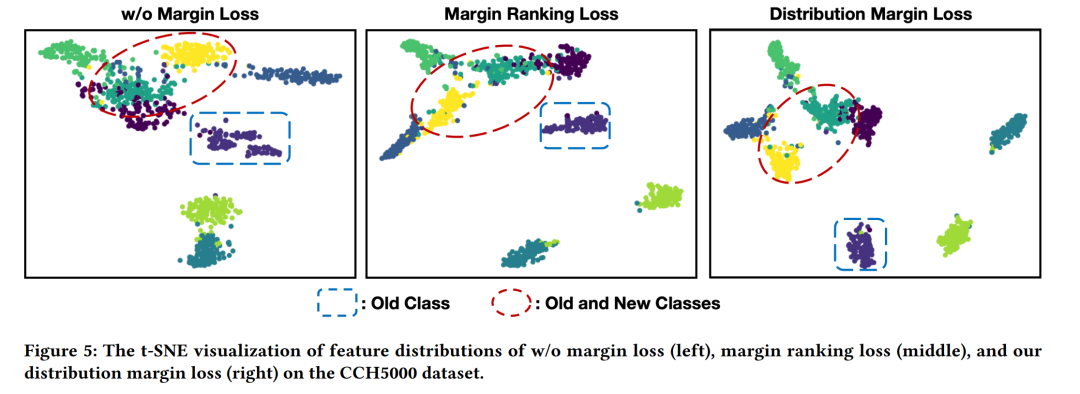
分析了每个组件的影响,包括CIL-balanced classification loss和distribution margin loss,以及它们与现有方法的集成效果。
-
研究了不同分类损失和边界损失对性能的影响,证明了提出的方法在解决类别不平衡问题方面的有效性。
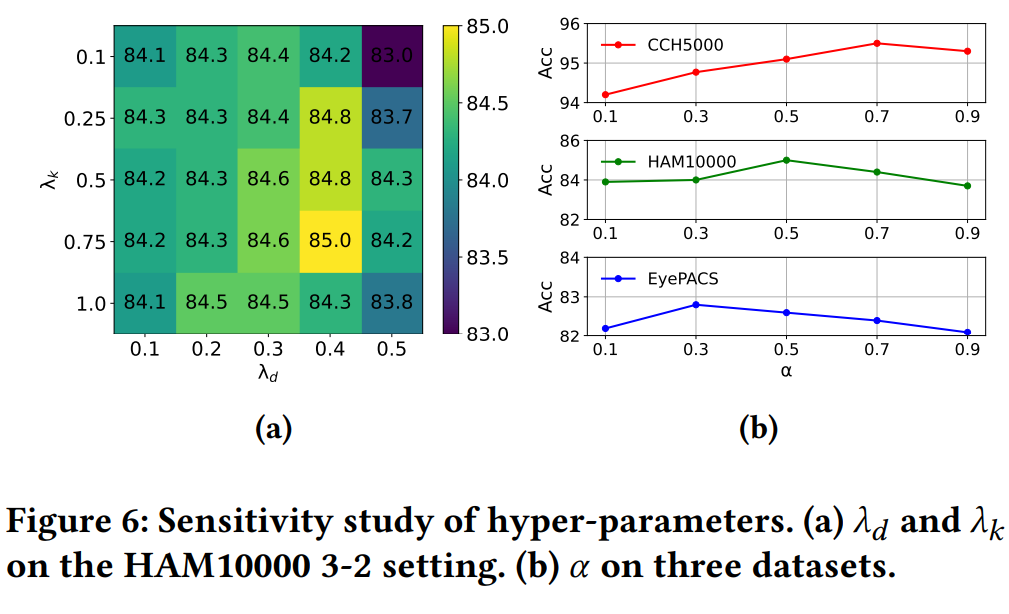
超参数敏感性研究
-
探讨了分布边界损失权重、知识蒸馏损失权重和权衡系数对模型性能的影响,并确定了不同数据集上的最优值。
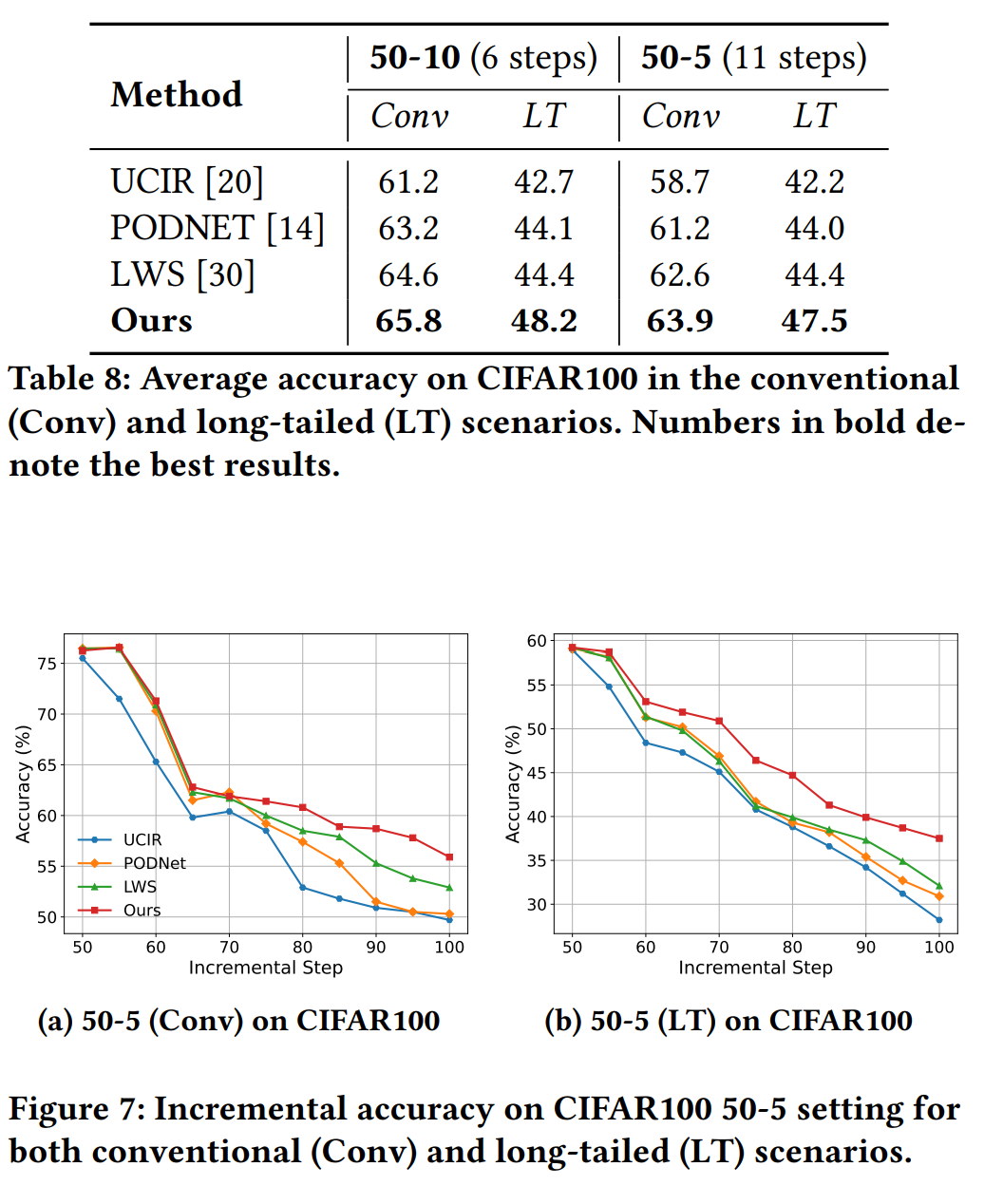
长期增量学习
-
在更长的学习步骤协议上评估了模型的鲁棒性,特别是在CIFAR100数据集上进行了50-10(6步)和50-5(11步)的实验,证明了提出的方法在长期增量学习中的有效性。
这些实验结果表明,论文提出的方法能够有效地解决医学图像分类中的类别增量学习问题,特别是在处理类别不平衡方面表现出色。
论文的主要内容:
这篇论文的主要内容包括以下几个方面:
-
问题背景:论文讨论了在医学图像分类领域中,深度卷积神经网络在假设所有类别的训练样本同时可用的情况下取得了显著进展。然而,在现实世界的医学场景中,需要模型能够持续学习新疾病,这导致了类别增量学习(Class Incremental Learning, CIL)的需求。
-
问题挑战:CIL在训练新类别时会遭受灾难性遗忘(catastrophic forgetting),即新数据的学习会抹去之前的知识。这种现象主要是由于旧类和新类之间的不平衡造成的,而在医学数据集中,这种不平衡问题尤为严重。
-
方法介绍:为了解决类别不平衡问题,论文提出了两种简单而有效的插件方法:
-
CIL-balanced classification loss:通过logit调整减少分类器对多数类的偏见,强调少数类。
-
Distribution margin loss:旨在推动旧类和新类在特征空间中的分布分离,并增强类内紧凑性。
-
-
实验验证:论文在CCH5000、HAM10000和EyePACS三个医学图像数据集上进行了广泛的实验,验证了所提出方法的有效性。实验结果表明,所提出的方法在处理类别不平衡问题方面优于现有的最先进方法。
-
实验分析:
-
增量性能分析:展示了随着学习步骤的增加,所提出方法在准确性和遗忘率上的表现。
-
消融研究:分析了每个组件的影响,包括CIL-balanced classification loss和distribution margin loss。
-
超参数敏感性研究:探讨了不同超参数对模型性能的影响。
-
-
结论:论文总结了所提出方法的主要贡献,并指出其在医学图像分类的类别增量学习问题中的有效性。
-
致谢:论文最后感谢了支持该研究的资助机构和使用的计算平台。
整体而言,这篇论文针对医学图像分类中的类别增量学习问题,提出了创新的解决方案,并通过实验验证了其有效性,为该领域的研究提供了新的思路和方法。
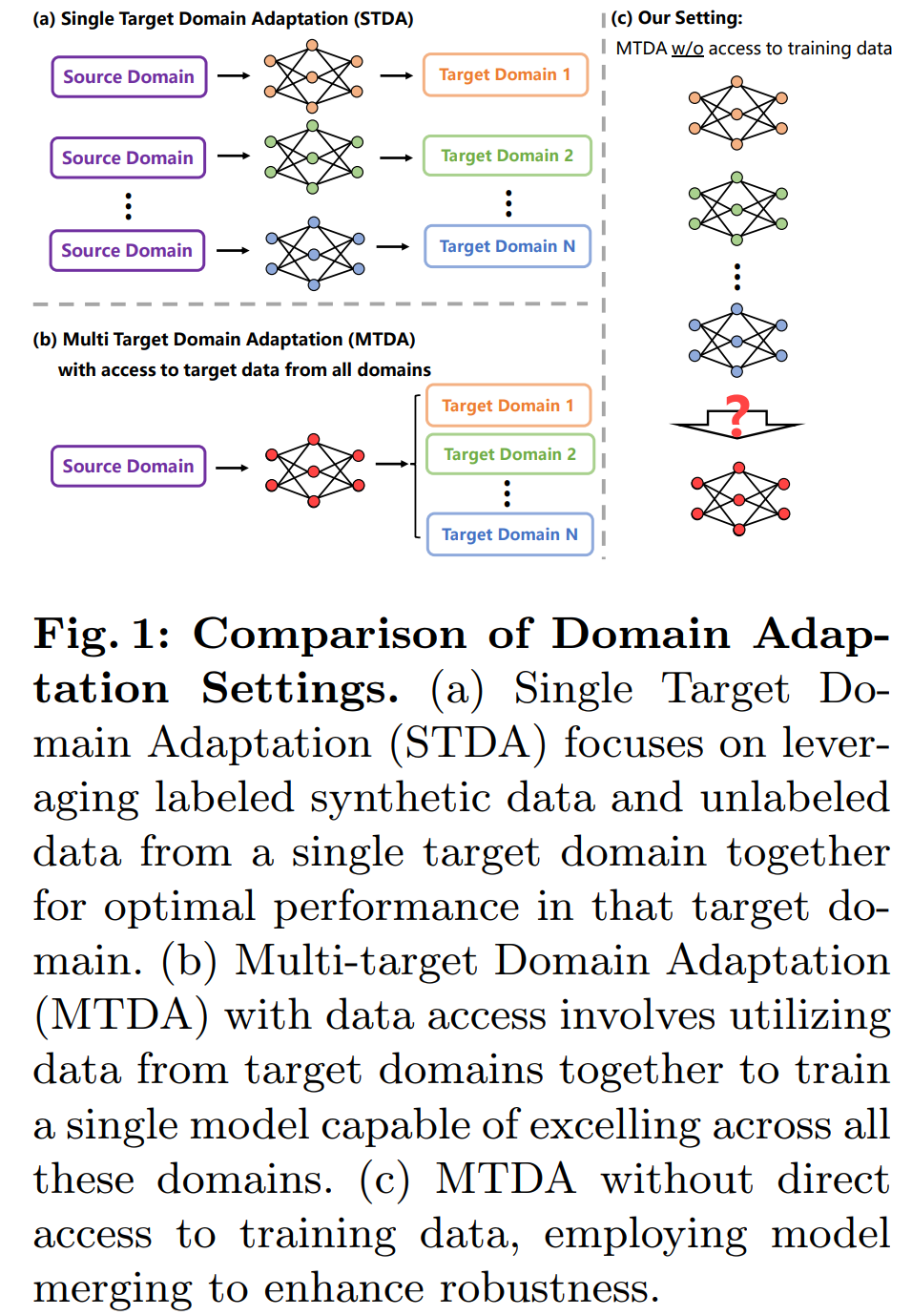
2.Training-Free Model Merging for Multi-target Domain Adaptation

标题: 用于多目标域适应的免训练模型合并
作者: Wenyi Li, Huan-ang Gao, Mingju Gao, Beiwen Tian, Rong Zhi, Hao Zhao
文章链接:https://arxiv.org/abs/2407.13771
项目代码:https://air-discover.github.io/ModelMerging/
摘要:
在本文中,我们研究场景理解模型的多目标域适应。虽然以前的方法通过域间一致性损失取得了值得称赞的结果,但它们经常假设从所有目标域同时访问图像是不现实的,忽视了数据传输带宽限制和数据隐私问题等约束。考虑到这些挑战,我们提出了一个问题:如何合并在不同领域独立适应的模型,同时绕过直接访问训练数据的需要?我们对此问题的解决方案涉及两个组件,合并模型参数和合并模型缓冲区(即归一化层统计数据)。对于合并模型参数,模式连接性的实证分析令人惊讶地表明,当采用相同的预训练骨干权重来适应单独的模型时,线性合并就足够了。为了合并模型缓冲区,我们使用高斯先验对现实世界的分布进行建模,并从单独训练的模型的缓冲区中估计新的统计数据。我们的方法简单而有效,可实现与数据组合训练基线相当的性能,同时无需访问训练数据。项目页面:此 https URL
这篇论文试图解决什么问题?
这篇论文试图解决的主要问题是在计算机视觉任务中,如何扩展基于状态空间模型(SSMs)的模型,特别是解决这些模型在大型尺寸时的不稳定性以及效率问题。具体来说,论文中提到了以下几个关键挑战:
-
稳定性问题:现有的基于SSM的模型,如Mamba的S6算法,在扩展到大型模型时,特别是在图像分类任务中,会遇到训练不稳定的问题。
-
参数和计算效率:传统的视觉状态空间(VSS)块在参数和计算需求上与输入通道数直接相关,这导致在处理大量通道时效率低下。
-
全局上下文处理:SSMs在处理信息密集型数据时,如计算机视觉领域,其数据独立的性质限制了全局上下文的处理能力。
为了解决这些问题,论文提出了以下解决方案:
-
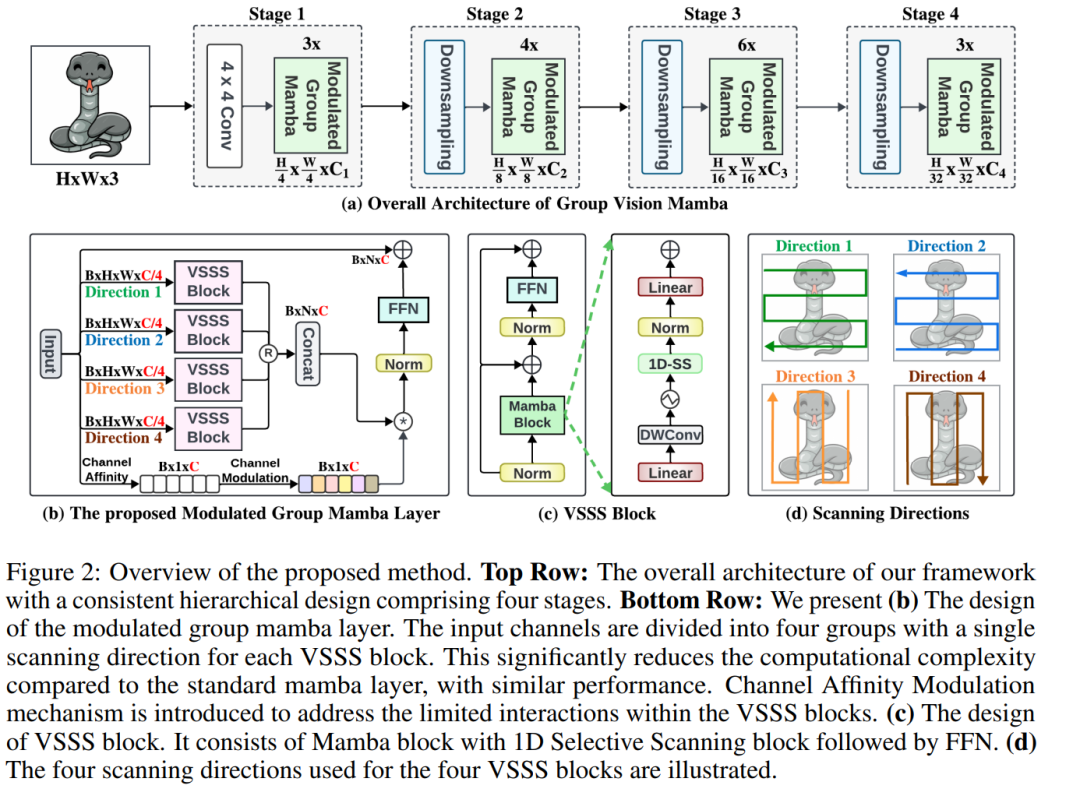
Modulated Group Mamba层:通过将输入通道分成四组,并独立地对每组应用基于SSM的高效视觉单选择性扫描(VSSS)块,每组VSSS块在一个空间方向上进行扫描,从而提高计算和参数效率。
-
通道亲和力调制(CAM)操作:为了增强通道间的通信,提出了CAM操作,以改善特征聚合。
-
基于蒸馏的训练目标:为了稳定大型模型的训练,引入了基于蒸馏的训练目标,通过结合分类损失和蒸馏损失来训练学生模型。
-
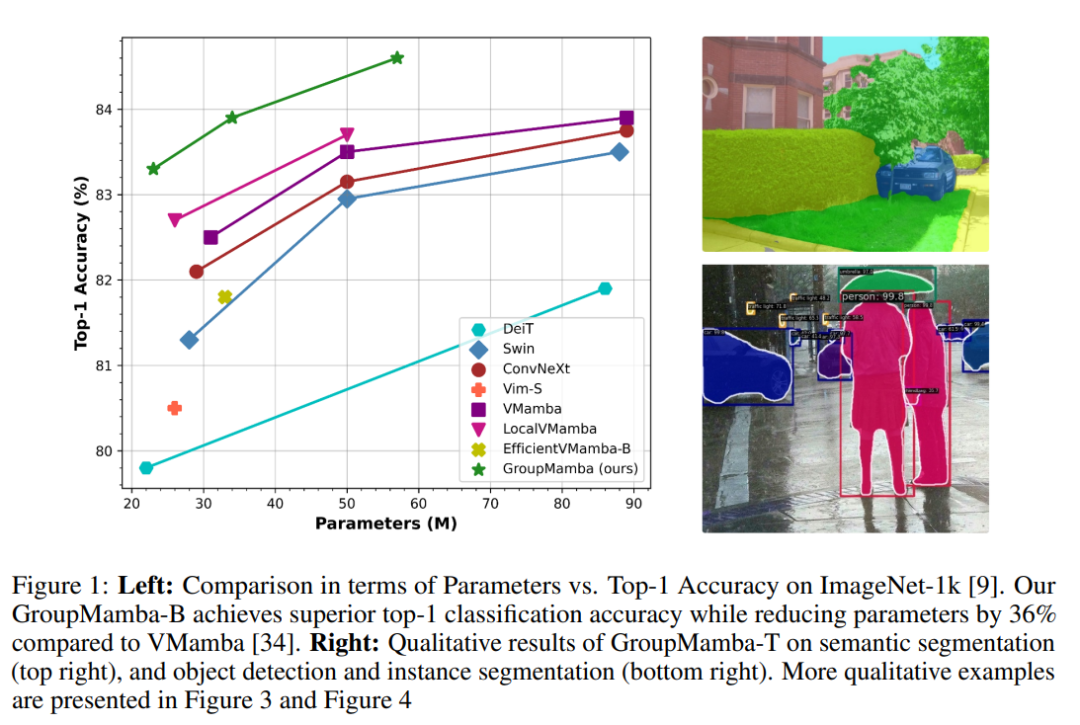
构建了一系列参数高效的通用分类模型:称为“GroupMamba”,这些模型在ImageNet-1K图像分类、MS-COCO对象检测和实例分割、ADE20K语义分割等任务上展示了优越的性能。
这些贡献旨在提高SSMs在视觉任务中的性能,同时减少所需的参数数量和计算复杂性。
论文如何解决这个问题?
论文通过以下几个关键方法来解决计算机视觉任务中状态空间模型(SSMs)的扩展问题,特别是针对大型模型的不稳定性以及效率问题:
-
Modulated Group Mamba Layer:
-
将输入通道分成四组,每组独立应用基于SSM的Visual Single Selective Scanning (VSSS) 块。
-
每组VSSS块在四个空间方向之一(左到右、右到左、上到下、下到上)进行扫描,以实现对输入序列的全面空间覆盖。
-
-
Channel Affinity Modulation (CAM) Operator:
-
为了增强不同通道间的信息交流,提出了CAM操作符,通过重新校准通道特征响应来增强网络的特征聚合能力。
-
通过全局平均池化计算通道统计信息,然后计算通道间的亲和性,最后将这些亲和性权重应用于Grouped Mamba操作的输出。
-
-
Distillation-Based Training Objective:
-
为了稳定大型模型的训练,引入了基于蒸馏的训练目标,结合了分类损失和蒸馏损失。
-
使用教师模型(如RegNetY-16G)的输出来指导学生模型的训练,通过最小化学生模型和教师模型输出之间的交叉熵损失来实现知识传递。
-
-
Hierarchical Architecture:
-
采用了类似Swin Transformer的分层架构,模型包含四个阶段,每个阶段处理不同分辨率的图像。
-
在每个阶段中,使用Patch Embedding层将图像分割成非重叠的小块,然后通过Modulated Grouped Mamba块进行处理。
-
-
Visual Single Selective Scan (VSSS) Block:
-
VSSS块是基于Mamba操作的标记和通道混合器,它使用1D选择性扫描块后跟一个前馈网络(FFN)来处理输入序列。
-
-
Grouped Mamba Operator:
-
Grouped Mamba操作是VSSS块的变体,它将输入通道分组,并分别对每组应用VSSS操作,以提高计算效率。
-
-
Parameter Efficiency:
-
通过上述方法,论文构建了一系列参数高效的通用分类模型,称为“GroupMamba”,这些模型在保持性能的同时减少了所需的参数数量。
-
通过这些方法,论文旨在提高SSMs在视觉任务中的性能,同时减少所需的参数数量和计算复杂性,从而解决了大型模型的不稳定性问题和效率问题。
论文做了哪些实验?
论文中进行了一系列实验来验证所提出的GroupMamba模型的性能和效率。以下是实验的主要内容:
-
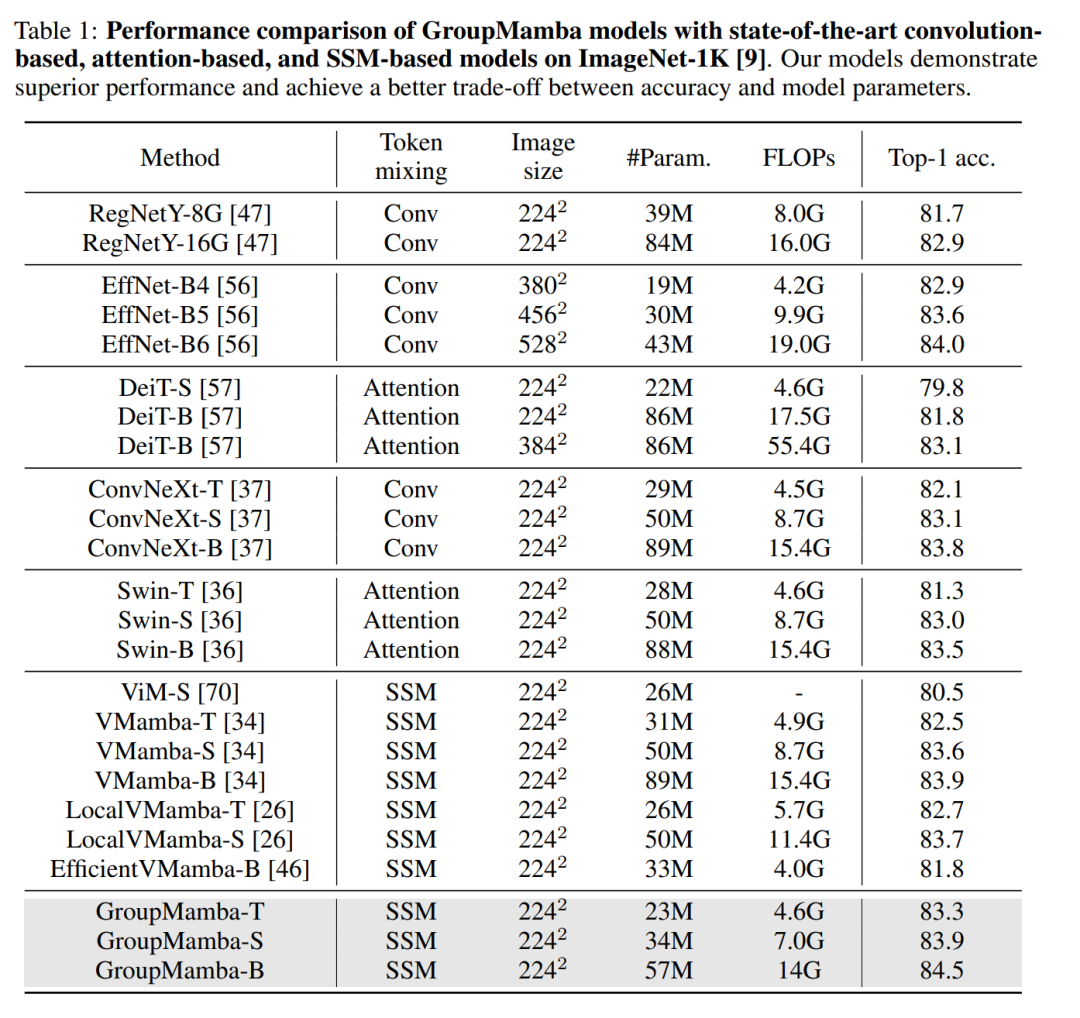
图像分类:
-
在ImageNet-1K数据集上进行图像分类实验,该数据集包含超过128万张训练图像和50K验证图像,涵盖1000个类别。
-
使用AdamW优化器和余弦衰减学习率调度器进行300个epoch的训练,包括20个epoch的预热。
-
比较了GroupMamba模型(T, S, B)与现有的最先进方法,包括基于卷积的、基于注意力的和基于SSM的模型。
-
-
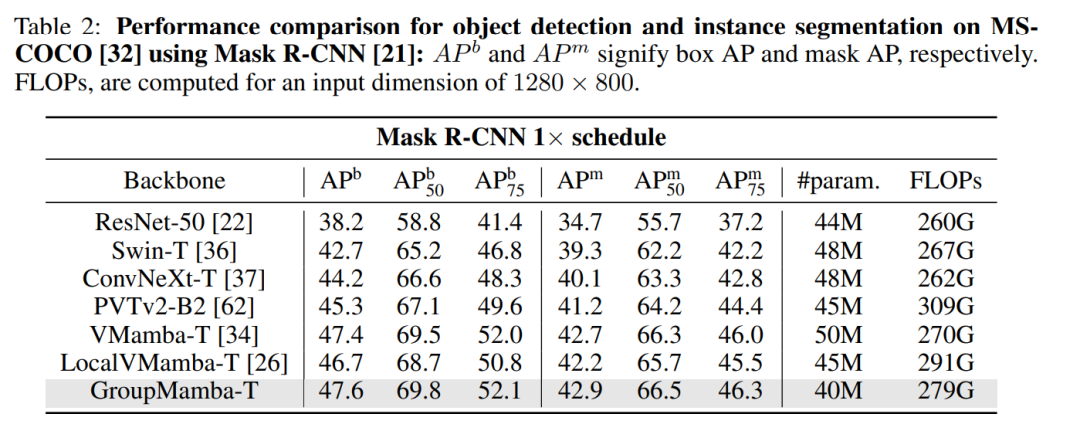
对象检测和实例分割:
-
在MS-COCO 2017数据集上评估GroupMamba-T模型的性能,该数据集用于对象检测任务。
-
使用Mask-RCNN检测器,并使用AdamW优化器进行12个epoch的训练。
-
比较了GroupMamba-T与其他最先进模型的性能,包括ResNet-50、Swin-T、ConvNeXt-T等。
-
-
语义分割:
-
在ADE20K数据集上评估GroupMamba-T模型在语义分割任务上的性能。
-
使用UperNet架构,并遵循Swin Transformer的超参数设置。
-
比较了GroupMamba-T与其他最先进方法的性能,包括ResNet-50、Swin-T、ConvNeXt-T等。
-
-
消融研究:
-
对GroupMamba-T模型的各个组成部分进行了消融研究,以评估每个贡献对模型性能的影响。
-
比较了不使用CAM模块的GroupMamba-T模型、使用CAM模块的模型、扩展通道数以匹配VMamba-T参数数量的模型,以及使用蒸馏损失的模型。
-
-
定性结果:
-
展示了GroupMamba-T在MS-COCO验证集上的对象检测和实例分割的定性结果,以及在ADE20K验证集上的语义分割的定性结果。
-
-
性能比较:
-
在ImageNet-1K、MS-COCO和ADE20K数据集上,GroupMamba模型与现有最先进方法的性能进行了详细的比较,包括准确率、参数数量和浮点运算次数(FLOPs)。
-
通过这些实验,论文展示了GroupMamba模型在不同视觉任务中的优越性能,证明了其在参数效率和计算效率方面的优势。同时,消融研究进一步验证了所提出的方法的各个组成部分的有效性。
论文的主要内容:
这篇论文的主要内容包括以下几个方面:
-
问题陈述:
-
论文指出了在计算机视觉任务中,现有的基于状态空间模型(SSMs)的模型在扩展到大型尺寸时面临的稳定性和效率问题。
-
-
方法介绍:
-
Modulated Group Mamba Layer:将输入通道分为四组,每组独立应用Visual Single Selective Scanning (VSSS) 块,每组在不同的空间方向上进行扫描。
-
Channel Affinity Modulation (CAM) Operator:增强不同通道间的信息交流,通过重新校准通道特征响应来增强网络的特征聚合能力。
-
Distillation-Based Training Objective:引入基于蒸馏的训练目标,通过结合分类损失和蒸馏损失来稳定大型模型的训练。
-
为了解决这些问题,论文提出了一种新的模型结构,称为Modulated Group Mamba,它包括:
-
-
模型架构:
-
论文采用了分层架构,类似于Swin Transformer,包含四个阶段,每个阶段处理不同分辨率的图像,并使用Patch Embedding层将图像分割成非重叠的小块。
-
-
实验验证:
-
在ImageNet-1K数据集上进行了图像分类实验,证明了GroupMamba模型在参数效率和计算效率方面的优势。
-
在MS-COCO数据集上进行了对象检测和实例分割实验,展示了GroupMamba模型在这些任务上的性能。
-
在ADE20K数据集上进行了语义分割实验,进一步验证了模型的有效性。
-
-
消融研究:
-
通过消融研究,论文展示了所提出的CAM模块和蒸馏损失对模型性能的影响。
-
-
定性结果:
-
提供了在COCO验证集和ADE20K验证集上的定性结果,展示了GroupMamba模型在实例分割和语义分割任务上的实际效果。
-
-
性能比较:
-
论文将GroupMamba模型与现有的最先进方法进行了详细的性能比较,包括准确率、参数数量和浮点运算次数(FLOPs)。
-
-
代码和模型:
-
论文提供了实现GroupMamba模型的代码和预训练模型,方便其他研究者复现和进一步研究。
-
总结来说,这篇论文通过提出一种新的Modulated Group Mamba模型,有效地解决了SSMs在计算机视觉任务中的扩展问题,并通过广泛的实验验证了其优越的性能和效率
3.GroupMamba: Parameter-Efficient and Accurate Group Visual State Space Model
标题:GroupMamba:参数高效且准确的群体视觉状态空间模型
作者:Abdelrahman Shaker, Syed Talal Wasim, Salman Khan, Juergen Gall, Fahad Shahbaz Khan
文章链接:https://arxiv.org/abs/2407.13772
项目代码:https://github.com/Amshaker/GroupMamba


摘要:
状态空间模型 (SSM) 的最新进展展示了在模拟具有次二次复杂度的远程依赖关系方面的有效性能。然而,纯基于 SSM 的模型仍然面临与稳定性和在计算机视觉任务上实现最佳性能相关的挑战。我们的论文解决了扩展基于 SSM 的计算机视觉模型的挑战,特别是大模型的不稳定性和低效率。为了解决这个问题,我们引入了调制组 Mamba 层,它将输入通道分为四组,并将我们提出的基于 SSM 的高效视觉单选择扫描 (VSSS) 块独立地应用于每个组,每个 VSSS 块扫描在四个通道之一中空间方向。 Modulated Group Mamba 层还将四个 VSSS 块封装到一个通道调制运算符中,以改善跨通道通信。此外,我们引入了基于蒸馏的训练目标来稳定大型模型的训练,从而实现一致的性能提升。我们的综合实验证明了所提出的贡献的优点,与 ImageNet-1K 上的图像分类、对象检测、MS-COCO 上的实例分割以及 ADE20K 上的语义分割的现有方法相比,具有更优越的性能。与相同模型的现有最佳 Mamba 设计相比,我们具有 23M 参数的微小变体实现了最先进的性能,在 ImageNet-1K 上的分类 top-1 准确率为 83.3%,同时参数效率提高了 26%尺寸。我们的代码和模型可在以下位置获取:此 https URL。
这篇论文试图解决什么问题?
这篇论文研究了多目标领域自适应(Multi-target Domain Adaptation, MTDA)的场景理解模型。论文试图解决的问题是如何在没有直接访问所有目标领域训练数据的情况下,将独立适应不同领域的模型合并成一个单一的、有效的模型。具体来说,论文面临的挑战包括:
-
数据传输带宽限制:同时访问所有目标领域的图像数据可能会产生巨大的数据传输成本,因为这些数据集可能包含数千张图像,总计数百GB。
-
数据隐私问题:由于政策限制,可能无法共享或传输某些数据,这限制了可以用于训练的数据。
为了应对这些挑战,论文提出了一种新颖的问题设置,即在没有直接访问训练数据的情况下,通过模型合并来增强模型的鲁棒性。论文的主要贡献包括:
-
对领域自适应场景解析模型的模式连通性进行了系统性探索,揭示了模型合并生效的潜在条件。
-
引入了一种包括参数合并和缓冲区合并的模型合并技术,适用于任何单目标领域自适应模型。
-
该方法在数据可用性受限的情况下,实现了与多数据集组合训练基线相当的性能。
论文通过实证分析和实验验证了这种方法的有效性,并在多个数据集上展示了其优越的性能。
论文如何解决这个问题?
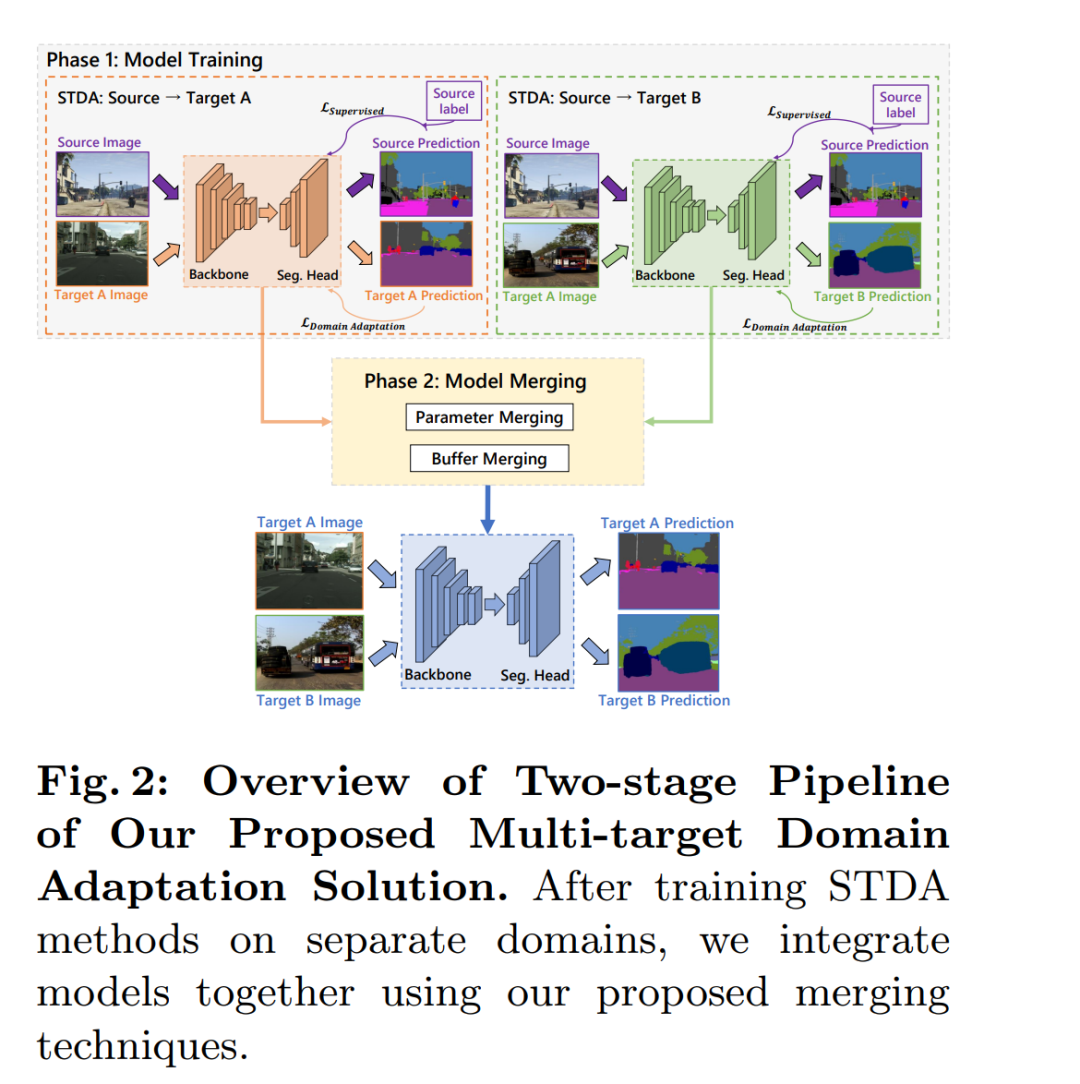
论文通过提出一种新颖的模型合并策略来解决多目标领域自适应(MTDA)问题,而无需依赖训练数据。具体方法包括以下两个主要组成部分:
-
模型参数合并(Merging Model Parameters):
-
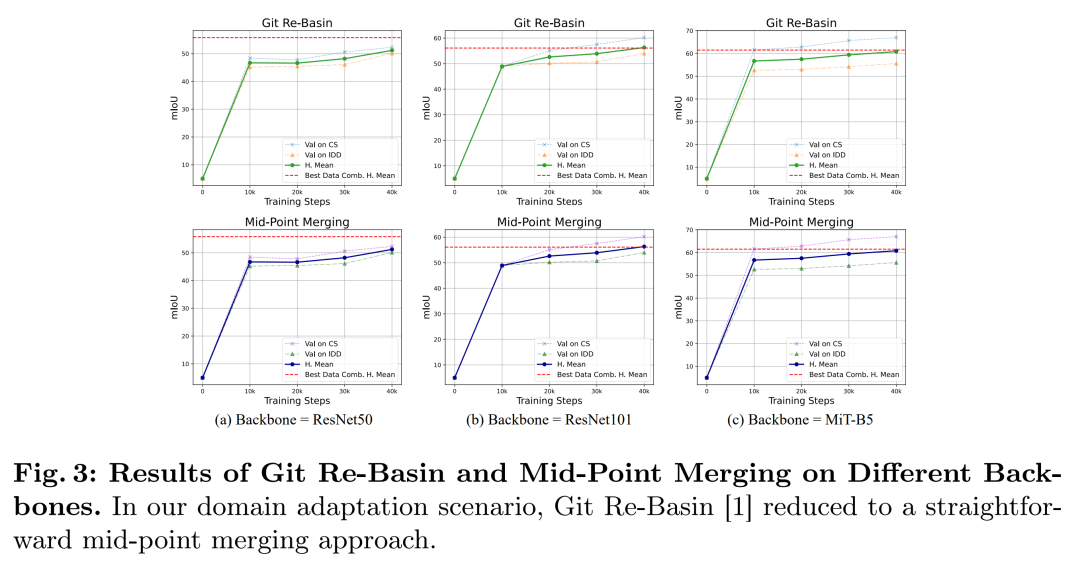
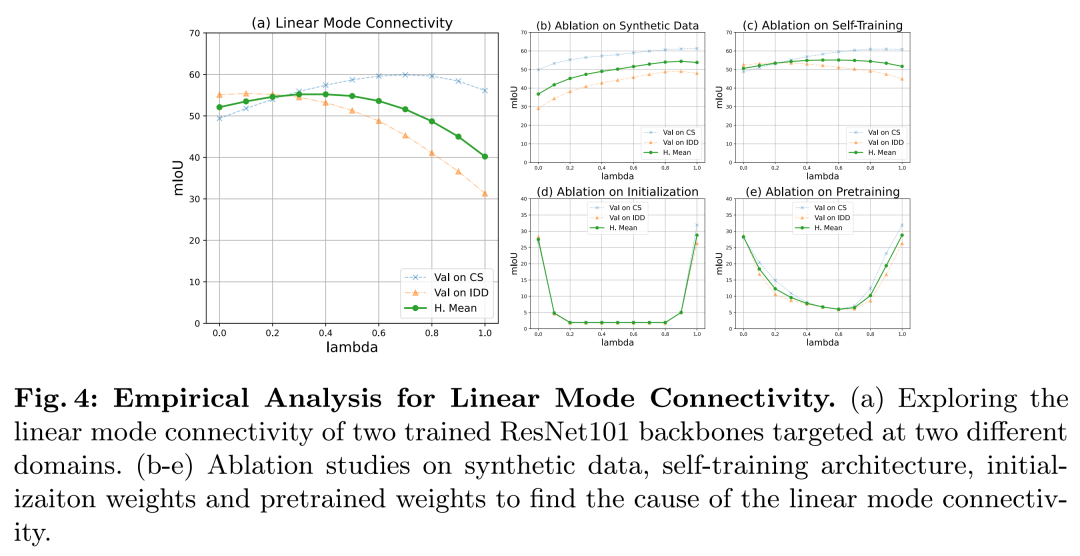
论文首先探讨了如何将独立适应不同目标领域的模型参数进行合并。作者发现,当使用相同的预训练模型权重来适应不同的领域时,简单的线性合并(如权重平均)就足够有效。
-
通过实证分析,作者发现预训练显著增强了训练模型之间的线性模式连通性(linear mode connectivity),这表明从相同的预训练权重开始,领域自适应模型可以有效地过渡到不同的目标领域,同时在参数空间内保持线性模式连通性。
-
-
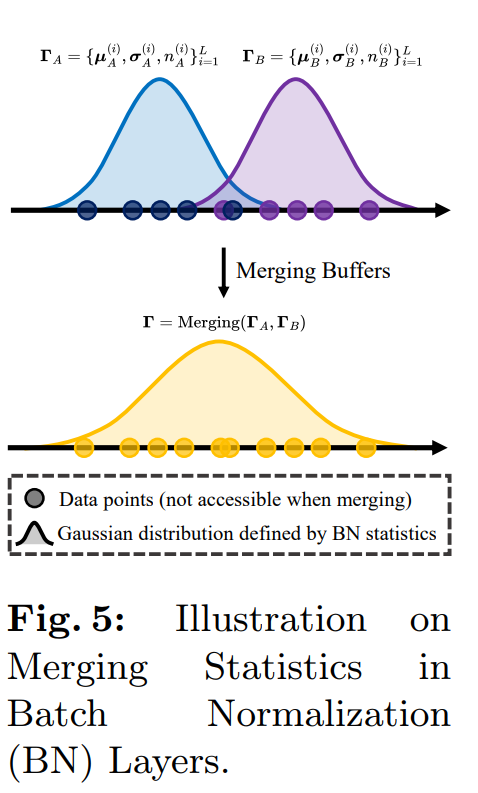
模型缓冲区合并(Merging Model Buffers):
-
论文还强调了模型缓冲区(如批量归一化层的统计数据)在多目标领域自适应中的重要性,因为这些缓冲区捕捉了特定于领域的特征。
-
作者提出了一种基于高斯先验的方法来估计合并层的新均值和方差,这些统计数据基于独立训练模型的缓冲区。这种方法不需要在合并阶段访问任何训练数据。
-
此外,论文还介绍了一个两阶段的流程:
-
第一阶段:单目标领域自适应(STDA):
-
在这一阶段,作者使用最新的无监督领域自适应方法(如HRDA)分别在不同的目标领域上训练模型。
-
-
第二阶段:模型合并:
-
在第二阶段,作者将第一阶段训练好的模型通过提出的参数合并和缓冲区合并技术整合到一起,形成一个鲁棒的模型,无需访问任何训练数据。
-
论文通过实验验证了这种方法的有效性,展示了在多个数据集上的性能提升。特别是在数据可用性受限的情况下,该方法的性能与多数据集组合训练的基线相当,甚至在某些情况下超过了现有的多目标领域自适应方法。
总结来说,论文通过模型参数的线性合并和缓冲区的统计数据合并,提出了一种简单而有效的多目标领域自适应方法,无需依赖训练数据,从而解决了数据传输带宽限制和数据隐私问题。
论文做了哪些实验?
论文中进行了一系列实验来验证所提出的多目标领域自适应(MTDA)模型合并方法的有效性。以下是实验的主要部分和结果:
-
数据集:
-
使用了GTA和SYNTHIA作为合成数据集,以及Cityscapes、Indian Driving Dataset (IDD)、ACDC和DarkZurich作为真实世界的目标领域数据集。
-
-
实现细节:
-
在单目标领域自适应(STDA)阶段,使用了HRDA方法,并在不同的图像编码器(如ResNet50、ResNet101和MiT-B5)上进行了训练。
-
-
模型合并:
-
在模型合并阶段,直接使用检查点文件的状态字典进行参数的中点合并和缓冲区的合并。
-
-
与基线方法的比较:
-
将所提出的方法与数据组合(Data Combination)方法和单目标领域自适应(STDA)基线进行了比较。数据组合方法涉及在两个目标领域的数据混合上训练单一领域自适应模型。
-
-
性能比较:
-
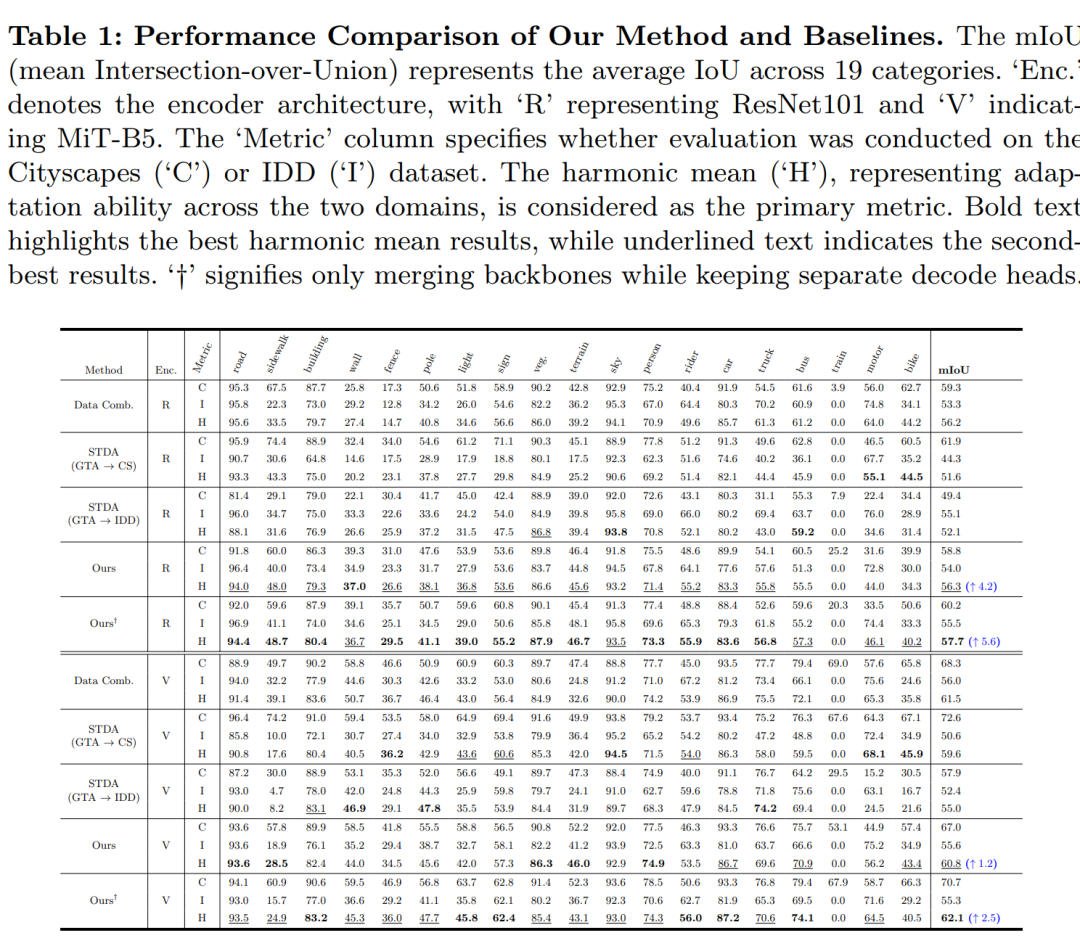
使用ResNet101和MiT-B5作为图像编码器,展示了所提出方法在不同目标领域的性能提升。与最强的单目标领域自适应模型相比,所提出方法在调和平均值(harmonic mean)上分别提高了4.2%和1.2%。
-
-
与最新技术方法的比较:
-
将所提出的方法与领域泛化(Domain Generalization)和多目标领域自适应(MTDA)的最新技术方法进行了比较,展示了在不同设置下的性能。
-
-
扩展到更多目标领域:
-
将模型合并技术扩展到四个不同的目标领域(Cityscapes、IDD、ACDC和DarkZurich),并展示了模型合并方法在这些领域中的性能提升。
-
-
消融研究:
-
对参数合并和缓冲区合并方法进行了消融研究,以验证每种方法的有效性。
-
-
可视化结果:
-
提供了不同基线和所提出模型合并方法的可视化比较,展示了合并方法如何保留两个独立模型的预测优势。
-
-
在不同数据集和任务上的验证:
-
在SYNTHIA数据集上重复了实验,验证了所提出方法的广泛适用性。
-
将模型合并方法应用于图像分类任务,并在CIFAR-100数据集上进行了实验,验证了方法的有效性。
-
通过这些实验,论文展示了所提出方法在多目标领域自适应任务中的有效性,并在多个数据集上取得了与数据组合训练基线相当的性能,同时避免了直接访问训练数据的需求。
论文的主要内容:
这篇论文提出了一种新颖的多目标领域自适应(MTDA)模型合并方法,旨在解决在没有直接访问所有目标领域训练数据的情况下,如何将独立适应不同领域的模型整合成一个单一有效模型的问题。以下是论文的主要内容总结:
-
问题背景:
-
论文讨论了场景理解模型在不同领域(如不同的光照、天气和城市景观)中可靠运行的重要性,以及传统的监督学习方法在这些任务中的局限性。
-
-
多目标领域自适应的挑战:
-
论文指出,与单目标领域自适应(STDA)相比,MTDA需要开发能够在多个目标领域中有效运行的单一模型,这更具挑战性。
-
-
模型合并策略:
-
参数合并:通过实证分析发现,当使用相同的预训练权重时,简单的线性合并(如权重平均)就足够有效。
-
缓冲区合并:利用高斯先验假设,从独立训练模型的缓冲区(如批量归一化层的统计数据)估计新的统计数据。
-
提出了一种模型合并方法,包括两个主要组成部分:
-
-
两阶段流程:
-
第一阶段:使用STDA方法分别在不同的目标领域上训练模型。
-
第二阶段:将训练好的模型通过参数合并和缓冲区合并技术整合到一起,形成一个鲁棒的模型。
-
-
实验验证:
-
在多个数据集上进行了实验,包括GTA、SYNTHIA、Cityscapes、Indian Driving Dataset (IDD)、ACDC和DarkZurich。
-
与数据组合方法和STDA基线进行了比较,展示了所提出方法的有效性。
-
-
消融研究:
-
对参数合并和缓冲区合并方法进行了消融研究,以验证每种方法的有效性。
-
-
可视化结果:
-
提供了不同基线和所提出模型合并方法的可视化比较,展示了合并方法如何保留两个独立模型的预测优势。
-
-
扩展到更多目标领域:
-
将模型合并技术扩展到四个不同的目标领域,并展示了模型合并方法在这些领域中的性能提升。
-
-
与最新技术方法的比较:
-
将所提出的方法与领域泛化(Domain Generalization)和MTDA的最新技术方法进行了比较,展示了在不同设置下的性能。
-
-
结论:
-
论文得出结论,所提出的模型合并策略是简单而有效的,能够在数据可用性受限的情况下实现与多数据集组合训练基线相当的性能。
-
论文的主要贡献在于提出了一种无需训练数据即可实现多目标领域自适应的方法,为解决数据传输带宽限制和数据隐私问题提供了新的解决方案。






